Atualmente nas micro e pequenas organizaçőes existe uma deficięncia com relaçăo ao aproveitamento das informaçőes armazenadas em suas bases de dados. Com base nisso, a ferramenta desenvolvida tem o intuito de prover a alta direçăo uma visăo estratégica baseada em dados históricos.
Com o grande aumento de dados gerados e armazenados nas empresas, torna-se necessário o uso mais eficiente destes dados, gerando informaçőes consistentes e consolidadas para auxiliar na tomada de decisăo. As micro e pequenas empresas năo utilizam sua informaçăo em massa, disponíveis em suas bases de dados, e geralmente utilizam sistemas computacionais para as operaçőes básicas da empresa onde somente poucos relatórios săo disponibilizados. Para uma maior vantagem competitiva, e para se manter no mercado, cada vez mais as empresas săo obrigadas a utilizarem as informaçőes armazenadas gerando conhecimento e se destacando entre seus concorrentes.
Diante deste contexto o projeto proposto tem como objetivo utilizar a tecnologia como meio de processamento e facilitar o entendimento das informaçőes no contexto dos negócios, através do desenvolvimento de uma ferramenta para a construçăo de DW -Data Warehouse de forma dinâmica e a extraçăo e sumarizaçăo de informaçőes operacionais contidas em bancos de dados estruturados, aplicando regras de negócio específicas para armazenar estas informaçőes em um repositório específico, ou seja, um Data Warehouse que servirá de base para apresentaçăo destas informaçőes em forma de gráficos e indicadores auxiliando os empreendedores na tomada de decisăo.
No projeto foi desenvolvida uma aplicaçăo ETL (Extract Transform and Load) com a criaçăo do DW e geraçăo dos scripts para a obtençăo dos dados da empresa, possibilitando a criaçăo dinâmica do DW baseado na necessidade e disponibilidade de informaçőes contidas na base de dados operacional da organizaçăo. Além disto, é possível realizar a execuçăo dos scripts para a extraçăo dos dados da fonte selecionada e a criaçăo de cubos de decisăo baseado no DW construído, bem como a visualizaçăo das informaçőes através de gráficos e indicadores, ou seja, desenvolvimento de ferramenta BI.
BI (Business Inteligence, ou Inteligęncia de Negócios), é um conjunto de conceitos e métodos para auxiliar e aumentar a capacidade de tomada de decisăo das organizaçőes, fazendo uso de acontecimentos (fatos).
Segundo Barbieri (2001), BI “representa a habilidade de se estruturar, acessar e explorar informaçőes, normalmente guardadas em DW/DM (Data Warehouse/Data Mart), com o objetivo de desenvolver percepçőes, entendimentos, conhecimentos, os quais podem produzir um melhor processo de tomada de decisăo”
SAD (Sistemas de Apoio ŕ Decisăo) ou DSS (Decision Support Systems) săo sistemas computacionais que fornecem informaçőes e contribuem para o processo de tomada de decisăo. Permite a realizaçăo de cálculos, projeçőes e análises por meio de gráficos comparativos.
Segundo Inmon (1997), os Sistemas de Apoio ŕ Decisăo (SAD), tiveram início na década de sessenta, onde o processamento e análise eram realizados em aplicaçőes baseados em relatórios, porém, com o passar dos anos, o volume dos dados foi crescendo e a tarefa de análise tornou-se complexa e trabalhosa.
Data Warehouse é um sistema computacional que através de transaçőes e processos realiza cópia de informaçőes registradas nos bancos de dados das organizaçőes reorganizando estas informaçőes e preparando-as para a realizaçăo de consultas, relatórios e análises. Ou seja, trata-se de um armazém de dados extraídos das bases operacionais que suprirá a necessidade das regras para criaçăo de visőes estratégicas e gerenciais para a alta administraçăo.
Segundo Inmon (1997, p. 33), [...] “Data warehouse é um conjunto de dados baseado em assuntos, integrado, năo-volátil, e variável em relaçăo ao tempo, de apoio ŕs decisőes gerenciais" [...].
Para Inmon (1997), a construçăo de um DW pode conter algumas características mencionadas abaixo:
Outra característica importante no projeto de um DW é a granularidade, nível de detalhamento nos dados. Quanto mais baixo o nível de detalhamento mais baixo, será o nível de granularidade e quanto menos detalhes, mais alto o nível de granularidade. A granularidade nos primeiros sistemas operacionais era tida como certa, pois quando os dados eram atualizados, certamente seria ao mais baixo nível de granularidade sendo que no ambiente de DW, a granularidade năo é um pressuposto (INMON, 1997).
ETL (Extract, Transform and Load) ou Extraçăo, Transformaçăo e Carga destina-se ŕ extraçăo, transformaçăo e carga dos dados de uma ou mais bases de dados de origem para uma ou mais base de dados de destino (Data Warehouse). Este processo é o mais crítico e demorado na construçăo de um DW, pois consiste na extraçăo de dados de bases de dados heterogęneas, transformaçăo e limpeza destes dados e a realizaçăo da carga destes dados no DW.
As decisőes gerenciais serăo tomadas baseadas nas informaçőes geradas pela ferramenta e armazenadas no DW sendo, portanto, que os dados devem representar a verdade, a mais pura verdade, nada mais que a verdade (KIMBAL, 1998). A maior parte do esforço exigido no desenvolvimento de um DW é consumido, e năo é incomum que oitenta por cento de todo o esforço seja empregado no processo de ETL, (INMON, 1997).
De acordo com Kimball (1998), somente a extraçăo dos dados leva mais ou menos sessenta por cento das horas de desenvolvimento de um DW. Esta parte do processo é responsável pela busca das informaçőes importantes nas bases de dados de fontes externas que estejam em conformidade com DW. Esta busca pode ser obstruída por problemas devido ŕs diversas plataformas diferentes gerando a demanda de utilizaçăo de formas de extraçăo diferentes para cada local.
Após a extraçăo dos dados, temos a transformaçăo deles, a limpeza, a correçăo de possíveis erros de digitaçăo, a descoberta de violaçőes de integridade, a substituiçăo de caracteres desconhecidos, a padronizaçăo e a abreviaçăo dos dados (GONSALVES, 2003).
Segundo Kimball (1998), as principais características para garantir a qualidade dos dados săo:
O termo OLAP (Online Analytical Processing) pode ser interpretado com diversos significados, pois a sua tecnologia encontra-se presente em várias camadas como, por exemplo: armazenamento, acesso, compiladores, linguagem e conceitos. Pode-se falar em conceitos OLAP, linguagens OLAP, camadas de produtos OLAP e produtos completos OLAP (THOMSEN, 2002).
OLAP é ferramenta de BI (Business Inteligence) utilizada para apoiar as empresas na análise de suas informaçőes, sendo formado por uma ou mais ferramentas com a finalidade de acesso e análise de dados ad hoc com o objetivo de transformar os dados armazenados no Data Warehouse em informaçăo capaz de dar suporte ŕ tomada de decisăo da alta administraçăo por meio de interfaces amigáveis e de fácil manipulaçăo.
OLTP (OnLine Transaction Processing), ou processamento de transaçőes on-line, năo săo apropriados para Data Warehouses, isto porque, năo podem armazenar dados históricos, năo atendem satisfatoriamente a consultas e recuperaçăo rápida de grande volume de informaçőes.
Ao contrário da OLTP, OLAP oferece grande potencial de análise e recuperaçăo de informaçőes de forma rápida e fácil, provendo um acesso seguro aos dados corporativos de um Data Warehouse, provendo ainda muita flexibilidade existente em programas dedicados ŕ análise de dados.
Na projeçăo de bases de dados para Data Warehouse, devemos quebrar o paradigma da eliminaçăo de redundância, buscando realizar um armazenamento histórico. Porém é necessário tomar cuidados para que esta redundância năo prejudique o projeto aumentando seu custo com armazenamento ou manutençăo.
No Esquema Estrela, as instâncias săo armazenadas em uma tabela principal contendo o identificador da instancia, valores das dimensőes descritivas para cada instância e valores dos fatos, ou medidas. Pelo menos uma tabela é usada para cada dimensăo, armazenando os dados correspondentes aos dados encontrados na coluna referente ŕquela dimensăo na tabela de fatos (MACHADO, 2002). Sua composiçăo parte por uma tabela dominante, chamada de tabela de fatos, no centro e em volta, cercada por tabelas auxiliares, chamadas de tabelas de dimensăo. A tabela de fatos conecta-se ŕs demais tabelas através de múltiplas junçőes.
Com base na fundamentaçăo teórica e com a percepçăo da necessidade atual do mercado em foco, foi desenvolvida uma ferramenta de BI que permite desde o processo de criaçăo do DW até a visualizaçăo gráfica das informaçőes sumarizadas e organizadas. O processo de criaçăo do DW ocorre de forma simples e dinâmica, sendo necessário apenas o conhecimento na fonte de dados de origem e nas regras de negócio a serem abordadas para a criaçăo dos cubos de análise.
A tela principal da aplicaçăo possibilita ao usuário realizar a construçăo de um DW ou realizar a conexăo com um DW já existente. Com uma interface amigável e intuitiva, o usuário facilmente poderá realizar as operaçőes disponíveis na aplicaçăo.
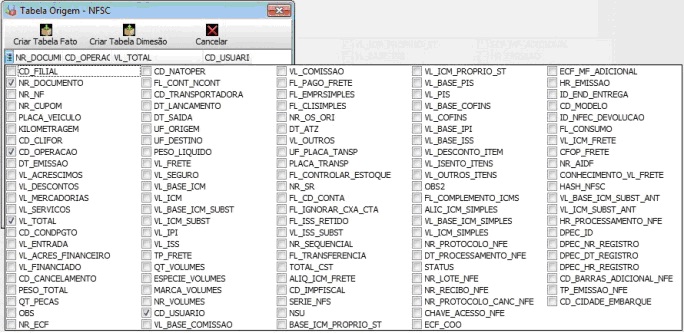
Para iniciar a criaçăo de um DW, é necessário possuir uma conexăo com uma base de dados de origem cadastrada. Após conectado a uma base de dados de origem, pode-se iniciar a construçăo do DW, partindo pela criaçăo da tabela fato. Para isso, o usuário deve dar duplo clique sobre a tabela origem desejada. Em seguida conforme ilustra a Figura 1, será exibida tela com todos os campos disponíveis na tabela. O usuário, baseado no fato a ser criado, irá marcar os campos necessários para a extraçăo dos dados.
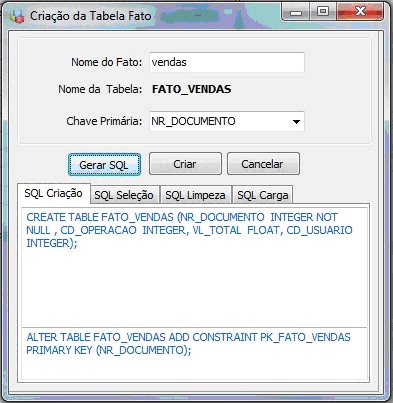
Após clicar em Criar Tabela Fato, será exibida uma tela conforme Figura 4, para indicar o nome do fato e a chave única da tabela a ser criada. Ao clicar no botăo Gerar SQL, serăo criados automaticamente os SQLs necessários para montar a estrutura do DW. A Figura 1 ilustra a visualizaçăo dos SQLs gerados para o processo de criaçăo da tabela, de seleçăo dos dados, de limpeza, e de carga.
O processo de criaçăo dos scripts ocorre através de métodos implementados na aplicaçăo realizando o tratamento dos dados e dos seus tipos, possibilitando a integraçăo deles de forma consistente e segura. Para a normalizaçăo dos dados foi criado método para obter o tipo de dado original da tabela origem e transformá-lo em um tipo único, facilitando a manipulaçăo e tratamento das informaçőes.
No exemplo foram criados os seguintes scripts SQL para a tabela fato vendas:
Basta clicar em criar para que os scripts de criaçăo da tabela sejam executados e que as informaçőes referentes ŕ tabela fato sejam gravadas na base de dados do projeto DW em questăo. A tabela será criada imediatamente no DW assim que executados os scripts. Da mesma maneira que foi criada a tabela fato anteriormente, a tabela dimensăo segue o mesmo conceito, porém ao invés de clicar em Criar Tabela Fato, será clicado em Criar Tabela Dimensăo. Ao clicar em gerar SQL, serăo gerados todos os scripts de SQL necessários para criaçăo da tabela dimensăo, bem como suas ligaçőes com a tabela fato correspondentes e seus scripts de seleçăo, limpeza e carga de dados para o DW.
Durante o processo de criaçăo das tabelas do DW, săo criados também em tempo de execuçăo e dinamicamente os scripts para a criaçăo dos cubos baseado nas estruturas dos fatos criados através da utilizaçăo dos metadados das tabelas. A Figura 3 demonstra o script montado.
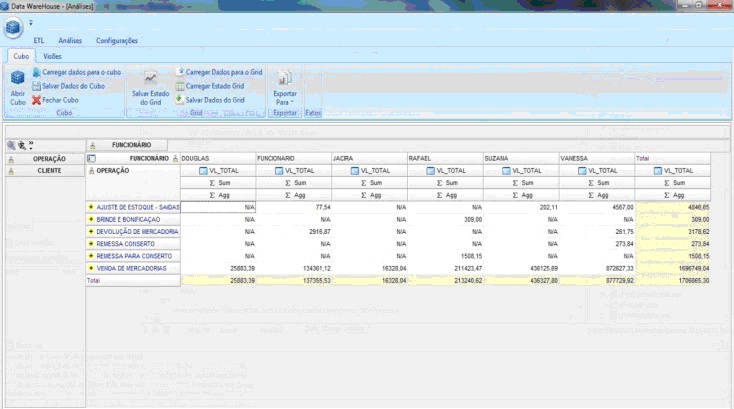
Com os dados agora carregados no DW, podemos realizar as análises deles, organizando, sumarizando, agrupando as informaçőes a fim de obtermos conhecimento sobre elas de forma rápida e fácil. Baseado nos modelos criados anteriormente, a Figura 4 demonstra uma análise criada com base no fato vendas, onde podemos observar o montante de vendas por operaçăo de vendedor.
Nesta tela serăo realizadas todas as fases de análise e criaçăo dos cubos. Podemos observar os menus que nos dăo a possibilidade de carregar um cubo já criado e salvar, além de salvar o grid ou somente as suas informaçőes, carregar um grid salvo, entre outras. Podemos exportar também esta informaçăo para diversos formatos como: pdf, Excel, BMP e HTML.
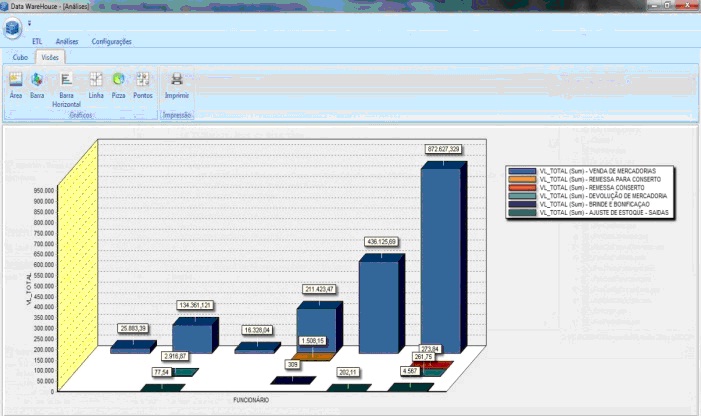
Conforme forem criados os cubos podemos utilizar forma visual para facilitar e ajudar no processo de entendimento da informaçăo. A Figura 5 demonstra o modo visual através do gráfico de barras do cubo criado anteriormente, sendo que podemos selecionar diversos formatos de gráficos para a exibiçăo das informaçőes, como: gráfico de barras, pizza, linha, barra horizontal, pontos entre outros.
Com o crescente uso de tecnologias para auxiliar as empresas na execuçăo de seus processos operacionais, que realizam o armazenamento de milhares de informaçőes históricas referente ŕs suas transaçőes, identificamos claramente a necessidade de abstrair estas informaçőes operacionais, transformando-as em conhecimento com a aplicaçăo de regras específicas possibilitando um melhor entendimento desta grande massa de dados. Com isso poderemos criar uma perspectiva de visăo sobre estes dados históricos auxiliando diretamente as decisőes estratégicas das organizaçőes antecipando as mudanças do mercado, as açőes dos competidores, identificaçăo de novos potenciais e uma melhor preparaçăo da organizaçăo para atender o mercado.
Observando a situaçăo atual das micro e pequenas empresas com pode-se perceber que apesar de existirem algumas ferramentas semelhantes, elas acabam por năo chegarem a este mercado, pelo seu alto custo e complexidade de implantaçăo e utilizaçăo. Com isso, foi possível perceber que podemos abranger uma grande massa de companhias oferecendo a elas năo apenas a ferramenta, mas também a construçăo do seu Data Warehouse aplicado ŕ sua necessidade específica.
Visto ŕ necessidade de se lançar ŕ frente da concorręncia no mercado, a posse e interpretaçăo das informaçőes é um dos principais fatores que contribuem para um desempenho melhor de uma organizaçăo.
Todo o processo de pesquisa realizado resultou na possibilidade de interpretaçăo dos dados armazenados através da ferramenta que disponibiliza a visualizaçăo das estruturas proprietárias permitindo a criaçăo do DW e aplicando a ETL, no formato de construçăo das tabelas de fatos e dimensőes de forma automatizada. O presente projeto também se apresenta com grande valia para o aprendizado e conhecimento de novos conceitos para a manipulaçăo e transformaçăo de dados em informaçăo, gerando conhecimento para auxiliar na tomada de decisăo.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.