Integrando o ERwin ao SGBD Adabas - Parte 01
Design em Camadas das Estruturas de Dados
por Gustavo Aguilar de Araújo
Desde os primórdios dos sistemas computacionais baseados em banco de dados, os modelos de dados constituem um recurso poderoso para a documentaçăo e para o projeto das estruturas de armazenamento das informaçőes. Em um primeiro momento, o Modelo de Entidades e Relacionamentos (Modelo ER), concebido com base nas regras de negócio e requisitos de informaçőes levantadas, provę o entendimento do “problema” e do seu respectivo contexto. Posteriormente, este modelo é utilizado para a geraçăo do Modelo de dados Lógico (Relacional), onde deve-se considerar as particularidades do Sistema Gerenciador de Banco de Dados (SGBD). Por conseguinte, o modelo lógico é utilizado para a criaçăo do esquema físico no banco de dados.
Avaliando rapidamente este fluxo, fica clara a necessidade de uma ferramenta que automatize e integre as várias etapas deste processo de Modelagem em Camadas das Estruturas de Dados, peça fundamental no ciclo de desenvolvimento de sistemas baseados em banco de dados. No aspecto tocante a modelagem de dados, existem ferramentas CASE que provęem tal agilidade e integraçăo. Apesar de CASE (Computer Aided Software Engineering) significar engenharia de software apoiada por computador, as ferramentas CASE săo largamente utilizadas em projetos de banco de dados. Neste sentido, deve-se dar preferęncia por ferramentas case de modelagem de dados que permitem ao usuário criar o modelo ER, criar o modelo de dados lógico, bem como gerar os respectivos scripts para a criaçăo física dos objetos no SGBD definido para o projeto.
A escolha do SGBD mais adequado para um determinado projeto năo é uma tarefa fácil, pois ele deve adequar-se năo só tecnicamente e funcionalmente, mas também comercialmente. As opçőes săo inúmeras. Atualmente, existe uma abundância de SGBD’s disponíveis no mercado, sejam eles gratuitos ou comerciais, cada um com seu(s) propósito(s), limites, características e aplicabilidade. A lista é extensa, contendo SGBD’s populares como Oracle, SQL Server, MySQL, Sybase, PostgreSQL, Firebird, SGBD orientado a objetos como o Caché da InterSystems, banco de dados XML como o Tamino da Software AG, SGBD’s voltados para Data Warehouse, como o Teradata, bancos de dados para mainframe como o ADABAS, também da Software AG, e o DB2 da IBM, dentre outros.
Avaliando esta lista de SGBD’s, imagina-se também o desafio para desenvolver uma ferramenta case que dę suporte a todos eles. Desafio tăo grande, que superá-lo se torna uma tarefa muito inviável, mas năo impossível. Inviável do ponto de vista técnico, dadas as particularidades de cada SGBD e das suas respectivas versőes; do ponto de vista da manutençăo da ferramenta diante da complexidade da soluçăo, do vasto conhecimento necessário nos diversos SGBD’s pelos profissionais desenvolvedores, e da possibilidade do surgimento de novos SGBD’s. Inviável também do ponto de vista comercial, pois seria uma ferramenta cara, dado o alto custo de desenvolvimento.
Avaliando o conjunto de ferramentas case existente e suas particularidades, conclui-se que em raras situaçőes, os fabricantes optam por construir uma ferramenta case proprietária, ou seja, específica para um determinado SGBD. Neste segmento, está, por exemplo, o Oracle Designer da Oracle.
Na tentativa de evitar um alto custo de desenvolvimento, e tentando atingir o maior número de usuários possíveis, os fabricantes adotam determinada estratégia onde elege-se os principais SGBD’s da atualidade e desenvolve-se uma ferramenta case nativamente compatível com estes bancos de dados. Neste ramo estăo, por exemplo, o AllFusion ERwin Data Modeler da Computer Associates, o Power Designer da Sybase, o System Architect da Popkin Software, Case Studio da Charonware, o ER Studio da Embarcadero Technologies, etc. No entanto, esta estratégia pode ser um problema para o usuário, pois o que fazer quando a ferramenta case năo dá suporte ŕ todos os bancos de dados utilizados na empresa?
Nesta situaçăo, considerando que seja primordial uma integraçăo entre a ferramenta case e o SGBD, pode-se dizer que existam basicamente quatro opçőes:
1) Adquirir outra ferramenta case compatível com o SGBD em questăo: implica em custos na aquisiçăo de uma nova ferramenta e treinamento, além de dificultar a manutençăo dos padrőes, metodologias e modelos de dados da empresa com a existęncia de duas ferramentas case corporativas;
2) Solicitar ao fabricante da ferramenta o desenvolvimento da interface nativa com o SGBD desejado: nem sempre é interesse do fabricante desenvolver esta interface, ficando a resoluçăo do problema dependente de outros fatores năo técnicos, como os já citados na inviabilidade para a construçăo da ferramenta case que suporte todos SGBD’s;
3) Substituir o SGBD năo suportado: pode implicar em um grande investimento para migrar o banco de dados e alterar os sistemas que acessem este SGBD;
4) Utilizar recursos da ferramenta case que viabilizem a integraçăo com o SGBD em questăo: requer um conhecimento avançado da ferramenta case, e pode necessitar de uma pequena camada de aplicaçăo entre o banco de dados e a ferramenta case para prover a integraçăo. Também gera custos, mas de menor grandeza, pois năo envolve compra de uma nova ferramenta case.
Neste artigo, será mostrada a aplicabilidade da quarta opçăo, onde viabiliza-se a integraçăo entre a ferramenta case AllFusion ERwin Data Modeler (versăo 4.1.4) e o SGBD ADABAS (versăo 7.4.2) para mainframe, que năo é suportado nativamente pelo ERwin.
O ERwin é uma ferramenta case específica para modelagem de dados relacional ou dimensional, fornecido pela Computer Associates. No portal da SQL Magazine (//www.devmedia.com.br/visualizacomponente.aspx?comp=1802&site=2), está disponível um artigo que fornece uma visăo geral do ERwin. Já o ADABAS (ADAptable data BASe) é um banco de dados multi-thread de alta performance, escalabilidade e disponibilidade, produzido pela Software AG (http://www.softwareag.com) e distribuído no Brasil pela Consist (http://www.consist.com.br).
Para demonstrar esta integraçăo, serăo expostas funcionalidades avançadas do ERwin, conceitos básicos do banco de dados ADABAS e de algumas tecnologias utilizadas no processo de comunicaçăo entre as plataformas distribuída e mainframe. O foco năo é detalhar os programas que participam do processo, mas simplesmente demonstrar a possibilidade de se criar uma soluçăo de modelagem de dados completa para sistemas mainframe baseados em ADABAS utilizando o ERwin, bem como servir de referęncia para situaçőes problemáticas semelhantes, onde há um SGBD năo suportado por determinada ferramenta case.
Esta soluçăo tem como princípio básico o conceito de design em camadas, contemplando desde a modelagem conceitual até a criaçăo física dos objetos. Tem como objetivo fornecer agilidade, qualidade, integridade e interligaçăo das etapas de um projeto de banco de dados.
A soluçăo foi concebida e especificada pela Administraçăo de Dados do Grupo Telemar, implementada em parceria com a Consist Brasil, com o apoio técnico da equipe de Administraçăo de Banco de Dados ADABAS, também do Grupo Telemar. De uma forma geral, a soluçăo consiste basicamente em criar o modelo ER no ERwin, derivar o modelo relacional a partir deste modelo, e utilizar o processo de integraçăo e conversăo para criar o esquema físico no banco de dados. A Figura 1 mostra este processo de uma forma macro.
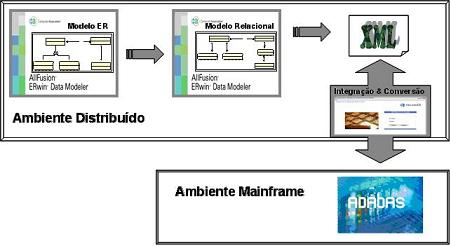
Figura 1. Visăo macro do processo de modelagem de dados para banco de dados Adabas com o ERwin.
Estudo de Caso
Para auxiliar no desenvolvimento do assunto, será feito um pequeno estudo de caso baseado em um sistema para controle de uma biblioteca. Para simplificar, neste sistema, deseja-se apenas:
- Cadastrar os usuários da biblioteca com os telefones para contato;
- Cadastrar as obras disponíveis para empréstimo (livros e artigos) e seus respectivos exemplares e ediçőes;
- Cadastrar o assunto da obra (no máximo 3);
- Cadastrar o(s) autor(es) e editoras das obras;
- Registrar os empréstimos e devoluçőes das obras;
- Registrar reservas de obras (limite de 5 reservas ativas para um mesmo usuário);
- Consultar a situaçăo dos exemplares existentes.
Primeira Etapa – A Criaçăo do Modelo de Entidades e Relacionamentos
O ERwin permite criar tręs tipos de modelos de dados: Logical Model, que possibilita a criaçăo do modelo de entidades e relacionamentos; Physical Model, que possibilita a criaçăo do modelo relacional específico para um determinado SGBD; e o Logical/Physical, que possibilita a criaçăo conjunta, em um mesmo modelo do ERwin, do modelo ER e do Relacional. Apesar dos dois primeiros tipos de modelos serem criados separadamente, eles podem ser sincronizados utilizando-se os recursos de design em camadas existentes no ERwin.
Para demonstrar a viabilidade do design em camadas no ERwin, foi criado inicialmente, um modelo de dados ER no ERwin do tipo logical model, mostrado na Figura 2. Nesta primeira etapa, é fundamental abstrair as reais necessidades do usuário năo preocupando-se em nenhum momento com os detalhes de implementaçăo física do modelo de dados. Deve-se definir as entidades necessárias, os relacionamentos existentes entre elas, os atributos das entidades, o domínio dos atributos (string, numérico, data, etc.), sem esquecer da documentaçăo da funcionalidade de cada componente do modelo.
OBS: quando se trabalha com o ERwin, é importante năo confundir seu “Logical Model” com o conceito de Modelo Lógico Relacional da Teoria de Banco de Dados.
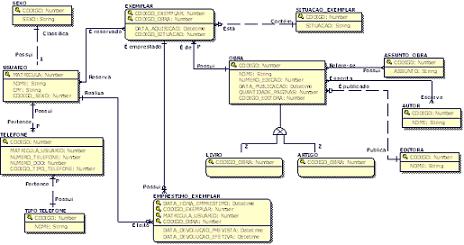
Figura 2. Modelo de Entidades e Relacionamentos para o Sistema de Biblioteca proposto.
Finalizado o modelo ER, passamos entăo para a próxima etapa, onde é construído o modelo relacional considerando-se as peculiaridades do SGBD escolhido. Para isto, alguns conceitos básicos sobre o ADABAS tornam-se necessários.
Conceitos Básicos do ADABAS
O ADABAS (ADAptable data BASe), como o próprio nome sugere, é um SGBD adaptável ŕ estrutura de modelo de dados que deseja-se implementar. Dentre elas, podemos citar a estrutura relacional, hierárquica, geográfica ou de rede.
Como todo SGBD, o ADABAS possui um Dicionário de Dados, chamado Predict, onde săo armazenados os metadados, ou seja, as informaçőes acerca dos objetos criados, tais como o nome do objeto, o tipo de dados dos campos, a descriçăo dos campos, etc.
Na soluçăo apresentada, toda interface com o ADABAS será feita através do seu dicionário de dados. Isto implica que, antes do objeto ser implementado fisicamente no SGBD, ele será criado primeiramente no Predict. Assim sendo, algumas etapas da soluçăo desenhada fazem mençăo ao Predict, visto que, estando o objeto criado no dicionário de dados, sua geraçăo física no ADABAS se torna trivial.
No ADABAS, existem dois tipos principais de estruturas de armazenamento e acesso a dados: Files e Userviews. Files (ou arquivos) săo estruturas tabulares, análogas ao conceito de tabelas em outros SGBD’s, para armazenamento de registros (linhas de dados). Estes files săo compostos por um ou mais Field (campo ou coluna), cada um com seu respectivo Datatype (tipo de dados). Já a userview, tem como objetivo restringir o acesso de um determinado usuário aos campos de um determinado file, ou seja, trata-se de uma camada lógica de acesso ao file, uma visăo do usuário. A Figura 3 ilustra a idéia destes 2 tipos de objetos.
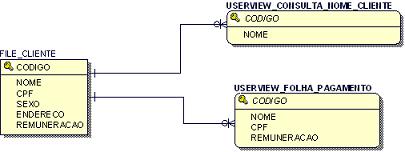
Figura 3. Files e Userviews.
Para determinar o tipo do objeto, ou seja, se ele é um file ou uma userview, o Predict utiliza uma propriedade denominada Type. Um objeto do tipo file, possui type igual a Adabas file. Uma userview possui esta propriedade igual a Adabas userview. Além desta, um file Adabas possui várias outras propriedades, tais como:
- File ID: nome do file que identifica unicamente o objeto no Predict, limitado a 32 caracteres.
- Abstract: descriçăo resumida do file, com no máximo 480 caracteres, geralmente utilizada para descrever brevemente a funcionalidade de um determinado file.
- Extended Description: descriçăo extensa do file, armazenando mais de 20.000 caracteres. Utilizada para descriçőes maiores e mais detalhadas da funcionalidade de um determinado file.
- Database: banco de dados onde o file está criado. Uma instalaçăo do ADABAS (versăo 7.4.2) permite a criaçăo de até 65.535 bancos. Cada banco pode ter até 5.000 files, e é identificado fisicamente por um número (PDBnr – physical database number).
- File number: número do file, que o identifica de forma única em um determinado database.
- Owner: proprietário do file. Pode ser um usuário, um departamento, etc.
- Keyword: palavra chave do file. A utilizaçăo deste recurso é bem ampla, mas pode ser utilizado por exemplo, para informar ŕ qual(is) sistema(s) um determinado file pertence.
Já as userviews, săo criadas a partir de um file Adabas, que neste contexto denomina-se Master file da userview. Com exceçăo da propriedade file ID, que deve ser o nome único da userview, as demais propriedades (database, file number, abstract, extended description, owner e keyword) săo herdadas do master file. Dentre estas propriedades, database e file number devem ser obrigatoriamente iguais aos do master file. As demais podem ser customizadas diretamente na userview.
Para criar um bom modelo de dados lógico para o ADABAS, deve-se conhecer também os tipos de campos que um file/userview pode ter e suas características fundamentais. Assim como em outros SGBD’s, um campo possui um nome (Field ID), possui um formato (Field Format) para os dados (alfanumérico, binário, decimal, float, etc.) e tamanho máximo (Length) aceito pelo campo. Além destas propriedades básicas, também deve-se definir as seguintes características de um campo de file Adabas/userview:
- Field Type (Ty): especifica o tipo do campo (năo confundir com Field Format, que é o tipo de dados aceito pelo campo). Os tipos mais utilizados săo:
· Normal field: também chamado de campo elementar (Elementary Field), é utilizado nos casos onde năo necessita-se do comportamento provido pelos demais tipos, como mostra a Figura 4.
· Group (GR): campo grupo, que permite agrupar um conjunto de campos. Para endentar este agrupamento, utiliza-se a propriedade Field Level (L), que informa o nível do campo. Com isto, o campo grupo possuirá nível sempre maior do que o nível dos campos que o compőe. Na prática, quando selecionamos o campo grupo, săo exibidos os valores dos campos que o compőem. A Figura 4 mostra um exemplo de um campo do tipo grupo.
OBS: é permitido definir grupos com até sete níveis.
· Multiple Value Field (MU): campo múltiplo que repete determinado número de vezes para um mesmo registro (linha) do file. Fazendo uma analogia, este campo representa um relacionamento 1xN dentro de cada registro de um mesmo file, ou seja, trata-se de uma desnormalizaçăo onde năo há a necessidade de se repetir a linha toda para cada valor do campo repetitivo. A Figura 4 mostra um exemplo de um campo do tipo múltiplo.
· Periodic Group (PE): grupo periódico que une os conceitos de grupo e múltiplo, permitindo que um conjunto de campos ocorra determinado número de vezes para um mesmo registro do file.
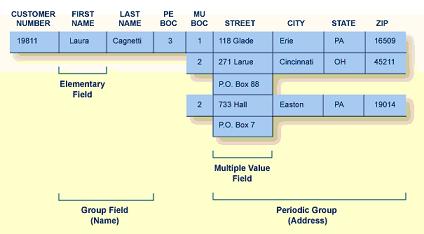
Figura 4. Tipos de campos elementar, grupo, múltiplo e grupo periódico.
· Superfield (SP): “super-campo”, que permite criar um campo composto por outros campos e/ou partes de outros campos. É sempre composto por no mínimo dois campos ou duas partes de campos.
· Subfield (SB): “sub-campo”, que permite criar um campo composto por um campo ou por uma parte de um campo.
As demais propriedades de um field săo:
- Occ (Número de Ocorręncias): propriedade de campos múltiplos e de grupos periódicos que informa a quantidade de vezes que o campo se repete para um único registro do file. O valor máximo na atual versăo, é de 191 ocorręncias.
- Unique Option (U): propriedade que indica a unicidade dos valores do campo.
- Field Suppression(S): serve para indicar a opçăo de compressăo do campo ou para indicar a representaçăo de campo nulo ou requerido (campo NOT NULL). Esta propriedade visa a otimizaçăo da utilizaçăo do espaço em disco consumido pelo campo.
- Short Name(DB): nome físico do campo utilizado internamente pelo ADABAS para acessá-lo. Este nome trata-se de um valor alfanumérico de 2 posiçőes, sendo que de E0 até E9 săo short names reservados para uso do banco. Este short name năo se repete dentro de um mesmo file.
- Descriptor Type(D): campos que possuem esta propriedade igual a D Descriptor/Index funcionam como campos descritores, que nada mais săo que índices simples de pesquisa. Para definir um índice composto de pesquisa, ou um índice de pesquisa composto de parte(s) de campo(s), utiliza-se a combinaçăo desta propriedade com a propriedade field type (SP ou SB), permitindo-se criar campos superdescritores ou subdescritores.
Ř Superdescritor: Superfield + Descritor. Este tipo de campo possui a propriedade field type igual a SP e a propriedade descriptor type igual a D.
Ř Subdescritor: Subfield + Descritor. Este tipo de campo possui a propriedade field type igual a SB e a propriedade descriptor type igual a D. Composto por apenas um campo ou apenas uma parte de um campo.
OBS: os campos que săo apenas superfield ou subfield e que năo săo descritores, năo podem ser utilizados como critério de busca.
De posse destes conceitos básicos, ficará plausível o entendimento da soluçăo dada para o modelo de dados lógico do Sistema de Controle de Biblioteca proposto, tendo como foco o SGBD ADABAS.

