Integrando o ERwin ao SGBD Adabas – Parte 02
Design em Camadas das Estruturas de Dados
por Gustavo Aguilar de Araújo
Segunda Etapa – A Criaçăo do Modelo Relacional
Nesta etapa, surge o primeiro problema: como criar um modelo para o ADABAS no ERwin, se ele năo é compatível com este SGBD? E se ele năo é compatível, como será especificado o formato dos dados dos campos dos files? Como serăo especificadas as propriedades dos files e userviews?
Eis entăo que “surge” o recurso salvador do ERwin: UDP. UDP (User Defined Properties) é um recurso com o propósito de prover documentaçăo extra, permitindo a criaçăo de propriedades para vários tipos de objetos do ERwin, como por exemplo, tabelas, campos e relacionamentos. Por exemplo, pode ser criada uma UDP para tabelas, onde é possível fazer a identificaçăo da categoria de cada tabela (pequena, média, grande ou gigante). Estas UDP’s podem ser do tipo texto, inteiro, real, data, lista de valores, ou do tipo Command, que permite abrir um arquivo externo ao modelo de dados do ERwin (por exemplo, a especificaçăo funcional do sistema referente ao modelo de dados). Sendo assim, este recurso pode ser utilizado para resolver o problema de especificaçăo das propriedades que năo existem no ERwin para files e campos.
Antes de especificar quais UDP’s săo necessárias, deve-se esclarecer um ponto: para criar um modelo lógico para o SGBD ADABAS no ERwin, representar-se-á files como tabelas e userviews como views destas tabelas. Portanto, criaremos um file da mesma forma como criamos uma tabela, especificando o nome dele, seus atributos e (super/sub) descritores, com a particularidade de informar as características intrínsecas do ADABAS via UDP.
Para padronizar os modelos de dados e evitar retrabalho, é interessante criar um modelo padrăo no ERwin, chamado de template, do tipo physical model, que já contenha toda definiçăo de UDP’s. Neste sentido, para definiçăo das propriedades dos files/userviews, foram criadas no template, as UDP’s mostradas na Figura 5.
OBS: estas UDP’s năo necessitam ser criadas no modelo ER, pois săo propriedades físicas do modelo de dados.
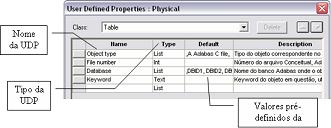
Figura 5. UDP’s definidas para objetos do tipo Table (files e userviews).
Note, por exemplo, que a UDP Database foi definida com o tipo (coluna Type) lista, o que permite definir previamente o conjunto de databases válidos para seleçăo, utilizando-se a coluna Default.
Analogamente, também devem ser definidas as UDP’s para representar as propriedades dos campos dos files e userviews do modelo de dados. A Figura 6 mostra a lista de UDP’s criadas para esta documentaçăo.
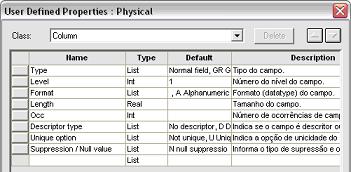
Figura 6. UDP’s definidas para os campos (column) dos files/userviews.
Dica: no ERwin, para criar ou visualizar as UDP’s definidas, utiliza-se a opçăo de menu Model, UDP Dictionary.
Estando o template definido, pode-se iniciar a construçăo do modelo lógico utilizando-se do do recurso de derivaçăo de modelos do ERwin. Com este recurso é possível criar automaticamente o modelo lógico a partir do modelo ER criado previamente. Nesta derivaçăo, deve ser utilizado o template criado para que todas as UDP’s já estejam disponíveis. A Figura 7 mostra o modelo lógico gerado para o exemplo do Sistema de Biblioteca, após derivaçăo feita a partir do Modelo ER, e após customizaçăo dos detalhes de implementaçăo física.
Dica: no ERwin, o recurso de derivaçăo de modelos é acessado através da opçăo de menu Tools, Derive New Model.
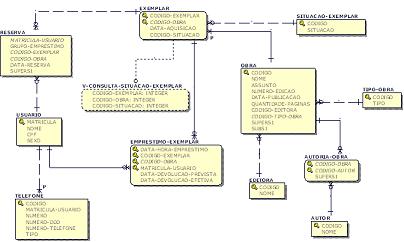
Figura 7. Modelo Lógico gerado a partir do Modelo de ER da figura 2.
Para demonstrar a documentaçăo de alguns recursos do ADABAS no ERwin, a soluçăo foi modelada desta forma, que năo necessariamente seja a melhor forma. Assim sendo, o modelo foi proposto de modo que:
· As propriedades dos files existentes no modelo foram definidas preenchendo-se as UDP’s de cada file, como mostra o exemplo da Figura 8;
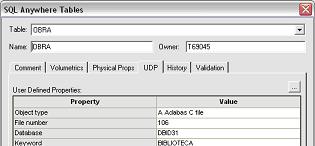
Figura 8. Propriedades do arquivo OBRA.
· Foi criada a userview V-CONSULTA-SITUACAO-EXEMPLAR, para permitir a consulta da situaçăo dos exemplares;
· Para files onde a chave única é composta por apenas um campo, definiu-se o campo chave como descritor único, como mostrado na Figura 9;
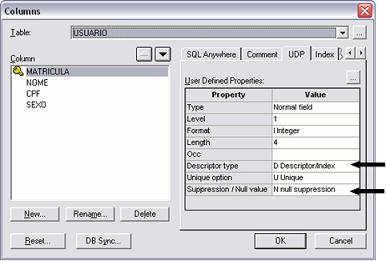
Figura 9. Campo MATRICULA do arquivo USUARIO definido como chave única.
· Para utilizar o conceito de grupo, foi criado o grupo NUMERO no arquivo TELEFONE, composto pelos campos NUMERO-DDD e NUMERO-TELEFONE;
· Para resolver o problema de limitaçăo das reservas para empréstimos futuros, feitas por um usuário, foi utilizado grupo periódico. Criou-se o campo GRUPO-EMPRESTIMO como periódico, contendo os campos CODIGO-EXEMPLAR, CODIGO-OBRA e DATA-RESERVA como mostra a Figura 10. Note que no exemplo, limita-se o número de ocorręncias deste grupo a 5 vezes (5 reservas), e atribui o nível 2 aos campos integrantes do grupo;
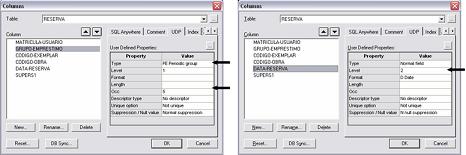
Figura 10. Campo periódico.
· Para demonstrar a utilizaçăo de múltiplo e permitir o cadastramento de no máximo tręs assuntos da Obra, definiu-se o campo ASSUNTO como um múltiplo de tręs ocorręncias, como mostrado na Figura 11.
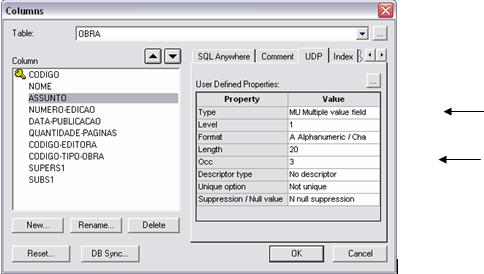
Figura 11. Campo múltiplo.
· Para arquivos onde a chave é composta por mais de um campo, foi criado um campo superdescritor único composto por estes campos, como mostrado na Figura 12. Perceba que para criar um superdescritor é preciso criar no file, o campo superdescritor, e depois definir os campos que fazem parte deste superdescritor. Esta definiçăo é feita na opçăo de criaçăo de índices no ERwin;
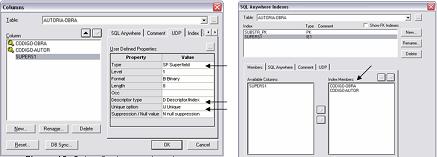
Figura 12. Definiçăo do superdescritor e seus campos no arquivo AUTORIA-OBRA.
· Campo subdescritor também é criado da forma acima, só que com Type = SB Subfield. Para definir a parte do campo que compőe o subdescritor, usamos UDP’s de índice. Para exemplificar, foi criado o campo subdescritor SUBS1 no arquivo OBRA, cujo membro é o campo NOME, que é uma string de 100 posiçőes. O intuito deste campo é permitir a pesquisa dos nomes das obras que comecem com uma determinada string de 10 posiçőes. Na Figura 13, é mostrada a definiçăo da composiçăo deste subdescritor.
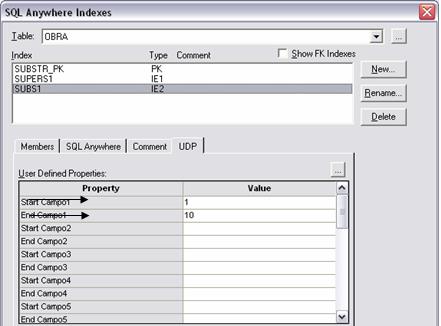
Figura 13. Definiçăo da composiçăo do subdescritor.
· Os comentários dos campos e arquivos săo inseridos na opçăo Comment do ERwin, como mostrado na Figura 14.
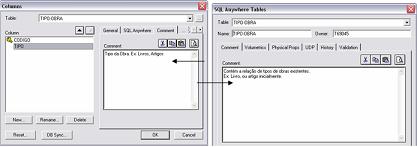
Figura 14. Definiçăo do comentário de campos e arquivos.
Assim sendo, verifica-se que é possível definir no modelo de dados do ERwin, todos os itens necessários para a criaçăo dos objetos no Predict. Perceba que até o momento, nenhum processo adicional foi desenvolvido. Caso năo deseje-se integrar o ERwin com o ADABAS do início ao fim, ou seja, da modelagem conceitual até a implementaçăo física, pode-se utilizar o modelo lógico gerado como base para a criaçăo manual dos objetos no Predict.
Como o objetivo proposto é integrar do início ao fim, vamos ŕ pergunta que năo quer se calar: “Como gerar o modelo de dados no SGBD, se o ERwin năo dá suporte para o ADABAS?
Surge entăo, o X da questăo: XML! O XML (eXtensible Markup Language) é uma linguagem de marcaçăo para páginas web, que tem como propósito principal, facilitar o compartilhamento de informaçőes. Caracteriza-se pela simplicidade e organizaçăo, separando o conteúdo do arquivo da formataçăo. Mais informaçőes sobre XML podem ser encontradas no endereço http://www.w3.org/XML/.
Valendo-se deste recurso, podemos gerar pelo ERwin um arquivo no formato XML que contenha, de forma estruturada, todas as informaçőes acerca dos objetos criados no modelo lógico, como mostrado na Listagem 1.
Listagem 1. Parte do XML gerado pelo ERwin com as informaçőes do modelo de dados.

Dica: para converter o modelo do ERwin para XML basta salvá-lo com o formato XML, utilizando o menu File, Save As, opçăo Salvar como XML Files.
Desta forma, com as informaçőes disponíveis e mapeadas, torna-se necessário o desenvolvimento de um pequeno processo para converter as informaçőes do formato XML, para o formato legível para o Predict/Adabas.
Terceira Etapa – A Conversăo do Modelo
Nesta etapa, começa-se a realizar efetivamente a integraçăo destes “dois mundos”, um tanto quanto diferentes. A soluçăo que pareceu mais viável e padronizada, foi gerar o modelo do ERwin no formato XML, de forma a permitir a leitura deste arquivo pelo processo que o converte em um arquivo seqüencial. Este arquivo seqüencial é gerado no formato aceito pelo SYSDICBE, que nada mais é que um utilitário do Predict utilizado para carga de dados, análogo ao SQL Loader da Oracle. A Figura 15 ilustra este fluxo.
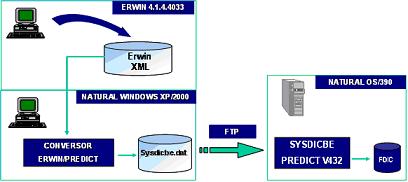
Figura 15. Conversăo do modelo de dados XML.
No processo de geraçăo do arquivo seqüencial, pode ser introduzido um middleware capaz de realizar trocas de mensagens online entre o ambiente distribuído e o ambiente mainframe, com o objetivo de realizar algumas consistęncias no modelo de dados. Dentre elas, poderia ser verificado se um determinado file que pretende-se gerar já encontra-se criado no Predict; se o número informado para um file está disponível para ser gerado, ou se determinada informaçăo (owner, keyword, database, etc) é válida. Esta preocupaçăo visa evitar ao máximo que erros aconteçam no servidor mainframe, prevendo-os no momento que o arquivo seqüencial é gerado e permitindo o acerto do modelo de dados ainda no lado cliente, ou seja, no ambiente distribuído.
Para auxiliar no processo de integraçăo, foi criada uma interface cliente, desenvolvida na linguagem Natural Windows 6.1.1. A partir desta interface consegue-se controlar todo o processo de geraçăo do modelo de dados, permitindo disparar o processo de leitura do arquivo XML, o processo de conversăo e o processo de carga.
A primeira tarefa é selecionar o arquivo XML gerado a partir do modelo de dados, para que seja possível visualizar os files e userviews, permitindo selecionar quais deles devem ser criados no Predict, como mostra a Figura 16.
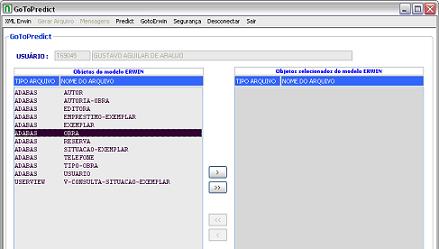
Figura 16. Interface para leitura do XML e seleçăo dos objetos que serăo criados no Predict.
A próxima tarefa é gerar o arquivo seqüencial com as definiçőes dos objetos selecionados. Na Listagem 2, é exibida uma parte do conteúdo deste arquivo seqüencial, gerado pelo processo conversor.
Listagem 2. Parte do arquivo seqüencial gerado no formato do SYSDICBE.
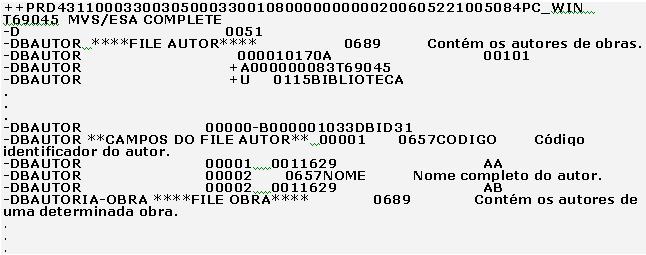
Com o arquivo seqüencial gerado, o próximo passo é efetuar o FTP deste arquivo, que encontra-se no ambiente distribuído, para o ambiente mainframe. No ambiente mainframe, assim que o arquivo seqüencial estiver disponível, um processo batch encarrega-se de acionar a carga das informaçőes dos files e userviews via SYSDICBE, que é o responsável pela criaçăo efetiva dos objetos no Predict.
Neste ponto, o middleware também pode ser útil para indicar o status do processo de FTP ou do processo de carga. Outra opçăo seria configurar este processo batch para enviar email ao término da carga dos objetos no Predict, informando se os files e userviews foram criados com sucesso ou năo. Como conseqüęncia de uma carga concluída com sucesso, tęm-se os objetos criados no Predict, como mostra a Figura 17.
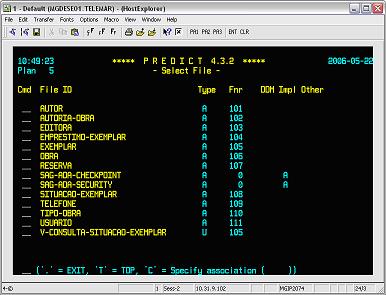
Figura 17. Objetos do modelo criados no Predict.
Na Figura 18¸ săo exibidas as propriedades dos campos do file OBRA, assim como elas estavam definidas no modelo de dados lógico no ERwin.
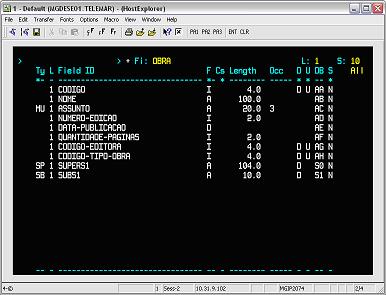
Figura 18. Definiçăo dos campos do arquivo OBRA.
Neste ponto, alguns podem estar se perguntando: “Mas a proposta inicial năo era de se integrar o ERwin com o ADABAS”? Exatamente! E esta integraçăo poderia ter sido feita diretamente com o SGBD, só que neste caso, os objetos năo estariam documentados no dicionário de dados do ADABAS, ou seja, no Predict. Por outro lado, estando os objetos criados no Predict, a implementaçăo física no ADABAS é feita através da execuçăo do comando Generate Adabas File. Executado este comando para a criaçăo física de cada objeto, chega-se ao ponto final do design em camadas das estruturas de dados para o Sistema de Controle de Biblioteca, feito do início ao fim de forma totalmente integrada.
Conclusőes
Peça fundamental no desenvolvimento de sistemas, o modelo de dados deve ser, sempre que possível, criado em etapas bem definidas, sendo que na etapa conceitual năo deve-se importar com os detalhes físicos de implementaçăo, que săo definidos na etapa de construçăo do modelo lógico. Para facilitar a criaçăo dos modelos de dados, provendo agilidade e integraçăo nas etapas do processo, o ideal é utilizar uma ferramenta case de qualidade.
Como existem inúmeros SGBD’s no mercado, é pouco provável que encontre-se uma ferramenta case compatível com todos estes bancos de dados. No entanto, deve-se sempre ter em mente que na maioria das vezes é possível prover esta compatibilidade. Primeiramente deve-se conhecer a fundo a ferramenta case em questăo para identificar as possibilidades de integraçăo e criar um processo confiável. Para que o processo seja íntegro, é preciso também conhecer bem o SGBD alvo da integraçăo, procurando implementar seus recursos e regras necessárias no modelo de dados lógico construído na ferramenta case.
No caso específico de modelagem de dados para sistemas baseados no SGBD ADABAS, analisando o processo explicitado do início ao fim, nota-se que há um grande ganho de tempo quando utiliza-se o recurso de derivaçăo de modelos no ERwin aliado ŕ integraçăo criada com o Predict. Sem eles, haveria muitos processos manuais sem conexăo, acarretando retrabalho. Com eles, consegue-se definir um fluxo que provę agilidade no processo de definiçăo e criaçăo das estruturas de dados, visibilidade da soluçăo antes de implementá-la, agregaçăo de qualidade ŕ soluçăo, além de facilitar o processo de manutençăo dos modelos de dados e do esquema físico gerado.
Conclui-se também que a mesma ideologia pode ser aplicada para o processo inverso, ou seja, para a Engenharia Reversa, que consiste em trazer para o modelo de dados os objetos criados fisicamente em um determinado SGBD, permitindo a documentaçăo do passivo. Com isto, sistemas que năo possuem os modelos de dados (ER e lógico) passariam a contar com este poderoso recurso para as alteraçőes emergentes de suas estruturas de dados.

