


Hoje em dia existe framework para quase tudo, desde o controle de migraçőes do banco de dados até gerenciadores de bibliotecas para o front-end. Daí quando vamos iniciar um projeto novo, ficamos horas tentando configurar tudo, deixando tudo alinhado, afim de integrar todos os frameworks. Dentro da comunidade Java já existem alguns projetos para facilitar esse pontapé inicial e dar o “bootstrap” na configuraçăo, dente os quais podemos citar o JBoss e o Spring Roo.
O JBoss Forge foi criado pela Red Hat no ano de 2011 e tem forte adoçăo pelos padrőes Java EE 6. Já o Spring ROO é um projeto do Spring, com lançamento em 2009, e é um dos seus pontos fortes é o trabalho com AspectJ: uma linguagem de programaçăo orientada a aspectos.
Correndo por fora para tentar chegar no topo e ganhar desses concorrentes, surgiu JHipster, que é scaffolding do Yeoman para gerar aplicaçőes baseada no Spring Boot e AngularJS.
Uma das principais singularidades entres essas tręs ferramentas é o uso baseado em linha de comando para a criaçăo de toda a estrutura do projeto. Essa tal criaçăo do projeto é chamada de scaffolding. Esse conceito vem da engenharia civil é tem o sentido de montar o “esqueleto” de um projeto. Entăo cada framework que foi citado é um scaffolding e cada um tem suas particularidades.
O JBoss Forge e o Spring ROO tem o próprio scaffolding. A Red Hat e a Spring criaram e fizeram a manutençăo deles, enquanto o JHipster é atualizado pela comunidade.
O Yeoman foi a escolha para fazer esse “esqueleto” dentro do JHipster, pois tem foco na comunidade front-end, pois gera toda a estrutura necessária, e faz seu trabalho tanto no back-end como no front-end. Além disso gera todas as classes Java e arquivos de configuraçőes necessários para o projeto.
Outro ponto relevante sobre essas ferramentas é a customizaçăo. É possível criar o projeto com vários tipos de setups diferentes, como Maven ou Gradle, Grunt ou Gulp, Banco relacional ou năo relacional, isso porque o JHipster conta com várias opçőes de tecnologia, tanto do lado do cliente quanto do servidor.
Dentro de todas essas ferramentas, esse artigo vai apresentar o framework juntamente com as seguintes opçőes:
Essas opçőes săo simplesmente para demostrar o framework por serem fáceis de mostrar, năo sendo é uma receita de bolo a ser seguida obrigatoriamente. Fique ŕ vontade para testar as outras opçőes que săo apresentadas na home do framework (vide seçăoLinks).
Repare que comentamos que o MySQL será usado para os dois ambientes do sistema. Isso porque o framework permite escolher bancos diferentes. Para esses casos é comum escolher o H2, que é um banco de dados mais simples para desenvolver e outro banco mais complexo para produçăo, como o MySQL, por exemplo. A escolha do mesmo banco para ambos é apenas para deixar os dois ambientes bem parecidos.
Outra vantagem que se deve levar em conta é a integraçăo para deploy em algumas nuvens conhecidas do mercado, como a AWS, Heroku, OpenShift, entre outras. Isso pode te ajudar a ter um ambiente em produçăo cada vez mais rápido.
Para otimizar ainda mais o desenvolvimento, o JHipster também oferece tręs tipos de “perfis” para sua rodar sua aplicaçăo:
Para entender melhor como funciona essa integraçăo, passaremos para as configuraçőes na prática. Veremos como é fácil integrar com poucos cliques. Configuraremos tudo em um ambiente Linux.
Para este artigo criamos uma máquina virtual para construir esse tutorial, entăo se algum momento vocę já tiver aquela ferramenta instalada no seu ambiente, vocę pode pular (por exemplo, se vocę já estiver com o node.js instalado, é bom pular essa parte).
Para iniciar precisamos instalar o servidor Node.js e o seu gerenciador de pacotes npm.
No momento da escrita desse artigo a versăo do node que está no repositório do Ubuntu é a 0.10, porém para rodar o projeto precisamos da versăo 0.12 ou superior, entăo primeiro vamos baixar a versăo certa a partir do site da própria, utilizando o comando a seguir no terminal:
curl -sL https://deb.nodesource.com/setup_0.12 | sudo bash -Em seguida instale usando o comando a seguir:
sudo apt-get install -y nodejsAgora precisamos instalar o npm usando o seguinte comando:
sudo apt-get install npmAgora podemos instalar o Yeoman com o seguinte comando usando o npm:
sudo npm install -g yoEm seguida podemos rodar o scaffolding do JHipster usando o comando a seguir:
npm install -g generator-jhipsterAgora criei uma pasta chamada loja para rodar a aplicaçăo lá dentro. Pelo terminal e dentro desta pasta rode o comando yo jhipster para começar a configuraçăo, como mostra a Figura 1.
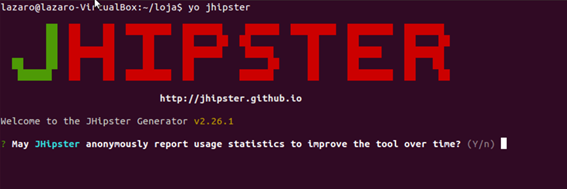
Figura 1. Iniciando a configuraçăo
A primeira pergunta que o JHipster fará é se desejamos ou năo enviar dados para serem usados nas estatísticas. Fica a seu critério enviar ou năo.
Logo depois iniciamos a configuraçăo do JHipster inserindo o nome do projeto e o caminho, como vemos na Figura 2.
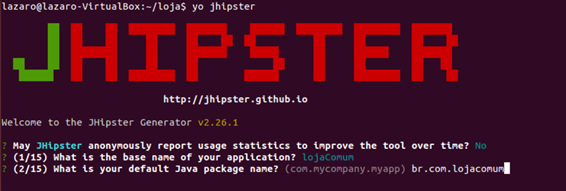
Figura 2. Nome e caminho do projeto
Nesse ponto ele te pergunta tipo de autenticaçăo vocę quer usar. O JHipster oferece quatro opçőes: Autorizaçăo Sessăo HTTP, Autorizaçăo Sessăo HTTP com Login Social (Facebook, Google Plus e Twitter), Autenticaçăo OAuth2 e Autenticaçăo baseado em token. Năo entraremos em detalhes sobre cada uma, pois daria um artigo a parte, porém faça a sua escolha com segurança já que é difícil voltar atrás nisso. As duas primeiras opçőes săo Stateful e as duas últimas săo Stateless. Para esse artigo escolhemos OAuth2 Authentication, como mostra a Figura 3.
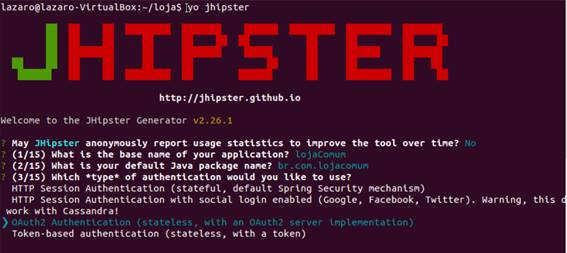
Figura 3. Escolha da autenticaçăo
Agora escolheremos qual banco de dados utilizaremos, se relacional ou năo relacional.Para o nosso artigo escolheremos a primeira opçăo. A seguir é perguntado sobre o banco para a produçăo e, no nosso caso, vamos escolher o MySQL. Há um aviso sobre a escolha do Oracle como banco, já que ele năo é open source, como mostra a Figura 4.
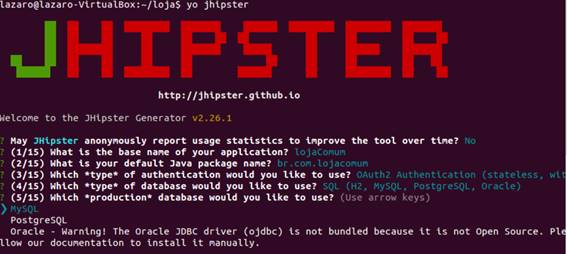
Figura 4. Escolha do banco e seu tipo
A mesma pergunta é feita para o banco de dados do ambiente de desenvolvimento e novamente escolhemos o MySQL.
Nesse ponto do setup ele pergunta se vocę quer usar o segundo nível de cache do Hibernate. Se sim, qual opçăo vocę quer: ehcache ou Hazelcast? Eu vou escolher o ehcache, como mostra a Figura 5.
Figura 5. Escolha do nível de cache
Agora ele quer saber se vocę quer usar o ElasticSearch, que é um mecanismo de busca full-text. Porém, como nosso exemplo năo vai precisar, escolhemos No.
Ele pergunta se vocę quer usar o Hazelcast para clusterizar as sessőes HTTP, mas năo vai ser preciso nesse nosso exemplo.
A próxima pergunta é com relaçăo ao uso do Websocket para as conexőes entre um navegador web e um servidor, mas esse também năo usaremos.
Agora chegamos as escolhas do back-end e front end. Vocę poderá escolher entre Maven ou Gradle e Grunt ou Gulp.js, como mostra a Figura 6.
Figura 6. Escolha do back-end e front-end
Em seguida precisamos escolher se queremos usar a biblioteca escrita em ruby LibSass para seu CSS: escolhemos No.
A próxima pergunta é com relaçăo ao AngularJS, que tem suporte a internacionalizaçăo da aplicaçăo: como năo usaremos, escolha No.
E quais frameworks para testes vocę quer usar: Gatling, cucumber ou Protractor? Conforme a Figura 7, vocę pode escolher todos e năo apenas só um. Para esse artigo usaremos o Gatling, que é um framework baseado no Scala e com reports em HTML.
Figura 7. Escolha dos frameworks de teste
Pronto, agora ele vai criar e configurar todo o projeto. Depois de tudo gerado, a estrutura do projeto será igual ŕ da Figura 8.

Figura 8. Estrutura do projeto.
Para rodarmos a nossa aplicaçăo precisamos configurar o nosso banco de dados. Por isso crie um banco de dados chamado lojacomum no MySQL e coloque a configuraçăo no arquivo de configuraçăo application-dev.yml (Figura 9).
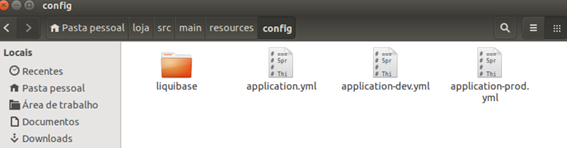
Figura 9. Arquivo application-dev.yml
Já dentro do arquivo é só alterar a URL do banco de dados, usuário e senha, conforme mostra a Figura 10.
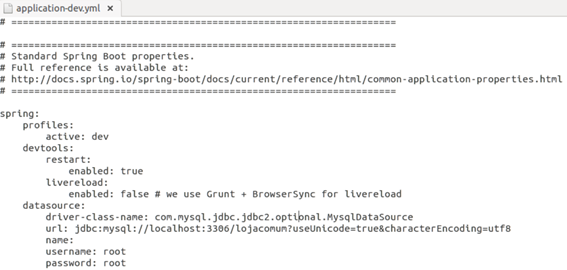
Figura 10. Estrutura do arquivo
Pelo terminal basta rodar o comando mvn do Maven e tudo vai rodar perfeitamente. Esse processo demora um pouco, pois ele vai baixar todas as dependęncias na primeira vez que rodar. A tela no console será algo como a Figura 11.

Figura 11. Rodando o Maven
Em seguida abra o browser e a cara da aplicaçăo padrăo será igual ŕ da Figura 12.
Figura 12. Aplicaçăo no browser
Por padrăo, o JHipster já vem com alguns usuários para testarmos e ver como está sua aplicaçăo. Vamos entăo começar usando o login admin (use também para a senha). Em seguida, vá até o último menu, conforme mostra a Figura 13.
Figura 13. Menu de ferramentas
Nesse menu vocę encontra várias ferramentas que o JHipster criou. Vamos entender cada uma.
A opçăo API mostra todos os endpoints da aplicaçăo usando o Swagger (Figura 14), que é uma API RESTful de documentaçăo interativa e geraçăo de SKD.
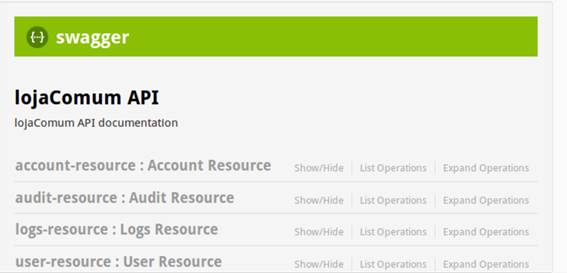
Figura 14. Swagger
Veja que o mesmo já tem os endpoints listados e prontos para testar e usar em outros dispositivos. Vamos ver o endpoint do user, presente na Figura 15.
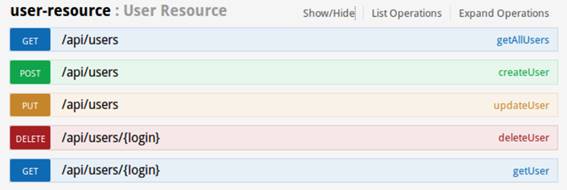
Figura 15. Endpoint user
Clicando em algum endpoint desses teremos a descriçăo dos parâmetros e ainda uma opçăo de teste para ver o retorno, como mostram as Figuras 16 e 17.
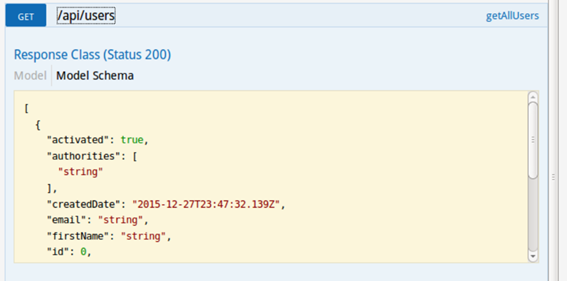
Figura 16. Parâmetros
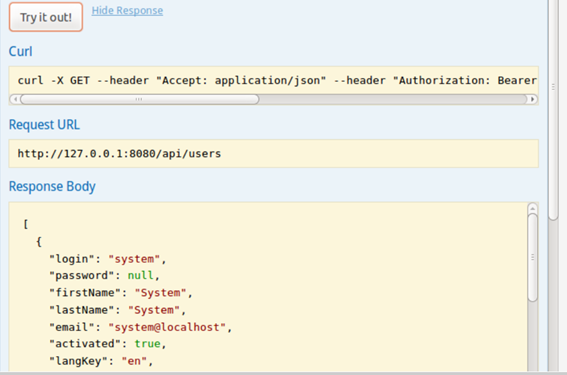
Figura 17. Opçăo de teste
Agora vamos passar para o outro Métrica, que mostra como está sua máquina virtual Java (JVM), como mostra a Figura 18. Isso é muito útil para quando sua aplicaçăo for para produçăo.
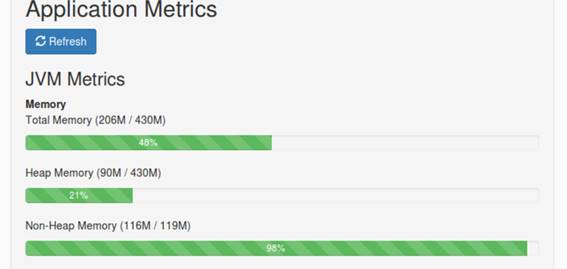
Figura 18. Menu Métrica
Já o menu de auditoria serve para ver o que está acontecendo com sua aplicaçăo, como mostra a Figura 19.
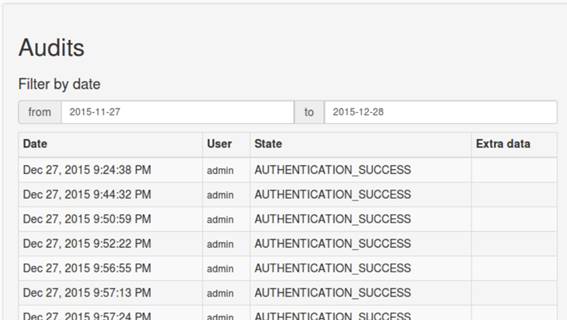
Figura 19. Menu Auditoria
Como podemos ver, o segundo menu está vazio, pois năo criamos nenhuma entidade. Para isso criaremos de forma fácil um CRUD completo pela linha de comando.
Essa entidade vai ser chamar PRODUTO e é um objeto da nossa loja, que terá um nome, uma descriçăo, um valor e uma data de vencimento.
Vamos voltar para o terminal e rodar o comando yo jhipster:entity Produto. Assim, ele vai começar a perguntar o que desejamos fazer. As perguntas serăo:
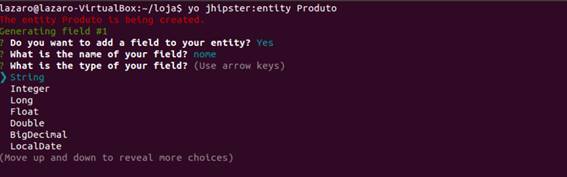
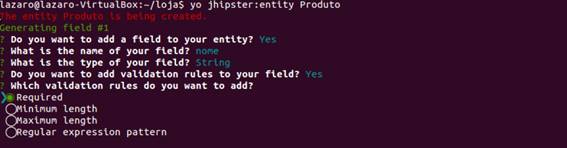

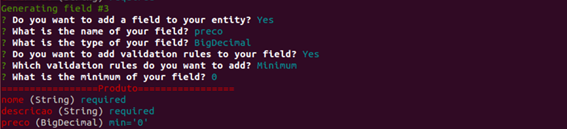
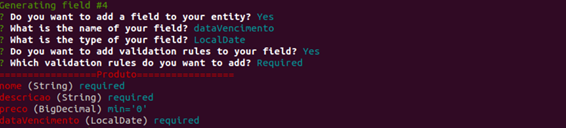
Depois de colocar todos os atributos dessa entidade ele vai perguntar se vocę quer fazer algum relacionamento com outra entidade, mas como năo temos outra entidade, vamos responder năo para essa pergunta também.
Agora ele quer saber se vocę quer usar um DTO (ainda em BETA no momento da escrita desse artigo) para acessar os dados no banco de dados. Como năo usaremos, escolha năo.
Em seguida ele perguntará sobre o uso de um SERVICE para essa entidade. Como năo usaremos, escolha a primeira opçăo, conforme mostra a Figura 25.

Figura 25. Escolha do service
Essa parte agora é sobre seu front-end. Que tipo de paginaçăo vocę quer para essa entidade? Ele te dá algumas opçőes: paginaçăo simples, paginaçăo com links, scroll infinito (tipo o Facebook) ou sem paginaçăo. Vamos escolher a opçăo de scroll infinito.
Com tudo terminado, repare no tanto de arquivos que ele criou sozinho na Figura 26.
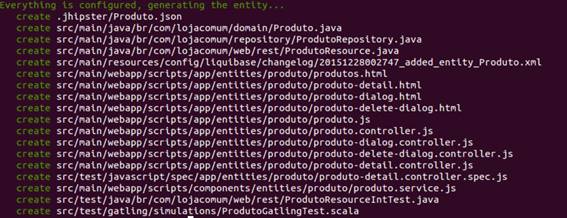
Figura 26. Criaçăo de arquivos
Foram criados tanto o back-end como o front-end da aplicaçăo. Para vermos como ficou, atualize a página no browser, como mostra a Figura 27.
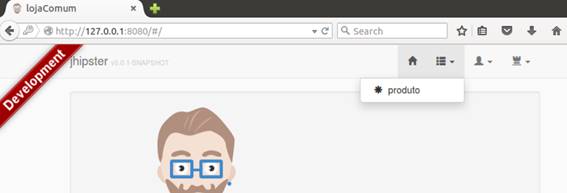
Figura 27. Novo menu
Agora a listagem (ainda vazia, claro) e o botăo para criar um novo produto estăo prontos, como mostra a Figura 28.
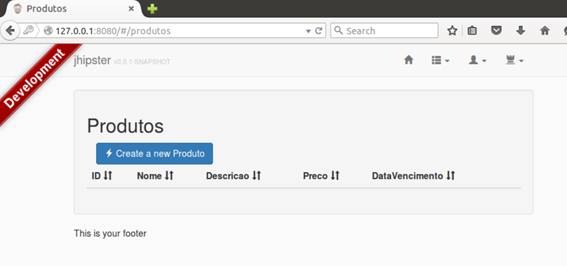
Figura 28. Cadastro de produtos.
A aparęncia do cadastro será igual ŕ da Figura 29.
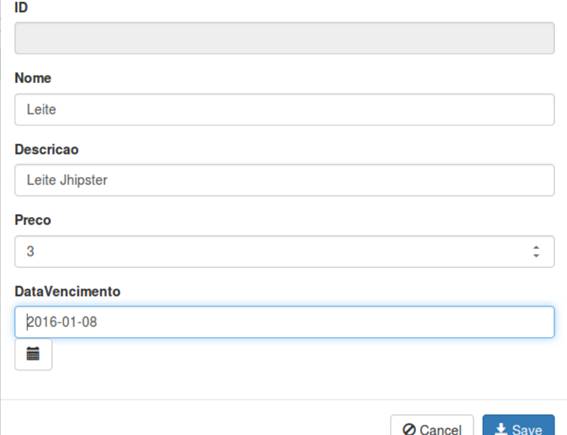
Figura 29. Aparęncia do cadastro.
Após cadastrar um exemplo qualquer, veja na Figura 30 como ficou o cadastro.
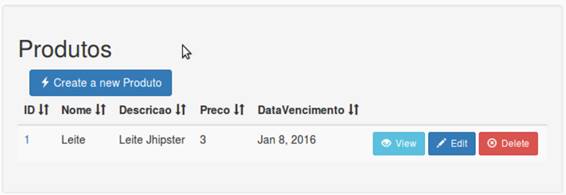
Figura 30. Cadastro do item
Veja que os botőes ao lado correspondem as demais opçőes do CRUD, assim temos um CRUD completo.
Como vimos, o JHipster tem muitas opçőes para escolher. O objetivo deste artigo foi demostrar um pouco de um stack bem simples e bem usado no mercado pela gama de tecnologias atreladas a ele.
É um framework ainda novo, entăo temos que tomar cuidados, pois ainda pode ter vários bugs. Como é um projeto open-source, vocę pode contribuir para a evoluçăo dele na comunidade.
É uma ótima opçăo para projetos Java e AngularJS. Outro ponto positivo é a facilidade de manutençăo, pois tudo que está nele á é padrăo na comunidade Java, entăo é fácil a procura por ajuda.
Um ponto negativo é que ele te pede uma bagagem do desenvolvedor, dificultando para programadores iniciantes. A documentaçăo ainda năo é uma das melhores, mas está em evoluçăo.
Links
JHipster
http://jhipster.github.io/


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.