


Artigo no estilo Mentoring
O conhecimento apresentado neste artigo é útil para apoiar as atividades referentes ŕ procura por um melhor desempenho do SGBD. Sem dúvidas, o uso correto de estatísticas e índices contribui muito para este fim.
Indexaçăo se tornou um ponto chave no cenário de bancos de dados. Um problema existente em banco de dados refere-se ŕ necessidade de năo se preocupar muito com a forma com que as consultas SQL săo executadas e informadas ao otimizador de consultas que verifica, em primeiro lugar, se existe um plano disponível para sua execuçăo.
Năo havendo, ele compila um plano de forma automática. Para executar de forma eficaz, é necessário ser capaz de estimar as linhas intermediárias que seriam geradas a partir das várias estratégias e alternativas para o retorno de um resultado.
O Database Engine mantém estatísticas sobre a distribuiçăo dos valores das chaves em cada índice da tabela, e usa essas estatísticas para determinar qual índice(s) usar ao compilar o plano de consulta. Se, no entanto, há problemas com estas estatísticas, o desempenho das consultas será afetado.
Se năo há estatísticas, o otimizador terá que estimar a contagem de linhas ao invés de estimá-las, e acreditem: isso năo é o que se quer e pode estar aqui o problema da lentidăo em executar certas consultas.
Existem várias formas de descobrir que ambos os planos de execuçăo, o estimado e o real, possuem problemas quando o otimizador se depara com a falta de estatísticas.
Neste caso, existirá avisos no plano, como um ponto de exclamaçăo ou um “x” indicando erro, no plano de execuçăo e um aviso nas informaçőes, assim como mostra a Figura 1.
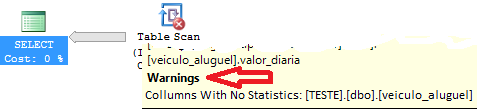
Figura 1. Colunas sem estatísticas.
Havendo a necessidade de visualizar os planos de execuçăo de consultas anteriores, pode-se solicitar esses planos pelo uso do comando sys.dm_exec_cached_plans DMV. Há várias ocasiőes em que se precisa visualizar estatísticas no histórico, seja para saber de alguma alteraçăo que foi realizada ou para ter um acompanhamento e monitoramento dos processos. Antes de ir para uma discussăo profunda, é necessário ter ideia sobre alguns termos utilizados na indexaçăo:
· Table Scan: Sempre que é invocada uma consulta em um banco de dados, o otimizador de consulta SQL está tentando buscar a melhor forma possível para executar a consulta a fim de se obter um melhor desempenho.
Neste processo, quando o otimizador de consultas determina que năo há índices úteis disponíveis para produzir o conjunto de resultados de saída, entăo ele faz a verificaçăo da tabela toda. Assim, o Table Scan precisa inspecionar toda a tabela, linha por linha, a fim de obter os resultados esperados.
Isso é muito lento e é recomendado evitar, pois há alguns casos em que os Table Scan săo mais rápidos do que o Index Scan, por exemplo, em tabela com poucos dados;
· Index Scan: estrutura de dados auxiliar usada para acelerar o acesso a dados dentro do banco de dados. Aqui, năo irá se fazer um rastreamento em toda a tabela, mas irá se buscar diretamente as linhas que qualificam a consulta do requisitante. Para tanto, a estrutura de dados é mantidaseparada para sustentar as informaçőes sobre os valores da chave da tabela.
A principal propriedade do índice é ser ordenado. Por exemplo, no caso de um dicionário, todas as palavras estăo em forma ordenada, de modo que quando se procura qualquer palavra, pula-se diretamente para a página correspondente relacionada com a palavra. Da mesma forma, o motor de banco de dados está em busca das linhas exigidas quando a(s) coluna(s) correspondente é indexada.
Bom, se isso ocorre de forma correta, entăo o que ocorre de forma errada, e o que pode ser feito para colocar as coisas no seu devido lugar? Vamos percorrer os problemas mais comuns e explicar como isso ocorre e de que forma pode ser resolvido. A ideia geral deste artigo é apresentar de forma sucinta alguns problemas que envolvem o uso de estatísticas e índices dentro do banco de dados SQL Server e como solucioná-los.
Setando auto create statistics OFF
Problema
Como as estatísticas aumentam o desempenho da execuçăo de consulta do SQL Server?
Soluçăo
Os histogramas estatísticos săo usados pelo otimizador de consulta para escolher o plano de execuçăo de consulta ideal. Se uma consulta contém uma coluna com as estatísticas, o otimizador tem como estimar com precisăo o número de linhas afetadas por essa consulta. Assim, o otimizador tem informaçőes suficientes para criar o plano de execuçăo. O SQL Server cria estatísticas de diferentes maneiras:
· As estatísticas săo criadas automaticamente para cada novo índice;
· Se a definiçăo auto create statistics do banco de dados é setada como ON, entăo o SQL Server criará automaticamente as estatísticas para colunas năo indexadas que săo utilizadas em suas consultas.
Utilizando variáveis de tabela
Problema
Para as variáveis de tabela do SQL Server, as estatísticas nunca serăo mantidas. Tenha isso em mente. Quando se seleciona a partir de variáveis de tabela, a contagem de linhas estimada é sempre 1, a menos que um predicado seja avaliado como falso e năo disponha de qualquer relaçăo com a variável de tabela.
Neste caso é aplicado (como WHERE 1 = 0) quando a contagem de linhas da estimativa avaliada seja 0.
Soluçăo
Năo conte com o uso de variáveis de tabela para tabelas temporárias se elas săo susceptíveis a conter mais do que algumas poucas linhas. Como regra geral, use tabelas temporárias (tabelas com um "#" como o primeiro o caractere em seu nome), ao invés de variáveis de tabela, para tabelas temporárias com mais de 100 linhas, pois isso acarreta em menos ou nenhuma recompilaçăo.
Executando Consultas remotas
Problema
Suponha que ...
Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método







Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.