Weka é um software livre do tipo open source para mineraçăo de dados, desenvolvido em Java, dentro das especificaçőes da GPL (General Public License) que ao longo dos últimos anos se consolidou como a ferramenta de mineraçăo de dados mais utilizada em ambiente acadęmico.
Embora a ferramenta possua como ponto forte a mineraçăo de classificadores em bases de dados, também pode ser utilizada para executar outras tarefas, especialmente a mineraçăo de regras de associaçăo. Curiosamente, é muito difícil encontrar artigos com exemplos de utilizaçăo da Weka no data mining de regras de associaçăo. Esta situaçăo serviu de motivaçăo para a produçăo deste artigo, que mostra o passo-a-passo para a execuçăo do data mining de regras de associaçăo na Weka. O artigo é destinado a pessoas que já possuem alguma experięncia no uso da ferramenta (quem já utilizou a Weka para executar algoritmos de classificaçăo, por exemplo) e conhecem os conceitos básicos sobre regras de associaçăo (algoritmo Apriori, medidas de interesse, etc.).
O restante do artigo está dividido da seguinte forma. A Seçăo 2 apresenta um exemplo possível de formataçăo de uma base de dados do tipo "market basket data" para mineraçăo na Weka. A seguir, na Seçăo 3, apresenta-se a forma de configurar os parâmetros de entrada e executar a mineraçăo das regras de associaçăo. As conclusőes săo apresentadas na Seçăo 4.
A ferramenta Weka trabalha com arquivos de entrada no formato ARFF, que corresponde a um arquivo texto contendo um conjunto de observaçőes, precedido por um pequeno cabeçalho. O cabeçalho é utilizado para fornecer informaçőes a respeito dos campos que compőem o conjunto de observaçőes.
É importante observar que o formato ARFF foi originalmente proposto para a mineraçăo de classificadores; no entanto, ele pode ser "adaptado" para a mineraçăo de regras de associaçăo. Essa adaptaçăo resulta em uma base de dados com uma estrutura um pouco esquisita, porém capaz de ser manipulada pela ferramenta. A seguir apresenta-se um exemplo de base de dados ARFF contendo 9 transaçőes e envolvendo 6 itens.
@relation "Transacoes"
@attribute I1 {y, n}
@attribute I2 {y, n}
@attribute I3 {y, n}
@attribute I4 {y, n}
@attribute I5 {y, n}
@attribute I6 {y, n}
@data
y,y,?,?,y,?
?,y,?,y,?,?
?,y,y,?,?,?
y,y,?,y,?,?
y,?,y,?,?,?
?,y,y,?,?,?
y,?,y,?,?,?
y,y,y,?,y,?
y,y,y,?,?,?
A seguir apresenta-se o passo-a-passo para a mineraçăo de regras de associaçăo na Weka, a partir da base de dados exemplo.
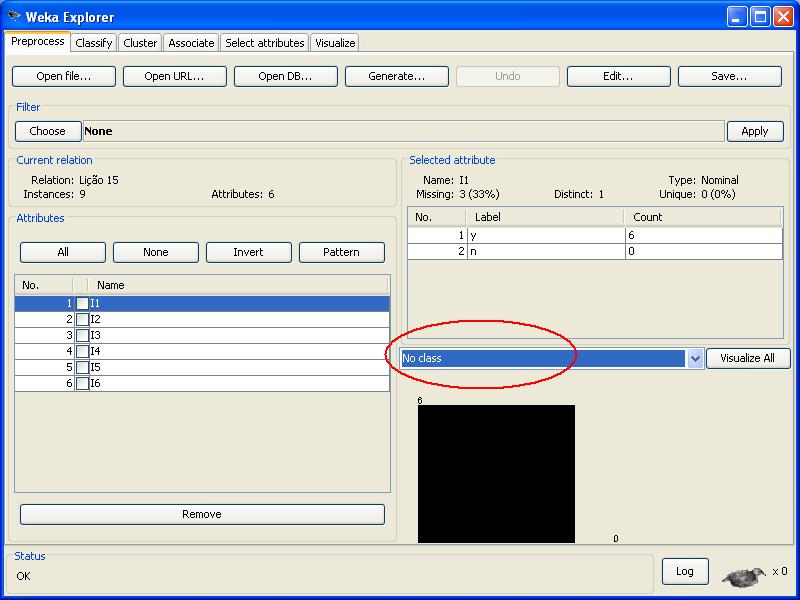
PASSO 1: digite as informaçőes da base mostrada na Figura 1 e salve com a extensăo .ARFF (exemplo: “transacoes.arff”). Após abrir a Weka, clique no botăo “Open file...” para importar a base.
PASSO 2: mude a caixa de seleçăo que mostra o atributo classe e selecione a opçăo “No class” (destacado na figura abaixo). Isso é feito porque na mineraçăo de regras transacionais năo existe o conceito de atributo classe (conceito associado ŕ tarefa de classificaçăo).
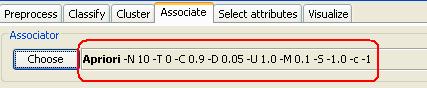
PASSO 3: clique na aba "Associate". Efetue duplo clique onde está escrito “Apriori” para poder configurar os parâmetros do algoritmo
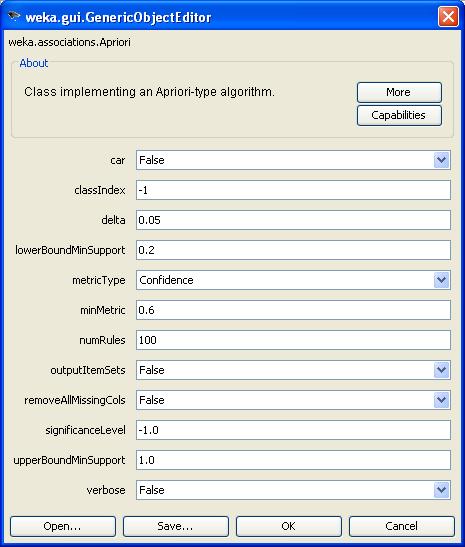
PASSO 4: a janela de configuraçăo irá abrir. Para executar o exemplo, vocę poderá configurar os parâmetros de acordo com o que está indicado na figura abaixo.
Uma breve orientaçăo sobre a configuraçăo destes parâmetros é apresentada a seguir. Dentro da ferramenta Weka, vocę pode utilizar o botăo “More” para visualizar uma janela de ajuda com mais informaçőes sobre os parâmetros.
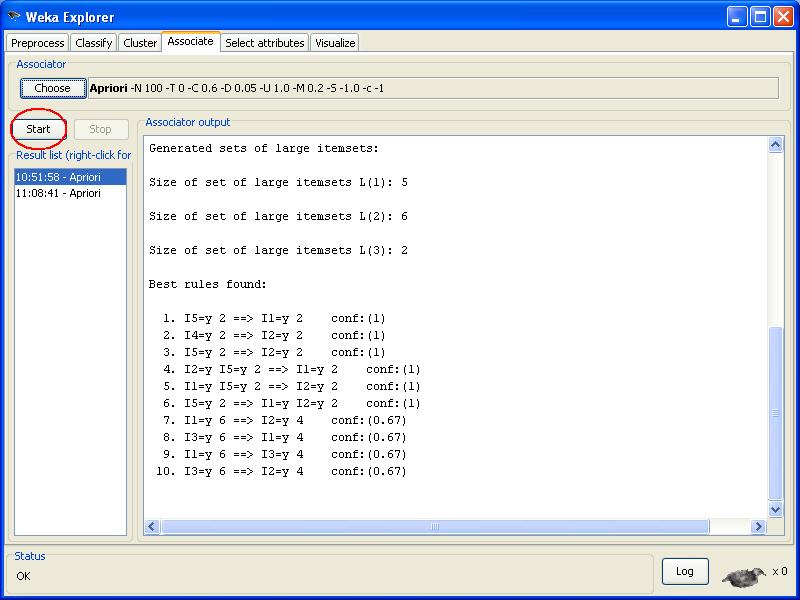
PASSO 5: clique no botăo “OK”. A seguir clique em “Start”. As regras de associaçăo serăo mineradas e exibidas na tela de resultados.
Este artigo apresentou um roteiro para a mineraçăo de regras de associaçăo na popular ferramenta Weka. Uma característica atraente da ferramenta é a sua simplicidade. A configuraçăo dos parâmetros e a execuçăo do algoritmo de mineraçăo săo feitas através de uma interface agradável e intuitiva.
Como principal característica negativa, encontra-se o fato de a base de dados a ser minerada precisar estar estruturada em um formato que năo é muito prático (o que pode inviabilizar o uso da ferramenta em algumas aplicaçőes reais). É preciso especificar todos os itens do domínio na seçăo de cabeçalho e indicar os itens ausentes em cada transaçăo com o uso do símbolo "?".

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.