O artigo apresenta o assunto modelagem de dados, descrevendo os principais conceitos envolvidos no assunto e diferentes notaþ§es que podem ser aplicadas para modelagem dos dados.
A modelagem de dados Ú uma etapa importante e essencial em qualquer projeto de desenvolvimento ou manutenþÒo de software. Assim, estar atualizado neste assunto Ú importante para qualquer profissional da ßrea. Serve como material introdut¾rio ao tema de modelagem de dados, apresentando um breve resumo sobre o assunto.
O objetivo deste artigo Ú apresentar uma visÒo geral sobre as habilidades de modelagem de dados fundamentais que todos os desenvolvedores devem ter, habilidades que podem ser aplicadas em projetos tradicionais que seguem uma abordagem em sÚrie e aplicadas em projetos ßgeis que seguem uma abordagem evolucionßria. Idealmente, todos profissionais de TI deveriam ter um entendimento bßsico sobre modelagem de dados. Eles nÒo precisam ser especialistas neste assunto, mas deveriam estar preparados para se envolverem na criaþÒo de um modelo, estar apto a ler um modelo de dados existente, entender quando criar um modelo de dados e quando nÒo criar e conhecer as tÚcnicas de projeto de dados fundamentais.
Neste contexto, este artigo apresenta uma breve introduþÒo sobre estas habilidades. Seu p·blico principal sÒo os desenvolvedores de aplicaþ§es que precisam obter um entendimento de alguma das atividades crÝticas realizadas por um DBA. Este entendimento deve levar ao conhecimento do que um DBA faz e por que faz, ajudando a estabelecer uma ponte de comunicaþÒo reduzindo a distÔncia existente entre esses dois papÚis fundamentais no desenvolvimento de software (desenvolvedor e DBA).
Modelagem de dados Ú o ato de explorar estruturas orientadas a dados. Como outros artefatos de modelagem, modelos de dados podem ser usados para uma variedade de prop¾sitos, desde modelos conceituais de alto nÝvel atÚ modelos fÝsicos de dados. Do ponto de vista de um desenvolvedor atuando no paradigma orientado a objetos, modelagem de dados Ú conceitualmente similar Ó modelagem de classes. Com a modelagem de dados identificamos tipos de entidades da mesma forma que na modelagem de classes identificamos classes. Atributos de dados sÒo associados a tipos de entidades exatamente como associados atributos e operaþ§es Ós classes. Existem associaþ§es entre entidades, similar Ós associaþ§es entre classes û relacionamento, heranþa, composiþÒo e agregaþÒo sÒo todos conceitos aplicßveis em modelagem de dados.
Modelagem de dados tradicional Ú diferente da modelagem de classes porque o seu foco Ú totalmente nos dados û modelos de classes permitem explorar os aspectos comportamentais e de dados em um domÝnio de aplicaþÒo, jß com o modelo de dados podemos apenas explorar o aspecto dado. Por causa deste foco, projetistas de dados tendem a serem melhores em identificar os dados ôcorretosö em uma aplicaþÒo do que modeladores de objetos. No entanto, algumas pessoas modelam mÚtodos de banco de dados (stored procedures, stored functions e triggers) quando estÒo realizando a modelagem fÝsica dos dados.
Apesar de o foco deste artigo ser modelagem de dados, existem normalmente alternativas para artefatos orientados a dados. Por exemplo, quando estamos na modelagem conceitual, os diagramas ORM (Object Role Model) nÒo sÒo a ·nica opþÒo. AlÚm do Modelo L¾gico de Dados, Ú comum a criaþÒo de diagramas de classes da UML.
Embora as quest§es de metodologias sejam abordadas depois, precisamos discutir como modelos de dados podem ser usados na prßtica para melhor entendÛ-los. Provavelmente, iremos nos deparar a trÛs estilos bßsicos de modelos de dados:
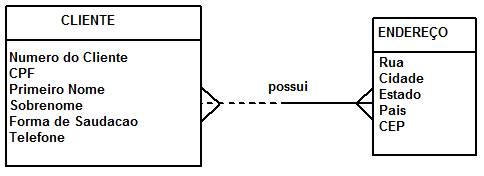
Embora MLDs e MFDs parecerem similares, e eles de fato sÒo, o nÝvel de detalhes que eles modelam pode ser significativamente diferente. Isso porque o objetivo de cada diagrama Ú diferente û podemos usar um MLD para explorar conceitos do domÝnio com os envolvidos no projeto e MFD para definir o projeto do banco de dados. A Figura 1 apresenta um simples MLD e a Figura 2 um simples MFD, ambos modelando o conceito de clientes e endereþos, assim como o relacionamento entre eles. Ambos os diagramas seguem a notaþÒo de Barker, que serß descrita a seguir. Note como o MFD mostra mais detalhes, incluindo uma tabela associativa necessßria para implementar a associaþÒo, assim como as chaves necessßrias para manter os relacionamentos. Mais detalhes sobre esses conceitos serÒo descritos a seguir.
MFDs devem tambÚm refletir os padr§es de nomenclatura de banco de dados da organizaþÒo. Neste caso, uma abreviaþÒo do nome da entidade Ú colocado para cada nome de coluna e uma abreviaþÒo para ôn·meroö foi consistentemente introduzida. Um MFD deve tambÚm indicar os tipos de dados das colunas, tais como integer e char(5). Apesar de a Figura 2 nÒo mostrß-las, tabelas de referÛncia como para o endereþo Ú usado, assim como para estados e paÝses estÒo implÝcitos pelos atributos END_USADO_CODIGO,END_ESTADO_CODIGO, END_PAIS_CODIGO.
Modelos de dados podem ser usados efetivamente tanto no nÝvel da empresa como de projetos. Os arquitetos da empresa normalmente criarÒo um ou mais MLDs de alto nÝvel que descreve as estruturas de dados que apoiam toda a empresa, normalmente chamados de modelos de dados da empresa ou modelos de informaþÒo da empresa. Um modelo de dados da empresa Ú uma das vßrias vis§es que os arquitetos da empresa podem escolher para manter e apoiar û outras vis§es podem explorar a infraestrutura de rede/hardware, a estrutura da organizaþÒo, infraestrutura de softwares o processo de neg¾cios, dentre outros. Esses modelos provÛm informaþ§es que uma equipe de projeto pode usar como conjunto de restriþ§es e tambÚm como descriþÒo da estrutura do sistema.
Equipes de projeto tipicamente criarÒo MLDs como um dos principais artefatos de anßlise quando seu ambiente de implementaþÒo Ú predominantemente procedural por natureza, por exemplo quando estÒo usando COBOL estruturado como linguagem de implementaþÒo. MLDs sÒo tambÚm boas escolhas quando um projeto Ú orientado a dados, como um data warehouse ou sistema de relat¾rio. No entanto, MLDs sÒo normalmente escolhas ruins quando uma equipe de projeto estß usando tecnologias orientadas a objeto ou baseadas em componentes porque os desenvolvedores trabalhariam melhor com diagramas UML ou quando o projeto nÒo Ú orientado a dados. Como uma dica de modelagem, aplique os artefatos corretos para aquele trabalho a ser desenvolvido.
Quando um banco de dados relacional Ú usado para armazenar dados, equipes de projeto sÒo aconselhadas a criar um MFD para modelar um esquema interno. MFD normalmente Ú apenas um dos artefatos de projeto crÝticos para projetos de desenvolvimento de aplicaþ§es de neg¾cio.
Muitos profissionais de dados preferem criar um ORM (Object-Role Model), como o apresentado no exemplo da Figura 3, em vez de um MLD para um modelo conceitual. A vantagem Ú que a notaþÒo Ú muito simples, algo que os envolvidos no projeto podem rapidamente interpretar, apesar da desvantagem que seria o fato de os modelos se tornarem grandes rapidamente. ORMs nos permite primeiramente explorar os exemplos de dados reais em vez de simplesmente saltar para uma abstraþÒo potencialmente incorreta û por exemplo, a Figura 3 examina o relacionamento entre clientes e um endereþo em detalhe.
Normalmente ORMs sÒo usados para explorar o domÝnio da aplicaþÒo com os envolvidos no projeto, mas depois ele Ú substituÝdo por um artefato mais tradicional, como um MLD, um diagrama de classes ou atÚ um MFD.
A Figura 4 apresenta um resumo da sintaxe das quatro notaþ§es mais comuns para modelagem de dados: Engenharia da InformaþÒo (EI), NotaþÒo de Barker, IDEF1X e UML (Unified Modeling Language). Este diagrama nÒo tem a pretensÒo de ser altamente compreensivo, mas sim prover uma visÒo geral bßsica sobre as notaþ§es. AlÚm disso, para nÒo se estender muito no texto, nÒo foi possÝvel descrever a abordagem altamente detalhada para nomenclatura de relacionamento como sugerido por Barker. Apesar disso, foi provida uma breve discussÒo de cada notaþÒo na Tabela 1.
| NotaþÒo | Comentßrios |
|---|---|
| EI | A notaþÒo EI Ú simples e fßcil de ser lida, e Ú bem abrangente para modelagem de dados de neg¾cio e modelagem l¾gica de alto nÝvel. O ·nico ponto negativo desta notaþÒo Ú que ela nÒo suporta a identificaþÒo de atributos de uma entidade. Assume-se que os atributos serÒo modelados com outro diagrama ou simplesmente descrito em uma documentaþÒo de apoio. |
| Barker | A notaþÒo de Barker Ú uma das mais populares, sendo apoiadas por vßrias ferramentas (ex: Oracle toolset), Ú bem abrangente para todos os tipos de modelos de dados. Esta abordagem pode se tornar complicada com hierarquias que possuem vßrios nÝveis de profundidade. |
| IDEF1X | Esta notaþÒo Ú a mais complexa, e foi originalmente intencionada para modelagem fÝsica, mas foi mal aplicada para modelagem l¾gica. Esta notaþÒo tem sido abandonada por todos, entÒo evite-a se possÝvel. |
| UML | Esta nÒo chega a ser uma notaþÒo de modelagem de dados oficial. Apesar de vßrias sugest§es para um perfil UML de modelagem de dados existirem, nenhum Ú completo e nÒo sÒo oficializados pela UML. |
╔ crucial para um desenvolvedor de aplicaþÒo ter uma noþÒo dos fundamentos de modelagem de dados nÒo apenas para ler os modelos de dados, mas tambÚm para trabalhar efetivamente com os DBAs responsßveis pelos aspectos relacionados aos dados do projeto. O objetivo ao ler esta seþÒo nÒo Ú aprender como se tornar um modelador de dados, mas sim obter uma apreciaþÒo a respeito do que Ú envolvido nesta tarefa.
As seguintes tarefas sÒo realizadas de forma iterativa:
Um tipo de entidade, ou simplesmente entidade, Ú conceitualmente similar ao conceito de orientaþÒo a objeto de uma classe û um tipo de entidade representa uma coleþÒo de objetos similares. Um tipo de entidade pode representar uma coleþÒo de pessoas, lugares, coisas, eventos ou conceitos. Exemplos de entidades em um sistema de vendas incluiria: Cliente, Endereþo, Venda, Item e Taxa. Se estivÚssemos modelando classes, esperarÝamos descobrir classes exatamente com esses nomes. No entanto, a diferenþa entre uma classe e um tipo de entidade Ú que classes possuem dados e comportamentos, enquanto que tipos de entidade possuem apenas dados.
Idealmente, uma entidade deveria ser normal, descrevendo de forma coesa uma informaþÒo do mundo real. Uma entidade normalmente descreve um conceito, tal como uma classe coesa modela um conceito. Por exemplo, cliente e venda sÒo claramente dois conceitos diferentes, portanto, faz sentido modelß-los como entidades diferentes.
Cada tipo de entidade terß um ou mais atributos de dados. Por exemplo, na Figura 1 podemos ver que a entidade Cliente possui atributos como Primeiro Nome e Sobrenome e na Figura 2 que a tabela TCLIENTE possui colunas de dados correspondentes CLI_PRIMEIRO_NOME e CLI_SOBRENOME (uma coluna Ú a implementaþÒo de um atributo de dados em um banco de dados relacional).
Atributos devem ser coesos do ponto de vista do domÝnio da aplicaþÒo. Na Figura 1 decidimos que querÝamos modelar o fato de pessoas possuÝrem primeiro nome e sobrenome em vez de apenas um nome (ex: ôClßudioö e ôDiasö VS. ôClßudio Diasö). Usar o nÝvel de detalhe correto pode ter um impacto significativo no esforþo de desenvolvimento e manutenþÒo. Refatorar uma simples coluna de dados em vßrias colunas pode ser difÝcil, o que pode resultar em construir o sistema com elementos desnecessßrios e, portanto, provoca um maior custo de desenvolvimento e de manutenþÒo do que realmente necessßrio.
Sua organizaþÒo deve dispor de normas e diretrizes aplicßveis Ó modelagem de dados, algo que vocÛ deve ser capaz de obter dos administradores da empresa (se nÒo existir vocÛ deve fazer algum lobby para incluÝ-lo).Essas diretrizes devem incluir as convenþ§es de nomenclatura para a modelagem l¾gica e fÝsica, as convenþ§es de nomenclatura l¾gica devem ser focadas na capacidade de leitura de humanos, enquanto as convenþ§es de nomenclatura fÝsica refletirÒo consideraþ§es tÚcnicas. VocÛ pode ver claramente que diferentes convenþ§es de nomenclatura foram aplicadas nas Figuras 1 e 2.
A ideia bßsica Ú que desenvolvedores sigam um conjunto comum de padr§es de modelagem em um projeto de software. Tal como Ú importante seguir convenþ§es comuns de codificaþÒo, um c¾digo limpo que segue as diretrizes escolhidas Ú mais fßcil de ser compreendido. Isso funciona da mesma forma para as convenþ§es de modelagem de dados.
No mundo real, entidades possuem relacionamentos entre elas. Por exemplo, clientes FAZEM compras, clientes MORAM EM endereþos e itens de venda S├O PARTE DAS vendas. Todos esses termos em mai·sculo definem relacionamentos entre entidades. Os relacionamentos entre entidades sÒo conceitualmente idÛnticos aos relacionamentos (associaþ§es) entre objetos.
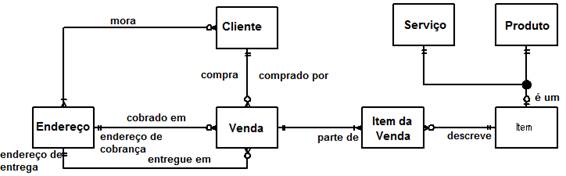
A Figura 5 descreve um MLD parcial para um sistema de compra online. A primeira coisa a se notar sÒo os vßrios estilos aplicados aos nomes dos relacionamentos e papÚis û diferentes relacionamentos requerem diferentes abordagens. Por exemplo, o relacionamento entre Cliente e Venda possui dois nomes, compra e Ú comprado por, mesmo o relacionamento entre essas entidades sendo apenas um. Neste exemplo, tendo um segundo nome no relacionamento, a ideia seria especificar como ler o relacionamento em cada direþÒo. O ideal seria colocar apenas um nome por relacionamento.
Precisamos tambÚm identificar a cardinalidade e opcionalmente de um relacionamento (a UML combina os conceitos de cardinalidade e opcionalmente de um relacionamento em um conceito ·nico de multiplicidade). Cardinalidade representa o conceito de ôquantosö enquanto opcionalmente representa o conceito de ôse Ú obrigat¾ria a existÛncia da entidadeö. Por exemplo, nÒo Ú suficiente saber que clientes fazem vendas. Quantas vendas um cliente pode realizar? Nenhuma, uma ou vßrias? AlÚm disso, os relacionamentos existem nos dois sentidos: nÒo apenas clientes fazem vendas, mas vendas sÒo realizadas por clientes. Isso nos leva a quest§es como: quantos clientes podem ser envolvidos em uma dada venda e Ú possÝvel ter uma venda com nenhum cliente envolvido? A Figura 5 mostra que clientes fazem nenhuma ou mais vendas e que qualquer venda Ú realizada por um e somente um cliente. Ela tambÚm mostra que um cliente possui um ou mais endereþos e que qualquer endereþo possui zero ou mais clientes associados a ele.
Apesar de a UML distinguir entre diferentes tipos de relacionamentos û associaþ§es, hierarquia, agregaþÒo, composiþÒo e dependÛncia û modeladores de dados normalmente nÒo estÒo por dentro dessa questÒo. Subtipo, uma aplicaþÒo de hierarquia, Ú normalmente encontrada em modelos de dados. AgregaþÒo e composiþÒo sÒo muito menos comum, assim como dependÛncias, que sÒo tipicamente uma construþÒo de software e portanto nÒo aparecem no modelo de dados, a menos que tenhamos um modelo fÝsico de dados bastante detalhado que mostre como views, triggers ou stored procedures dependem de outros aspectos do esquema do banco de dados.
Existem duas estratÚgias fundamentais para associar chaves Ós tabelas. Primeiro, podemos associar uma chave natural que Ú um ou mais atributos de dados existentes que sÒo ·nicos para o conceito do neg¾cio. Imaginemos uma tabela Cliente, por exemplo. Ela possui de imediato duas chaves candidatas, as colunas NumeroCliente e CPF. A segunda forma Ú introduzindo uma nova coluna, chamada chave substituta, que Ú uma chave que nÒo possui qualquer significado para o neg¾cio. Um exemplo disso seria uma coluna idEndereco de uma tabela Endereco. Endereþos nÒo possuem uma chave natural ôtrivialö porque seria necessßrio usar todas as colunas da tabela Endereco para formar uma chave. Assim, introduzir uma chave substituta Ú uma opþÒo muito melhor neste caso.
O debate entre "natural vs. substituta" Ú um das grandes quest§es religiosas na comunidade de banco de dados. O fato Ú que nÒo existe estratÚgia perfeita, e com o tempo percebemos que na prßtica algumas vezes fazem sentido usar chaves naturais e em outras situaþ§es Ú mais adequado o uso de chaves substitutas.
NormalizaþÒo de dados Ú um processo no qual atributos de dados em um modelos de dados sÒo organizados para aumentar a coesÒo dos tipos de entidade. Em outras palavras, o objetivo da normalizaþÒo de dados Ú reduzir e atÚ eliminar redundÔncia de dados, uma questÒo importante para desenvolvedores, pois Ú incrivelmente difÝcil armazenar objetos em um banco de dados relacional que mantÚm a mesma informaþÒo em vßrios lugares. A Tabela 2 resume as trÛs principais regras de normalizaþÒo descrevendo como aumentar os nÝveis de normalizaþÒo em tipos de entidade.
Com respeito Ó terminologia, um esquema de dados Ú considerado estar em um nÝvel de normalizaþÒo do seu tipo de entidade menos normalizado. Por exemplo, se todos os tipos de entidade estÒo na segunda forma normal (2NF) ou maior, entÒo dizemos que o esquema de dados estß na 2NF.
| NÝvel | Regra |
|---|---|
| Primeira Forma Normal (1NF) | Uma entidade estß na 1NF quando ela nÒo contÚm grupos de dados repetidos. |
| Segunda Forma Normal (2NF) | Uma entidade estß na 2NF quando ela estß na 1NF e quando todos seus atributos que nÒo sÒo chaves primßrias sÒo completamente dependentes de sua chave primßria. |
| Terceira Forma Normal (3NF) | Uma entidade estß na 3NF quando ele estß na 2NF e quando todos seus atributos sÒo diretamente dependentes da chave primßria. |
A Figura 6 descreve um esquema de banco de dados na ONF enquanto que a Figura 7 descreve um esquema normalizado na 3NF.
Por que normalizaþÒo de dados? A vantagem de ter do esquema de dados altamente normalizado Ú que a informaþÒo Ú armazenada em um lugar apenas, reduzindo a possibilidade de dados inconsistentes. AlÚm disso, esquemas de dados altamente normalizados em geral sÒo conceitualmente mais pr¾ximos dos esquemas orientados a objeto, pois os objetivos da orientaþÒo a objetos de promover alta coesÒo e pouco acoplamento entre as classes resulta em soluþ§es similares (ao menos do ponto de visa de dados). Isso geralmente torna mais simples mapear os objetos para o esquema de dados. Infelizmente, a normalizaþÒo normalmente traz um custo para o desempenho. Com o esquema de dados da Figura 6 todos os dados para uma venda estÒo armazenados em uma linha (assumindo que vendas poderÒo ter atÚ dois itens), simplificando o acesso. Com o esquema de dados da Figura 6 podemos rapidamente determinar a quantidade total de uma venda lendo uma ·nica linha da tabela. Para fazer o mesmo com o esquema de dados da Figura 7, precisamos ler dados a partir de uma linha na tabela Venda, dados a partir de linhas na tabela ItemVenda para aquela venda e dados a partir das linhas correspondentes na tabela Item. Para esta consulta, o esquema de dados da Figura 6 provavelmente obtÚm melhor resultado.
Esquemas de dados normalizados, quando colocados em produþÒo, normalmente sofrem problemas de desempenho. Isso faz sentido û as regras de normalizaþÒo focam em reduzir redundÔncia de dados, nÒo em melhorar desempenho do acesso aos dados. Uma parte importante da modelagem de dados Ú Diversificar porþ§es do esquema de dados para melhorar tempo de acesso aos dados.
Observe que se o projeto inicial e normalizado dos dados atinge o desempenho necessßrio para a aplicaþÒo, nada precisa ser feito. A DiversificaþÒo deve ser aplicada apenas quando os testes de desempenho mostram que temos um problema com os objetos, revelando que precisamos melhorar o tempo de acesso aos dados.
Modelagem de dados evolucionßria Ú a modelagem de dados realizada de forma incremental. Modelagem de dados ßgil Ú a modelagem de dados evolucionßria feita de forma colaborativa.
Apesar de nem todos pensarem assim, a modelagem de dados pode ser uma das mais desafiantes tarefas que um DBA pode estar envolvido em um projeto de desenvolvimento ßgil.
Como vocÛ melhora suas habilidades de modelagem de dados? Prßtica, prßtica, prßtica. Se vocÛ tiver a chance, vocÛ deve trabalhar pr¾ximo a DBAs, se ofereþa para trabalhar na modelagem de dados e pergunte sobre o andamento do trabalho. Isso farß com que um profissional sempre evolua seu conhecimento na ßrea, tanto na modelagem l¾gica como na modelagem fÝsica.
AlÚm disso, vocÛ pode ter a oportunidade de trabalhar com o arquiteto da empresa. Estes profissionais tambÚm possuem bastante conhecimento sobre o domÝnio das aplicaþ§es e como abstraÝ-los para a modelagem dos dados.
AlÚm de tudo isso, Ú preciso estar sempre atualizado lendo informaþ§es sobre a ßrea. Este artigo Ú um bom ponto de partida, apresentando uma breve introduþÒo sobre o tema. No entanto, Ú importante ler muito mais informaþ§es sobre o assunto para se tornar um especialista.


Utilizamos cookies para fornecer uma melhor experiÛncia para nossos usußrios, consulte nossa polÝtica de privacidade.