


Diante das constantes modificaçőes tecnológicas e a crescente demanda por serviços web que atendam as requisiçőes de acesso em tempo real, se faz necessário ter uma soluçăo que se adapte ŕs estas mudanças. Visto que os sistemas de informaçăo tornaram-se onerosos, com o advento do NoSQL e a sua nova abordagem no tratamento dos dados, tendo como base a utilizaçăo do par, chave-valor, que trouxe a agilidade necessária para as demandas atuais.
Neste contexto, a fim de unir a infraestrutura atual das organizaçőes com todas as vantagens de um sistema de banco de dados relacional, ao sistema de banco de dados NoSQL, este artigo visa propor a construçăo de uma soluçăo híbrida, procurando reunir o modelo relacional do MySQL Server junto ŕ API do próprio, que oferece suporte ŕ interface NoSQL.
Pretende-se com essa abordagem técnica atender a uma aplicaçăo que demande disponibilidade operacional 24x7, tal como a de um comércio eletrônico, por exemplo.
Entre as funcionalidades de um SGBD destacam-se o aprovisionamento dos privilégios de acesso, a disposiçăo de planos de backup e recuperaçăo, otimizaçăo de consultas, performance, disponibilidade, controle da redundância e da segurança dos dados.
O principal objetivo de um SGBD é o de proporcionar um ambiente tanto conveniente quanto eficiente para a recuperaçăo e armazenamento das informaçőes do banco de dados.
Um SGBD é composto por um conjunto de softwares que săo adotados como os gerentes dos bancos de dados a fim de proteger o controle dos negócios. Dentre os modelos de dados mais utilizados, este artigo abordará as caraterísticas do relacional e do NoSQL.
De acordo com DB-Engines (2015), o modelo relacional é o tipo de banco de dados mais utilizado do mercado. Classificado no topo do ranking dos SGBDs, o modelo ocupa as tręs primeiras posiçőes: Oracle seguido do MySQL e SQL Server.
O modelo relacional representa os dados como uma coleçăo tabelas. Cada entidade possui uma estrutura que se repete a cada linha, como pode-se observar ao utilizar uma planilha, onde cada linha representa um registro e cada coluna, um tipo de dado.
A Figura 1 apresenta o modelo ER - Entidade Relacionamento, que ilustra as entidades, atributos e relacionamentos de um banco de dados relacional.

Figura 1. Representaçăo do Modelo Entidade Relacionamento
Conforme evidenciado por Suehring (2002), um banco de dados relacional é uma coleçăo de uma ou mais tabelas, que se relacionam.
Este modelo destaca-se pela geręncia das transaçőes por meio da propriedade ACID - Automaticidade, Consistęncia, Isolamento e Durabilidade, se comprometendo com a autenticidade dos dados. As principais vantagens desta abordagem săo a independęncia e a visăo múltipla dos dados.
Este modelo pretende suprir os problemas de escalabilidade apresentado pelos modelos de dados tradicionais, garantindo alto desempenho para ambientes que necessitam da agilidade das transaçőes. (Nascimento, 2010).
NoSQL possui a capacidade de trabalhar com dados năo estruturados, contribuindo com diversos ramos, como a medicina, inteligęncia artificial e a estatística, a partir da análise, com precisăo, de uma grande massa de dados. Com o advento desse banco é possível traçar estratégias eficazes adequadas a cada tipo de negócio.
O modelo NoSQL, baseado no par, chave-valor, é composto por uma coleçăo de dados indexados a partir da sua respectiva chave, sendo adequado para a proposta deste artigo, que pretende agilizar o tempo de resposta da aplicaçăo, conforme apresentado na Figura 2.
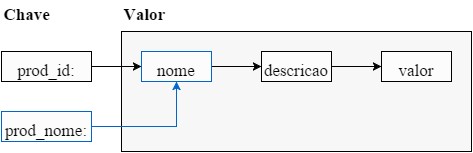
Figura 2. Representaçăo do modelo NoSQL baseado no par Chave-Valor
Independentemente das vantagens do banco relacional ou do NoSQL, năo há uma regra que defina a melhor soluçăo, visto que esta decisăo cabe a aplicaçăo que melhor se adequará ŕ tecnologia.
Em contraponto, segundo Dias (2014), há situaçőes em que é viável unir os dois modelos, usufruindo dos potenciais de ambos. É comum o uso de soluçőes híbridas, que usam tanto banco relacional como NoSQL. Um exemplo disso é quando em um produto há demanda por um controle transacional e, ao mesmo tempo, picos de acessos que exigem baixo tempo de resposta.
Diferentemente do modelo convencional, onde os bancos estăo centralizados em um único servidor, os bancos distribuídos săo dispersos em vários servidores, uma vez que os mesmos podem ser replicados geograficamente, aumentando a segurança dos dados em caso de catástrofes. A Figura 3 apresenta o modelo desta arquitetura.
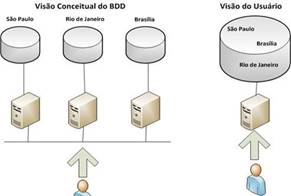
Figura 3. Arquitetura de Banco de Dados Distribuído
Um banco de dados distribuído é um conjunto de banco de dados parciais independentes que compartilha um esquema comum e que coordena o processamento de transaçőes com acesso de dados năo local. Dentre as características destaca-se a transparęncia da replicaçăo ao usuário final.
Com a utilizaçăo de um sistema de banco de dados distribuído, aumenta-se o nível da confiabilidade, disponibilidade e desempenho do banco como um todo, visto que o sistema será capaz de gerenciar um alto tráfego.
Cluster pode ser definido como um sistema que compreende dois ou mais computadores que trabalham de maneira conjunta para realizar diversos tipos de processamento. (Pitanga, 2003)
Cada computador de um cluster é chamado de nó. Os nós de um cluster dividem as tarefas de processamento e trabalham como uma única máquina.
Um cluster deve estar previamente preparado para receber novos nós em sua arquitetura, ou ainda, em caso de danos, estar preparados para a retirada de um deles. Neste caso, todo o processamento destinado ŕquele nó deve ser redistribuído aos demais. Isto se faz necessário para que a remoçăo de um dos nós năo interfira no funcionamento do cluster como um todo.
Este artigo aborda a implementaçăo de um cluster de alta disponibilidade com o balanceamento de carga a fim de aumentar a disponibilidade e a escalabilidade dos serviços.
Este tipo de cluster tem como finalidade prover, de maneira ininterrupta, a disponibilidade e a distribuiçăo dos seus serviços entre os nós que compőe o cluster. Estas operaçőes se apresentam de maneira transparente ao usuário.
A disponibilidade de um serviço é calculada com base na porcentagem que quantifica a probabilidade de encontrar o serviço operacional em determinado momento. A esta porcentagem associa-se o termo Uptime do serviço, isto é, tempo em que o serviço se encontra operacional. Deste modo, A (t) é a probabilidade de que o sistema esteja funcionando e pronto para uso em um dado instante de tempo t.
Com a incorporaçăo de mecanismos contra falhas, pode-se aumentar a disponibilidade do sistema.
A combinaçăo da Alta Disponibilidade com o Balanceamento de Carga é adequada para ambientes que trabalham diretamente com o desempenho do cluster.
Clusters de balanceamento de carga săo amplamente utilizados em serviços de comércio eletrônico e provedores de internet, visto que, estes ambientes necessitam resolver as diferenças de carga provenientes de múltiplas requisiçőes de entrada em tempo real.
No entanto, a eficięncia de um comércio eletrônico é calculada através da disponibilidade e da capacidade de gerenciar com eficięncia os recursos computacionais de toda a sua infraestrutura.
Dentro deste escopo de desenvolvimento foram implementadas sete máquinas virtuais com o Sistema Operacional Linux Debian, sendo quatro máquinas, em particular, para viabilizar o MySQL Cluster DB.
Na composiçăo do MySQL Cluster, duas máquinas foram destinadas como nós gerentes e as outras duas como nós de dados e SQL (para essas duas, uma de redundância, em espelho). Uma característica importante desta estrutura é que os nós de SQL recebem o balanceamento de carga, contribuindo com múltiplas consultas simultâneas.
Para a viabilizaçăo da API NoSQL, foi aplicado um cluster, master-slave, a partir de duas máquinas, visando a garantia da disponibilidade do cache em caso de queda de um dos nós. E, uma última máquina, utilizada para a instalaçăo da aplicaçăo.
Portanto, pode-se afirmar que esta infraestrutura dispőe de dois clusters, um para o MySQL e outro para o NoSQL, que operam como um cluster integrado, em paralelo, visando oferecer alta disponibilidade da aplicaçăo.
Estruturada na linguagem PHP, a página de teste desta infraestrutura é voltada ao comércio eletrônico, ramo onde a eficięncia da aplicaçăo pode determinar a valorizaçăo do negócio.
Dentre as configuraçőes de hardware utilizadas para a implementaçăo desta soluçăo, destacam-se: um Processador Intel Core i5, segunda geraçăo, e 8GB de memória RAM.
A Figura 4 apresenta a infraestrutura que atenderá a interface NoSQL:
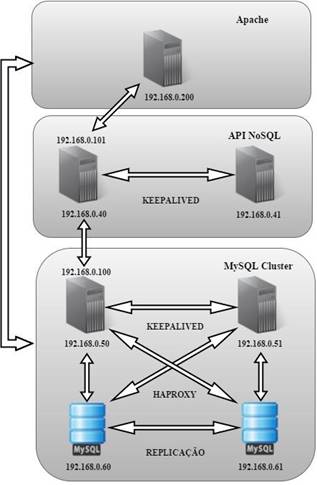
Figura 4.Cenário da infraestrutura dos clusters
O nó de aplicaçăo se comunica com o master do Cluster NoSQL através do seu IP Virtual, retornando os dados solicitados pela aplicaçăo.
O cache viabiliza a diminuiçăo de carga no servidor de banco de dados, reportando a disponibilidade da página e a navegabilidade do site para o Cluster NoSQL.
Já o sistema de busca da aplicaçăo e as atualizaçőes no site que exijam do modelo transacional, serăo direcionadas aos nós de SQL, como pode-se observar ao efetuar uma compra.
Quando houver atualizaçőes de registros no banco via aplicaçăo, será invocada a atualizaçăo do cache, que por sua vez, se comunica com o master dos nós gerentes do MySQL Cluster.
A carga de acesso aos nós de SQL é dividida por meio do balanceamento de carga, que checa os bancos ativos intercalando as conexőes entre os nós.
A Tabela 1detalha as configuraçőes presentes em cada nó com os seus respectivos serviços:
| Componente | Host | Memória |
Serviços |
IP Virtual |
| Aplicaçăo | 192.168.0.41 | 1GB | MemCached e KeepAlived | - |
| Master1 | 192.168.0.50 | 512MB | Management node, KeepAlived e HAProxy | 192.168.0.100 |
| Master2 | 192.168.0.51 | 512MB | Management node, KeepAlived e HAProxy | - |
| Slave1 | 192.168.0.60 | 1,5GB | NDB e SQL node | - |
| Slave2 | 192.168.0.61 | 1,5GB | NDB e SQL node | - |
Tabela 1.Configuraçőes e serviços de cada nó do cluster
Nas próximas sessőes deste artigo serăo detalhadas as principais características das ferramentas utilizadas na composiçăo desta soluçăo.
É um sistema de banco de dados relacional, cliente/servidor, desenvolvido para manipular grandes quantidades de dados garantindo agilidade e confiabilidade das informaçőes.
“O MySQL é o banco de dados de código aberto mais popular do mundo, com uma estimativa de mais de 15 milhőes de instalaçőes e dezenas de milhares de novos downloads diários”. Oracle apud Gartner (2008).
Considerado um dos servidores de bancos de dados relacionais mais rápidos do mundo, o MySQL foi desenvolvido com o intuito de manter o custo baixo na instalaçăo e manutençăo do banco de dados.
“O MySQL é reconhecido por sua capacidade de ser executado e dimensionado horizontalmente em todo o hardware. Isso o tornou o banco de dados preferencial para os aplicativos mais exigentes e das maiores empresas na web, incluindo o Facebook, que tem milhares de servidores MySQL e escalou o MySQL para gerenciar mais de 1 bilhăo de usuários ativos”. (Oracle, 2012)
É um software livre projetado para oferecer disponibilidade de 99,999% com a garantia de recuperaçăo de falhas e a capacidade de realizar a manutençăo programada, sem tempo de inatividade. (Oracle, 2015)
O MySQL Cluster consiste na aplicaçăo, responsável pela interface com o cliente, onde recebe as consultas por meio do SQL Node, um servidor MySQL tradicional que utiliza o motor de armazenamento NDB Cluster, onde é realizado o processamento dos dados. Estes processos săo gerenciados pelo Management Node, utilizado pelos administradores de banco dados a fim de configurar, inicializar e parar os nós. (Oracle, 2015)
A Figura 5 apresenta a disposiçăo destes serviços entre os nós:
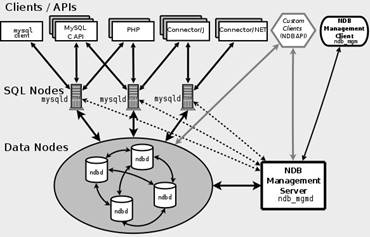
Figura 5.Arquitetura do MySQL Cluster
O MySQL Cluster garante a integridade dos dados por meio da replicaçăo síncrona, onde as transaçőes săo concluídas quando todos os nós confirmarem a sua atualizaçăo. Deste modo, pode-se afirmar que os pontos de falhas săo contornados por meio do espelhamento dos dados entre os Data Nodes, garantindo a disponibilidade da aplicaçăo.
Dentre os clientes desta tecnologia, destacam-se: Apple, Juniper, PayPal, Sky, empresas de telefonia, dentre outros. O MySQL Cluster deve ser considerado como uma soluçăo para ambientes que visam a performance, escalabilidade, disponibilidade, flexibilidade, estabilidade e a segurança, observando o custo total da propriedade e o conhecimento da equipe. (Lastori, 2013)
A Oracle integrou capacidades NoSQL junto ao MySQL Cluster, a partir da versăo 7.2.1, garantindo a eficięncia no acesso aos dados.
Conforme descrito pela Oracle (2015), mantenedora da comunidade MySQL, com a API MemCached padrăo, o aplicativo envia, lę e escreve para o processo MemCached, que por sua vez, chama o driver MemCached para NDB. Deste modo, consultas a partir da API NDB, tem o acesso mais rápido aos dados mantidos em nós de dados do MySQL Cluster, pois o mesmo ignora a camada de SQL.
“MemCached é a API popular que ‘fala’ NoSQL, provę alta performance, especialmente para aplicaçőes web diminuindo a carga do banco de dados relacional. Utilizado pelo Twitter, Facebook, YouTube e entre outros”. (MySQL, 2011).
Esta soluçăo foi projetada com o intuito de prover a flexibilidade de uso, sendo possível co-localizar a API MemCached em todos nós ou somente nos nós de dados, de aplicaçăo ou, em alternativa, situá-la em uma camada MemCached dedicada.
A API se utiliza da memória RAM disponível no servidor, guardando em cache os dados acessados com frequęncia. Com a utilizaçăo deste cache, há uma diminuiçăo de carga no servidor, suportando um alto tráfego sem a necessidade de aumentar os recursos da infraestrutura.
A principal vantagem da utilizaçăo desta API, está na velocidade do acesso aos dados, assegurando o desempenho em tempo real, sem descumprir com as propriedades ACID presentes no banco MySQL.
HAProxy, que significa High Availability Proxy, é um poderoso software open source, leve e de fácil configuraçăo, voltado para aplicaçőes baseadas nos protocolos TCP (Transmission Control Protocol) e HTTP (Hypertext Transfer Protocol). (HAProxy, 2015)
Esta ferramenta dispőe de recursos de alta disponibilidade, balanceamento de carga e proxy. No entanto, o HaProxy é apto para atender a demanda de toda a infraestrutura de um serviço web, seja aplicaçăo ou banco de dados, suportando milhares de conexőes em hardwares modestos. (HAProxy, 2015)
O HaProxy é utilizado como uma alternativa eficiente para a melhoria do desempenho e da confiabilidade de um servidor por meio da distribuiçăo da carga de trabalho entre os seus nós.
A ferramenta é amplamente utilizada por empresas que avaliam o balanceamento de carga como recurso prioritário para a estabilidade dos seus negócios, como o GitHub, Instagram e Twitter.
É um framework que mantém a disponibilidade de um serviço por meio do protocolo VRRP - Virtual Routing Redundancy Protocol, que elege o nó com maior prioridade como mestre e os demais, como backup. Os níveis de prioridade săo definidos no arquivo de configuraçăo do KeepAlived.
O nó principal (mestre) recebe um IP Virtual que estabelece a comunicaçăo com a aplicaçăo, enquanto os nós de backup ouvem a atividade do mestre. No entanto, o KeepAlived efetua checagens a nível de rede, transporte e aplicaçăo. Se uma das checagens falhar, o mesmo se encarrega de direcionar o IP Virtual para o servidor de backup, que assumirá o serviço.
Para configurar um ambiente de alta disponibilidade é necessário, no mínimo, dois servidores, um definido como mestre e o outro como backup, garantindo a atividade da aplicaçăo em caso de falhas.
O Apache é um servidor web, open source, responsável pela troca de informaçőes com outras máquinas, que săo chamadas de clientes, onde o cliente solicita as informaçőes e o servidor atende aos pedidos. (Alecrim, 2006)
Com esta troca de dados, o Apache disponibiliza a página web, sendo possível realizar compras on-line, enviar e-mails, checar extrato da conta bancária e entre outros.
Um servidor web necessita estar disponível ininterruptamente a fim de atender as solicitaçőes sempre que houver a necessidade.
PHP (Hypertext Preprocessor) é uma linguagem de script, open source, adequada ao desenvolvimento web, podendo ser embutida dentro do HTML. (PHP, 2015)
Todo código PHP é executado no servidor, tornando-o capaz de interagir com um banco de dados ou aplicaçőes internas. Uma das grandes vantagens desta característica é o de năo expor o código fonte para o cliente, contribuindo com a segurança no gerenciamento de senhas e de informaçőes confidenciais. (PHP, 2015)
O PHP é uma das linguagens mais populares do mundo que destaca por sua velocidade e flexibilidade, além de possuir a orientaçăo a objetos.
Conforme evidenciado por Harrington (2010), a parte mais lenta das açőes de um Sistema Gerenciador de Banco de Dados é a de recuperar e gravar dados no disco. Partindo deste princípio, com a incorporaçăo do MemCached, oferecido pela API NoSQL, é possível utilizar o par chave-valor, garantindo o acesso a partir da consulta dos dados em memória que, juntamente com o cluster MySQL, provę a distribuiçăo da carga de operaçőes, de acordo com a sua finalidade: consultas nas sessőes do site săo dirigidas ao cluster NoSQL e transaçőes săo dirigidas ao cluster MySQL.
Essa proposta, se deu ŕ natureza da aplicaçăo do comércio eletrônico que, em geral, tem um volume alto de consultas em detrimento a um volume menor de transaçőes.
Portanto, admite-se que a proposta vem de encontro a oferecer, de fato, uma soluçăo que utilize o melhor dos dois modelos, relacional e NoSQL: para o relacional, transaçőes com a garantia de integridade e, para o NoSQL, a altíssima eficięncia em consultas.
Diferentemente do modelo convencional, onde o acesso aos dados em um banco relacional é cedido por meio do padrăo SQL - Structured Query Language, com a API MemCached é possível atribuir capacidades NoSQL ao SGBD MySQL.
O banco de dados ndbmemcache é responsável pela atribuiçăo do modelo chavevalor ao MySQL, contendo tręs tabelas que determinam o comportamento da interface NoSQL: containers, produto e key_prefixes.
A Figura 6 apresenta a entidade containers com 16 registros que estabelecem a comunicaçăo com a tabela produto, onde os dados săo representados no formato chave-valor, conforme ilustrado na Figura 7.
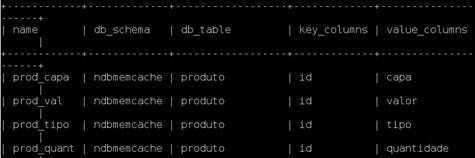
Figura 6.Demonstraçăo da formaçăo do modelo chave-valor
A Figura 7 representa um dos registros presentes na página principal, cujo prefixo do
identificador atribuído ao produto corresponde a sua sessăo no site.
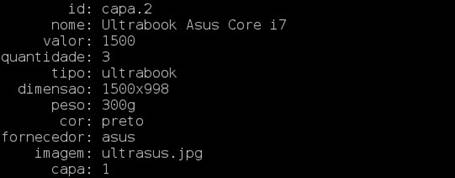
Figura 7.Demonstraçăo dos dados no formato chave-valor
A tabela key_prefixes é responsável pela definiçăo das chaves com os seus respectivos privilégios de acesso ŕ tabela containers, que por sua vez, se comunica com os dados no formato chave-valor da tabela produto. A Figura 8 apresenta o modelo das chaves definidas que servirăo a aplicaçăo.

Figura 8.Definiçăo das chaves do modelo chave-valor
Deste modo, o daemon MemCached fará a comunicaçăo com o banco ndbmemcache quando for invocada uma atualizaçăo do cache ou quando for solicitado um dado que năo esteja em memória.
Foram implementadas duas funçőes no PHP com o intuito de controlar o sistema NoSQL, deixando-o sempre atualizado e disponível para novas requisiçőes de acesso.
A primeira funçăo, denominada como, update_memcache(), conta com a busca dos dados da capa do site através do padrăo SQL a fim de inseri-los nas tabelas destinadas ao cache, conforme ilustrado na Listagem 1.
Listagem 1.Demonstraçăo da funçăoupdate_memcache()
while($produto=mysql_fetch_row($vet)){
$ident= “capa.”.$i;
//Nome
$key_chave= ‘prod_nome:’ . $ident;
$value_chave = “produto[1]”;
$m->set($key_chave,$value_chave);
//Descriçăo
$key_chave= ‘prod_desc:’ . $ident;
$value_chave = “produto[2]”;
$m->set($key_chave,$value_chave);
}O tempo de atualizaçăo do cache da página principal é de aproximadamente 1,5 segundos. Esta funçăo também é encarregada pela atualizaçăo dos demais produtos que săo distribuídos entre as sessőes do site.
A atualizaçăo total do cache é de aproximadamente 4 minutos, onde 4.999 produtos săo enviados para o sistema de cache. No entanto, o tempo de atualizaçăo năo traz prejuízos ao negócio, visto que, todas transaçőes săo direcionadas ao MySQL Cluster, que se encarrega de executar o commit (que atualiza as alteraçőes no disco) a nível do SGBD.
A segunda funçăo, chamada de search_body_memcache(), procura os dados no cache para compor os dados da aplicaçăo. Esta funçăo será invocada todas as vezes que uma nova consulta for realizada ou que novas solicitaçőes de acesso ao site forem iniciadas. A Listagem 2 apresenta uma demonstraçăo de como os valores săo buscados no cache NoSQL:
Listagem 2.Demonstraçăo da funçăosearch_body_memcache()
$m=new Memcached();
$m=addServer(‘192.168.0.01’,11211);
while($i<27){
$result[$i]=$m->get(“prod_capa:$capa.$i”);
$nome=$m->get(“prod_nome:$capa.$i”);
$marca=$m->get(“prod_marca:$capa.$i”);
}A fim de demonstrar a eficięncia do MySQL Cluster unido ŕ API MemCached, foram aplicados testes de desempenho a partir da aplicaçăo, que dispőe de 26 produtos em sua vitrine dos 4.999 produtos armazenados nos bancos de dados.
O cache NoSQL pretende atender todas sessőes do site, tornando a carga do banco de
dados mais leve. A Figura 9 apresenta parte da página principal do site:
Figura 9. Página principal da aplicaçăo de teste
A primeira prova desta soluçăo é destinada a performance da aplicaçăo com o cluster de banco de dados e, em seguida, é apresentada a proposta da camada NoSQL. No entanto, a Figura 10 demonstra os nós ativos durante a execuçăo dos testes de atualizaçăo do cache e consulta ao banco de dados a fim de justificar a atividade do cluster:
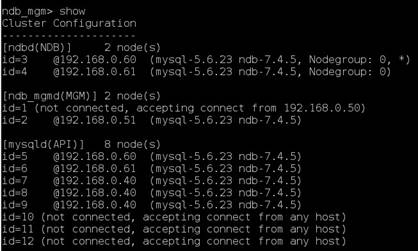
Figura 10.Listagem dos nós ativos do cluster
O cluster é operado com apenas um nó gerencial ativo, demonstrando a estabilidade dos serviços em meio a parada de um dos seus componentes.
O cluster também conta com dois nós de dados e SQL ativos além de contar com tręs nós de cache, que correspondem ŕ primeira máquina do MemCached.
Em ambos testes, seja na consulta ao banco ou no cache, foram simuladas 100 conexőes simultâneas através da ferramenta ApacheBench, aumentando o número de conexőes até 1000. A seguir, serăo demonstrados os resultados desta operaçăo.
De acordo com os resultados obtidos pelo ApacheBench, foram gastos 44 segundos
para a conclusăo do teste, sendo que, 882 das 1000 requisiçőes apontaram falhas.
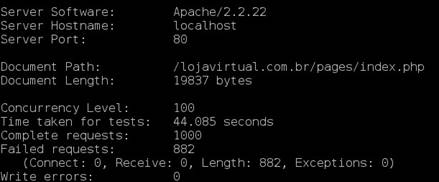
Figura 11.Requisiçőes de acesso ao banco de dados
A Figura 12 apresenta o número máximo de requisiçőes por segundo e o tempo de conexăo em milissegundos:
Figura 12.Tempo das requisiçőes de acesso
Também foi submetida na página a funçăo microtime() da linguagem PHP em um período sem tráfego na aplicaçăo. O tempo de acesso ŕ página foi satisfatório, visto que, o mesmo năo ultrapassou 1,5 segundos.
Após a atualizaçăo do cache no NoSQL, foi submetido o teste do ApacheBench ao sistema NoSQL. A Figura 13 apresenta o resultado.
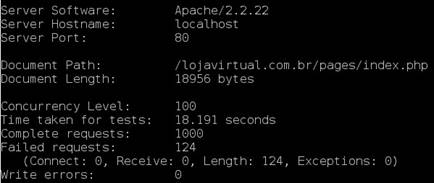
Figura 13.Requisiçőes de acesso ao sistema NoSQL
Do mesmo modo, foi avaliado o tempo de requisiçőes com o cache NoSQL, conforme apresentado na Figura 14.

Figura 14.Tempo das requisiçőes de acesso aliado ao NoSQL
O tempo de resposta da aplicaçăo utilizando a funçăo microtime() para a consulta no cache NoSQL em um momento sem tráfego, obteve praticamente o mesmo resultado da consulta direta ao banco. A página foi carregada em apenas um 1 segundo.
Considerando 2GB de RAM, segmentado entre as máquinas de cache e aplicaçăo, o resultado dos testes com o ApacheBench demonstra que o site suportou 876 conexőes com eficięncia.
A Tabela 2 apresenta o resumo dos testes de desempenho da aplicaçăo, tendo como vertentes: a comunicaçăo do site com o banco de dados e a incorporaçăo da camada de cache NoSQL nesta infraestrutura.
| Teste | Número de requisiçőes | Número de processos concorrentes | Número de requisiçőes por segundo | Tempo utilizado pelas consultas (s) | Número de falhas |
| Banco de dados | 1000 | 100 | 22.68 | 4.409 | 822 |
| Cache NoSQL + BD | 1000 | 100 | 54.97 | 1.819 | 124 |
Tabela 2. Resumo dos testes de desempenho
A partir dos dados apresentados, pode-se afirmar que o sistema de cache é altamente recomendável para ambientes que necessitam gerenciar um alto tráfego de acesso com segurança e agilidade no acesso ŕ informaçăo, visto que com a incorporaçăo do sistema NoSQL, as falhas nas requisiçőes de acesso diminuíram quase 7 vezes em relaçăo ao modelo que contempla somente a tecnologia do MySQL Cluster.
A soluçăo cache NoSQL, associada ao banco de dados é adequada para ambientes críticos, onde a segurança da informaçăo e o tempo de resposta săo essenciais para a evoluçăo do negócio. A infraestrutura proposta garante a integridade dos dados através do modelo relacional unido ao melhor do NoSQL por meio do cache chave-valor, que assegura um tempo de resposta ágil para as demandas atuais.
Este tipo de implementaçăo é justificado para ambientes que se utilizam de dados sigilosos, como o número da conta bancária de um cliente, cenário onde os bancos devem ser bem estruturados a fim de que o sistema năo apresente brechas de segurança e entre outras falhas de normalizaçăo que podem ser tratadas nos bancos relacionais. No entanto, somente os dados com um baixo nível de exposiçăo aos riscos serăo entregues ao cache NoSQL, năo comprometendo a autenticidade de dados importantes.
Referęncias
ALTMANN, Marcelo. MySQL
& NoSQL - Memcached Plugin
Http://planet.mysql.com/entry/?id=5988879
BADGLEY, Jarvis. Introduction
to using MySQL as a NoSQL store via Memcached
http://chipersoft.com/p/MySQL-via-Memcache/
FROM DUAL. Making
HaProxy High Available For MySQL Galera Cluster
http://www.fromdual.com/making-haproxy-high-available-for-mysql-galera-cluster
HARRINGTON, Jan. Projeto de Bancos de Dados Relacionais: Teoria e Prática. 2 ed. Rio de Janeiro: Campus, 2002.
HAPROXY. HAProxy - A
carga confiável, de alto desempenho TCP / HTTP Balancer
http://www.haproxy.org/#desc
LASTORI, Airton. MySQL
Cluster - Visăo geral
http://pt.slideshare.net/MySQLBR/mysql-cluster-viso-geral
MORGAN, Andrew. Scalable,
Persistent, HA NoSQL Memcache Storage Using MySQL Cluster.
http://www.clusterdb.com/mysql-cluster/scalabale-persistent-hanosql-memcache-storage-using-mysql-cluster
REFERENCE MANUAL: Using
MySQL with memcached
http://dev.mysql.com/doc/refman/5.1/en/ha-memcached.html


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.