
Clique aqui para ler todos os artigos desta ediçăo
MySQL Cluster Disponibilidade total
Renato A. Golin
Quando pensamos em segurança dos dados, a primeira coisa que vem ŕ mente é criptografia.
Esse é, de fato, um quesito fundamental da segurança, mas năo é o único e, sozinho, năo garante segurança alguma.
Segundo o British Standards Institute (equivalente ŕ ISO para segurança), a segurança da informaçăo é caracterizada pela preservaçăo da confidencialidade, integridade e disponibilidade.
Neste artigo vamos cobrir a parte de disponibilidade, que é o maior benefício do MySQL Cluster.
O que é o MySQL Cluster?
O MySQL Cluster é uma tecnologia que foi oficialmente lançada na versăo 4.1.12 do MySQL Max e ainda está sob um desenvolvimento pesado para que todas as funcionalidades do MySQL padrăo sejam adicionadas ao Cluster.
Essa tecnologia é hoje, como o resto do MySQL, software livre.
Em uma replicaçăo tradicional, o MySQL copia todos os dados do master para o slave mas sem a obrigaçăo de garantir que os dados foram copiados corretamente. Diferentemente, o Cluster garante a integridade dos dados em todos os nós ao mesmo tempo, ou seja, o cluster se certifica que inseriu o dado em cada nó (máquinas que compőe o cluster) antes de disponibilizar esse dado para outro usuário. Isso é o que chamamos de replicaçăo síncrona. Isso acontece por que o Cluster armazena cada pedaço do seu dado em mais de um nó ao mesmo tempo para que, quando um dos nós falhar, seus dados permaneçam acessíveis
a partir do outro nó.
Outra vantagem do Cluster é que năo é compartilhada nenhuma informaçăo sobre configuraçăo entre os nós, ou seja, năo é preciso mudar a configuraçăo de todos os nós atuais para adicionar mais um. Com isso, fica fácil adicionar novas máquinas, sendo possível aumentar o poder de processamento do seu cluster sem a necessidade de reconfigurar todo o cluster.
Administrar tudo isso pode parecer complicado, entrar em cada máquina para configurar cada uma, mas o MySQL facilitou a vida do DBA criando um servidor de configuraçăo que cuida de todos os parâmetros, logs, controle dos nós e adiçăo de mais nós ao cluster. É o chamado Management Node (ou nó gerencial).
O MySQL Cluster consegue funcionar exatamente como um servidor MySQL tradicional, executando suas queries e retornando os dados obtidos como se fosse qualquer outro servidor MySQL: o Cluster é transparente para o usuário, para a sua aplicaçăo e até para o cliente MySQL (texto ou MySQL Admin).
Resumindo: o MySQL Cluster garante a disponibilidade dos seus dados de forma síncrona e transparente, é facilmente gerenciável e escalável e ainda por cima, é livre!
Agora vamos ver quais săo as peças existentes no Cluster e o que cada uma delas faz para garantir a disponibilidade dos seus preciosos dados.
Arquitetura
O Cluster é composto por tręs tipos diferentes de nós:
• Data Node (nó de dados): onde săo armazenados seus dados;
• Management Node (nó de gerenciamento): que controla o cluster;
• SQL Node (nó SQL): onde săo executadas as queries.
E dois tipos diferentes de clientes:
• MySQL Client (cliente do banco): que administra
os nós SQL (e executa queries também);
• Management Client (nó de dados): que administra o restante do cluster de banco de dados.
Essa arquitetura pode ser resumida pela Figura 1.
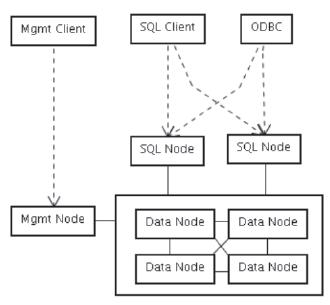
Figura 1. Resumo da arquitetura do MySQL Cluster.
O conceito de nó está relacionado ŕ parte do programa que está em execuçăo. Se uma máquina roda o programa ndbd, que é o programa relacionado ao nó de dados, esta máquina pode ser considerada um nó de dados. É possível ter mais de um nó em cada máquina como rodar o nó de gerenciamento e um nó SQL, mas a idéia é instalar cada componente do Cluster em uma máquina separada, pois afinal, estamos falando de disponibilidade! O coraçăo do MySQL Cluster é o grupo de nós de dados.
Esses nós compartilham os dados entre si em uma arquitetura que possui dois conceitos básicos: réplicas e fragmentos.
Réplicas săo o número de vezes que o dado aparecerá no cluster como um todo e Fragmentos săo o número de pedaços em que essa réplica será repartida e distribuída nos nós de dados, ou seja, se tivermos duas réplicas, teremos cada dado armazenado no banco duas vezes, e se tivermos dois fragmentos, precisaremos de dois nós de dados diferentes para armazená-las.
Na Figura 2 ...

