NoSQL é um movimento que promove soluçőes de armazenamento de dados năo relacionais. Ele é composto por diversas ferramentas que, de forma particular e específica, resolvem problemas como tratamento de grandes volumes de dados, execuçăo de consultas com baixa latęncia e modelos flexíveis de armazenamento de dados, como documentos XML ou JSON.
As tecnologias NoSQL năo tęm como objetivo substituir os bancos de dados relacionais, mas apenas propor algumas soluçőes que em determinados cenários săo mais adequadas. Desta forma é possível trabalhar com tecnologias NoSQL e banco de dados relacionais dentro de uma mesma aplicaçăo.
As ferramentas apresentadas neste artigo săo importantes em cenários onde sistemas de banco de dados tradicionais năo săo suficientes ou adequados ŕs necessidades específicas, tais como: baixa latęncia, grandes volumes de dados, escalabilidade ou estruturas em que as conexőes entre os dados săo tăo importantes quanto o próprio dado. Todas as tecnologias abordadas apresentam situaçőes de uso particulares, que podem ser úteis na substituiçăo dos tradicionais bancos de dados relacionais.
Cada tecnologia NoSQL apresentada neste artigo tem suas próprias características. O Redis adota o modelo chave-valor, utiliza a memória para alocaçăo de dados e é ideal para utilizaçăo de Cache. O MongoDB implementa o modelo baseado em documentos, tem foco no tratamento de grandes volumes de dados e é ideal para grande parte das aplicaçőes web. Já o Neo4j, uma das ferramentas NoSQL mais maduras, tem o modelo baseado em grafos e seus principais casos de uso estăo relacionados a motores de recomendaçăo, análise de rotas geográficas e redes sociais. Por fim, tem-se o Cassandra, que é uma implementaçăo open source do modelo de dados do BigTable com a arquitetura distribuída do Dynamo.
Na primeira parte desta série, foi apresentado o conteúdo teórico, abordando temas como história, arquiteturas e modelos de dados alternativos ao relacional, permitindo compreender que esta nova buzzword está mais relacionada a uma nova escola de pensamento, do que a uma tecnologia em particular.
Esta segunda parte terá um foco prático, tendo como objetivo principal instalar e utilizar, através da linguagem Java, algumas das principais ferramentas NoSQL. Todas elas săo projetos open source, o que nos permite experimentá-las sem ter um custo inicial de aquisiçăo.
As ferramentas apresentadas neste artigo serăo: Redis (chave-valor), MongoDB (documento), Neo4J (grafo) e Cassandra (família de colunas). Elas foram especialmente selecionadas de forma a representar os principais modelos de dados e diferentes arquiteturas apresentadas no primeiro artigo.
O Redis foi criado no início de 2009 pelo italiano Salvatore Sanfilippo com o objetivo de melhorar a performance de seu produto de análise em tempo real de páginas web. Em março de 2010 Salvatore foi contratado pela VMWare para se dedicar exclusivamente ao desenvolvimento do Redis, que hoje conta também com a dedicaçăo do holandęs Pieter Noordhuis, além de contribuiçőes vindas da forte comunidade formada em torno desta ferramenta.
Sem dúvida esta é uma das ferramentas NoSQL mais utilizadas atualmente. Escrito em ANSI C, tem seu modelo baseado em chave-valor e utiliza a memória RAM como principal meio de alocaçăo de dados, porém oferece um mecanismo paralelo de serializaçăo em disco, bem como um mecanismo opcional de log (AOF – Append Only File). Atualmente seu modelo de distribuiçăo de dados é baseado em master/slave, no entanto está em desenvolvimento o recurso de cluster.
Para instalar o Redis faça o download dos fontes (oficialmente ele é distribuído apenas neste formato) da versăo mais recente e estável, descompacte o arquivo e execute o comando make na pasta descompactada (portanto é necessário ter em seu ambiente o make e um compilador C).
O Redis năo é suportado e năo deve ser usado em produçăo em ambientes Windows. Entretanto, caso vocę utilize Windows, poderá usar o Cygwin ou fazer o download de uma versăo já compilada para Windows.
Colocar o servidor do Redis no ar é uma tarefa bem simples, basta executar no terminal (ou no prompt) o comando ./redis-server (ou redis-server.exe no Windows). Feito isso, o servidor do Redis irá gerar algumas mensagens no próprio console, como exibido na Listagem 1. Caso tenha alguma dificuldade, verifique as permissőes de execuçăo do seu usuário.
[22925] 01 Oct 18:38:44 # Warning: no config file specified, using the default config. In order to specify a config file use 'redis-server /path/to/redis.conf'
[22925] 01 Oct 18:38:44 * Server started, Redis version 2.0.2
[22925] 01 Oct 18:38:44 * The server is now ready to accept connections on port 6379
[22925] 01 Oct 18:38:44 - 0 clients connected (0 slaves), 1074272 bytes in usePara acessar o Redis através do Java, utilizaremos a biblioteca Jedis, que implementa o protocolo do Redis em Java. A Listagem 2 mostra o código necessário para adicionar e recuperar um par de chave-valor.
import redis.clients.jedis.Jedis;
public class TesteRedis {
public static void main(String[] args) {
// Estabelece conexăo com o Redis
Jedis jedis = new Jedis("localhost", 6379);
// Adiciona o par chave-valor
jedis.set("cadastro:porcelli:nome", "Alexandre Porcelli");
// Busca o valor a partir da chave
String valor = jedis.get("cadastro:porcelli:nome");
System.out.println("Valor recuperado: " + valor);
jedis.quit();
}
}Neste código a classe Jedis é instanciada com os parâmetros de endereço e número da porta do servidor (“localhost” e 6379, respectivamente). Para armazenar um par de chave-valor utilizamos o método set() passando como parâmetros a chave e o valor. É importante ressaltar que ambos devem ser obrigatoriamente do tipo String. Já para recuperar o valor armazenado, utilizamos o método get() passando a chave desejada como parâmetro. Por fim, fechamos a conexăo com o servidor através do método quit().
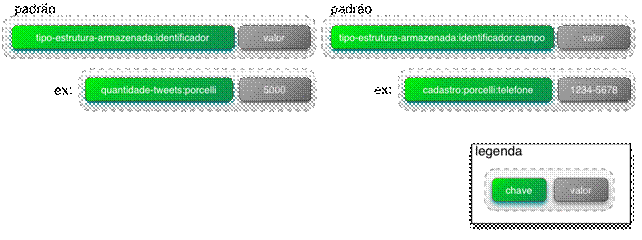
A notaçăo utilizada para representar a chave na Listagem 2 (utilizando o caractere “:” como separador) năo é obrigatória, porém é uma boa prática que pode ser empregada em qualquer key-value store. Esta notaçăo adota o seguinte padrăo: o primeiro elemento identifica o que está sendo armazenado (no caso da Listagem 2, dados de um cadastro), o segundo elemento é o identificador único (que neste exemplo é o nome do usuário porcelli) e o terceiro, que é opcional, representa um campo da estrutura armazenada (neste caso o nome).
Este padrăo pode parecer estranho inicialmente, principalmente quando os dados săo decompostos em campos. Esta decomposiçăo acaba naturalmente gerando um número maior de chaves. Mas tenha em mente que em um modelo de chave-valor vocę só pode obter um dado através de sua chave. Neste exemplo, para obter o nome cadastrado para o usuário porcelli basta utilizar a chave cadastro:porcelli:nome. A Figura 1 mostra dois exemplos de como utilizar este formato.
Para compilar e rodar o código da Listagem 2, execute os seguintes comandos com o servidor do Redis no ar:
$ javac TesteRedis.java -cp jedis.jar
(unix) $ java -cp jedis.jar:. TesteRedis
(windows) C:\ java -cp jedis.jar;. TesteRedisO Redis suporta valores com até 1 Gigabyte de tamanho que săo armazenados no formato string binary-safe (ou seja, uma cadeia de bytes formatada como String). Devido a este formato podemos armazenar e recuperar dados binários como imagens, vídeos ou simplesmente textos.
No exemplo exibido na Listagem 2, utilizamos a estrutura mais simples, porém o Redis disponibiliza outras estruturas de dados mais ricas como Listas, Sets, Sets Ordenados e Hashes, o que torna esta ferramenta bastante útil em diversos cenários.
A utilizaçăo mais comum do Redis é como Cache, substituindo ferramentas como o Memcached, com a vantagem de serializar dados em paralelo no disco (o que permite, em caso de crash, subir o cache já “esquentado”, ou seja, com dados). Outras utilizaçőes comuns săo a implementaçăo de gerenciadores de filas (utilizando o recurso de Listas) e servidores de chat ou broadcast em geral (utilizando o recurso de publish/subscribe).
Para saber mais sobre o Redis, visite: redis.io. Lá vocę encontrará links para uma ótima documentaçăo, bem como alguns exemplos de uso.
O MongoDB, que teve seu primeiro release público em novembro de 2009, foi criado por Dwight Merriman (um dos fundadores da DoubleClick) e Eliot Horowitz (ex-funcionário da DoubleClick), que juntos formaram a 10gen, empresa responsável pelo desenvolvimento e suporte profissional do MongoDB.
Esta é uma ferramenta NoSQL bastante popular, inclusive tem sido considerada o novo M (“anteriormente” ocupado pelo MySQL) da stack LAMP (Linux, Apache, MongoDB e PHP, Perl ou Python). Conta com diversos cases importantes entre start-ups web, como bit.ly (que utiliza o MongoDB para armazenar o histórico de URLs encurtadas de seus usuários) e foursquare (onde o MongoDB é utilizado como ferramenta principal de armazenamento de dados), bem como em empresas mais tradicionais, como é o caso do The New York Times, que passou a utilizá-lo para armazenar dados de uma aplicaçăo para submissăo de imagens.
Sua estrutura de dados é baseada em documento, e tem como principal característica a capacidade de trabalhar com grandes volumes de dados. Inclusive o nome MongoDB vem da expressăo “huMONGOus”, que pode ser traduzida como muito grande ou enorme. Ele é escrito em C++ e disponibilizado, já compilado, para os principais sistemas operacionais. Uma particularidade dessa ferramenta é a capacidade de executar consultas ad-hoc – poucas ferramentas NoSQL oferecem este recurso.
É importante ressaltar que, para usar o MongoDB em produçăo é necessário um ambiente 64 bits (ele funciona em 32 bits, mas com limite de 2GB para armazenamento de dados), bem como executá-lo em mais de uma máquina em cluster (utilizando master/slave ou através de replica-set), pois a durabilidade dos dados no MongoDB é “garantida” apenas através da distribuiçăo dos dados. É previsto para a versăo 1.8, ainda sem data definida, a durabilidade de dados baseado em uma única máquina.
Para instalar o MongoDB basta fazer o download da versăo mais recente e estável (veja seçăo Links) e descompactar o arquivo. Antes de iniciar o MongoDB é necessário criar a pasta onde serăo armazenados os dados. Em ambientes Linux/Mac/Unix, o local padrăo é /data/db (no Windows, C:\data\db).
Colocar o servidor do MongoDB no ar é uma tarefa bastante simples. Basta executar no terminal (ou no prompt) o comando ./mongod (ou mongod.exe no Windows). Dessa forma o servidor irá gerar algumas mensagens no próprio console, conforme a Listagem 3. Caso tenha algum problema na execuçăo do mongod, verifique as permissőes de execuçăo do seu usuário.
Tue Oct 5 11:16:06 MongoDB starting : pid=24582 port=27017 dbpath=/data/db/ 64-bit
Tue Oct 5 11:16:06 db version v1.6.3, pdfile version 4.5
Tue Oct 5 11:16:06 git version: 278bd2ac2f2efbee556f32c13c1b6803224d1c01
Tue Oct 5 11:16:06 sys info: Darwin erh2.10gen.cc 9.6.0 Darwin Kernel Version 9.6.0: Mon Nov 24 17:37:00 PST 2008; root:xnu-1228.9.59~1/RELEASE_I386 i386 BOOST_LIB_VERSION=1_40
Tue Oct 5 11:16:06 [initandlisten] waiting for connections on port 27017
Tue Oct 5 11:16:06 [websvr] web admin interface listening on port 28017No MongoDB os documentos săo armazenados em coleçőes, que por sua vez săo agrupadas em databases. Para melhor entender esta estrutura podemos compará-la com a de um banco de dados relacional, onde:
Para acessá-lo através do Java, assim como no Redis, precisamos de uma biblioteca que implemente seu protocolo. No caso do MongoDB, existe um driver suportado pelo próprio time de desenvolvimento (veja a referęncia em Links). A Listagem 4 mostra um programa Java que adiciona o documento exibido na Listagem 5, e faz uma busca pelo mesmo através de um de seus campos.
import java.net.UnknownHostException;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.mongodb.DBObject;
import com.mongodb.Mongo;
import com.mongodb.MongoException;
public class TesteMongo {
public static void main(String args[]) throws UnknownHostException,
MongoException {
// Abre a conexăo com o servidor do MongoDB
Mongo mongo = new Mongo("localhost", 27017);
// Seleciona um database, caso o database năo exista ele será criado
DB db = mongo.getDB("MeuDatabase");
// Seleciona uma coleçăo para armazenar os dados, caso a coleçăo năo
// exista ela será criada
DBCollection coll = db.getCollection("pessoas");
// Criando o documento
BasicDBObject dados = new BasicDBObject();
dados.put("id", 1);
dados.put("nome", "Alexandre Porcelli");
dados.put("email", " alexandre.porcelli@gmail.com ");
// Criando o sub-documento
BasicDBObject endereco = new BasicDBObject();
endereco.put("rua", "r. qualquer");
endereco.put("numero", 1022);
// Anexando o sub-documento ao documento
dados.put("endereco", endereco);
// Insere o documento no servidor
coll.insert(dados);
// Para executar uma pesquisa com critérios (cláusula where em sql) no
// MongoDB, basta criar um documento modelo que
// contenha os campos e os valores que devem ser pesquisados.
// Portanto aqui é criado a estrutura para encontrar documentos onde o
// campo id tenha o valor igual a 1
BasicDBObject cond = new BasicDBObject();
cond.put("id", 1);
// Executa uma pesquisa que retorna apenas o primeiro documento que
// atenda a condiçăo da busca
DBObject documentoEncontrado = coll.findOne(cond);
System.out.println(documentoEncontrado);
// Fecha a conexăo com o servidor
mongo.close();
}
}{
id : 1,
nome : "Alexandre Porcelli",
email : "alexandre.porcelli@gmail.com",
endereco : {
rua : "r. qualquer" ,
numero : 1022
}
}Neste código a classe Mongo é instanciada com os parâmetros de endereço e número da porta do servidor (“localhost” e 27017, respectivamente) para estabelecer a conexăo com o MongoDB. O próximo passo é obter um database, utilizando o método getDB() passando como parâmetro o nome do database desejado. Caso năo exista, o MongoDB irá criá-lo automaticamente na primeira operaçăo de inclusăo de dados em uma coleçăo deste banco.
Agora precisamos obter uma coleçăo, pois é nela onde o documento será efetivamente armazenado. Para obtę-la, basta chamar o método getCollection() da classe DB com o nome da coleçăo desejada como parâmetro. Caso a coleçăo năo exista, o MongoDB, assim como no caso do database, irá cria-la automaticamente na primeira operaçăo de inclusăo.
Para a criaçăo dos documentos, o MongoDB disponibiliza a classe BasicDBObject, que de fato é uma implementaçăo da interface Map<String, Object>, onde cada chave adicionada no map (utilizando o método put()) se tornará um campo do documento. Nos casos de campos complexos (ou seja, campos compostos por sub-campos), como é o caso do endereço da Listagem 5, basta criar um novo documento com os dados necessários (linhas 23 a 26 da Listagem 4) e adicioná-lo como um valor normal do campo complexo (linha 35). Agora com o documento criado (linhas 23 até 35), basta inseri-lo na coleçăo através do método insert() da classe DBCollection.
Após inserir o documento, vamos realizar uma consulta para encontrá-lo. O MongoDB permite a execuçăo de consultas ad-hoc que podem conter restriçőes (algo parecido com a cláusula where da linguagem SQL). Estas restriçőes, ou condiçőes, podem contemplar um ou mais campos. Neste código de exemplo utilizamos a seguinte condiçăo para encontrar nosso documento: campo id deverá ser igual a 1. Esta restriçăo deve ser passada como parâmetro para o método de consulta através de um documento JSON (linhas 45 e 46 da Listagem 4).
O método que iremos utilizar para executar esta consulta é o findOne() da classe DBCollection, com o parâmetro definido anteriormente. Este método retorna apenas o primeiro documento encontrado. Para consultas onde é necessário buscar mais de um documento, utilize o método find(). Ele retornará um Iterator com os documentos encontrados. Por fim fechamos a conexăo com o servidor através do método close() da classe Mongo.
Para compilar e rodar o código da Listagem 4 execute os seguintes comandos com o servidor do MongoDB no ar:
$ javac TesteMongo.java -cp mongo.jar
(unix) $ java -cp mongo.jar:. TesteMongo
(windows) C:\ java -cp mongo.jar;. TesteMongoUma característica da API do MongoDB é a utilizaçăo extensiva de JSON. Ele foi projetado para utilizar extensivamente, tanto no lado servidor como no cliente, a linguagem JavaScript. E na linguagem JavaScript o formato JSON é nativo. Porém, infelizmente, criar documentos JSON em Java para comunicaçăo com o MongoDB é um pouco burocrático devido a quantidade de código necessário, se compararmos com linguagens como Ruby ou o próprio JavaScript.
No entanto, repare que năo foi preciso fazer nenhuma configuraçăo prévia para executar este código, pois ao executar o método insert() ele se encarrega de criar o database e a coleçăo, caso qualquer um năo exista.
Devido a natureza flexível orientada a documentos de sua estrutura de dados, săo inúmeros os casos de uso para o MongoDB. Existem diversas aplicaçőes web que estăo utilizando esta ferramenta de forma a substituir totalmente o uso de bancos de dados relacionais. Um destaque vai para o armazenamento de informaçőes geoespaciais, que conta com um tipo de índice especial para este tipo de dado. Outra aplicaçăo comum é a utilizaçăo do MongoDB para armazenar logs que serăo posteriormente analisados.
O MongoDB é uma ferramenta repleta de recursos. Alguns dos destaques săo a capacidade de criaçăo de índices e a possibilidade de executar consultas em modo explain, o que permite entender melhor como uma consulta está sendo executada, e de que forma é possível melhorar sua execuçăo tirando maior proveito dos índices criados.
O Neo4j foi idealizado em 2000 pela equipe de uma software house sueca chamada Windh Technologies. Em 2002 já contava com a maior parte dos recursos disponíveis atualmente, e por volta de 2003 teve seus primeiros cases de aplicaçőes importantes rodando em produçăo. Atualmente o Neo4j é desenvolvido e suportado profissionalmente pela Neo Technology (uma spin-off da Windh Technologies).
Esta é uma das ferramentas NoSQL mais maduras. Seu modelo é baseado em grafos, sendo, inclusive, um dos poucos NoSQL que implementam as propriedades ACID. Ele é escrito em Java, o que permite utilizá-lo através de um servidor dedicado ou embarcado dentro de uma aplicaçăo. Para iniciar com o Neo4j basta fazer o download da versăo mais recente e estável do kernel e descompactar o arquivo.
A Listagem 6 mostra um programa Java que utiliza o Neo4J de forma embarcada, e cria uma pequena rede social entre alguns personagens do filme Matrix.
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Node;
import org.neo4j.graphdb.Relationship;
import org.neo4j.graphdb.RelationshipType;
import org.neo4j.graphdb.Transaction;
import org.neo4j.kernel.EmbeddedGraphDatabase;
public class TesteNeo4j {
// Enum que define os tipos de relacionamento entre os nós
public enum MeusTiposDeRelacionamento implements RelationshipType { CONHECE }
public static void main(String[] args) {
// Abre (em caso de năo existir, cria) uma conexăo com o banco de dados de grafo
GraphDatabaseService graphDb = new EmbeddedGraphDatabase("db/matrix-social");
// Inicia a transaçăo
Transaction tx = graphDb.beginTx();
try {
// Criaçăo de nós
Node thomasAnderson = graphDb.createNode();
Node trinity = graphDb.createNode();
Node morpheus = graphDb.createNode();
// Criaçăo de relacionamentos entre os nós (personagens)
Relationship link1 = thomasAnderson.createRelationshipTo(trinity,
MeusTiposDeRelacionamento.CONHECE);
Relationship link2 = trinity.createRelationshipTo(morpheus,
MeusTiposDeRelacionamento.CONHECE);
// Adiciona algumas propriedades nos nós e nos relacionamentos
thomasAnderson.setProperty("nome", "Thomas Anderson");
trinity.setProperty("nome", "Trinity");
morpheus.setProperty("nome", "Morpheus");
morpheus.setProperty("cargo", "Capităo");
link1.setProperty("mensagem", "texto 1!");
link2.setProperty("mensagem", "texto 2!");
// Commit da transaçăo
tx.success();
System.out.println(thomasAnderson.getProperty("nome"));
System.out.println(trinity.getProperty("nome"));
System.out.println(morpheus.getProperty("nome"));
} finally {
// Finalizaçăo da transaçăo
tx.finish();
// Shutdown no banco
graphDb.shutdown();
}
}
}Neste código criamos uma base de dados de grafo através da classe EmbeddedGraphDatabase, que é instanciada recebendo como parâmetro o caminho para o diretório onde os dados serăo armazenados. No caso deste exemplo estamos utilizando o Neo4j de forma embarcada, ou seja, o servidor do Neo4j estará rodando dentro da aplicaçăo. Deste modo, quando a aplicaçăo for encerrada o Neo4j também será encerrado.
Para executar qualquer operaçăo que modifique o estado do grafo é necessário iniciar uma transaçăo através do método beginTx() da interface GraphDatabaseService. Com o objetivo de assegurar que esta transaçăo seja finalizada de forma adequada, todas as operaçőes devem ser executadas em um bloco try/finally.
Criar nós no Neo4j é bem simples, basta executar o método createNode() da interface GraphDatabaseService, que retornará uma nova instância da interface Node. Para criar relacionamentos entre nós, primeiramente é necessário definir os tipos de relacionamento da aplicaçăo através da criaçăo de um enum, que obrigatoriamente deve implementar a interface RelationshipType do Neo4j. No caso da Listagem 6, o enum MeusTiposDeRelacionamento define um único tipo de relacionamento que será utilizado no exemplo (neste caso CONHECER).
O relacionamento entre os nós é criado através do método createRelationshipTo() da interface Node, que deve ser executado no nó de origem, passando como parâmetro o nó de destino, bem como o tipo do relacionamento (valor do enum) que será criado entre eles.
As interfaces Node e Relationship estendem a interface PropertyContainer, que define uma API comum para tratamento de propriedades para ambos os tipos. Portanto, para setar o valor de uma propriedade basta utilizar o método setProperty(), passando como parâmetro o nome da propriedade e seu valor. Do mesmo modo, é possível recuperar o valor de uma propriedade através do método getProperty(), passando como parâmetro o nome desta propriedade.
Para efetivar as modificaçőes feitas no grafo é necessário executar dois métodos da interface Transaction. O primeiro é o success(), que apenas sinaliza que a transaçăo está em estado correto. Já o segundo método, o finish(), é responsável por efetuar o commit no grafo. Caso algum problema ocorra e o método success() năo seja executado, o método finish() irá executar o rollback. Por fim temos o método shutdown() da interface GraphDatabaseService, que encerra as operaçőes do grafo.
Para compilar e rodar o código da Listagem 6 execute os seguintes comandos no terminal (ou no prompt):
$ javac TesteNeo4j.java -cp neo4j-kernel.jar
(unix) $ java -cp neo4j-kernel.jar:geronimo-jta.jar:. TesteNeo4j
(windows) C:\ java -cp neo4j-kernel.jar:geronimo-jta.jar;. TesteNeo4jUtilizar a API do Neo4j é bastante simples, mas năo a subestime. Com poucos recursos é possível criar aplicaçőes bem complexas. Alguns exemplos de uso do Neo4j săo a criaçăo de motores de recomendaçăo e análise de rotas de trânsito, onde ambos necessitam de uma análise detalhada de conexőes entre nós, usando algoritmos como: nós mais conectados ou menor rota entre dois nós.
Outro recurso bastante útil do Neo4j é a exposiçăo de dados no formato RDF (estrutura de dados padrăo do W3C para a web semântica), que permite expressar modelos semânticos que podem ser consultados através da linguagem SPARQL. Veja a seçăo Links para mais informaçőes sobre o formato RDF e a linguagem SPARQL.
O Cassandra nasceu dentro do Facebook para lidar com as buscas nas caixas de entrada de mensagens de seus usuários. Inicialmente foi desenvolvido por Avinash Lakshman (um dos autores do paper sobre o Dynamo da Amazon) e por Prashant Malik. Em Julho de 2008 o Facebook liberou seu código fonte e em março de 2009 se tornou um projeto incubado dentro da fundaçăo Apache. Pouco menos de um ano depois a Apache o promoveu a um projeto top-level.
Seu modelo de dados é baseado em família de colunas e sua arquitetura é totalmente distribuída, o que faz do Cassandra uma implementaçăo do modelo de dados do BigTable com a arquitetura distribuída do Dynamo. Como é escrito em Java, ele é capaz de ser executado em qualquer sistema operacional que tenha uma máquina virtual instalada. No entanto, o Cassandra năo disponibiliza nativamente uma interface para as aplicaçőes cliente, deixando esta funçăo a cargo do Thrift.
Para instalar o Cassandra basta fazer o download da versăo mais recente e estável (veja seçăo Links) e descompactar o arquivo. É importante ressaltar que, assim como o MongoDB, o Cassandra só deve ser colocado em produçăo em uma configuraçăo de cluster, onde os dados serăo distribuídos e replicados em mais de uma máquina.
Colocar o servidor do Cassandra no ar, assim como todos os outros NoSQL que vimos, é uma tarefa bastante simples. Basta executar no terminal (ou no prompt) o comando sudo ./bin/cassandra (ou apenas bin\cassandra.exe no Windows). Dessa forma o servidor irá gerar algumas mensagens no próprio console, conforme a Listagem 7. Caso tenha algum problema na execuçăo, verifique as permissőes do seu usuário (note que é necessário o comando sudo no ambiente *unix, pois o Cassandra utiliza algumas pastas de acesso restrito).
INFO 18:27:30,555 DiskAccessMode 'auto' determined to be mmap, indexAccessMode is mmap
INFO 18:27:30,868 Deleted /var/lib/cassandra/data/system/LocationInfo-13-Data.db
INFO 18:27:30,869 Deleted /var/lib/cassandra/data/system/LocationInfo-14-Data.db
INFO 18:27:30,870 Deleted /var/lib/cassandra/data/system/LocationInfo-15-Data.db
INFO 18:27:30,885 Sampling index and loading saved keyCache for /var/lib/cassandra/data/system/LocationInfo-17-Data.db (0 saved keys)
INFO 18:27:30,895 Deleted /var/lib/cassandra/data/system/LocationInfo-16-Data.db
INFO 18:27:30,901 loading row cache for LocationInfo of system
INFO 18:27:30,907 completed loading (6 ms; 0 keys) row cache for LocationInfo of system
INFO 18:27:30,909 loading row cache for HintsColumnFamily of systemA Listagem 8 mostra o código Java necessário para adicionar e recuperar dados de uma coluna no Cassandra utilizando o driver Hector versăo 0.6.0-15 (veja a referęncia em Links). Este driver é considerado a melhor forma de se conectar ao Cassandra através do Java.
Antes de explorar o código da Listagem 8, é importante ressaltar que o keyspace, assim como suas famílias de colunas, deve estar previamente configurado no arquivo CASSANDRA_HOME/conf/storage-conf.xml. Porém, neste código de exemplo, é utilizado o Keypace1 e a família Standard1, que fazem parte da configuraçăo padrăo do Cassandra. Deste modo năo é necessário se preocupar com nenhuma configuraçăo para executar este código.
import static me.prettyprint.cassandra.utils.StringUtils.bytes;
import static me.prettyprint.cassandra.utils.StringUtils.string;
import me.prettyprint.cassandra.service.CassandraClient;
import me.prettyprint.cassandra.service.CassandraClientPool;
import me.prettyprint.cassandra.service.CassandraClientPoolFactory;
import me.prettyprint.cassandra.service.Keyspace;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnPath;
public class TesteCassandra {
public static void main(String[] args) throws Exception {
// Obtém uma instância do pool
CassandraClientPool pool = CassandraClientPoolFactory.INSTANCE.get();
// Solicita ao pool uma conexăo com o servidor
CassandraClient client = pool.borrowClient("localhost", 9160);
try {
// Obtém o Keyspace
Keyspace keyspace = client.getKeyspace("Keyspace1");
// Cria um ColumnPath para definir o caminho onde os
// dados serăo armazenados no keyspace
ColumnPath columnPath = new ColumnPath();
// Seta o nome da família de colunas
columnPath.setColumn_family("Standard1");
// Seta o nome da coluna desejada
columnPath.setColumn(bytes("telefone"));
// Adiciona na chave "porcelli" o valor "Alexandre Porcelli" na
// coluna definida pela variável columnPath
keyspace.insert("porcelli", columnPath, bytes("1234-5678"));
// Obtém o valor da coluna definida pela variável columnPath
Column colValue = keyspace.getColumn("porcelli", columnPath);
System.out.println("Telefone:" + string(colValue.getValue()));
} finally {
// Libera a conexăo
pool.releaseClient(client);
}
}
}Neste código de exemplo estabelecemos a conexăo com o Cassandra através do método borrowClient() da interface CassandraClientPool (obtida através da factory CassandraClientPoolFactory). Os parâmetros deste método săo o endereço e número da porta do servidor (“localhost” e 9160, respectivamente). Uma vez estabelecida a conexăo, este método retorna uma instância da interface CassandraClient.
O próximo passo é obter o keyspace (algo como um database do modelo de família de colunas), através do método getKeyspace() da interface CassandraClient, passando como parâmetro o nome desejado.
Depois de obter o keyspace, precisamos indicar o local (família e coluna) onde os dados serăo inseridos. Para isso precisamos criar uma instância da classe ColumnPath. O método setColumn_family() desta classe seta o nome da família que será utilizado. Em seguida é necessário especificar a coluna, que é justamente onde o dado será realmente armazenado.
Diferente das estruturas keyspace e família de colunas, uma coluna năo necessita ser previamente definida. Portanto, caso a coluna năo exista, ela será automaticamente criada. Para definir no ColumnPath qual é o nome da coluna, basta utilizar o método ColumnPathsetColumn()
.Grande parte dos métodos que lidam com armazenamento e recuperaçăo de dados na API do Cassandra utiliza o formato Array de Bytes ao invés de String. Com o objetivo de facilitar a conversăo de String para Array de Bytes e de Array de Bytes para String, o Hector disponibiliza a classe StringUtils com os respectivos métodos estáticos: bytes() e string().
Agora que já temos o Keyspace e o ColumnPath, podemos finalmente inserir um dado no Cassandra. O método utilizado para tal é o insert() da interface Keyspace, que recebe como parâmetro um identificador único, a instância do ColumnPath e o valor que será armazenado.
O identificador único é a chave que permite acessar qualquer coluna armazenada dentro da família de colunas. Veja a Figura 2 para entender melhor como os dados deste exemplo săo estruturados no modelo de dados do Cassandra.
Após inserir o dado na coluna telefone, vamos executar uma consulta com o objetivo de recupera-lo. Para realizar esta operaçăo utilizaremos o método getColumn() da interface Keyspace, passando como parâmetros o identificador único (“porcelli”) e a instância do ColumnPath. O retorno deste método é uma instância da classe Column que, para obter o valor armazenado, precisamos executar o método getValue().
Todas as operaçőes de manipulaçăo de dados foram executadas dentro de um bloco try/finally com o objetivo de garantir que, ao final da execuçăo, a conexăo com o servidor será liberada. Esta liberaçăo ocorre através da execuçăo do método releaseClient() da interface CassandraClientPool, que recebe como parâmetro a instância da interface CassandraClient.
Para compilar e rodar o código da Listagem 8 execute os comandos no terminal (ou no prompt) exibidos na Listagem 9.
unix:
$ javac TesteCassandra.java -cp clhm-production.jar:hector-0.6.0-15-sources.jar:log4j-1.2.14.jar:commons-codec-1.4.jar:hector-0.6.0-15.jar:perf4j-0.9.12.jar:apache-cassandra-0.6.0.jar:commons-pool-1.5.3.jar:high-scale-lib.jar:slf4j-api-1.5.8.jar:cassandra-javautils.jar:google-collections-1.0.jar:libthrift-r917130.jar:slf4j-log4j12-1.5.8.jar
$ java -cp clhm-production.jar:hector-0.6.0-15-sources.jar:log4j-1.2.14.jar:commons-codec-1.4.jar:hector-0.6.0-15.jar:perf4j-0.9.12.jar:apache-cassandra-0.6.0.jar:commons-pool-1.5.3.jar:high-scale-lib.jar:slf4j-api-1.5.8.jar:cassandra-javautils.jar:google-collections-1.0.jar:libthrift-r917130.jar:slf4j-log4j12-1.5.8.jar:. TesteCassandra
windows:
C:\ javac TesteCassandra.java -cp clhm-production.jar;hector-0.6.0-15-sources.jar;log4j-1.2.14.jar;commons-codec-1.4.jar;hector-0.6.0-15.jar;perf4j-0.9.12.jar;apache-cassandra-0.6.0.jar;commons-pool-1.5.3.jar;high-scale-lib.jar;slf4j-api-1.5.8.jar;cassandra-javautils.jar;google-collections-1.0.jar;libthrift-r917130.jar;slf4j-log4j12-1.5.8.jar
C:\ java -cp clhm-production.jar;hector-0.6.0-15-sources.jar;log4j-1.2.14.jar;commons-codec-1.4.jar;hector-0.6.0-15.jar;perf4j-0.9.12.jar;apache-cassandra-0.6.0.jar;commons-pool-1.5.3.jar;high-scale-lib.jar;slf4j-api-1.5.8.jar;cassandra-javautils.jar;google-collections-1.0.jar;libthrift-r917130.jar;slf4j-log4j12-1.5.8.jar;. TesteCassandraCom sua capacidade de armazenar grandes volumes de dados através de sua arquitetura distribuída, aliada ŕ baixa latęncia nas operaçőes de manipulaçăo de dados, o Cassandra atende ŕs necessidades de aplicaçőes que precisam lidar com o chamado Big Data.
Em uma arquitetura complexa que utiliza cache sobre a base de dados, a utilizaçăo do Cassandra é bastante vantajosa, pois será resolvido o problema de latęncia sem ter a necessidade de duplicaçăo de dados.
Como foi possível observar neste artigo, em geral, colocar uma ferramenta NoSQL para funcionar e programar com sua API é muito simples. Diferentemente dos bancos de dados relacionais, năo tivemos que criar usuários, definir permissőes, entre tantas outras tarefas burocráticas. Com exceçăo do Cassandra, até mesmo a definiçăo de esquemas năo precisou ser feita. Do ponto de vista do desenvolvedor, estas ferramentas – se bem usadas – acabam trazendo muita agilidade e produtividade.
Por outro lado, colocar estas ferramentas em produçăo é bem mais complicado do que pode parecer. Năo existem muitas ferramentas para auxiliar na administraçăo, e as disponíveis săo baseadas em linha de comando, o que torna ainda mais difícil a tarefa do administrador. Também temos que considerar o fato destas tecnologias serem jovens, e a todo o momento săo encontrados bugs ou implementadas novas funcionalidades, o que exige um trabalho mais intenso de atualizaçăo e manutençăo por parte dos sysadmins.
Algumas empresas viram nesta dificuldade de administraçăo uma oportunidade de negócio, oferecendo o chamado Dados como Serviço (ou DaaS), onde o desenvolvedor utiliza uma infraestrutura externa sem ter que se preocupar com os pormenores de administraçăo.
Este artigo mostrou como instalar e utilizar algumas das principais ferramentas NoSQL. Através delas pudemos entender, de forma menos abstrata, como os dados săo estruturados nos diferentes modelos que emergiram dentro do movimento NoSQL (chave-valor, documento, grafo e família de colunas).
Um dos principais fatores de sucesso destas, e de grande parte das ferramentas NoSQL, deve-se ao modo elegante como suas APIs foram projetadas. Independente da complexidade interna que estas ferramentas implementam, suas funcionalidades săo expostas aos desenvolvedores de modo bastante simplificado.
Porém, vale ressaltar que estas tecnologias precisam evoluir um pouco mais para atingir certo nível de maturidade. Isso fica evidente quando nos deparamos com a falta de ferramental de apoio para a administraçăo das mesmas. Mas, este caminho é natural, pois ocorreu de forma bastante semelhante com outras tecnologias, dentre elas os próprios bancos de dados relacionais.
Na terceira e última parte desta série de artigos, serăo apresentados alguns casos práticos em que a utilizaçăo de uma soluçăo NoSQL será mais vantajosa que a de um banco de dados relacional. Abordaremos também o tema persistęncia poliglota e, para encerrar, serăo dadas algumas dicas de como escolher a ferramenta NoSQL que melhor se adeque as suas necessidades.
redis.io
Página principal do
Redis.
github.com/xetorthio/jedis/downloads
Página de download da
biblioteca Jedis.
mongodb.org
Página principal do
MongoDB.
github.com/mongodb/mongo-java-driver/downloads
Página de download do
driver do MongoDB para Java.
neo4j.org
Página principal do
Neo4j.
w3.org/RDF
Página principal da
especificaçăo do formato RDF.
w3.org/TR/rdf-sparql-query
Página principal da
especificaçăo da linguagem SPARQL.
cassandra.apache.org
Página principal do
Cassandra.
github.com/rantav/hector/downloads
Página de download do
Hector, driver Java para o Cassandra.
s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf
Paper sobre o Dynamo da Amazon.
labs.google.com/papers/bigtable.html
Página do paper do BigTable.
cygwin.com
Página principal do
Cygwin.
memcached.org
Página principal do
Memcached.
nosql-database.org
Catálogo das
principais ferramentas noSQL.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.