Este artigo aborda o tema bancos de dados relacionais, seus conceitos, como funcionam, vantagens e desvantagens, em uma visăo geral sobre o assunto.
Serve como conteúdo introdutório sobre o assunto, que é de interesse de todos os profissionais da área de banco de dados que desejam se manter por dentro das tecnologias adotadas na prática.
Bancos de dados relacionados săo os mecanismos de persistęncia de dados mais adotado por empresas de TI, de forma que os profissionais da área devem conhecer esta tecnologia com detalhes.
Um Sistema Gerenciador de Banco de Dados Relacional é um software que controla o armazenamento, recuperaçăo, exclusăo, segurança e integridade dos dados em um banco de dados. Neste contexto, este artigo aborda o tema bancos de dados relacionais, seus conceitos, como funcionam, vantagens e desvantagens, em uma visăo geral sobre o assunto.
Para início de discussăo, um banco de dados relacional é um mecanismo de armazenamento que permite a persistęncia de dados e opcionalmente implementar funcionalidades. Neste contexto, o objetivo deste artigo é apresentar uma visăo geral de tecnologias de sistemas de gerenciamento de banco de dados relacionais (SGBDR) e explorar questőes práticas aplicáveis ao seu uso em organizaçőes modernas. Sendo assim, o objetivo deste artigo năo é discutir a teoria relacional.
SGBDRs săo usados para armazenar a informaçăo requerida por aplicaçőes construídas usando tecnologias procedurais, tais como COBOL ou FORTRAN, tecnologias orientadas a objeto tais como Java e C# e tecnologias baseadas em componentes como Visual Basic. Como SGBDRs săo as tecnologias de armazenamento de persistęncia dominantes, é importante que todos os profissionais de TI entendam ao menos os conceitos básicos dos SGBDRs, os desafios por trás da tecnologia e quando seu uso é apropriado.
Vamos iniciar este tópico pela definiçăo de algumas terminologias comuns. Um Sistema Gerenciador de Banco de Dados Relacional (SGBDR) é um software que controla o armazenamento, recuperaçăo, exclusăo, segurança e integridade dos dados em um banco de dados. Um banco de dados relacional armazena dados em tabelas. Tabelas săo organizadas em colunas, e cada coluna armazena um tipo de dados (inteiro, números reais, strings de caracteres, data, etc.). Os dados de uma simples “instância” de uma tabela săo armazenados como uma linha. Por exemplo, a tabela Cliente teria colunas como numeroCliente, primeiroNome e sobrenome, e uma linha na tabela teria algo como {123, “Arilo”, “Dias”}.
Tabelas tipicamente possuem chaves, uma ou mais colunas que unicamente identificam uma linha na tabela. No caso da tabela Cliente a chave seria a coluna numeroCliente. Para melhorar o tempo de acesso aos dados de uma tabela, săo definidos índices. Um índice provę uma forma rápida para buscar dados em uma ou mais colunas em uma tabela, da mesma forma que o índice de um livro permite que nós encontremos uma informaçăo específica rapidamente.
O uso mais comum de SGBDRs é para implementar funcionalidades simples do tipo CRUD (do inglęs Create, Read, Update e Delete – que significa as operaçőes de Inserçăo, Leitura, Atualizaçăo e Exclusăo de dados). Por exemplo, uma aplicaçăo pode criar uma nova compra e inseri-la no banco de dados. Ela pode ler uma compra, trabalhar com seus dados e entăo atualizar o banco de dados com a nova informaçăo. Ela pode ainda optar por excluir uma compra existente, talvez porque o cliente a cancelou. A grande maioria das interaçőes com um banco de dados provavelmente implementará as funcionalidades básicas de CRUD.
A forma mais fácil de manipular um banco de dados relacional é submeter declaraçőes escritas na linguagem SQL a ele. A Figura 1 descreve um simples modelo de dados usando a notaçăo de modelagem de dados proposta pela UML. Para criar uma nova linha na tabela Seminario devemos criar uma declaraçăo de INSERT, como exemplificado no código da Listagem 1. Similarmente, o código da Listagem 2 apresenta um exemplo de como ler uma linha da tabela usando a declaraçăo SELECT. A Listagem 3 apresenta um código para atualizar uma linha existente através da declaraçăo do tipo UPDATE e, finalmente, a Listagem 4 descreve como excluir uma linha da tabela usando a declaraçăo DELETE.
Listagem 1. Declaraçăo SQL para inserir uma linha na tabela Seminario
INSERT INTO Seminario
(idSeminario, idCurso, idProfessor, numeroSeminario, tituloSeminario)
VALUES (74656, 1234, ‘DCC1982’, 2, “Banco de Dados Relacional”) Listagem 2. Declaraçăo SQL para consultar uma linha na tabela Seminario
SELECT * FROM Seminario WHERE SEMINAR_ID = 1701 Listagem 3. Declaraçăo SQL para atualizar uma linha na tabela Seminario
UPDATE Seminario
SET idProfessor = ‘PPGI1982’, numeroSeminario = 3
WHERE idSeminario = 1701Listagem 4. Declaraçăo SQL para excluir uma linha na tabela Seminario
DELETE FROM Seminario
WHERE idSeminario > 1701 AND idProfessor = ‘THX0001138’Existem várias funcionalidades avançadas de SGBDRs que desenvolvedores aprendem uma vez que eles estăo familiarizados com as funcionalidades básicas de CRUD. Cada uma dessas funcionalidades é muito importante, e ŕs vezes bastante complexa, fazendo com que tivéssemos que escrever um artigo próprio para cobri-las. Por isso, iremos aqui apenas introduzir os conceitos e entăo detalhes podem ser encontrados em outros artigos. Essas funcionalidades incluem:
Para armazenar um objeto em um banco de dados relacional precisamos adequá-lo – criar uma representaçăo de dados do objeto em questăo – pois bancos de dados relacionais apenas armazenam dados. Para recuperar o objeto, é preciso ler os dados a partir do banco de dados e entăo criar o objeto, operaçăo normalmente chamada de restauraçăo do objeto, baseado nos dados recuperados. Apesar de o armazenamento em um banco de dados relacional parecer algo simples, na prática năo é. Isso porque năo existe uma traduçăo perfeita e automática entre as tecnologias de objeto e relacional, pois essas tecnologias săo baseadas em teorias diferentes. Para armazenar objetos com sucesso em bancos de dados relacionais, precisamos aprender como mapear um esquema de objetos para um esquema de banco de dados relacional.
Comportamento é implementado em um banco de dados relacional através de stored procedures e/ou stored functions que podem ser invocadas internamente no banco de dados e por aplicaçőes externas. Stored functions e procedures săo operaçőes que executam no SGBDR, a diferença entre elas é o que a operaçăo pode retornar e se ela pode ser invocada em uma query. As diferenças năo săo importantes para nosso objetivo neste artigo, entăo usaremos o termo stored procedure para se referir a ambas as operaçőes. No passado, stored procedures eram escritas em uma linguagem proprietária, tal como PL/SQL da Oracle, mas agora Java está se tornando rapidamente uma opçăo de linguagem para programaçăo de banco de dados. Uma stored procedure tipicamente executa algum código SQL, mensagens de dados e entăo aguarda uma resposta na forma de zero ou mais registros, um código de resposta ou uma mensagem de erro de banco de dados.
Considere um sistema de reserva de passagem aéreas. Existe um vôo com um assento e duas pessoas estăo tentando reservar este assento ao mesmo tempo. Ambas as pessoas verificam o status do voo e săo avisadas que o assento ainda está disponível. Ambos informam seus dados para pagamento do ticket e entăo clicam no botăo de reserva ao mesmo tempo. O que deveria acontecer? Se o sistema está funcionando corretamente, apenas uma pessoa deveria ter acesso ao assento e a outra deveria ser informada que năo existe nenhum assento disponível. Controle de concorręncia é o que faz isso acontecer. Ele deve ser implementado ao longo do código fonte do objeto no banco de dados.
Uma transaçăo é uma coleçăo de açőes no banco de dados – tal como salvar, recuperar ou deletar – que formam uma unidade de trabalho. Uma bandeira das transaçőes é uma abordagem que diz “tudo ou nada”, o que significa que todas as açőes devem ser executadas com sucesso ou entăo serem desfeitas (operaçăo de roll back). A transaçăo aninhada é uma abordagem onde algumas das açőes săo tratadas como suas próprias transaçőes, subdividindo-as. Essas subtransaçőes săo comitadas uma vez com sucesso e năo săo desfeitas se a transaçăo maior falhar. Transaçőes podem ainda ser de curta duraçăo, executando em centésimos de segundo, ou de longa duraçăo, levando horas, dias, semanas e até meses para serem completadas. Controle de transaçăo é um conceito crítico que todos desenvolvedores devem entender.
Integridade referencial (IR)é a garantia de que uma referęncia a partir de uma entidade para outra entidade é válida. Por exemplo, se um cliente referencia um endereço, entăo este endereço deve existir. Se o endereço é deletado, entăo todas as referęncias a ele devem também ser removidas, caso contrário o sistema năo deve permitir a operaçăo de exclusăo. Contrariando a crença popular, IR năo é apenas uma questăo de banco de dados, mas sim um aspecto a ser tratado no sistema como um todo. Um cliente é implementado como um objeto em uma aplicaçăo Java e como um ou mais registros no banco de dados – endereços săo também implementados como objetos e como linhas. Para excluir um endereço, devemos remover o objeto endereço da memória, qualquer referęncia direta ou indireta a ele (uma referęncia indireta para um endereço incluiria um objeto cliente que conhece o valor de idEndereco, a chave primária de endereço no banco de dados), a(s) linha(s) de endereço no banco de dados e qualquer referęncia a ela (através de chaves estrangeiras) no banco de dados. Para complicar ainda mais, se temos outras aplicaçőes acessando o banco de dados, entăo é possível que elas possuam representaçőes do endereço em memória. Um cenário ainda pior seria se tivéssemos o endereço armazenado em vários locais (ex: bancos de dados diferentes), devemos levar isso em consideraçăo. Todos os desenvolvedores devem entender as estratégias básicas para implementar integridade referencial.
A Tabela 1 descreve as funcionalidades técnicas comuns nos principais SGBDRs disponíveis no mercado, as principais formas dos desenvolvedores usá-los e os pontos negativos associados ao seu uso.
|
Funcionalidades |
Uso Principal |
Pontos Negativos |
|
Database cursors – Um database cursor é um objeto usado para percorrer os resultados de uma consulta SQL, permitindo mover para frente ou para trás no conjunto de resultados acessando um ou vários registros por vez. |
|
|
|
Java – A maioria dos SGBDRs comerciais suportam a máquina virtual de Java no banco de dados. |
|
|
|
Triggers – Um trigger é um procedimento que é executado antes ou após uma açăo (tal como inserçăo, atualizaçăo ou exclusăo), e é executado em uma linha de uma tabela do banco de dados. |
|
|
Tabela 1. Funcionalidades Técnicas Comuns de SGBDR.
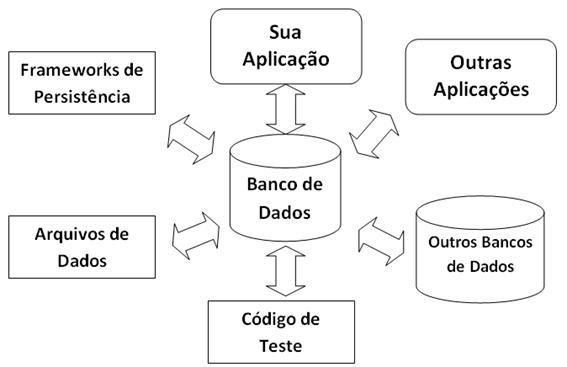
Acoplamento é uma medida do nível de dependęncia entre dois itens – quanto mais acoplado săo dois elementos, maior a chance de que uma mudança em um deles irá requerer um mudança na outro. Acoplamento é a “raiz de todo mal” quando se fala do desenvolvimento de software, e quanto mais coisas seu banco de dados está acoplado mais difícil é mantę-lo e evoluí-lo. Esquemas de banco de dados relacional podem ser acoplados a:
Como podemos ver, acoplamento é um problema sério quando tratamos de refatoraçăo de banco de dados.Por questăo de simplicidade, na continuidade deste artigo o termo “aplicaçăo” irá se referir a todos os sistemas externos, bancos de dados, aplicaçőes, programas, ambientes de teste, etc., que săo acoplados a um banco de dados.
Acoplamento năo é o único desafio que iremos nos deparar ao usar SGBDRs, apesar dele ser o mais importante. Outras questőes que iremos encontrar incluem:
Toda tecnologia possui seus pontos positivos e negativos, e a tecnologia de SGBDR năo foge ŕ regra. Provavelmente existem formas para mitigarmos alguns desses desafios, e encapsulamento é uma técnica importante para isso.
Encapsulamento é um recurso de projeto que trata de como uma funcionalidade é compartimentada em um sistema. Năo precisamos saber como algo está implementado para usá-lo. A implicaçăo de encapsulamento é que podemos construir qualquer coisa que desejarmos, e entăo podemos depois mudar a implementaçăo e isso năo afetará outros componentes no sistema (considerando que a interface para este componente năo mude).
As pessoas normalmente dizem que encapsulamento é o ato de pintar a caixa de preto – estamos definindo algo será feito, mas năo estamos dizendo ao resto do mundo como ele está sendo feito. Usando o exemplo de um banco, como eles rastreiam as informaçőes de nossas contas, em um mainframe, um mini ou um PC? Qual banco de dados eles usam? Qual o sistema operacional? Isso năo importa, pois o banco encapsulou os detalhes sobre como e eles realizam os serviços nas contas. Nós apenas usamos os terminais e fazemos as operaçőes que desejamos.
Através do acesso encapsulado a um banco de dados, talvez por algo tăo simples como objetos de acesso a dados ou algo mais complexo como um framework de persistęncia, podemos reduzir o acoplamento do banco de dados.
A partir de agora assumimos que é possível esconder detalhes do esquema de banco de dados da maioria dos desenvolvedores na organizaçăo enquanto ao mesmo tempo damos a eles acesso ao banco de dados. Algumas pessoas, normalmente apenas DBAs responsáveis por manter o banco de dados, precisarăo entender e trabalhar com o esquema de dados para manter e evoluir a estratégia de encapsulamento.
Uma vantagem do acesso encapsulado ao banco de dados é que ele permite aos programadores focar apenas no problema. Vamos assumir que estamos fazendo algo simples tal como objetos de acesso aos dados que implementem código SQL para acessar o esquema de banco de dados. Os programadores trabalharăo com essas classes de acesso aos dados, năo com o banco de dados. Isso permite ao DBA evoluir o esquema do banco de dados da forma que ele precisar, refatorando-o se necessário, e tudo que ele precisa se preocupar é em manter as classes de acesso aos dados atualizadas. Isso revela uma segunda vantagem desta abordagem – ela provę uma maior liberdade para que o DBA faça seu trabalho.
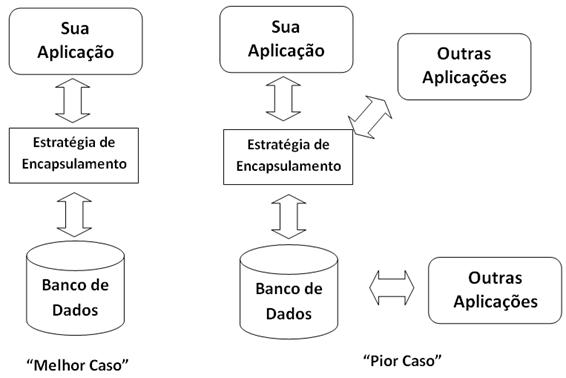
A Figura 4 descreve o conceito de acesso encapsulado em banco de dados, mostrando como o cenário do melhor caso da Figura 2 e o cenário do pior caso da Figura 3 provavelmente seriam modificados. No cenário do melhor caso, o código fonte das regras de negócio iriam interagir com os objetos de acesso aos dados em vez de interagir com o banco de dados. A principal vantagem seria que todos os códigos relacionados a acesso a dados ficariam em um único lugar, tornando simples o processo de alteraçăo em caso de mudanças no esquema do banco de dados ou para apoiar mudanças relacionadas a ajustes de desempenho. É interessante notar que o código com as regras de negócio que os programadores estăo escrevendo estariam acoplados aos objetos de acesso aos dados. Portanto, eles precisariam ser alterados caso a interface do objeto de acesso aos dados mude.
Nós nunca ficaremos livre do acoplamento. No entanto, do ponto de vista dos programadores, é muito mais fácil mudar apenas este código – com a estratégia de encapsulamento de banco de dados eles precisariam lidar apenas com o código fonte da aplicaçăo, e năo com o código fonte do programa + código em SQL de acesso aos dados.
As coisas năo săo assim tăo ideais para o cenário do pior caso. Apesar de ser possível que todas as aplicaçőes possam tirar vantagem da estratégia de encapsulamento, a realidade é que apenas um subconjunto estará apto a usá-lo.
Incompatibilidade de plataforma pode ser um problema – talvez os objetos de acesso aos dados săo escritos em Java, mas alguns sistemas legados podem ser escritos usando tecnologias que năo săo tăo compatíveis com Java. Talvez vocę tenha optado por năo refazer alguns de seus sistemas legados para simplesmenteusar a estratégia de encapsulamento de dados. Talvez alguns aplicativos játenham uma estratégia de encapsulamento em umlugar(em caso afirmativo, vocępode querer considerara reutilizaçăoda estratégiaexistenteem vez de construir sua própria).Talvez vocę queira usar as tecnologias que exigem acesso direto ao banco de dados.
A questăo é que parte das aplicaçőes da sua organizaçăo será capaz de tirar proveito de sua estratégia de encapsulamento e outras năo. Há ainda um benefício de se fazerisso, estaremos reduzindoo acoplamentoe, portanto, reduzindo seus custos de desenvolvimentoe manutençăo,oproblemaéqueelenăo é um beneficio total realizado.
Outra vantagem do acesso encapsulado para acessar um banco de dados é disponibilizar um lugar único, além do próprio banco de dados, para implementar regras de negócio orientada a dados.
Como existem alguns problemas claros com a tecnologia de banco de dados relacional, podemos optar por usar outra tecnologia. Sim, SGBDR é o tipo de mecanismo de persistęncia mais comumente utilizado, mas ele năo é a única opçăo disponível. Entre as opçőes, podemos citar:
Além dessas opçőes, podemos citar ainda bancos de dados em XML, arquivos Flat (arquivos texto), bancos de dados hierárquicos e camada de prevalęncia. Năo entraremos em detalhes sobre elas por năo ser o foco principal do artigo, mas existem diversas informaçőes disponíveis na Internet sobre estas opçőes.
A Tabela 2 apresenta uma comparaçăo de vários tipos de mecanismo de persistęncia. A Tabela 3 apresenta sugestőes para quando usar cada tipo de tecnologia.
|
Mecanismo |
Vantagens |
Desvantagens |
Aplicaçăo Potencial |
|
Arquivos Flat |
|
Difícil acesso ad-hoc |
|
|
Bancos de dados hierárquicos |
|
Năo é tăo popular |
|
|
Bancos de dados de objeto |
|
Năo é bem aceito no mercado e os padrőes definidos, como Object Query Language (OQL), ainda estăo evoluindo |
|
|
Bancos de dados objeto/ relacional |
Tecnologia em crescimento |
Năo é bem aceito no mercado, padrőes emergentes, como SQL3, năo săo largamente adotados e possui base de experięncia ainda pequena |
|
|
Camada de Prevalęncia |
|
Tecnologia emergente |
|
|
Banco de dados relacional |
|
Mapeamento de objeto para banco de dados relacional pode ser uma habilidade difícil de ser aprendida |
|
|
Bancos de dados em XML |
|
Tecnologia emergente com padrőes, como o XML equivalente de SQL, năo tăo adotado e năo funciona bem para sistemas orientados a transaçăo |
Ambiente ideal para aplicaçőes que usam XML, tal como portais ou facilidades para relatórios online |
Tabela 2. Comparando Mecanismos de Persistęncia.
A tecnologia de SGBDRs năo é perfeita, como nenhuma tecnologia é, mas ela é uma das mais utilizadas em nossa área, entăo precisamos aprender como ela funciona efetivamente. A razăo pela qual discutimos sobre os pontos negativos desta tecnologia é que eles nos permitem conhecer as limitaçőes para usar tal tecnologia em nosso dia-a-dia.
Em geral, alguns autores sempre focam nos benefícios do uso de SGBDRs, e claramente existem muitos, mas ignoram os pontos negativos. Outros autores focam em questőes acadęmicas, deixando um pouco de lado questőes práticas, que é como de fato aprendemos a usar uma tecnologia.
Acoplamento é uma questăo séria para todos profissionais de TI, incluindo desenvolvedores e DBAs. Acesso encapsulado a um banco de dados pode ajudar a minimizar os problemas de acoplamento, mas ele é apenas uma soluçăo parcial. É importante também reconhecer que bancos de dados relacionais săo apenas uma das várias escolhas que temos disponíveis para persistęncia dos dados. Abordagens năo-relacionais săo soluçőes viáveis para algumas situaçőes e devem ser levadas em consideraçăo. De qualquer forma, bancos de dados relacionais serăo sempre soluçőes para trabalharmos com persistęncia de dados.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.