O adaptive query optimization é o novo mecanismo do Oracle para apoiar a otimizaçăo de consultas.
Através dele, o SGBD Oracle toma as decisőes sobre qual plano de execuçăo seguir para obter um rendimento ótimo ao rodar consultas SQL. O entendimento deste tema é útil na busca de um melhor desempenho de consultas no Oracle.
Será possível entender como este mecanismo funciona e como ele permite identificar problemas de desempenho em queries e como corrigi-los através de sugestőes oferecidas automaticamente pelo SGBD.
A maior mudança no otimizador de consultas do Oracle 12c é o Adaptive Query Optimization. Trata-se de um conjunto de recursos que permitem ao otimizador fazer ajustes em tempo de execuçăo, de planos de execuçăo, e descobrir informaçőes adicionais que podem levar a melhores estatísticas. Esta nova abordagem é extremamente útil quando as estatísticas existentes năo săo suficientes para gerar um plano ideal. Existem dois aspectos distintos:
O Adaptive Plans permite, ao otimizador, adiar a decisăo sobre o plano final até o tempo de execuçăo. Os instrumentos do otimizador escolhem o plano (padrăo) com o coletor de estatísticas para que em tempo de execuçăo ele possa verificar se suas estimativas de cardinalidade diferem grandemente do número real de linhas encontradas pelas operaçőes no plano.
Saiba mais: Curso de Oracle
Se existir uma diferença significativa, entăo o plano ou uma parte dele pode ser adaptado automaticamente evitando, dessa forma, performance inferior na primeira execuçăo de uma instruçăo SQL.
Através do Adaptive Join Methods, o otimizador é capaz de adaptar join methods em tempo de execuçăo de uma query, predeterminando vários subplanos para partes do plano.
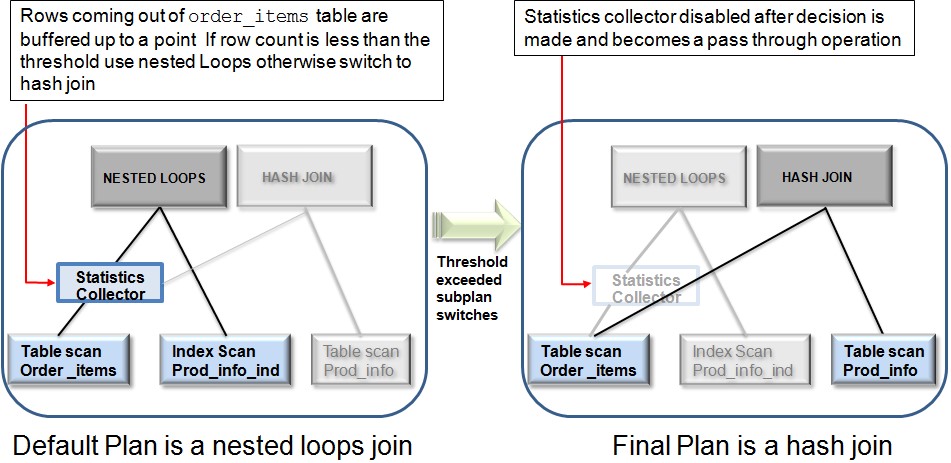
Por exemplo, na Figura 2, a escolha de plano inicial do otimizador para unir as tabelas itens do pedido e informaçőes do produto é um nested loops join através de um acesso de índice na tabela de informaçőes do produto.
Um subplano alternativo também foi determinado, o que permite ao otimizador mudar o tipo join para o hash join. Portanto, com este plano alternativo, a tabela informaçőes do produto será acessada por um full table scan.
Durante a execuçăo, o coletor de estatísticas reúne informaçőes sobre a execuçăo e isola uma porçăo de linhas que entram no subplano.
Neste exemplo, o coletor de estatísticas está monitorando e colocando em buffer as linhas provenientes da varredura completa da tabela de itens do pedido. Com base nas informaçőes vistas no coletor de estatísticas, o otimizador tomará a decisăo final sobre qual subplano será usado.
Neste caso, o hash join é escolhido como o plano final, uma vez que o número de linhas que vęm a partir da tabela de itens do pedido é maior do que o otimizador inicialmente estimou.
Após o otimizador escolher o plano final, a coleta de estatísticas cessa, assim como o armazenado em buffer das linhas, e ele apenas roda as instruçőes. Em execuçőes subsequentes do child cursor, o otimizador desativa o buffer e escolhe o mesmo plano final.
Assim, o otimizador pode mudar facilmente de um nested loops join para uma hash join e vice-versa. No entanto, se o método do join inicial for um sort merge join, nenhuma adaptaçăo ocorrerá (ver Figura 2).


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.