N style="mso-spacerun: yes">
Clique aqui para ler todos os artigos desta ediÁ„o
Otimizando performance de queries
Tuning de joins
por Paulo Ribeiro
Leitura obrigatůria: SQL Magazine 19, EstatŪsticas de DistribuiÁ„o de Dados no SQL Server 2000.
Ao escrever um join estamos informando ao otimizador quais s„o as colunas que desejamos visualizar e qual a lůgica que deve ser empregada no relacionamento entre as tabelas. A n„o ser que utilizemos hints, n„o induzimos o otimizador a utilizar um plano de Nested Loop quando a opÁ„o inicial seria utilizar um Hash Join. Em outras palavras, ao escrever uma query n„o informamos como o otimizador deverŠ processar a query; deixamos a cargo dele a escolha do melhor plano.
O objetivo dessa matťria serŠ estudar a fundo o funcionamento de joins no SQL Server 2000. ComeÁaremos com os tipos bŠsicos de join utilizados em queries (inner, left, right, full e o cross join). No decorrer do artigo a discuss„o serŠ ampliada para dicas de tuning de queries, com foco sobre os modelos fŪsicos de join (nested loop, merge e hash).
O que existe de comum entre a teoria dos conjuntos e os tipos de join
Lembram-se da velha teoria dos conjuntos? Pois os cinco tipos de join existem para reproduzir no mundo dos SGBDīs relacionais os modelos matemŠticos que regem essa teoria.
Para explicar as diferenÁas existentes entre inner join, left join, right join, full outer join e cross join, vou fazer um paralelo com a teoria dos conjuntos. Considere a uni„o (A![]() B) entre os conjuntos A={1,2,3,4} e B={4,5,6,7}, cuja representaÁ„o grŠfica pode ser visualizada na Figura 1.
B) entre os conjuntos A={1,2,3,4} e B={4,5,6,7}, cuja representaÁ„o grŠfica pode ser visualizada na Figura 1.
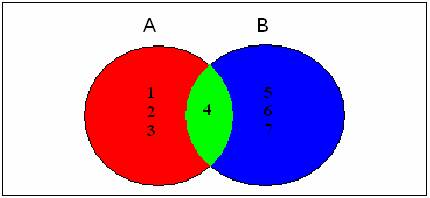
Figura 1. RepresentaÁ„o grŠfica da uni„o entre os conjuntos A e B (A![]() B).
B).
Dando continuidade a nossa analogia, poderŪamos transpor o conjunto A para a tabela de nome tab_A, o mesmo acontecendo para o conjunto B, que assumiria tab_B. O script da Listagem 1 irŠ criar e popular as duas tabelas.
Listagem 1. Script para criar e popular as tabelas.
use NorthWind
go
create table tab_a (elemento tinyint primary key clustered)
create table tab_b (elemento tinyint primary key clustered)
insert into tab_a values (1)
insert into tab_a values (2)
insert into tab_a values (3)
insert into tab_a values (4)
insert into tab_b values (4)
insert into tab_b values (5)
insert into tab_b values (6)
insert into tab_b values (7)
Formatado o ambiente, vamos reproduzir alguns relacionamentos comparando-os com modelos de join:
1. Criar uma query para listar o elemento 4, resultado da intersecÁ„o entre os conjuntos A e B (A![]() B = {4}).
B = {4}).
O inner join ť o modelo que devemos utilizar para identificar as linhas que possuem relaÁ„o de igualdade entre duas tabelas. O select da Listagem 2 expressa esse relacionamento.
Listagem 2. Inner join.
select a.elemento
from tab_A a
INNER join
tab_B b
on a.elemento = b.elemento
-------------------------------------------------------------------------------------------
elemento
-------------
4
...

