No SQL Server um banco de dados é composto por no mínimo um arquivo de dados e outro de log. Os arquivos de dados contęm dados e objetos como tabelas, índices, procedures, views e as informaçőes de dados e log nunca săo armazenadas no mesmo arquivo.
O SQL Server possui tręs tipos de arquivos:
- Arquivo de dados primário: os arquivos de dados primários é o ponto de partida do banco de dados e para os outros arquivos no banco de dados. Todo banco de dados tem um arquivo de dados primário. A extensăo de nome de arquivo recomendado para arquivo de dados primário é mdf.
- Arquivo de dados secundário: os arquivos de dados secundários compőem todos os arquivos de dados, diferente do arquivo de dados primário. Alguns bancos de dados podem năo ter qualquer arquivo de dados secundário, enquanto outros possuem vários arquivos de dados secundários. A extensăo do nome de arquivo recomendado para arquivos de dados secundários é ndf.
- Arquivo de log:os arquivos de log armazenam todas as informaçőes de log que é usado para recuperar o banco de dados. Deve haver pelo menos um arquivo de log para cada banco de dados, embora possa haver mais de um. A extensăo de nome de arquivo recomendado para arquivos de log é .ldf.
Obs: O SQL Server năo obriga o uso das extensőes.mdf, .ndf e .ldf no nome dos arquivos, mas estas extensőes săo regularmente utilizadas por ajudar na identificaçăo dos diferentes tipos de arquivos e seu uso.
Podemos criar grupos de arquivos denominados de Filegroups coleçőes de arquivos. Săo usados para ajudar na colocaçăo de dados e tarefas administrativas como, operaçőes de backup e restore.
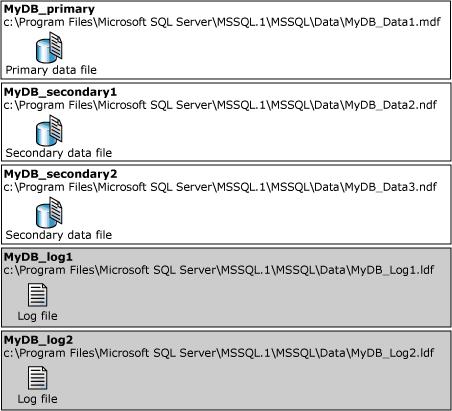
A ilustraçăo abaixo mostra um exemplo dos nomes de arquivo lógico e os nomes de arquivo físico de um banco de dados criado em uma instância default do SQL Server 2005:
Particionamento da tabela e do índice
O particionamento da tabela e do índice alivia o gerenciamento de bancos de dados de grande porte, facilitando o gerenciamento em partes menores e mais manejáveis. O particionamento horizontal permite a divisăo de uma tabela em pequenos grupos baseados no esquema de particionamento. O particionamento da tabela é designado para amplos bancos de dados, de centenas de gigabytes a terabytes ou mais. Nas versőes anteriores do SQL Server era necessário carregar cada partiçăo em tabelas separadas, definir uma visualizaçăo da tabela e em seguida utilizar uma sentença complexa UNION para incorporá-la na consulta. No SQL Server 2005, as partiçőes podem ser alternadas dentro e fora do esquema de partiçăo existente de maneira rápida, eliminando a necessidade de criar e indexar novas tabelas ou perder tempo modificando a sentença UNION para adaptar a nova tabela. Este recurso está somente disponível na versăo Enterprise.
Particionando uma Tabela
Criando um Banco de Dados
Vamos criar o banco de dados Particionamento com um arquivo de dados primário, seis arquivos secundários e um arquivo de log.
USE master
GO
CREATE DATABASE Particionamento
ON PRIMARY
( NAME = db_data,
FILENAME = d:bancodb.mdf,
SIZE = 3MB),
FILEGROUP FG1
( NAME = FG1_data,
FILENAME = d:bancoFG1.ndf,
SIZE = 3MB),
FILEGROUP FG2
( NAME = FG2_data,
FILENAME = d:bancoFG2.ndf,
SIZE = 3MB),
FILEGROUP FG3
( NAME = FG3_data,
FILENAME = d:bancoFG3.ndf,
SIZE = 3MB),
FILEGROUP FG4
( NAME = FG4_data,
FILENAME = d:bancoFG4.ndf,
SIZE = 3MB),
FILEGROUP FG5
( NAME = FG5_data,
FILENAME = d:bancoFG5.ndf,
SIZE = 3MB),
FILEGROUP FG6
( NAME = FG6_data,
FILENAME = d:bancoFG6.ndf,
SIZE = 3MB)
LOG ON
( NAME = db_log,
FILENAME = d:bancolog.ndf,
SIZE = 2MB,
FILEGROWTH = 10% );
GO
USE Particionamento
GOCriando uma Partition Function
Uma Partition Function é um objeto independente no banco de dados que define o limite para partiçăo dos dados. É o primeiro passo para particionar uma tabela ou índice.
CREATE PARTITION FUNCTION particao_funcao (int) AS
RANGE LEFT FOR VALUES (100, 200, 300, 400, 500);
GOAbaixo temos os intervalos das Partiçőes:
| Id da Partiçăo | Intervalo dos Valores |
|---|---|
| 1 | 1 –infinito a 100 |
| 2 | 101 a 200 |
| 3 | 201 a 300 |
| 4 | 301 a 400 |
| 5 | 401 a 500 |
| 6 | 501 a +infinito |
Este comando cria uma funçăo de partiçăo chamada de particao_funcao que é aplicado a um tipo de dados inteiro. A clausula RANGE LEFT especifica o ponto de limite definido para a partiçăo ŕ esquerda e para a direita usamos RANGE RIGHT. A clausula VALUES define os pontos de limite da partiçăo. O SQL Server 2005 suporta todos os tipos de dados para o uso de particionamento, exceto TEXT, NTEXT, IMAGE, XML, TIMESTAMP, VARCHAR(MAX), NVARCHAR(MAX), VARBINARY(MAX).
Criando um PARTITION SCHEME
O Esquema de Partiçăo define em quais filegroups os intervalos serăo armazenados.
CREATE PARTITION SCHEME particao_esquema AS
PARTITION particao_funcao
TO ([FG1], [FG2], [FG3], [FG4], [FG5], [FG6])
GOEste comando cria uma funçăo de partiçăo chamada particao_esquema e é mapeado a um esquema de partiçăo. A clausula TO define quais filegroups que irá utilizar da Function Partition.
Utilize o scrip abaixo para Verificar a PARTITION SCHEME criada
SELECT * FROM sys.partition_schemesCriando uma tabela particionada
Vamos criar uma tabela particionada utilizando um PARTITION SCHEME criado no passo 3. A clausua ON define o esquema a ser utilizado.
CREATE TABLE dbo.AULA_PARTICAO
(aula_id int, descricao Char(10) default (AAAAA))
ON particao_esquema(aula_id);Testando os recursos implementados
Criando um script para inserir 60 registros com intervalo de 10 cada.
SET NOCOUNT ON
DECLARE @i INT
SET @i=1
WHILE @i<=600
BEGIN
INSERT dbo.aula_particao (aula_id) select @i
SET @i=@i+10
END
GOO script abaixo verifica a quantidade de registros por partiçăo. A VIEW sys.partitions contem informaçőes sobre partiçőes de tabela e indices do banco de dados.
SELECT * FROM sys.partitions
WHERE object_id = OBJECT_ID(dbo.AULA_PARTICAO);
SELECT *,$partition.particao_funcao(aula_id) as nr_particao
FROM dbo.aula_particao
where aula_id in (1,11,101,151,201,221,301,331,401,431,511,561)
SELECT *,$partition.particao_funcao(aula_id) as nr_particao
FROM dbo.aula_particao
WHERE $partition.particao_funcao(aula_id) = 2Particionando um Índice
O procedimento para criar um índice particionado é igual ao procedimento de se criaruma tabela particionada. Para exemplificar, vamos criar um índice para a coluna aula_id da tabela aula_partiçăo utilizando a Partition function e Partition Sheme utilizados para tabela.
USE particionamento
GO
Create Nonclustered Index ix_aula_id on aula_particao(aula_id)
on particao_esquema(aula_id)No exemplo criamos um índice chamado ix_aula_id para a coluna aula_id da tabela aula_particao referenciando o esquema de partiçăo particao_esquema. Podemos verificar a criaçăo do índice utilizando a procedure de sistema sp_helpindex como no exemplo abaixo:
sp_helpindex aula_particaoNa coluna index_description podemos observar que o índice foi locado no esquema de partiçăo particao_esquema.
Com a query abaixo também podemos verificar a quantidade de registros por partiçăo do índice.
SELECT * FROM sys.partitions
WHERE object_id = OBJECT_ID(dbo.AULA_PARTICAO)
and sys.partitions.index_id =
(select sys.indexes.index_id from sys.indexes
where object_id = OBJECT_ID(dbo.AULA_PARTICAO)
and sys.indexes.name = ix_aula_id)Gerenciando Partiçőes
Para gerenciar partiçőes temos tręs operadores SLIPT, MERGEe SWITCH.
- SPLIT – Adiciona um intervalo para a funçăo de partiçăo
- MERGE – Permite mesclar um ou mais intervalos de uma funçăo de partiçăo
- SWITCH – Adiciona ou remove linhas de uma tabela
Antes de alterar a partiçăo vamos relembrar como está criada nossa Partition Function e Partition Scheme.
select sys.partition_functions.name , sys.partition_range_values.* ,
sys.partition_schemes.name as name_scheme
from sys.partition_functions
inner join sys.partition_range_values on sys.partition_range_values
.function_id = sys.partition_functions.function_id
inner join sys.partition_schemes on sys.partition_schemes.function_id =
sys.partition_functions.function_id
where sys.partition_functions.name = particao_funcao
select sys.partition_schemes.name as name_scheme, sys.data_spaces
.name as name_filegroup
from sys.partition_schemes
inner join sys.destination_data_spaces on sys.destination_data_spaces
.partition_scheme_id = sys.partition_schemes.data_space_id
inner join sys.data_spaces on sys.data_spaces.data_space_id =
sys.destination_data_spaces.data_space_id
where sys.partition_schemes.name = particao_esquemaUtilizando MERGE
O MERGE permite mesclar um ou mais intervalos de uma Partition Function. Note que no exemplo abaixo solicitamos a mesclagem do intervalo entre 200 e 399 e como resultado o filegroup FG3 năo faz mais parte da Partition Scheme particao_esquema.
ALTER PARTITION FUNCTION PARTICAO_FUNCAO()
MERGE RANGE (300);Utilizando SPLIT
Use o SPLIT sempre que precisar adiciona um intervalo para uma Partition Function.
-- Adidionando um Filegroup para a Partition Scheme
ALTER PARTITION SCHEME particao_esquema
NEXT USED FG3;
-- Criando o Intervalo de 300 a 399
ALTER PARTITION FUNCTION PARTICAO_FUNCAO ()
SPLIT RANGE (300);Utilizando SWITCH
O operador SWITCH permite mover dados de uma partiçăo para uma outra tabela do mesmo filegroup. Imagine que vocę queira mover os dados de produçăo para uma tabela de histórico quanto tempo năo iria demorar com o SWITCH o SQL Server move o ponteiro dos dados para a outra tabela, mas é valido somente para tabelas criadas no mesmo FILEGROUP e com a mesma estrutura.
Como exemplo, vamos mover os dados da partiçăo 1 para a tabela AULA_PARTICAO_HIST.
CREATE TABLE dbo.AULA_PARTICAO_HIST (aula_id int,descricao Char(10) default (AAAAA)) ON FG1
ALTER TABLE AULA_PARTICAO
SWITCH PARTITION 1 TO AULA_PARTICAO_HIST
SELECT * FROM AULA_PARTICAO_HIST
