Perigos e
Armadilhas do Particionamento - Etapa 2 – Parte 01
por Arup Nanda
Chaves de Partiçăo Multi-colunadas (Multi-Column
Partition Keys)
A maioria dos documentos, artigos, livros e outras publicaçőes, falam sobre
o uso de uma única coluna para chave de particionamento, mas que tal usar duas
ou mais colunas? Definitivamente é possível, mas em tal caso, como deveríamos
proceder?
Muitas
pessoas tęm a impressăo de que especificando mais de uma coluna como chave de
particionamento cria-se uma tabela particionada multidimensional. Por exemplo,
se vocę tem uma tabela chamada "faixa de empregado" particionada em
(DEPTNO, ZIPCODE), isso significa que săo avaliados os valores de ambas as
colunas quando se está decidindo sobre a colocaçăo da linha em uma
partiçăo?
Infelizmente, a resposta é năo.
A
segunda coluna na chave de particionamento só é usada em alguns casos
especiais. Ambos os valores năo precisam ser satisfeitos para uma linha ir para uma partiçăo específica. A primeira
coluna é avaliada antes; se satisfizer a condiçăo, entăo a segunda coluna năo é
avaliada. Porém, se o primeiro valor da coluna năo for totalmente satisfatório,
a próxima coluna é considerada.
Isto será mais bem entendido talvez utilizando-se um exemplo. Considere o seguinte:
create table ptab1
col1 number(10),
col2 number(10),
col3 varchar2(20)
)
partition by range (col1, col2)
(
partition p1 values less than (101, 101),
partition p2 values less than (201, 201)
)
É uma percepçăo popular que quando uma linha é inserida, se ambos os valores de col1 e col2 săo menores que 101, entăo văo para a partiçăo P1; se os valores săo menores que 201, porém maiores ou igual a 101, văo para a partiçăo P2; caso contrário, văo para a partiçăo PM. Em nosso exemplo, vejamos para qual partiçăo serăo direcionados. Aqui estăo todas as linhas da tabela:
select * from ptab1;COL1 COL2 COL3--------- ---------- ------100 100 rec1102 102 rec2100 102 rec3102 100 rec4101 100 rec5101 101 rec6101 102 rec7201 100 rec8201 101 rec9201 102 rec10
Em quais partiçőes os registros serăo inseridos? Confiramos o primeiro:
select * from ptab1 partition (p1);COL1 COL2 COL3---------- ---------- ------100 100 rec1100 102 rec3101 100 rec5
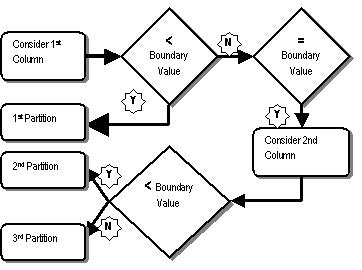
O registro REC1 está na partiçăo P1, como esperado. Mas REC3 deveria estar na partiçăo P1? O valor da coluna COL1, que é 100, é menor que 101 e entăo satisfaz a condiçăo. Porém COL2 tem 102, e é maior que 101, o valor de limite de COL2. Como é que COL2 foi para a partiçăo P1? A razăo é bastante simples: P1 é a primeira partiçăo, o valor é avaliado pela primeira coluna (COL1) e satisfaz, assim o valor da coluna COL2 năo é nem mesmo avaliado. O registro vai para P1, embora o critério de COL2 năo seja satisfeito.
Assim, se a segunda coluna, COL2, năo é nem mesmo considerado em alguns casos, onde entraria em jogo e por que seria definido assim? Considere o registro REC5 no qual o valor de COL1 é 101, para a chave de particionamento é um valor incerto daquela coluna. Mas neste caso, é considerada a segunda coluna. Neste caso, o valor de COL2 é 100, menor que o valor de limite de COL2 na chave de particionamento (101); entăo, entra na partiçăo P1. Veja os registros na partiçăo P2.
select * from ptab1 partition (p2);COL1 COL2 COL3---------- ---------- -----102 102 rec2102 100 rec4101 101 rec6101 102 rec7201 100 rec8201 101 rec9201 102 rec10
Os registros REC2, REC4, e REC7 satisfazem as colunas e săo, como esperado, inseridos na partiçăo P2. Porém, para REC6, o valor de COL1 é 101, que é o valor limite para a primeira coluna da chave de particionamento. Assim, REC6 cai na consideraçăo especial para chaves de particionamento multi-colunados. Porque o valor 101 de COL2 é maior que o valor limite da coluna COL2 da partiçăo P1 (101), as linhas foram para a partiçăo P2.
Pela mesma lógica, para os registros REC8, REC9 e REC10, o valor de COL1 é 201 exatamente no limite para o valor daquela coluna na chave de particionamento. Porém, o valor de COL2 é menor que 201 e o valor limite daquela coluna em P2. Entăo, as linhas foram para a partiçăo P2.
O que acontece quando vocę insere uma linha com COL1 = 201 e COL2 = 201?
Esta linha entrará na partiçăo PM, desde que ambas as colunas năo podem estar fora dos limites. Esquematicamente, a decisăo para inserir em uma partiçăo pode ser explicada pela figura abaixo.
Entăo o que acontece no caso da lista de particionamento no Oracle 9i, onde năo há nenhum conceito de uma faixa e, portanto, năo há nenhum valor de limite? Felizmente, a lista de particionamento năo permite colunas múltiplas, assim esta situaçăo năo surge.
Aparentemente, considerando a confusăo potencial sobre a colocaçăo de linhas em partiçőes, năo vale a pena o uso de chaves de particionamento multi-colunadas. Porém, em alguns casos especiais, pode ser muito útil. Por exemplo, considere uma tabela chamada SALES com colunas SALES_YEAR, SALES_MONTH e SALES_DAY, em vez de uma única coluna chamada SALES_DATE. Isto é útil em alguma implementaçăo de projeto de datawarehouse para habilitar dimensőes e hierarquias. Em tal caso, vocę poderia usar uma chave de particionamento em todas as tręs colunas para efetivamente projetar as partiçőes.
Armadilha potencial: Tenha cuidado quando for definir colunas múltiplas como chave de particionamento. Se tiver que faze-lo, use casos de teste precisamente em torno dos valores limite.

