O artigo apresenta o projeto Spring Data JPA, lançado em 2011 e construído com base nos conceitos do padrăo de projeto Repository, o que torna a programaçăo do código de persistęncia muito mais simples e ágil. O Spring Data JPA é útil para desenvolvedores que fazem uso de persistęncia de dados em suas aplicaçőes e procuram uma forma mais rápida, simples e eficaz de implementá-la.
O Spring é um framework Java que tem grande aceitaçăo na área de desenvolvimento de sistemas. Embora năo tenha sido lançado como um framework de persistęncia de dados, ele provę ferramentas que facilitam o desenvolvimento das classes que contęm as operaçőes de CRUD, tanto com o uso de JDBC puro, como com algum framework de mapeamento objeto relacional (ORM).
O lançamento do projeto Spring Data JPA conseguiu ir além de apenas mais uma ferramenta de apoio a frameworks de persistęncia. Este é um poderoso projeto que tem tudo para ganhar espaço e se tornar uma das ferramentas mais adotadas para persistęncia de dados, transformando os códigos fontes em poucas linhas de muita eficácia.
Quando chega a hora de iniciar um novo projeto de software, a equipe de desenvolvimento começa a ter diversas dúvidas sobre o que usar. Escolher as ferramentas certas, para cada tipo de projeto, entre todas as disponíveis em Java, é sempre um processo bem difícil. Escolher um framework entăo pode complicar ainda mais a decisăo de o que usar em um novo projeto. Os frameworks, ŕs vezes, possuem um objetivo bem específico, como por exemplo: um framework de persistęncia tem a responsabilidade apenas de persistir dados; um framework MVC tem como finalidade a inclusăo do padrăo MVC no projeto; frameworks de interface com o usuário (UI) disponibilizam componentes para a camada de visualizaçăo. Mas felizmente, para os apreciadores do Spring Framework, este surge como uma soluçăo que se adapta a vários tipos de projeto. Considerado uma ferramenta de fácil aprendizado, também disponibiliza uma vasta quantidade de APIs que podem ser usadas inclusive na integraçăo com outros frameworks.
Os desenvolvedores do Spring estăo sempre trabalhando para aperfeiçoar os recursos já disponíveis no framework, como também para adicionar novos recursos, que possam facilitar ainda mais o processo de desenvolvimento de aplicaçőes. Entre esses processos, as operaçőes de CRUD sempre foram um dos focos do Spring, sejam elas com uso de algum framework de persistęncia ou mesmo sem o uso deles. Para isso, algumas APIs foram disponibilizadas, como o JdbcTemplate, HibernateTemplate, JpaTemplate, entre outras.
As APIs de persistęncia sempre estiveram presentes no Spring Framework com a finalidade de facilitar o processo de implementaçăo das classes direcionadas a operaçőes de CRUD. Ainda năo satisfeitos com as opçőes existentes no framework, os desenvolvedores do Spring lançaram nos primeiros meses de 2011 um novo projeto, chamado Spring Data JPA.
Este projeto tem como objetivo facilitar as operaçőes de CRUD baseadas em implementaçőes JPA 2, reduzindo o esforço do programador para a quantidade de código que realmente se faz necessária. A Java Persistence API, ou apenas JPA, é uma especificaçăo Java (JSR 317) que deve ser seguida por frameworks de mapeamento objeto-relacional (ORM), como o Hibernate, TopLink ou IBatis. Ela padroniza um conjunto de classes e métodos que devem ser implementados pelos frameworks ORM que desejam seguir a especificaçăo. A vantagem em adotar este padrăo é que um framework pode ser trocado por outro sem que exista a necessidade de modificar as classes e métodos de persistęncia da aplicaçăo.
O projeto Spring Data JPA, embora năo seja um framework ORM, foi desenvolvido com base no padrăo JPA 2 para trabalhar com qualquer framework que siga tal especificaçăo. Ele é responsável pela implementaçăo dos repositórios (camada de persistęncia de dados), oferecendo funcionalidades sofisticadas e comuns ŕ maioria dos métodos de acesso a banco de dados. Ao programador, se abstrai a necessidade de criar classes concretas para os repositórios, sendo necessário apenas criar uma interface específica para cada classe de entidade, e nelas, estender a interface JpaRepository. Ao herdar a interface JpaRepository, dois propósitos săo preenchidos: no primeiro, uma variedade de métodos como save(), delete(), findAll(), entre outros, săo fornecidos; e no segundo, o reconhecimento desta interface como um bean do Spring, o que é útil para a injeçăo de dependęncia.
Outra funcionalidade interessante se refere aos métodos de pesquisa. Em um projeto sem o uso de Spring Data, teríamos geralmente uma interface, e nela, alguns métodos de consulta seriam definidos. Estes métodos posteriormente seriam codificados em uma classe concreta. Quando se faz uso de Spring Data, basta incluir a assinatura do método de pesquisa na interface e adicionar a esta assinatura uma anotaçăo do tipo @Query, com a respectiva consulta no formato JPQL. A implementaçăo deste método será realizada automaticamente pelo Spring em tempo de execuçăo.
Neste contexto, o artigo apresenta uma introduçăo ao Spring Data-JPA, demonstrando suas principais classes e interfaces. Para exemplificar seu uso, será desenvolvido um pequeno projeto que abordará sua configuraçăo com o framework Hibernate e a implementaçăo de alguns métodos de pesquisa usando os recursos disponibilizados pelo Spring Data. Para o leitor ter uma melhor compreensăo do conteúdo tratado aqui, é aconselhável que já tenha um conhecimento básico de Spring e persistęncia com JPA.
Os desenvolvedores do Spring tentaram facilitar em muito a vida do programador que usará o Spring Data JPA em suas aplicaçőes. Para isso, eles desenvolveram algumas classes e interfaces que reduzem a complexidade e a quantidade de código fonte que seria de responsabilidade do programador nas operaçőes de CRUD.
O Spring Data está disponível na versăo estável 1.0.2-RELEASE e pode ser encontrado no site da comunidade SpringSource – veja a URL para download na seçăo Links – ou através do repositório Maven. Ele pode ser usado com qualquer framework de persistęncia que siga a especificaçăo JPA2, como por exemplo, o Hibernate. Sua configuraçăo possui a dependęncia de algumas bibliotecas do Spring Framework, como spring-core, spring-bean, spring-context, entre outras.
A partir da próxima seçăo do artigo, vamos demonstrar como funciona esta excelente ferramenta do Spring, e o código fonte aqui apresentado estará disponível, em forma de projeto, no espaço da revista reservado para download.
Toda aplicaçăo que usa algum tipo de framework de persistęncia deve ter suas tabelas e colunas do banco de dados mapeadas em classes de entidades. O mapeamento é a forma como o framework consegue relacionar uma tabela com uma classe e as colunas desta tabela com os atributos da classe. Nos dias atuais, os mapeamentos săo, em sua maioria, realizados através de anotaçőes. As anotaçőes (Annotation) fazem parte do Java desde o lançamento da versăo 5 e, no caso dos frameworks de persistęncia, substituem as antigas configuraçőes feitas através de arquivos XML. Na Listagem 1, é possível visualizar a classe Usuario mapeada para a tabela Usuarios utilizando anotaçőes.
package br.com.devmedia.springdata.model;
import javax.persistence.*;
import java.io.Serializable;
import java.util.Date;
@Entity
@Table(name = "USUARIOS")
public class Usuario implements Serializable {
private static final long serialVersionUID = -2420346134960559062L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID_PROPRIERATIO")
private Long id;
@Column(name = "LOGIN", length = 30, nullable = false, unique = true)
private String login;
@Column(name = "SENHA", length = 6, nullable = false, unique = false)
private String senha;
@Column(name = "DATA_CADASTRO", nullable = false, unique = false)
@Temporal(value = TemporalType.TIMESTAMP)
private Date dtCadastro;
@Column(name = "IDADE", nullable = false, unique = false)
private int idade;
//Omitidos os métodos getters e setters
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Usuario usuario = (Usuario) o;
if (id != null ? !id.equals(usuario.id) : usuario.id != null)
return false;
return true;
}
@Override
public int hashCode() {
return id != null ? id.hashCode() : 0;
}
}O Spring Data JPA fornece a classe AbstractPersistable, que facilita ao programador o desenvolvimento de suas classes de entidades. Ela pode ser encontrada no pacote org.springframework.data.jpa.domain. Com o uso desta classe, uma nova implementaçăo da classe Usuario pode ser conferida na Listagem 2. Note que o atributo id e suas anotaçőes, mais os métodos equals() e hashCode(), desapareceram da classe. Isso é decorrente do uso da classe AbstractPersistable (apresentada na Listagem 3), que já possui este atributo e os métodos em sua implementaçăo. O tipo do id se torna padrăo entre as entidades que estendem AbstractPersistable. Os métodos equals() e hashCode(), por sua vez, săo construídos com base no atributo id, e a estratégia de persistęncia é configurada como automática (GenerationType.AUTO). A classe ainda fornece o método isNew(), que tem como retorno um tipo boolean para testar se o objeto é novo ou se já é um objeto persistido.
Embora a classe AbstractPersistable já traga recursos pré-configurados para entidades, como o atributo id e os métodos get(), set(), equals(), hascode(), toString() e isNew() implementados, seu uso năo é obrigatório em projetos que adotem o Spring Data JPA, ficando a critério dos programadores utilizá-la ou năo.
package br.com.devmedia.springdata.model;
import org.springframework.data.jpa.domain.AbstractPersistable;
import javax.persistence.*;
import java.util.Date;
@Entity
@Table(name = "USUARIOS")
public class Usuario extends AbstractPersistable<Long> {
@Column(name = "LOGIN", length = 30, nullable = false, unique = true)
private String login;
@Column(name = "SENHA", length = 6, nullable = false, unique = false)
private String senha;
@Column(name = "DATA_CADASTRO", nullable = false, unique = false)
@Temporal(value = TemporalType.TIMESTAMP)
private Date dtCadastro;
@Column(name = "IDADE", nullable = false, unique = false)
private int idade;
//Omitidos os métodos getters e setters
}package org.springframework.data.jpa.domain;
import java.io.Serializable;
import javax.persistence.*;
import org.springframework.data.domain.Persistable;
@MappedSuperclass
public abstract class AbstractPersistable<PK extends Serializable>
implements Persistable<PK> {
private static final long serialVersionUID = -5554308939380869754L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private PK id;
public PK getId() {
return id;
}
protected void setId(final PK id) {
this.id = id;
}
public boolean isNew() {
return null == getId();
}
@Override
public String toString() {
return String.format("Entity of type %s with id: %s",
this.getClass().getName(), getId());
}
@Override
public boolean equals(Object obj) {
if (null == obj) {
return false;
}
if (this == obj) {
return true;
}
if (!getClass().equals(obj.getClass())) {
return false;
}
AbstractPersistable<?> that = (AbstractPersistable<?>) obj;
return null == this.getId() ? false : this.getId().equals(that.getId());
}
@Override
public int hashCode() {
int hashCode = 17;
hashCode += null == getId() ? 0 : getId().hashCode() * 31;
return hashCode;
}
}Repository (em portuguęs, repositório) é um padrăo de projeto descrito no livro Domain-Driven Design (DDD) de Eric Vans. É um conceito muito semelhante ao padrăo de projeto DAO, já que seu foco também é a camada de persistęncia de dados de uma aplicaçăo. Muitas vezes a implementaçăo de um DAO acaba sendo tratada como um Repository, ou vice-versa, mas estas abordagens se diferem em alguns pontos. Os repositórios săo parte da camada de negócios da aplicaçăo, e fornecem objetos a outras camadas como as de controle ou visăo. Outra particularidade do repositório é que ele năo conhece a infraestrutura da aplicaçăo, como o tipo de banco de dados, ou se uma conexăo será por JDBC, ODBC ou mesmo se vai trabalhar com um framework de persistęncia. Já o padrăo DAO conhece a infraestrutura usada e tem a responsabilidade de traduzir as chamadas de persistęncia em chamadas de infraestrutura, como preparar os dados que serăo persistidos em um banco de dados. O repositório, entăo, năo seria nada mais que uma interface, e poderíamos dizer que as regras existentes nas classes que implementam tais interfaces seriam os DAOs.
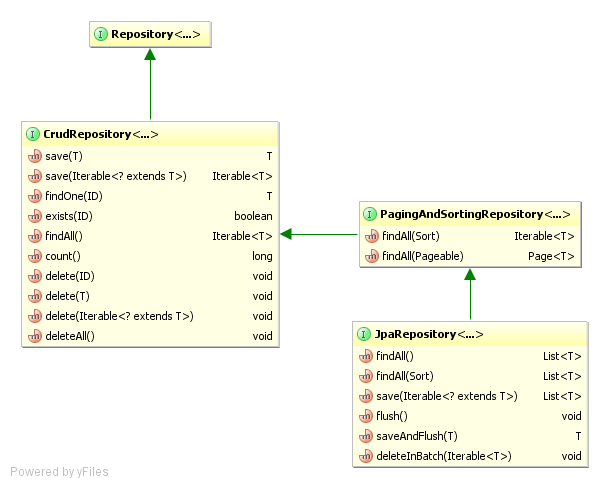
O Spring Data JPA foi projetado a partir dos conceitos do padrăo Repository, sendo assim, tem Repository como sua interface principal. Mas o projeto provę ainda mais tręs interfaces, que para os programadores săo as mais importantes, provendo métodos básicos de operaçőes de CRUD. No pacote org.springframework.data.repository estăo disponíveis, além de Repository, as interfaces: PagingAndSortingRepository, com métodos que facilitam o acesso paginado aos dados da entidade, e CrudRepository, que tem funcionalidades sofisticadas para métodos do tipo salvar, excluir e alguns métodos básicos de pesquisa. Já no pacote org.springframework.data.jpa.repository, encontra-se JpaRepository. Ela é construída de forma que fornece seus próprios métodos de pesquisa, como também métodos capazes de salvar e remover listas de objetos do banco de dados. Também reúne, por meio de herança, os métodos das interfaces PagingAndSortingRepository e CrudRepository, centralizando os principais métodos fornecidos pelo Spring Data.
Confira nas referęncias da seçăo Links a documentaçăo destas interfaces, ou veja na Figura 1 o relacionamento entre as interfaces e os métodos fornecidos por cada uma delas.
A “mágica” existente ao usar, por exemplo, a interface JpaRepository, é que năo se faz necessário criar uma classe concreta com a implementaçăo de seus métodos, nem registrar tal classe como um bean do Spring. O Spring Data JPA procura por todas as interfaces que estendam JpaRepositry, as registra como beans e implementa seus métodos em tempo de execuçăo (Runtime). Mas para que isso aconteça, é necessário adicionar a instruçăo jpa:repositories no arquivo de configuraçăo do Spring. Nesta instruçăo deve ser indicado o local, ou o pacote, que contém as interfaces que herdam JpaRepository. Caso vocę tente implementar a interface JpaRepository em uma classe concreta, o Spring năo reconhecerá essa classe como um bean. Veja na Listagem 4 um exemplo desta configuraçăo. As demais instruçőes e beans do arquivo săo normalmente empregadas para se configurar o Spring utilizando JPA como framework ORM.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<context:annotation-config/>
<context:component-scan base-package="br.com.devmedia.springdata"/>
<!-- Indica onde se encontram as interfaces que estendem JpaRepository -->
<jpa:repositories base-package="br.com.devmedia.springdata.repository"/>
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.
LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor
.HibernateJpaVendorAdapter">
<property name="showSql" value="true"/>
<property name="generateDdl" value="true"/>
</bean>
</property>
<property name="persistenceUnitName" value="persistenceUnitName"/>
</bean>
<bean id="transactionManager"
class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="jpaDialect">
<bean
class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"/>
</property>
</bean>
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/spring-data-jpa"/>
<property name="username" value="root"/>
<property name="password" value=""/>
</bean>
</beans>package br.com.devmedia.springdata.repository;
import br.com.devmedia.springdata.model.Usuario;
import org.springframework.data.jpa.repository.JpaRepository;
public interface IUsarioRepository extends JpaRepository<Usuario, Long> {
}Observe na Listagem 5 a interface IUsuarioRepository, construída para persistir objetos do tipo Usuario (Listagem 2), e veja que ela herda a interface JpaRepository. Outro fato importante a ser observado é que IUsuarioRepository năo possui nenhuma anotaçăo que informe que esta interface seja um bean do Spring no processo de injeçăo de dependęncia. O Spring saberá que ela é um bean pelo simples fato de estender a interface JpaRepository.
Com a interface IUsuarioRepository adicionada ao projeto e após a configuraçăo realizada no arquivo applicationContext.xml do Spring, já é possível executar operaçőes de CRUD usando os métodos herdados de JpaRepository. Veja nos exemplos da Listagem 6, na classe UsuarioTest, como é simples executar estas operaçőes com um objeto do tipo IUsuarioRepository. Para isso, é necessário apenas invocar o método desejado a partir do atributo repository (bean IUsuarioRepository).
No método salvar() é criado um objeto Usuario e invocado o método save(T entity) para gravar um novo usuário no banco de dados. Já o método salvarLista() tem o objetivo de gravar uma lista de usuários. Para isso, é usado o método save(Iterable entities). No método excluir(), uma consulta na tabela é realizada com o método findAll(), que recupera todos os usuários cadastrados. Em seguida é selecionado um usuário, entre todos da lista recuperada e, com o método delete(), o excluímos do banco de dados. Alguns outros métodos podem ser úteis, como: findByOne(), que recupera uma única linha da tabela; exists(), para testar se uma linha existe na tabela; count(), que retorna o número de linhas existentes na tabela; deleteAll(), que exclui todas as linhas da tabela; entre outros.
package br.com.devmedia.springdata.teste;
import br.com.devmedia.springdata.context.Container;
import br.com.devmedia.springdata.model.Usuario;
import br.com.devmedia.springdata.repository.IUsarioRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Date;
import java.util.List;
@Component
public class UsuarioTest {
@Autowired
private IUsarioRepository repository;
public void salvar(){
Calendar calendar = Calendar.getInstance();
calendar.set(2011, 11, 8, 16, 42, 44);
Usuario u5 = new Usuario("java07@email.com", "teste7",
calendar.getTime(), 35);
repository.save(u5);
}
public void salvarLista(){
List<Usuario> usuarios = new ArrayList<Usuario>();
Usuario u1 = new Usuario("java01@email.com", "teste1", new Date(), 20);
Usuario u2 = new Usuario("java02@email.com", "teste2", new Date(), 22);
Usuario u3 = new Usuario("java03@email.com", "teste3", new Date(), 26);
Usuario u4 = new Usuario("java04@email.com", "teste4", new Date(), 30);
usuarios.add(u1); usuarios.add(u2); usuarios.add(u3); usuarios.add(u4);
List<Usuario> users = repository.save(usuarios);
}
public void excluir(){
List<Usuario> usuarios = repository.findAll();
Usuario usuario = usuarios.get(0);
repository.delete(usuario);
}
public void findByLogin() {
Usuario usuario = repository.findByLogin("java02@email.com");
System.out.println(usuario.toString());
}
public void findByIdadeBetween() {
List<Usuario> usuarios = repository.findByIdadeBetween(25, 35);
for (Usuario u : usuarios)
System.out.println(u.toString());
}
public void findByDtCasdastro() {
Calendar c = Calendar.getInstance();
c.set(2011, 11, 8, 16, 42, 44);
List<Usuario> usuarios = repository.findByDtCadastro(c.getTime());
for (Usuario u : usuarios)
System.out.println(u.toString());
}
public void findByLoginAndSenha() {
Usuario usuario = repository
.findByLoginAndSenha("teste2", "java02@email.com");
System.out.println(usuario.toString());
}
public void findByLoginAndSenhaAndIdade() {
Usuario usuario = repository
.findByLoginAndSenhaAndIdade(30, "teste4", "java04@email.com");
System.out.println(usuario.toString());
}
}O Spring Data JPA, apesar de ter algumas consultas pré-definidas, fornece uma maneira muito simples para se criar métodos de pesquisa. Talvez a grande evoluçăo do projeto, em relaçăo ŕs APIs como HibernateTemplate e JpaTemplate, seja a praticidade e facilidade fornecida ao desenvolvedor para criar estes novos métodos. Ele foi construído de maneira que, em tempo de execuçăo, consegue implementar um método de pesquisa a partir apenas da assinatura declarada na interface de repositório. Para exemplificar e tornar mais fácil a compreensăo deste recurso, confira na Listagem 7 alguns métodos adicionados na interface IUsuarioRepository.
package br.com.devmedia.springdata.repository;
import br.com.devmedia.springdata.model.Usuario;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.Date;
import java.util.List;
public interface IUsarioRepository extends JpaRepository<Usuario, Long> {
//nome do método deve conter o atributo da classe
public Usuario findByLogin(String login);
//palavra-chave da consulta: Between
public List<Usuario> findByIdadeBetween(int startAge, int endAge);
//consulta por namedQuery
public List<Usuario> findByDtCadastro(Date dtCadastro);
//consulta por named parameters
@Query("from Usuario where login = :login and senha = :senha")
public Usuario findByLoginAndSenha(@Param("login")String login,
@Param("senha") String senha);
//consulta com ordinal parameters
@Query("from Usuario where login = ?3 and senha = ?2 and idade = ?1")
public Usuario findByLoginAndSenhaAndIdade
(int idade, String senha, String login);
}O primeiro método declarado, findByLogin(), tem o objetivo de localizar no banco de dados um usuário pelo seu login. Normalmente teríamos que criar o código deste método em uma classe concreta, porém com o Spring Data JPA năo é necessário. Isso porque, quando o bean IUsuarioRepository for instanciado pelo Spring, ele inspeciona todos os métodos declarados na interface e constrói uma consulta para cada um deles. Por padrăo, o Spring Data-JPA analisa automaticamente o nome do método e referęncia parte do nome com o atributo declarado na classe de entidade. No caso do método findByLogin(), ele reconhece o trecho “Login” após o “findBy” e cria uma consulta que pesquise pelo atributo login.
Já o método findByIdadeBetween() tem como característica o uso da palavra-chave between. Esta palavra é uma condiçăo que recupera no banco de dados as linhas que estejam entre dois ou mais valores passados como parâmetros. Por exemplo, uma pesquisa que encontre usuários que tenham idade entre 20 e 30 anos.
Na Tabela 1 estăo listadas as palavras chaves suportadas pelo Spring Data JPA que podem fazer parte do nome de um método. Caso a palavra-chave ou o nome do atributo declarado na assinatura do método năo exista, uma exceçăo do tipo java.lang.IllegalArgumentException será lançada em tempo de execuçăo.
| Palavra chave | Exemplo de Método | Trecho JPQL |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Between | findByStartDateBetween | … where x.startDate between 1? and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
Alguns desenvolvedores entendem que o uso de NamedQueries é uma boa prática por deixar o código mais organizado – facilitando a manutençăo do software – ao centralizar em um único local todas as consultas e por evitar SQL Injection. Outros evitam utilizá-las porque acreditam que elas podem tornar a inicializaçăo da aplicaçăo mais lenta – quando existe uma grande quantidade de consultas – já que săo carregadas na criaçăo da EntityManagerFactory, e podem consumir um pouco mais de memória por ficarem em cache. Porém, independentemente dos fatores positivos ou negativos dessa prática, os desenvolvedores do Spring Data JPA năo se esqueceram de dar suporte a ela.
Um breve exemplo de como empregá-la está descrito na Listagem 8, onde a anotaçăo @NamedQuery é adicionada ŕ classe Usuario. A anotaçăo possui dois parâmetros: o name, que recebe o nome da consulta; e o parâmetro query, que recebe a consulta no formato JPQL. Na interface IUsuarioRepository, se deve declarar um método com o mesmo nome do contido no parâmetro name, o qual é apresentado na Listagem 7 com a assinatura findByDtCadastro(). É valido observar que caso uma consulta tenha dois ou mais parâmetros, a ordem desses parâmetros deve ser respeitada na lista de argumentos do método conforme a ordem que eles se encontram na query JPQL. Ou seja, o primeiro parâmetro da query deve ser o primeiro na lista de argumentos do método, o segundo na query será o segundo na lista de argumentos e assim sucessivamente.
package br.com.devmedia.springdata.model;
import org.springframework.data.jpa.domain.AbstractPersistable;
import javax.persistence.*;
import java.util.Date;
@Entity
@Table(name = "USUARIOS")
@NamedQuery(name = "Usuario.findByDtCadastro",
query = "select u from Usuario u where u.dtCadastro =?1"
)
public class Usuario extends AbstractPersistable<Long> {
//código restante omitido.
}Uma abordagem parecida com as consultas NamedQueries, mas que deixam de lado a necessidade de declará-las na classe de entidade é o uso da anotaçăo @Query na própria interface do repositório. Na Listagem 7 há dois exemplos, os métodos findByLoginAndSenha() e findByLoginAndSenhaAndIdade().
O método findByLoginAndSenha() usa os chamados Named Parameters, ou, parâmetros nomeados. Esse tipo de parâmetro é inserido como um critério em consultas JPQL. Eles devem ser precedidos de dois pontos, como por exemplo: where login = :login. Nos argumentos do método que usa tal consulta, deve ser adicionada a anotaçăo @Param(“login”), onde o argumento login será o Named Parameter referente ao parâmetro da consulta (:login). Quando se usa essa prática, a ordem dos parâmetros da consulta com os do método năo precisa ser a mesma, já que eles săo relacionados pelo nome.
Consultas JPQL aceitam também que parâmetros sejam adicionados de maneira ordinal, iniciando em 1. Para isso, basta utilizar o caractere ?seguido de um número que represente a posiçăo do parâmetro na assinatura do método. Por exemplo, no método findByLoginAndSenhaAndIdade(), os parâmetros estăo declarados na seguinte ordem:
Já na consulta, a ordem está inversa:
Usando o caractere ?e seguindo a ordem dos parâmetros declarados na assinatura do método, a consulta JPQL seria expressa da seguinte forma: ...where login = ?3 and senha = ?2 and idade = ?1.
No desenvolvimento de aplicaçőes corporativas, geralmente existe a necessidade de armazenar o histórico de acessos ao banco de dados, o que se costuma chamar de Auditoria. Esse processo tem como funçăo monitorar se um dado é inserido, alterado ou excluído da base de dados. Na prática, săo definidas tabelas para armazenar esses logs que contęm tais informaçőes. No entanto, como uma base de dados pode ter inúmeras tabelas e colunas e nem todas precisam de auditoria, o processo vai de acordo com as necessidades de cada empresa e projeto. A auditoria é muito usada também para registrar os usuários que efetuam login na aplicaçăo. Estes registros podem ser feitos em uma tabela no banco de dados ou mesmo em um algum tipo de arquivo como um TXT ou XML.
Para utilizar o recurso de auditoria do Spring Data JPA o desenvolvedor deve criar uma classe de entidade com os atributos que deseja auditar. Essa entidade deve estender a classe AbstractAuditable (do pacote org.springframework.data.jpa.domain), uma implementaçăo da interface Auditable, presente no mesmo pacote, que provę alguns atributos e métodos já pré-definidos. Caso năo deseje estender a classe AbstractAuditable, existe a opçăo de implementar por conta própria a interface Auditable. O Spring Data JPA provę um ouvinte, um tipo de listener, que pode ser empregado para acionar a captura das datas de alteraçőes realizadas no sistema. Para usar este ouvinte é preciso registrar a classe org.springframework.data.jpa.domain.support.AuditingEntityListener em um arquivo do tipo orm.xml, conforme o descrito na Listagem 9.
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm
http://java.sun.com/xml/ns/persistence/orm_2_0.xsd" version="2.0">
<persistence-unit-metadata>
<persistence-unit-defaults>
<entity-listeners>
<entity-listener
class="org.springframework.data.jpa.domain.support.AuditingEntityListener"/>
</entity-listeners>
</persistence-unit-defaults>
</persistence-unit-metadata>
</entity-mappings>Para ativar a funcionalidade de auditoria, é necessário adicionar um elemento no arquivo de configuraçăo applicationContext.xml para indicar o bean que irá implementar a interface org.springframework.data.domain.AuditorAware. Observe na Listagem 10 a configuraçăo que deve ser inserida neste arquivo. As classes que implementam AuditorAware serăo identificadas pelo Spring como uma classe de auditoria e também terăo acesso ao método getCurrentAuditor(), que tem como objetivo retornar um objeto auditado. Um exemplo simples de implementaçăo de AuditorAware pode ser conferido na Listagem 11, onde apresentamos a classe AuditorAwareImpl, que possui apenas um atributo do tipo AuditoriaUsuario e seus métodos get e set. Este atributo faz referęncia ŕ classe de entidade que possui os dados definidos pelo programador a serem armazenados na tabela de auditoria. Na classe AuditoriaUsuario (veja a Listagem 12) foram definidos dois atributos que serăo persistidos no banco: login e acao. Além disso, AuditoriaUsuario estende a classe abstrata org.springframework.data.jpa.domain.AbstractAuditable, que fornece uma implementaçăo pré-definida da interface org.springframework.data.jpa.domain.Auditable, que contém alguns métodos modificadores (set) e assessores (get). Com esta implementaçăo pré-definida, a classe AbstractAuditable provę alguns atributos próprios, que para serem persistidos é importante que o arquivo orm.xml tenha sido configurado conforme a Listagem 10. É possível também, ao invés de estender a classe AbstractAuditable em AuditoriaUsuario, implementar diretamente a interface Auditable e definir seus métodos por conta própria.
<bean id="auditorAware" class="br.com.devmedia.springdata.auditing.AuditorAwareImpl"/>
<jpa:auditing auditor-aware-ref="auditorAware"/>package br.com.devmedia.springdata.auditing;
import org.springframework.data.domain.AuditorAware;
public class AuditorAwareImpl implements AuditorAware<AuditoriaUsuario> {
private AuditoriaUsuario auditoriaUsuario;
public void setAuditoriaUsuario(AuditoriaUsuario auditoriaUsuario) {
this.auditoriaUsuario = auditoriaUsuario;
}
public AuditoriaUsuario getCurrentAuditor() {
return auditoriaUsuario;
}
}package br.com.devmedia.springdata.auditing;
import org.springframework.data.jpa.domain.AbstractAuditable;
import javax.persistence.*;
@Entity
@Table(name = "AUDITORIA_USUARIO")
public class AuditoriaUsuario extends AbstractAuditable<AuditoriaUsuario, Long> {
@Column(name = "LOGIN")
private String login;
@Column(name = "ACAO")
private String acao;
@Transient
public static final String[] Tipo_Acao = {"Save", "Update", "Delete"};
public String getLogin() {
return login;
}
public void setLogin(String login) {
this.login = login;
}
public String getAcao() {
return acao;
}
public void setAcao(String acao) {
this.acao = acao;
}
}Na Listagem 13 vamos apresentar um exemplo simples de como realizar o processo de auditoria. No método auditoria() criamos um objeto do tipo Usuario e em seguida salvamos seus dados no banco. Instanciamos a seguir um objeto do tipo AuditoriaUsuario para inserir nele as informaçőes que serăo persistidas na tabela de auditoria; neste caso, o login do usuário e a açăo (Save) gerada pela operaçăo anterior. Porém, só é possível persistir o objeto AuditoriaUsuario se ele for adicionado em um objeto do tipo AuditorAwareImpl. Objeto este que implementa a interface AuditorAware, a qual controla o processo de auditoria configurado no arquivo applicationContext.xml. Para finalizar, usamos o método save(), da interface CrudRepository, e nele atribuímos como parâmetro o objeto AuditorAwareImpl. Além dos atributos login e acao, este processo irá salvar no banco de dados os atributos da classe AbstractAuditable: createdBy, createdDate, lastModifiedBy e lastModifiedDate.
package br.com.devmedia.springdata.teste;
import br.com.devmedia.springdata.auditing.AuditorAwareImpl;
import br.com.devmedia.springdata.auditing.AuditoriaUsuario;
import br.com.devmedia.springdata.model.Usuario;
import br.com.devmedia.springdata.repository.IUsarioRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Component;
import java.util.Date;
@Component
public class AuditoriaTest {
@Autowired
private CrudRepository<AuditoriaUsuario, Long> auditorAwareRepository;
@Autowired
private AuditorAwareImpl auditorAware;
@Autowired
private IUsarioRepository usarioRepository;
public void auditoria() {
Usuario u1 = new Usuario("user01@auditoria.com",
"user1", new Date(), 29);
usarioRepository.save(u1);
AuditoriaUsuario auditoria;= new AuditoriaUsuario();
auditoria.setLogin(u1.getLogin());
auditoria.setAcao(AuditoriaUsuario.Tipo_Acao[0]);
auditorAware.setAuditoriaUsuario(auditoria);
auditorAwareRepository.save(auditoria);
System.out.println("AuditoriaTest.auditoria : "
+ auditorAware.getCurrentAuditor());
}
} O Spring Framework é um dos projetos mais bem-sucedidos da linguagem Java. Seus desenvolvedores estăo sempre em busca de novidades que podem facilitar o desenvolvimento de aplicaçőes. Embora o Spring năo seja um framework de persistęncia de dados, sempre forneceu a seus usuários diversas APIs para esse fim, como HibernateTemplate, JdbcTemplate, JpaTemplate, entre outras, e em sua maioria, sempre foram muito bem-aceitas e bastante utilizadas em vários projetos. Com o lançamento do Spring Data JPA, pode-se dizer que houve uma grande evoluçăo no que diz respeito ŕ persistęncia de dados. Esse projeto facilita em muito o desenvolvimento de repositórios para persistęncia de dados, diminuindo bastante o número de linhas de código, o que torna o desenvolvimento do projeto mais rápido e fácil para o programador.
A grande facilidade em manipular consultas a dados talvez seja o principal aspecto do Spring Data JPA, já que necessita apenas que sejam criadas as assinaturas dos métodos de pesquisa, enquanto a implementaçăo destes métodos fica por conta do Spring. Estas consultas podem ser realizadas usando a linguagem JPQL com NamedQueries, Named Parameters ou Query Methods.
Spring Reference Documentation 3.0 - Documentaçăo de referęncia do Spring Framework.
Hibernate Reference Documentation - Documentaçăo de referęncia do Hibernate.
Spring Data JPA - Reference Documentation - Documentaçăo de referęncia do Spring Data JPA.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.