Realizando backup de grandes volumes de dados
A estratťgia de filegroups possibilita alcanÁarmos a faixa dos terabytes para execuÁ„o de backups de grandes massas de dados.
… cada vez mais crescente o nķmero de empresas que tÍm bancos de dados que estejam no intervalo de terabytes e/ou pentabytes. Eles s„o conhecidos como bancos de dados de grande volume de dados (VLDBs). Imagine tentar executar um backup de um banco de dados que possua 10TB diariamente todas as noites, ou atť mesmo semanalmente. Mesmo se vocÍ tivesse adquirido o hardware mais moderno, vocÍ ainda percebe que estŠ levando muito tempo para realizaÁ„o do backup. Uma soluÁ„o para esta problemŠtica pode ser a execuÁ„o de backups utilizando a estratťgia de filegroups, uma maneira em que podemos fazer o backup atravťs de pequenas seÁűes do banco de dados de cada vez.
Simplesmente, um filegroup ť um agrupamento lůgico de arquivos de banco de dados. Usando filegroups, vocÍ pode explicitamente colocar objetos do banco de dados em um determinado conjunto de arquivos. Por exemplo, vocÍ pode separar tabelas e Ūndices n„o clusterizados em filegroups distintos, conforme mostrado na figura abaixo.
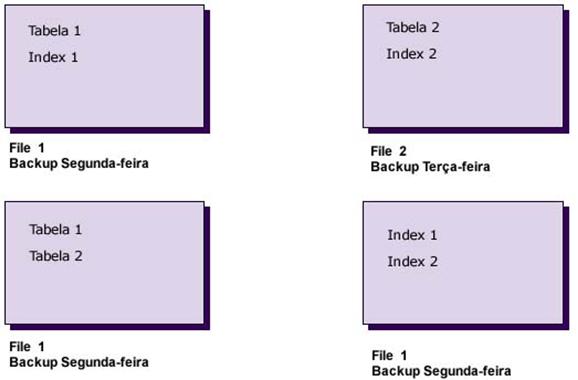
Dessa forma, o banco de dados n„o ť limitado sendo colocado em um ķnico disco rŪgido, ele pode ser distribuŪdo por vŠrios outros discos rŪgidos e, portanto, pode crescer e ficar realmente bem grande. Tambťm temos que lembrar que adoÁ„o de filegroups pode melhorar o desempenho, porque as modificaÁűes em uma tabela podem ser gravadas tanto na tabela quanto no Ūndice ao mesmo tempo. Outra vantagem ť a capacidade de marcar todos os dados de arquivos que fazem parte dele como ReadOnly, ReadWrite, ou ambos. … interessante adotar essa abordagem quando vocÍ tem uma grande preocupaÁ„o com seus dados, logo, os filegroups lhe d„o a capacidade de backup com apenas um ķnico filegroup de cada vez. Isso pode ser extremamente ķtil para um VLDB, porťm o grande tamanho do banco de dados pode fazer o processo de backup extremamente demorado.
Agora vamos implementar esta estratťgia de backup para o banco de dados AdventureWorks que ficou muito grande e n„o estŠ mais cabendo em um ķnico disco. Para acomodar esse crescimento e melhorar o desempenho, vocÍ decidiu distribuir o banco de dados AdventureWorks por vŠrios discos usando filegroup. VocÍ sabe que realizar um backup de filegroup ť o mťtodo de backup mais rŠpido para grandes bancos de dados. Portanto, vocÍ decidiu iniciar a execuÁ„o de backups de filegroup no Adventureworks apůs a criaÁ„o do filegroup.
Para adicionar um filegroup para o banco de dados AdventureWorks, siga os seguintes passos:
1. Abra o SQL Server Management Studio, expanda e depois clique em Databases.
2. Clique com o bot„o direito na base de dados AdventureWorks, e selecione Properties.
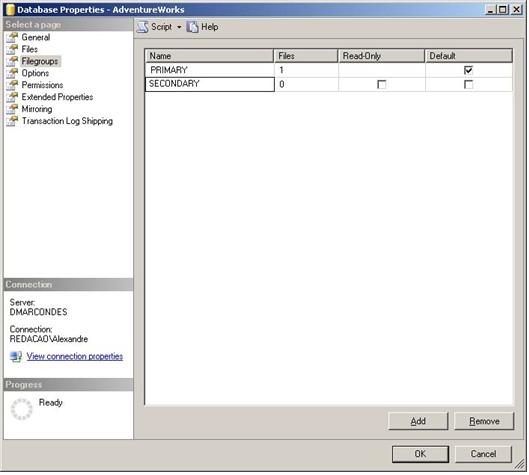
3. Na pŠgina Filegroups, clique em no bot„o Add. Na caixa de texto digite Secondary, como mostra a figura abaixo.
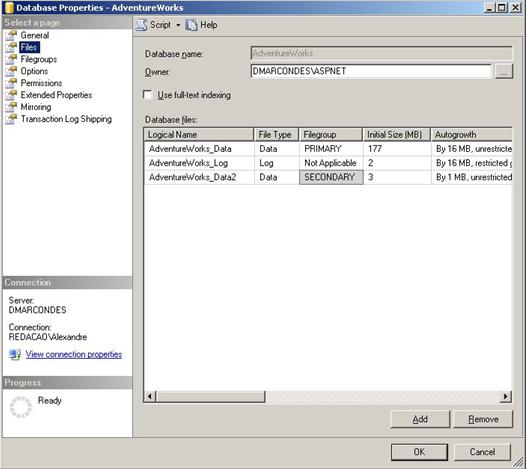
4. Na pŠgina Files, clique no bot„o Add e digite as seguintes informaÁűes, como mostrado na figura a seguir:
_ Name: AdventureWorks_Data2
_ File Type: Data
_ Filegroup: Secondary
_ Initial Size: 3.
5. Pressione OK para criar o novo arquivo no filegroup Secondary.
6. Agora para adicionar uma tabela no novo filegroup, expanda o banco de dados AdventureWorks no Object Explorer, depois clique em Tables, e selecione New Table.
7. Sobre Column Name na primeira linha, digite Emp_Name e escolha o tipo de dado varchar com tamanho 50.
8. Na segunda linha, vamos digitar Emp_Number e escolher o tipo de dado varchar com tamanho 50
9. Altere o filegroup para Secondary na opÁ„o Filegroup or Partition Scheme Name, como mostra a figura abaixo.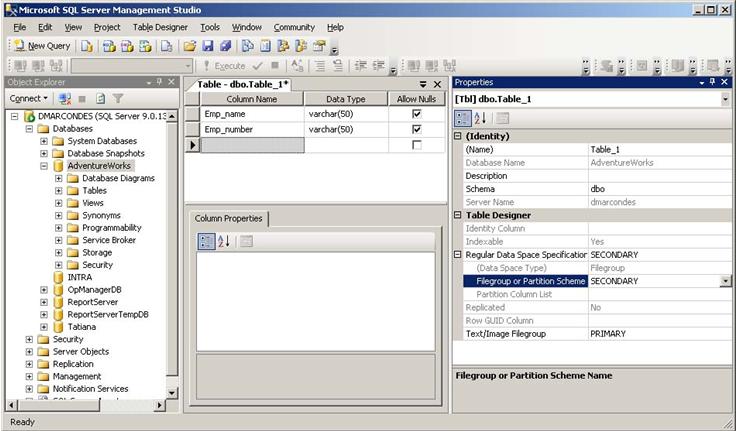
10. Pressione no bot„o Save para criar a nova tabela, e entre com o nome Employees para o nome da tabela e em seguida feche o Table Desginer.
11. Vamos adicionar alguns dados nesta nova tabela, abra uma new query, e execute as seguintes intruÁűes sql.
USE AdventureWorks
INSERT Employees
VALUES(ĎHiro Nakamuraí, ĎVZ1765FRí)
INSERT Employees
VALUES(ĎClaire Bennetí, ĎHQ9187GLí)
12. Feche a janela da consulta que vocÍ acabou de executar.
13. Com o segundo filegroup para armazenar os dados, vocÍ pode executar o backup do filegroup.
14. Clique com o bot„o direito na base de dados AventureWorks no Object Explorer, selecione Taks, e escolha Back Up.
- Na caixa de diŠlogo do Backup selecione o banco de dados que serŠ feito o backup, em nosso cenŠrio serŠ o AdventureWorks, e depois escolha o modo de recuperaÁ„o Full, como mostra a figura abaixo.
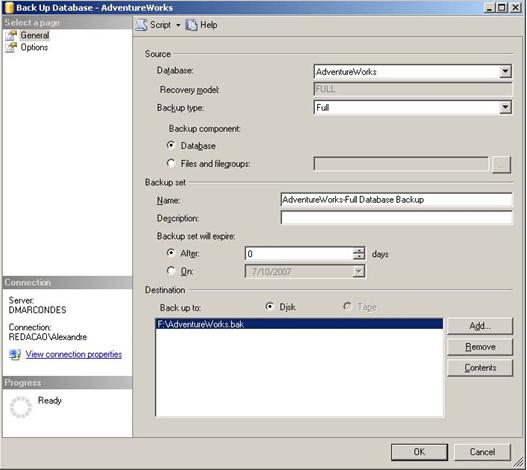
- Na opÁ„o Backup Component, selecione Files and Filegroups.
- Na caixa de diŠlogo, Files and Filegroups, marque o checkbox para Secondary, and click OK, como mostra a figura abaixo.
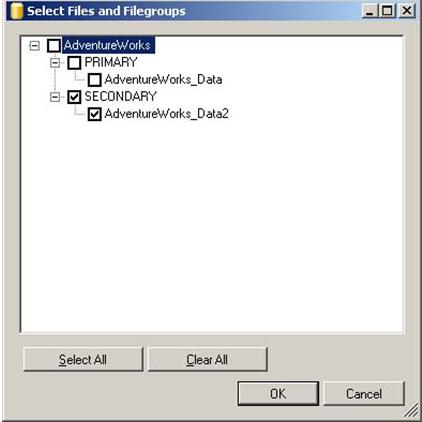
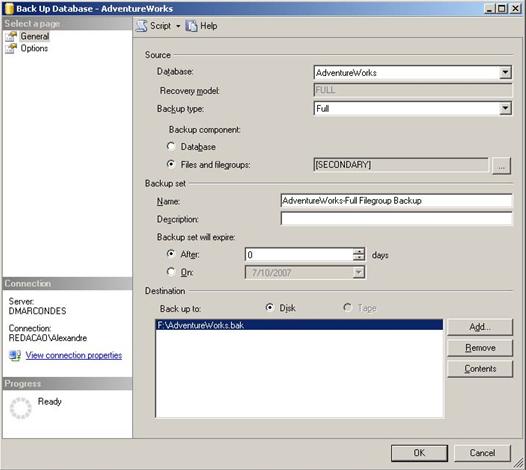
15. As outras opÁűes vocÍ pode deixar conforme exposto na figura e pressione em OK para comeÁar o backup, como mostra a figura abaixo.
Neste artigo, vocÍ aprendeu como criar uma estratťgia de backup usando filegroup, visando atender a necessidade de armazenamento de grandes volumes de dados.

