


Esse artigo faz parte da revista SQL Magazine ediçăo 60. Clique aqui para ler todos os artigos desta ediçăo
-se cada vez mais necessária a utilizaçăo de técnicas de replicaçăo de dados. Tais técnicas văo desde uma simples cópia de um servidor a outro, até uma estrutura que provę capacidade de alta disponibilidade, recuperaçăo de falhas, balanceamento de carga e etc. Cada uma com sua particularidade de utilizaçăo e gerenciamento, com pontos negativos e positivos.
Este artigo demonstrará algumas técnicas de replicaçăo de bases de dados disponíveis no PostgreSQL. Para tanto, serăo feitas apresentaçőes rápidas de cada método, focando os prós e contras de cada utilizaçăo. Serăo mostradas as técnicas de replicaçăo com PGCluster, Slony, replicaçăo dos arquivos de transaçőes (log shipping), Sequoia e PGPool.
PGCluster
O PGCluster é uma ferramenta de replicaçăo do PostgreSQL que permite a montagem de um sistema de replicaçăo síncrono multi-master, onde existe uma replicaçăo em tempo real, com a utilizaçăo de vários servidores primários. Ele pode ser composto por tręs tipos de servidores: o de balanceamento de carga, o de armazenamento e o de replicaçăo (ver Figura 1).
Pode haver mais de um servidor responsável pelo balanceamento de carga, recebendo as consultas e as encaminhando para os nós de armazenamento com menor carga. O fator de carga de um nó é calculado pelo número de sessőes ativas (conexőes feitas pelo sistema ou diretamente por usuários que estăo realizando alguma tarefa). Ele também tem a funçăo de verificar se há problemas com o nó de armazenamento durante esta comunicaçăo, separando-o se houver falhas.
O servidor de armazenamento, podendo haver mais de um, faz parte do agrupamento do banco de dados (chamado cluster). É o servidor que mantém o back-end do PostgreSQL, onde os dados podem ser armazenados (caso năo se utilize uma unidade externa de armazenamento como um storage) e processados.
O servidor de replicaçăo, podendo também haver mais de um, cuida da sincronia dos dados entre os diversos hosts de armazenamento, e quando o servidor de replicaçăo principal falha, outro assume o seu lugar.
A replicaçăo pode ser feita de dois modos: modo normal e modo confiável. No modo normal, uma resposta é enviada ao usuário assim que a atualizaçăo for executada no nó de armazenamento que a recebe. No modo confiável, a resposta só é enviada após a execuçăo do comando de atualizaçăo ter sido realizada em todos os nós de armazenamento.
O servidor de replicaçăo também verifica problemas com o nó de armazenamento durante a comunicaçăo. Se um problema for detectado, o servidor de replicaçăo separa o nó para posterior replicaçăo e uma entrada no arquivo de log é criada. Quando um nó é recolocado ou adicionado ao agrupamento, o servidor de replicaçăo cuida da sincronizaçăo dos dados.
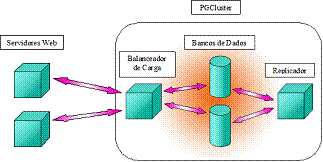
Figura 1. Estrutura do PGCluster para balanceamento de carga e replicaçăo
O PGCluster só pode ser executado em um ambiente Linux, pois o engine é derivado de uma modificaçăo no código fonte do PostgreSQL e compilado para este ambiente operacional. Além dessa restriçăo, existem outras que podem ser mencionadas, como o fato dos large objects (tipos de dados que podem guardar objetos muito grandes) que para serem replicados, devem ser colocados em um diretório que possa ser acessado por todos os servidores de armazenamento do cluster. O PGCluster também năo consegue restaurar um banco de dados quando o mesmo utiliza tablespaces (organizaçăo lógica do banco de dados, que especifica um local físico no sistema de arquivo, onde os objetos serăo armazenados).
Testes de performance foram divulgados comparando-se o PostgreSQL com o PGCluster configurado e o PostgreSQL isolado. Com a utilizaçăo do PGCluster, foi observado que, ŕ medida que o número de atualizaçőes aumentava, sendo executadas paralelamente com as consultas, havia uma queda de performance devido ao fato da atualizaçăo requerer um bloqueio para processar as atualizaçőes que săo replicadas. Esta sobrecarga anulava o efeito da carga de processamento distribuída.
Como alternativa ŕs limitaçőes do PGCluster foi desenvolvido o PGCluster II, que é uma tentativa de reescrever o mesmo, usando um modelo de memória compartilhada. Este projeto foi criado com o objetivo principal de fazer as escritas menos custosas, sem sacrificar a alta disponibilidade nem a performance da leitura de dados, focando um ambiente de sistemas web.
Quer ler esse conteúdo completo?
Tenha acesso completo

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.