Separaçăo dos dados transacionais x históricos
por Sálvio Padlipskas
Olá amigos(as) !
Dias atrás em 28/11/2006 – sábado, estávamos no evento InterCon2006 falando sobre a importância de manter o bom desempenho em termos de acesso feito ao banco de dados. Um dos temas mais excitantes e que agradou a toda comunidade que estava presente, foi a “separaçăo dos dados transacionais x históricos”.
Nesse artigo iremos abordar a importância e como fazer uma distribuiçăo dos dados a fim de garantir acessos heterogęneos feitos pelas aplicaçőes, garantindo a cada tipo de usuário um desempenho proporcional a sua complexidade.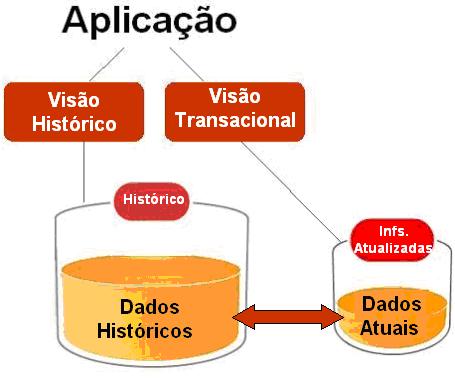
A justificativa
O principal motivo para que seja aplicada essa técnica é o trafegar a informaçăo de forma objetiva, evitando realizar muitas leituras dos blocos de dados, que é a unidade básica de leitura do banco de dados. Essa técnica é o mapa do tesouro para aplicaçőes críticas como leilőes on-line ou bolsa de valores, ou para aquelas que trabalhem com alta disponibilidade ou com grande volume de dados.
O resultado é simples : Garantir o bom desempenho, pois o banco de dados irá acessar um menor número de blocos de dados, diminuindo assim o tempo para processar a consulta.
Outras justificativas seriam: Menor tempo de backup e restore do banco de dados transacional, diminuiçăo do tempo de recuperaçăo do banco de dados entre outros.
Como fazer ?
De forma bem simplificada, os passos a seguir devem ser executados :
1) Separar fisicamente os banco de dados em duas ou mais máquinas
2) Duplicar o banco de dados (com linhas e suas respectivas interaçőes com outros databases)
3) Criar um mecanismo de sincronismo entre os banco de dados, de acordo com a criticidade e o objetivo da aplicaçăo
Uma ressalva. Até aqui os dados estăo “duplicados”, porém com sincronismo. Isso quer dizer que se criarmos um usuário HISTÓRICO e fazer com que ele acesse o banco de dados de histórico descrito no item 2 apenas apontamos para a base histórico.
Para ajustar os dados transacionais, seguimos em frente :
4) Eliminar as linhas de histórico do banco de dados transacional. Essa fase é uma fase extremamente crítica e um profissional especializado como um AD (Administrador de Dados), é de vital importância para garantir que a definiçăo do que é informaçăo histórico e o que é informaçăo transacional deve ser cumprida de forma a alcançar a definiçăo feita pela empresa.
Nesse momento em nossas măos temos 2 usuários : o usuário comum que acessa o dado transacional e o usuário HISTŇRICO, que é acessado pelas pessoas que necessitam da informaçăo em maior granularidade, exigindo uma grande massa de dados.
Os dados também estăo sincronizados, entăo temos 2 bancos de dados distribuídos, porém com volume de dados diferentes. O banco de dados transacional comporta apenas as informaçőes de uso diário e que năo geram estatísticas, porém guardar a informaçăo mais atualizada e indispensável para o banco de dados de histórico, que contém toda a granularidade da informaçăo em termos de volume de dados.
5) Modificar a aplicaçăo, dividindo o acesso da aplicaçăo de acordo com o tipo de usuário. Os usuários transacionais năo mais poderăo extrair informaçőes históricas. Porém os usuários históricos podem extrair informaçőes atuais e históricas. Aqui será necessário criar privilégios com menus dinâmicos de acesso, fazendo a distribuiçăo necessária.
6) Por fim, monitorar com freqüęncia os ambientes e coletar métricas com os usuários e os próprios recursos que o ambiente proporciona.
7) Sair para comemorar (e pode me convidar que estarei lá para sorrir também), pois o sucesso com certeza será alcançado
Pontos Positivos
ü Custo com o hardware transacional fica estacionado, pois ele irá conter somente as informaçőes necessárias para que a aplicaçăo atinja seu objetivo.
ü Tempo de retorno dos dados no acesso ŕ informaçăo
ü Satisfaçăo do usuário
Pontos Negativos
ü Custo com um novo hardware para a base de dados históricos
ü Complexidade em manter o sincronismo entre os bancos de dados
ü Aumento da complexidade da aplicaçăo
ü Ajuste na aplicaçăo (código fonte)
Bem amigos(as), perante o exposto devemos analisar detalhadamente os pontos críticos e os possíveis pontos de falhas e tomar a decisăo de implementar ou năo a técnica. Essa técnica é altamente recomendada para novas aplicaçőes que sendo geridas da fase de modelagem de dados e novas especificaçőes.
Todo esse esforço é recompensado pela velocidade no tráfego de dados feito entre a aplicaçăo e o banco de dados. Garantir que sua aplicaçăo seja executada na maravilhosa web por milhares de pessoas satisfeitas em termos de desempenho no acesso ŕ informaçăo pode fazer a diferença entre a prosperidade e a ruína.
Entăo măos ŕ obra !
[ ] ´s
Salvio Padlipskas

