


Neste artigo estaremos interessados em fazer um estudo com relańŃo ao gerenciamento dos logs de transańŃo, os quais sŃo muito ·teis em tempos difĒceis que podemos ter com o mal funcionamento de nossas bases de dados. Teremos entŃo uma visŃo geral sendo apresentada nesse momento e posteriormente abordaremos pontos mais precisos com relańŃo a utilizańŃo dos logs para que possamos ter a compreensŃo correta na hora em precisarmos utilizß-los.
Podemos entender por logs de transańŃo sendo este um arquivo no qual o SQL Server armazena um registro com todas as transań§es realizadas e dados que foram modificados no banco de dados com o qual o arquivo de log possa estar associado. Isso ķ bem necessßrio para que em casos que o SQL Server seja desligado inesperadamente, como uma falha da instŌncia ou mesmo hardware, o log de transańŃo ķ utilizado para recuperar o banco de dados, com a integridade dos dados. Ap¾s o reinĒcio, um banco de dados entra em um processo de recuperańŃo em que o log de transańŃo ķ lido para garantir que todos os dados sejam vßlidos, onde os dados comitados serŃo escritos nos arquivos de dados, jß em casos em que quaisquer transań§es nŃo sejam parciais, estas sŃo desfeitas (realizańŃo de rollbacks). Em suma, o log de transańŃo ķ o meio fundamental pelo qual o SQL Server garante a integridade da base de dados e as propriedades ACID de transań§es. No papel de DBA, temos algumas tarefas importantes quanto a gestŃo de logs de transańŃo, sendo estes os seguintes:
Neste artigo, estaremos considerando cada uma destas tarefas de manutenńŃo em detalhes. No nosso primeiro momento, comeńaremos com uma visŃo geral de como o SQL Server usa o log de transańŃo, e duas das formas mais significativas de impactos na vida de um DBA, ou seja, a restaurańŃo e a recuperańŃo de banco de dados e gerenciamento de espańo em disco.
No SQL Server, o log de transańŃo ķ um arquivo fĒsico, identificado convencionalmente, embora nŃo obrigatoriamente, pela extensŃo FDL. Ele ķ criado automaticamente na criańŃo de um banco de dados, juntamente com o arquivo de dados principal, comumente identificado pela extensŃo de MDF, que armazena os objetos de banco de dados e os dados em si. O log de transańŃo, enquanto ele ķ implementado como um ·nico arquivo fĒsico geralmente, ele tambķm pode ser implementado como sendo um conjunto de arquivos. No entanto, mesmo neste ·ltimo caso, ainda ķ tratado pelo SQL Server como um ·nico arquivo de forma sequencial e, como tal, o SQL Server nŃo pode e nŃo escreve em paralelo com vßrios arquivos de log, e por isso nŃo hß vantagem com relańŃo a desempenho que possa ser tido a partir da implementańŃo do log de transańŃo com vßrios arquivos.
Sempre que ķ realizada uma alterańŃo com o c¾digo T-SQL em um objeto de banco de dados (DDL), ou mesmo, os dados que ele contķm, nŃo sŃo s¾ os dados ou objeto que sŃo atualizados no arquivo de dados, mas tambķm os detalhes da mudanńa que sŃo registrados como um registro de log na transańŃo log. Cada registro de log contķm detalhes sobre o ID da transańŃo que fez a mudanńa, quando essa operańŃo comeńou e quando ela terminou, quais pßginas foram alteradas, as alterań§es de dados que foram feitas, dentre outras informań§es relevantes. O que precisamos entender tambķm ķ que o log de transańŃo nŃo ķ uma trilha de auditoria. Ele nŃo fornece uma trilha de auditoria das alterań§es feitas ao banco de dados, nŃo mantķm um registro dos comandos que foram executados no banco de dados, assim como os dados alterados como resultado.
Quando uma modificańŃo de dados ķ feita, as pßginas de dados relevantes sŃo lidas a partir do cache de dados, ou serŃo recuperados primeiro do disco caso eles nŃo estejam no cache. Os dados sŃo modificados no cache de dados, e os registros de log para descrever os efeitos da operańŃo sŃo criados no cache de log. Quando uma transańŃo ķ confirmada, os registros de log sŃo gravados no log de transańŃo, no disco. No entanto, os dados que foram alterados nŃo podem ser gravados no disco atķ que ocorra o checkpoint do banco de dados. Qualquer pßgina em cache que foi modificada desde a sua leitura a partir do disco de modo que o valor dos dados em cache seja diferente do que estß no disco ķ chamada de ōpßgina sujaö. Estas pßginas sujas podem conter os dados que foram comprometidos para o arquivo de log de transańŃo, mas ainda nŃo para o arquivo de dados e os dados modificados por operań§es abertas, ou seja, aqueles que ainda nŃo tenham sido cometidos (ou revertida (roolback)).
Os checkpoints da base de dados realizam um scaneamento do cache e liberam todas as ōpßginas sujasö do disco, neste momento, as modificań§es sŃo refletidas no arquivo de dados fĒsico, bem como no arquivo de log. Isso acontece mesmo nos casos em que a transańŃo ainda estß aberta. Durante um checkpoint, as pßginas sujas relacionadas para abrir as transań§es sŃo liberadas para o disco, o SQL Server sempre assegura que os registros de log referentes a essas transań§es abertas sejam liberados a partir do cache de log para o arquivo de log de transańŃo antes que as pßginas sujas sejam liberadas para os arquivos de dados. Outro processo que verifica o cache de dados, ķ o LazyWriter, que tambķm pode escrever pßginas de dados no disco, de fora de um checkpoint, se forńado a fazĻ-lo por press§es de mem¾ria.
O ponto importante que devemos observar aqui ķ que o gerenciador de log de buffer sempre garante que as descriń§es de mudanńa (registros de log) sejam escritas no log de transańŃo, no disco, antes de as pßginas de dados serem escritas para os arquivos de dados fĒsicos. Este mecanismo ķ denominado log (ou registro) de write-ahead. ╔ essencialmente o mecanismo pelo qual o SQL Server garante durabilidade em suas transań§es.
Devido ao fato de sempre escrever as alterań§es no arquivo de log em primeiro lugar, o SQL Server tem a base de um mecanismo que possa garantir que os efeitos de todas as transań§es confirmadas sejam entŃo refletidos nos arquivos de dados, e que qualquer modificańŃo de dados no disco que se originar de transań§es incompletas, ou seja, aqueles para os quais nem um COMMIT ou um ROLLBACK foram emitidos em ·ltima anßlise, nŃo serŃo refletidos nos arquivos de dados.
Se um banco de dados quebra, por exemplo, depois de uma transańŃo (T1) ser comprometida, mas antes de os dados afetados serem escritos para o arquivo de dados, em seguida, durante a reinicializańŃo, o processo de recuperańŃo de banco de dados ķ iniciado, que tenta conciliar o conte·do das operań§es de arquivo de log e os arquivos de dados. Ele irß ler o arquivo de log de transańŃo e garantir que todas as operań§es que comp§em a transańŃo T1, registrada no arquivo de log, seja refeito para que sejam refletidas nos arquivos de dados.
Da mesma forma, ap¾s uma quebra do banco de dados, o processo de recuperańŃo irß "reverter" (desfazer) quaisquer alterań§es de dados no banco de dados que estŃo associados a transań§es nŃo confirmadas, lendo as operań§es relevantes do arquivo de log e executar a operańŃo inversa fĒsica sobre os dados. Desta forma, o SQL Server pode retornar o banco de dados para um estado consistente. De modo mais geral, o processo de reversŃo (desfazer) ocorre da seguinte forma:
Em tais circunstŌncias, os registros referentes a uma transańŃo interrompida, ou aquele para o qual o comando ROLLBACK ķ explicitamente emitido, sŃo lidas e as mudanńas sŃo revertidas. Dessa forma, o SQL Server garante que todas as ań§es associadas a uma operańŃo de sucesso, como uma unidade, ou que todos eles falham. Como tal, o log de transańŃo representa um dos meios fundamentais pelos quais o SQL Server garante a consistĻncia e integridade dos dados durante a operańŃo normal do dia a dia.
No entanto, o log de transańŃo desempenha um outro papel, o papel vital na medida em que fornece o mecanismo pelo qual o banco de dados pode ser restaurado para um ponto anterior no tempo, em caso de uma quebra. Com planejamento e gestŃo adequados, podemos usar backups destes arquivos de log para restaurar todos os nossos dados onde eles se tornaram danificados ou inutilizßveis.
Como dito anteriormente, um arquivo de log de transańŃo armazena uma sķrie de registros de logs, sequencial de acordo com quando a transańŃo comeńou, que dessa forma, fornecem um registro hist¾rico das modificań§es e operań§es que tenham sido emitidas contra esse banco de dados. Cada registro de log contķm detalhes sobre o ID da transańŃo que fez a mudanńa, quando essa operańŃo comeńou e terminou, quais pßginas foram alteradas, as alterań§es de dados que foram feitas, e assim por diante. Os registros de log no arquivo de log de transańŃo sŃo organizados em vßrias seń§es, que sŃo chamadas de Virtual Log Files (VLF).
O Mecanismo de log write-ahead do SQL Server garante que a descrińŃo de uma modificańŃo (ou seja, o registro de log) seja gravada em um VLF antes que os dados modificados sejam escritos para o arquivo de dados. Assim, um registro de log pode conter detalhes de uma transańŃo fechada (ou seja, comitada) ou uma transańŃo aberta (nŃo comitada), e em cada caso, os dados modificados pela transańŃo podem ou nŃo podem ter sido escritos para os arquivos de dados, dependendo de onde ocorreu um checkpoint ou nŃo. O processo de verificańŃo de banco de dados controla a quantidade de trabalho que o SQL Server precisa fazer durante uma operańŃo de recuperańŃo de banco de dados. Se o SQL Server teve que dar continuidade as mudanńas para um enorme n·mero de transań§es comitadas relacionadas com pßginas sujas, entŃo o processo de recuperańŃo poderß ser muito mais demorado.
Qualquer registro de log referente a uma transańŃo aberta pode ser necessßrio para uma operańŃo de reversŃo, durante a recuperańŃo, e sempre vai ser uma parte do que ķ chamado de um VLF ativo e devido a isso, sempre serß retido no arquivo de log. Um registro de log referente a uma transańŃo fechada tambķm serß parte de um VLF ativa, atķ atingir o ponto em que nŃo hß registros de log em todo o VLF que esteja associado com uma transańŃo aberta, onde o VLF passa a ser inativo.
Os registros de log contidos nessas VLF inativas essencialmente fornecem um "hist¾rico" das transań§es de banco de dados previamente preenchidas, e o que acontece com essas VLFs inativas varia de acordo com o modelo de recuperańŃo do banco de dados. Como exemplo, podemos citar que se estivermos usando a forma total do modelo de recuperańŃo de banco de dados (ou BULK Logged), entŃo o log de transańŃo mantķm os registros de log em VLF inativos, atķ que um backup do log seja tomado, o que trataremos posteriormente.
Ao fazer o backup do log de transańŃo, podemos entŃo capturar em um arquivo de backup todos os registros de log no log no momento da execuńŃo, incluindo os dessas VLFs inativas. Esses backups do log podem ser usados para restaurar o banco de dados para um ponto no tempo anterior; o que para n¾s seria muito melhor se ocorresse pr¾ximo a um ponto no tempo muito pr¾ximo do ponto em que as quebras ocorreram. No caso de uma quebra, os arquivos de backup de log podem ser aplicados a uma c¾pia restaurada de um arquivo de backup de banco de dados completo, e todas as transań§es que ocorreram ap¾s o backup completo serŃo executadas, durante a recuperańŃo do banco de dados, para recuperar o banco de dados e restaurar os dados para um determinado ponto no tempo, e assim minimizarmos qualquer perda de dados. Naturalmente, isso pressup§e que nŃo tenhamos apenas tomado esses backups de log, mas tambķm que os transferimos para locais seguros. Se os seus arquivos de backup do log estŃo na mesma unidade que o arquivo de registro, consequentemente onde tem as falhas no disco, entŃo podemos perder todos os nossos backups, e estaremos perdidos!
Quando um banco de dados estß no modelo de recuperańŃo simples, os registros de log existentes nos VLF ativos sŃo mantidos, uma vez que podem ser necessßrios para uma operańŃo de reversŃo (Rollback). No entanto, os VLF inativos serŃo truncados quando um checkpoint ocorrer, o que significa que os registros de log nessas VLF podem ser imediatamente substituĒdos por novos registros de log. ╔ por isso que um banco de dados operando em recuperańŃo simples ķ referido como estando em modo de auto truncado. Neste modo, nenhuma descrińŃo de fatos passados ķ mantida no registro e por isso nŃo pode ser capturada em um backup do log e usada como parte do processo de restaurańŃo.
De acordo com o ponto anterior, podemos ter certeza entŃo de que precisamos manter sempre um backup atualizado e seguro para casos de emergĻncia. No entanto, hß uma segunda razŃo importante a se tomar com relańŃo a esses backups do log quando estiverem operando em sua totalidade (ou em BULK_LOGGED) que ķ o controle do tamanho do log. Lembrem-se que um registro de log ķ gravado no arquivo de log para cada transańŃo que modifica os dados ou objetos em um banco de dados SQL Server. Em um sistema, com muitas transań§es simultŌneas, ou aqueles que escrevem um monte de dados, o log de transańŃo pode crescer em tamanho muito rapidamente.
Quando trabalhamos em modo full (ou BULK_LOGGED), a captura em um arquivo de backup de uma c¾pia dos registros de log em VLF inativas, ķ a ·nica ańŃo que vai fazer essas VLFs elegĒveis para um truncamento, o que significa que o espańo ocupado pelos registros de log se tornam disponĒveis para reutilizańŃo.
Algo que ķ necessßrio saber com relańŃo ao truncamento e ao tamanho dos logs de transańŃo ķ que hß um mal entendido comum que diz que truncar o arquivo de log significa que os registros de log sŃo excluĒdos e o arquivo diminui de tamanho... Ele nŃo ķ assim. O truncamento de um arquivo de log ķ simplesmente o ato de marcar o espańo como disponĒvel para reutilizańŃo. Portanto, uma das raz§es por que ķ vital para execuńŃo de backups do log de transańŃo regulares ao se trabalhar em modo full (ou BULK_LOGGED) ķ manter o controle com relańŃo ao tamanho do log. Agora vamos a um exemplo prßtico para comeńarmos a entender o processo de logs de transańŃo.
A fim de apresentarmos uma forma breve com relańŃo a alguns dos conceitos que discutimos neste artigo, serß feito um exemplo muito simples de como fazer backup do log de transańŃo para um banco de dados operando em modo de recuperańŃo total. Iremos entŃo criar uma nova base de dados chamada de TesteDB, utilizando o SQL Server 2014, mas podem utilizar outras vers§es, em seguida, obteremos o tamanho do arquivo de log inicial usando o comando SQLPERF (LOGSPACE). O c¾digo serß disposto como o apresentado pela Listagem 1.
Listagem 1. Tamanho do arquivo de Log inicial para a tabela de testes criada.
USE master ;
IF EXISTS ( SELECT name
FROM sys.databases
WHERE name = 'TesteDB' )
DROP DATABASE TesteDB ;
CREATE DATABASE TesteDB ON
(
NAME = TesteDB_dat,
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\TesteDB.mdf'
) LOG ON
(
NAME = TesteDB_log,
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\TesteDB.ldf'
) ;
DBCC SQLPERF(LOGSPACE);Como vocĻs podem ver, o arquivo de log tem aproximadamente 1 MB de tamanho, e cerca de 30% completo, como apresentado pela Figura 1. NŃo esqueńam de mudar os filenames para o caminho existente em sua mßquina, pois caso contrßrio nŃo irß funcionar. As caracterĒsticas iniciais de tamanho e crescimento dos bancos de dados do usußrio criados em uma instŌncia sŃo determinadas pelas propriedades do banco de dados do modelo, como ķ o modelo de recuperańŃo padrŃo que cada banco de dados irß utilizar (no nosso caso, o FULL).
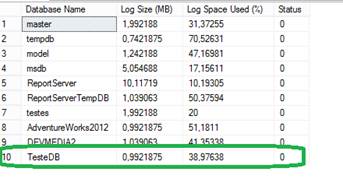
Figura 1. Tamanho do arquivo de log TesteDB.
Agora que temos nosso arquivo criado, vamos fazer um backup do arquivo de dados para TesteDB, como mostrado pela Listagem 2, para isso, criaremos primeiro o diret¾rio "backups" na unidade C. Notem aqui que esta operańŃo de backup garante que o banco de dados realmente estß operando em modo de recuperańŃo total.
Listagem 2. CriańŃo da pasta de backups para a realizańŃo do backup.
-- backup completo da base de dados
BACKUP DATABASE TesteDB
TO DISK ='C:\Backups\TesteDB.bak'
WITH INIT;
GOAtķ o momento nŃo hß nenhuma mudanńa no tamanho dos dados ou no arquivo de log, como resultado desta operańŃo de backup ou mesmo na porcentagem de espańo de log utilizado, o que talvez nŃo seja surpresa dado que nŃo hß tabelas de usußrio ou dados no banco de dados ainda. Vamos entŃo criar uma tabela chamada LogTeste no banco de dados, preenchĻ-lo com 500 mil registros, e reavaliar o tamanho do arquivo de log, como mostrado na Listagem 3. NŃo hß a necessidade de nos preocuparmos no momento com os detalhes do c¾digo.
Listagem 3. CriańŃo do script para gerańŃo de registros.
USE TesteDB ;
GO
IF OBJECT_ID('dbo.LogTeste', 'U') IS NOT NULL
DROP TABLE dbo.LogTeste;
-- "ID" possui um range def 1 atķ 500000 de numeros unicos
-- "Inteiros" possui um range def 1 atķ 50000 de numeros nŃo unicos
-- "texto";"AA"-"ZZ" string de 2 caracteres
-- "dinheiro"; 0.0000 to 99.9999 valores monetßrios
-- "Date" ; >=01/01/2000 and <01/01/2010 datas.
SELECT TOP 500000
ID = IDENTITY( INT,1,1 ),
Inteiros = ABS(CHECKSUM(NEWID())) % 50000 + 1 ,
texto = CHAR(ABS(CHECKSUM(NEWID())) % 26 + 65)
+ CHAR(ABS(CHECKSUM(NEWID())) % 26 + 65) ,
dinheiro = CAST(ABS(CHECKSUM(NEWID())) % 10000 / 100.0 AS MONEY) ,
Date = CAST(RAND(CHECKSUM(NEWID())) * 3653.0 + 36524.0 AS DATETIME)
INTO dbo.LogTeste
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2 ;
DBCC SQLPERF(LOGSPACE);Observem aqui que o tamanho do arquivo de log cresceu consideravelmente, como apresentado pela Figura 2, para quase 20MB e o registro ķ de 99% completo (os n·meros podem ser ligeiramente diferentes em seu sistema). Se f¶ssemos inserir mais dados, ele teria que crescer em tamanho novamente para acomodar mais registros de log.
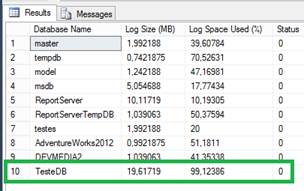
Figura 2. Registro de log alterado.
Caso tenham interesse, rodem novamente o script apresentado pela Listagem 2, para fazer o backup do arquivo de dados novamente, e isso nŃo farß diferenńa para o tamanho do arquivo de log, ou a porcentagem de espańo usado no arquivo. Agora, porķm, vamos fazer um backup do arquivo de log de transańŃo e verificar novamente os valores, como mostrado pela Listagem 4.
Listagem 4. Backup dos arquivos.
BACKUP Log TesteDB
TO DISK ='C:\Backups\TesteDB_log.bak'
WITH INIT;
GO
DBCC SQLPERF(LOGSPACE);O arquivo de log ainda ķ o mesmo tamanho fĒsico, mas por fazer o backup do arquivo, o SQL Server ķ capaz de truncar o log, tornando o espańo nas VLF "inativos" no arquivo de log disponĒvel para reutilizańŃo; mais registros de log podem ser adicionados sem a necessidade de crescer fisicamente o arquivo. Alķm disso, ķ claro, n¾s capturamos os registros de log em um arquivo de backup e assim seriamos capazes de usß-los como parte do processo de recuperańŃo de banco de dados, devemos entŃo precisar restaurar o banco de dados TesteDB para um estado anterior.
Com isso finalizamos o nosso artigo, onde explanamos um pouco com relańŃo ao gerenciamento de logs de transańŃo, apresentando alķm de uma parte te¾rica, um exemplo prßtico para um melhor conhecimento com relańŃo a como o SQL Server faz para manter a consistĻncia e a integridade dos dados, atravķs de um mecanismo de log write-ahead. N¾s tambķm apresentamos como um DBA pode capturar o conte·do do arquivo de log de transańŃo em um arquivo de backup, que pode ser reutilizado para restaurar o banco de dados como parte de um processo de recuperańŃo. Por fim, destacou-se a importŌncia de backups para controlar o tamanho do log de transańŃo.

Utilizamos cookies para fornecer uma melhor experiĻncia para nossos usußrios, consulte nossa polĒtica de privacidade.