


A sub-cláusula CUBE é utilizada no Oracle em instruçőes SELECT com GROUP BY. Ela possibilita o cálculo de subtotais e totais para diferentes níveis dos dados agregados.
Este artigo introduz a utilizaçăo básica desta operaçăo ainda pouco conhecida pelos desenvolvedores que trabalham com o SGBD Oracle. Para facilitar as explicaçőes, faremos uso da tabela exemplo “T_VENDAS” cujos dados săo apresentados na Figura 1. O script para criaçăo da tabela está disponibilizado na Listagem 1. Nesta tabela, cada registro representa um cliente diferente de uma loja de departamentos hipotética. O campo “Id” corresponde ŕ identificaçăo do cliente. Os campos “Sexo”, “Idade” e “UF” descrevem propriedades dos clientes, enquanto o campo e “Valor” indica o valor gasto na compra realizada por cada cliente.
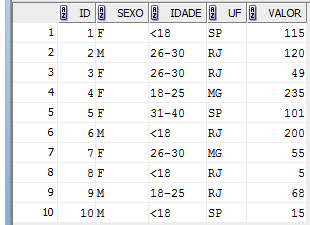
Figura 1: Tabela T_VENDAS
Listagem 1: Script para criar e popular a tabela “T_VENDAS”
//criaçăo da tabela
CREATE TABLE t_vendas (
id NUMBER PRIMARY KEY,
sexo CHAR(1),
idade CHAR(5),
UF CHAR(2),
VALOR NUMBER (5,2)
)
/
//inserindo dados na tabela
INSERT INTO t_vendas VALUES(1,'F','<18','SP',115);
INSERT INTO t_vendas VALUES(2,'M','26-30','RJ',120);
INSERT INTO t_vendas VALUES(3,'F','26-30','RJ',49);
INSERT INTO t_vendas VALUES(4,'F','18-25','MG',235);
INSERT INTO t_vendas VALUES(5,'F','31-40','SP',101);
INSERT INTO t_vendas VALUES(6,'M','<18','RJ',200);
INSERT INTO t_vendas VALUES(7,'F','26-30','MG',55);
INSERT INTO t_vendas VALUES(8,'F','<18','RJ',5);
INSERT INTO t_vendas VALUES(9,'M','18-25','RJ',68);
INSERT INTO t_vendas VALUES(10,'M','<18','SP',15);
COMMIT;
CUBE é uma operaçăo que pode ser entendida como uma espécie de “versăo tridimensional” da operaçăo de GROUP BY. Ela produz um maior número de resultados do que o produzido com em um SELECT com GROUP BY comum.
Vamos entăo comparar os dois tipos de instruçăo: (i) SELECT com GROUP BY x (ii) SELECT com GROUP BY e CUBE. Na Listagem 2, apresentamos o comando SELECT com GROUP BY que contabiliza a soma dos valores gastos nas compras dentro de grupos formados pelos campos “Sexo” e “UF”. O resultado da execuçăo da instruçăo é apresentado na Figura 2.
Listagem 2: SELECT com GROUP BY
SELECT SEXO, UF, SUM(VALOR)
FROM T_VENDAS
GROUP BY SEXO, UF
ORDER BY 1,2
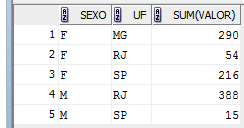
Figura 2: do SELECT com GROUP BY (Listagem 2)
Na Listagem 3, realizamos uma pequena modificaçăo nesta instruçăo através da inserçăo da sub-cláusula CUBE. Isto força a execuçăo da operaçăo de CUBE que adiciona algumas linhas de subtotais e uma linha de total geral no resultado do comando SELECT. Veja o resultado da execuçăo deste SELECT na Figura 3 e compare com o resultado do SELECT com GROUP BY comum apresentado na Listagem 1.
Listagem 3: SELECT com GROUP BY e CUBE
SELECT SEXO, UF, SUM(VALOR)
FROM T_VENDAS
GROUP BY CUBE (SEXO, UF)
ORDER BY 1,2
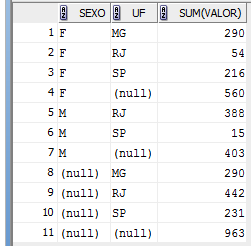
Figura 3: Resultado do SELECT com GROUP BY e CUBE (Listagem 3)
Em resumo, os efeitos produzidos pelo CUBE foram os seguintes:
A partir do exemplo, podemos concluir que a funçăo CUBE calcula subtotais para todas as combinaçőes possíveis das colunas selecionadas. Para que o conceito fique mais claro, veja o exemplo apresentado na Listagem 4 (resultados na Figura 4), onde o campo “Idade” também foi introduzido na tabulaçăo
Listagem 4: SELECT com GROUP BY e CUBE – introduçăo do campo “Idade”
SELECT IDADE, SEXO, UF, SUM(VALOR)
FROM T_VENDAS
GROUP BY CUBE (IDADE, SEXO, UF)
ORDER BY 1,2, 3
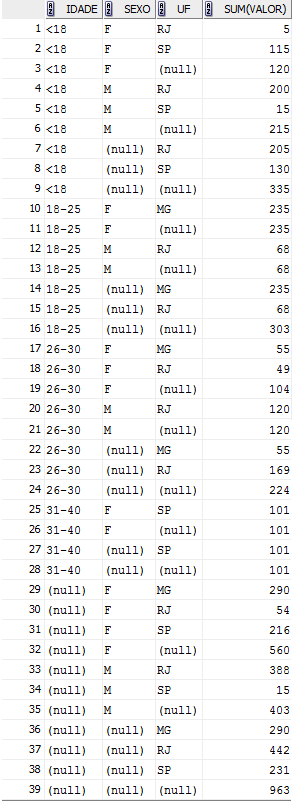
Figura 4: Resultado do SELECT da Listagem 4
A seguir săo relacionadas as regras de sintaxe para a sub-cláusula CUBE:
A funçăo GROUPING serve para identificar se uma linha é agregada ou “super-agregada” em instruçőes SELECT que realizam operaçőes de CUBE ou ROLLUP. A funçăo realiza uma açăo muito simples: ela retorna 1 quando identifica uma linha super-agregada para um determinado campo e 0 caso contrário. Veja os exemplos apresentados nas Listagens 5 e 6 para que a explicaçăo fique mais clara.
Listagem 5: SELECT com GROUP BY, CUBE e GROUPING no campo UF
SELECT GROUPING(UF), SEXO, UF, SUM(VALOR)
FROM T_VENDAS
GROUP BY CUBE (SEXO, UF)
ORDER BY 2,3
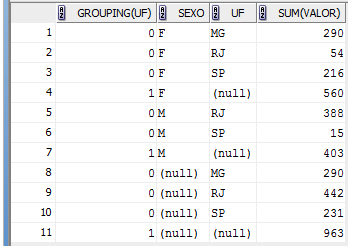
Figura 5: Resultado do SELECT com GROUP BY, CUBE e GROUPING (Listagem 5)
Listagem 6: SELECT com GROUP BY, CUBE e GROUPING nos campos UF e SEXO
SELECT GROUPING(SEXO), GROUPING(UF), SEXO, UF, SUM(VALOR)
FROM T_VENDAS
GROUP BY CUBE (SEXO, UF)
ORDER BY 3,4
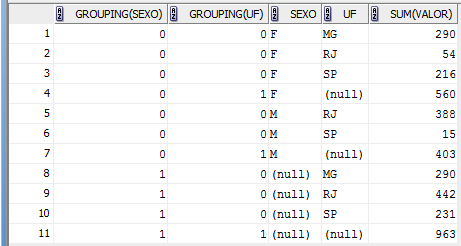
Figura 6: Resultado do SELECT com GROUP BY, CUBE e GROUPING (Listagem 6)
Assim encerramos o artigo sobre a operaçăo de CUBE e a funçăo GROUPING do Oracle. Ambas as funcionalidades săo utilizadas para tornar os comandos SELECT com GROUP BY mais flexíveis e poderosos, mantendo porém a simplicidade da sintaxe. Veja também o artigo sobre a operaçăo ROLLUP em: //www.devmedia.com.br/oracle-conhecendo-a-sub-clausula-rollup/26707
Até a próxima!

Veja os resultado dos nossos alunos
Conquistas reais de quem está aplicando o método








Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.