A plataforma Java disponibiliza diversas APIs para implementar o paralelismo desde as suas primeiras versűes, e estas veem evoluindo atť hoje, trazendo novos recursos e frameworks de alto nŪvel que auxiliam na programaÁ„o. No entanto, deve-se lembrar que a tecnologia n„o ť tudo. … importante, tambťm, conhecer os conceitos desse tipo de programaÁ„o e boas prŠticas no desenvolvimento voltado para esse cenŠrio.
O processamento paralelo, ou concorrente, tem como base um hardware multicore, onde dispűe-se de vŠrios nķcleos de processamento. Estas arquiteturas, no inŪcio do Java, n„o eram t„o comuns. No entanto, atualmente jŠ se encontram amplamente difundidas, tanto no contexto comercial como domťstico. Diante disso, para que n„o haja desperdŪcio desses recursos de hardware e possamos extrair mais desempenho do software desenvolvido, ť recomendado que alguma tťcnica de paralelismo seja utilizada.
Como sabemos, existem diversas formas de criar uma aplicaÁ„o que implemente paralelismo, formas estas que se diferem tanto em tťcnicas como em tecnologias empregadas. Em vista disso, no decorrer deste artigo ser„o contextualizadas as principais APIs Java, desde as threads ďclŠssicasĒ a modernos frameworks de alto nŪvel, visando otimizar a construÁ„o, a qualidade e o desempenho do software.
Uma arquitetura multicore consiste em uma CPU que possui mais de um nķcleo de processamento. Este tipo de hardware permite a execuÁ„o de mais de uma tarefa simultaneamente, ao contrŠrio das CPUs singlecore, que eram constituŪdas por apenas um nķcleo, o que significa, na prŠtica, que nada era executado efetivamente em paralelo.
A partir do momento em que se tornou inviŠvel desenvolver CPUs com frequÍncias (GHz) mais altas, devido ao superaquecimento, partiu-se para outra abordagem: criar CPUs multicore, isto ť, inserir vŠrios nķcleos no mesmo chip, com a premissa base de dividir para conquistar.
Ao contrŠrio do que muitos pensam, no entanto, os processadores multicore n„o somam a capacidade de processamento, e sim possibilitam a divis„o das tarefas entre si. Deste modo, um processador de dois nķcleos com clock de 2.0 GHz n„o equivale a um processador com um nķcleo de 4.0 GHz. A tecnologia multicore simplesmente permite a divis„o de tarefas entre os nķcleos de tal forma que efetivamente se tenha um processamento paralelo e, com isso, seja alcanÁado o t„o almejado ganho de performance.
Contudo, este ganho ť possŪvel apenas se o software implementar paralelismo. Neste contexto, os Sistemas Operacionais, hŠ anos, jŠ possuem suporte a multicore, mas isso somente otimiza o desempenho do průprio SO, o que n„o ť suficiente. O ideal ť cada software desenvolvido esteja apto a usufruir de todos os recursos de hardware disponŪveis para ele.
Ademais, considerando o fato de que hoje jŠ nos deparamos com celulares com processadores de quatro ou oito nķcleos, os softwares a eles disponibilizados devem estar preparados para lidar com esta arquitetura. Desde um simples projeto de robůtica a um software massivamente paralelo para um supercomputador de milhűes de nķcleos, a opÁ„o por paralelizar ou n„o, pode significar a diferenÁa entre passar dias processando uma determinada tarefa ou apenas alguns minutos.
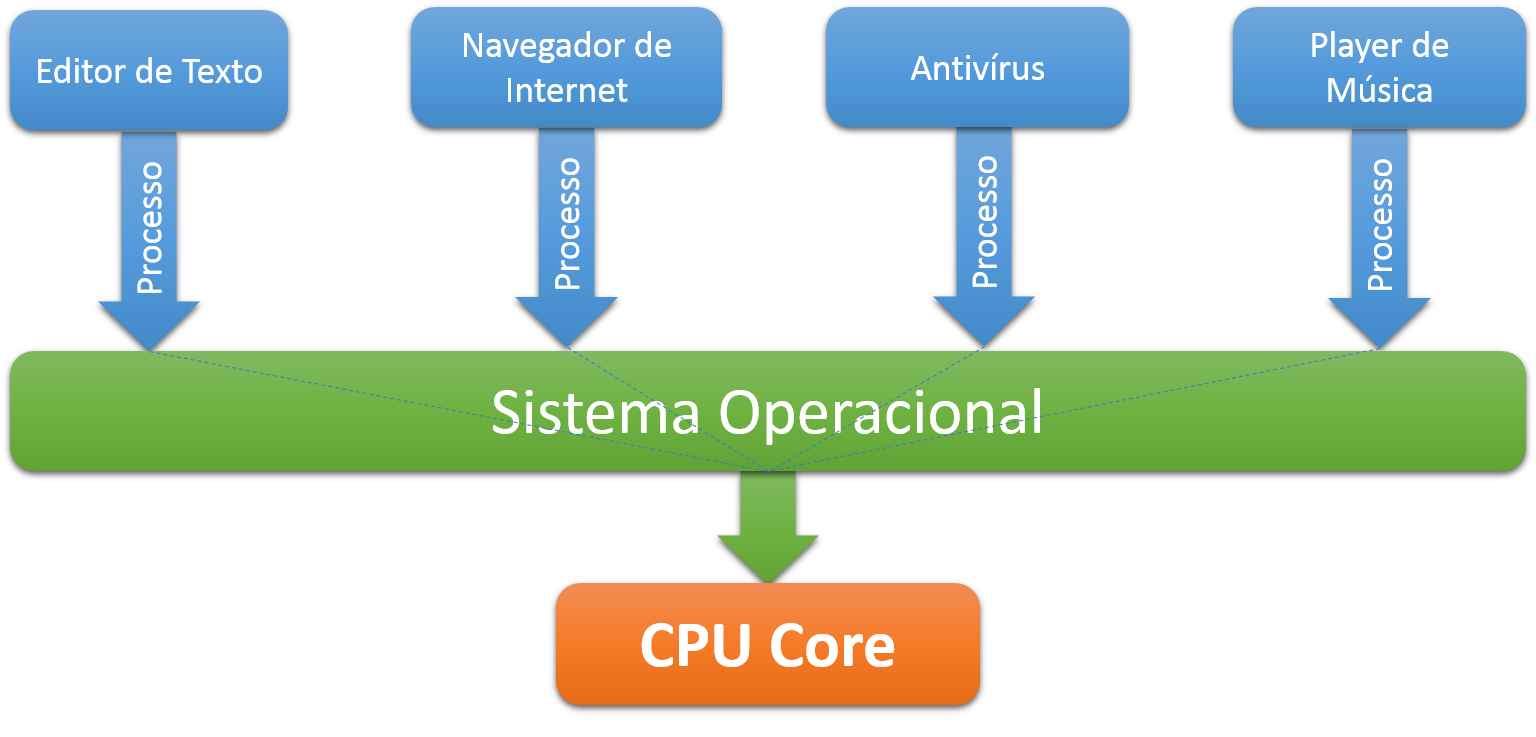
O multitasking, ou multitarefa, ť a capacidade que sistemas possuem de executar vŠrias tarefas ou processos ao mesmo tempo, compartilhando recursos de processamento como a CPU. Esta habilidade permite ao sistema operacional intercalar rapidamente os processos ativos para ocuparem a CPU, dando a impress„o de que est„o sendo executados simultaneamente, conforme a Figura 1.
No caso de uma arquitetura singlecore, ť possŪvel executar apenas uma tarefa por vez. Mas com o multitasking esse problema ť contornado gerenciando as tarefas a serem executadas atravťs de uma fila, onde cada uma executa por um determinado tempo na CPU. Nos sistemas operacionais isto se chama escalonamento de processos.
Figura 1. Processos executando em um nķcleo.
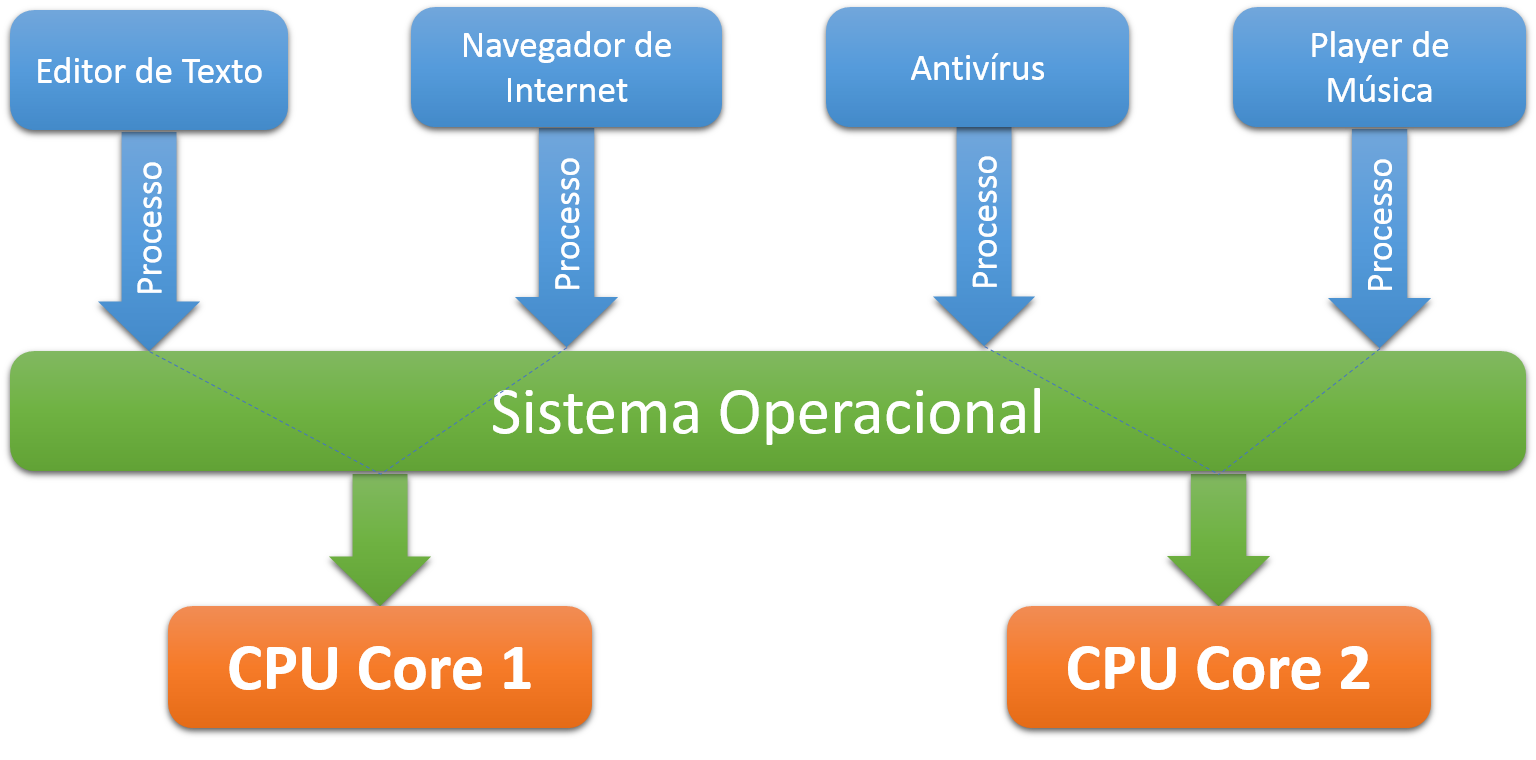
Em arquiteturas multicore, efetivamente os processos podem ser executados simultaneamente, conforme a Figura 2, mas ainda depende do escalonamento no sistema operacional, pois geralmente temos mais processos ativos do que nķcleos disponŪveis para processar.
Figura 2. Arquitetura multicore executando processos.
Desta forma, mais nķcleos de processamento significam que mais tarefas simult‚neas podem ser desempenhadas. Contudo, vale ressaltar que isto sů ť possŪvel se o software que estŠ sendo executado sobre tal arquitetura implementa o processamento concorrente. De nada adianta um processador de oito nķcleos se o software utiliza apenas um.
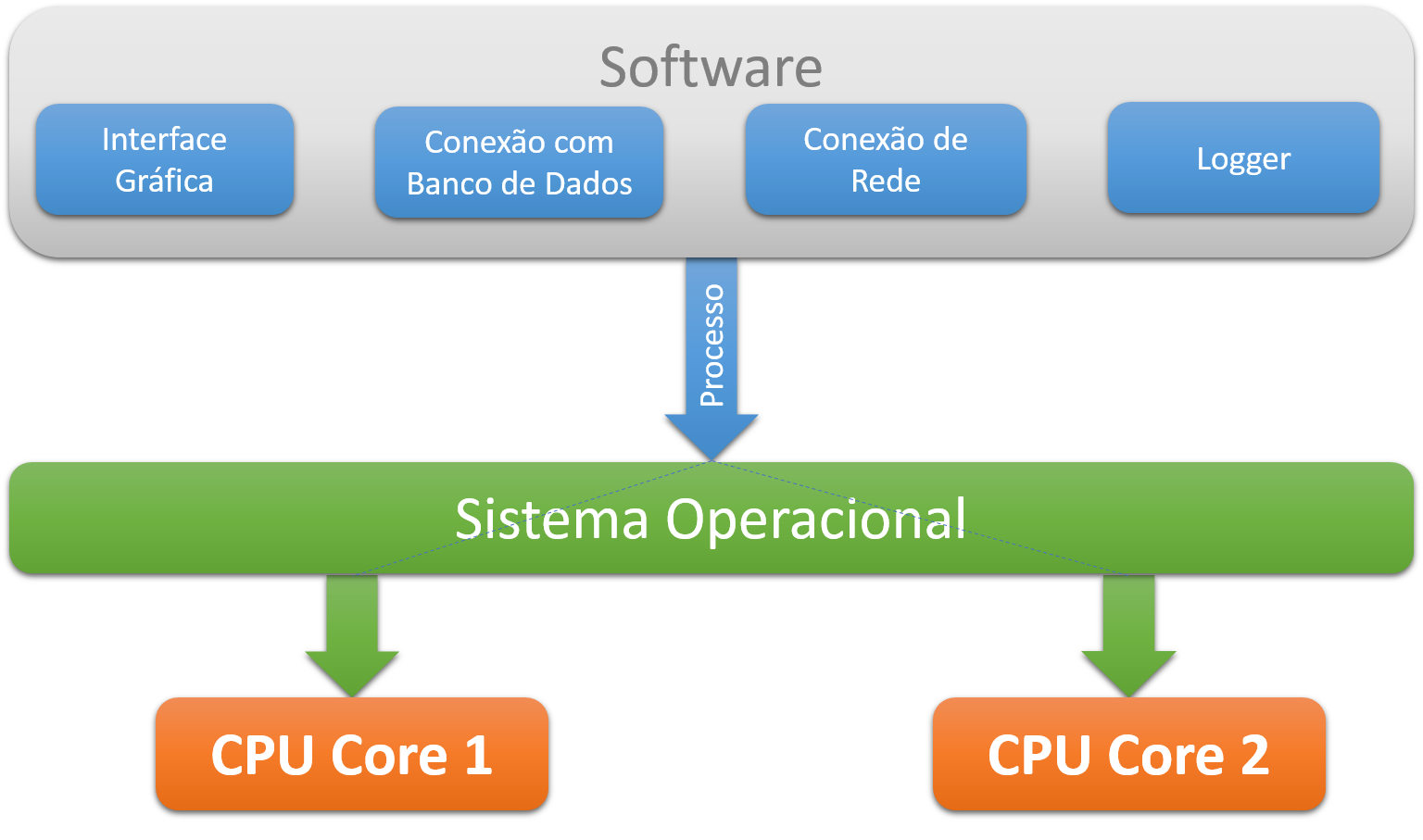
De certo modo, podemos compreender multithreading como uma evoluÁ„o do multitasking, mas em nŪvel de processo. Ele, basicamente, permite ao software subdividir suas tarefas em trechos de cůdigo independentes e capazes de executar em paralelo, chamados de threads. Com isto, cada uma destas tarefas pode ser executada em paralelo caso haja vŠrios nķcleos, conforme demonstra a Figura 3.
Figura 3. Processo executando vŠrias tarefas.
Diversos benefŪcios s„o adquiridos com este recurso, mas, sem dķvida, o mais procurado ť o ganho de performance. Alťm deste, no entanto, tambťm ť vŠlido destacar o uso mais eficiente da CPU. Sabendo dessa import‚ncia, nosso průximo passo ť entender o que s„o as threads e como criŠ-las para subdividir as tarefas do software.
Na plataforma Java, as threads s„o, de fato, o ķnico mecanismo de concorrÍncia suportado. De forma simples, podemos entender esse recurso como trechos de cůdigo que operam independentemente da sequÍncia de execuÁ„o principal. Como diferencial, enquanto os processos de software n„o dividem um mesmo espaÁo de memůria, as threads, sim, e isso lhes permite compartilhar dados e informaÁűes dentro do contexto do software.
Cada objeto de thread possui um identificador ķnico e inalterŠvel, um nome, uma prioridade, um estado, um gerenciador de exceÁűes, um espaÁo para armazenamento local e uma sťrie de estruturas utilizadas pela JVM e pelo sistema operacional, salvando seu contexto enquanto ela permanece pausada pelo escalonador.
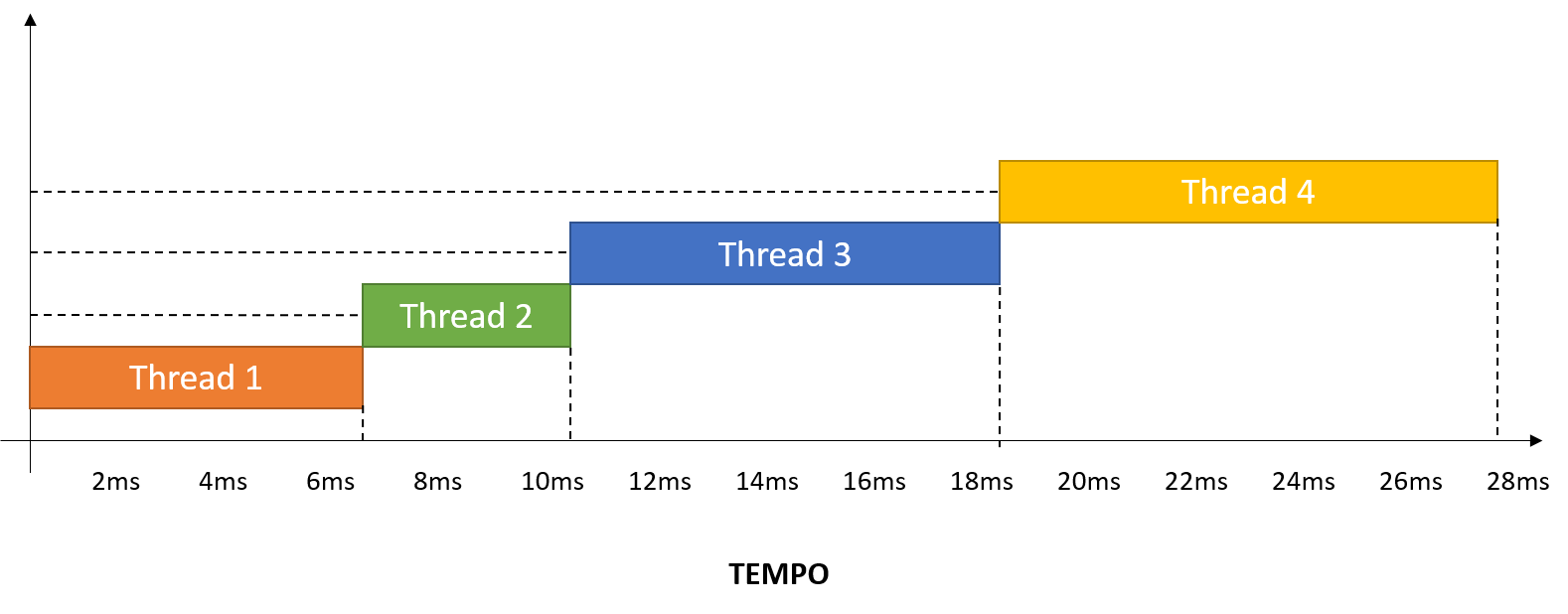
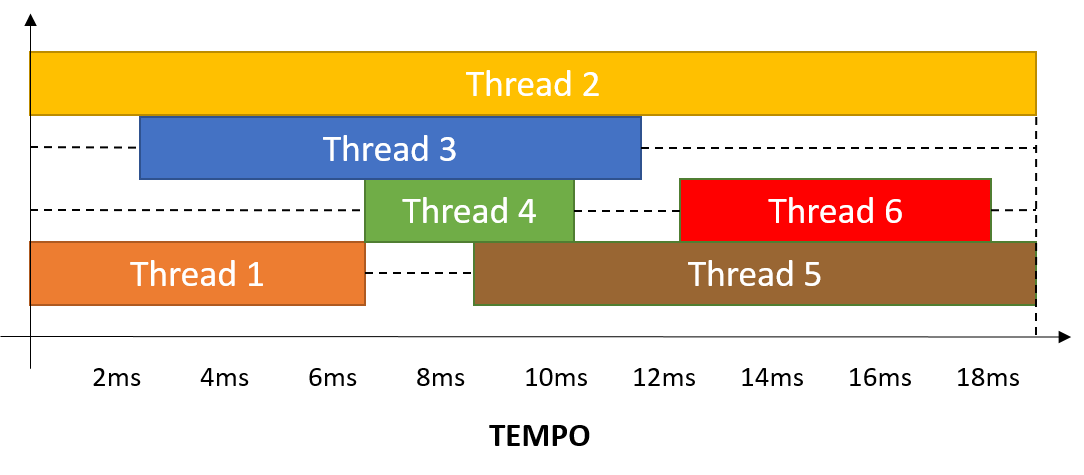
Na JVM, as threads s„o escalonadas de forma preemptiva seguindo a metodologia ďround-robinĒ. Isso quer dizer que o escalonador pode pausŠ-las e dar espaÁo e tempo para outra thread ser executada, conforme a Figura 4. O tempo que cada thread recebe para processar se dŠ conforme a prioridade que ela possui, ou seja, threads com prioridade mais alta ganham mais tempo para processar e s„o escalonadas com mais frequÍncia do que as outras.
Figura 4. Escalonamento de threads, modo round-robin.
Tambťm ť possŪvel observar na Figura 4 que apenas uma thread ť executada por vez. Isto normalmente acontece em casos onde sů hŠ um nķcleo de processamento, o software implementa um sincronismo de threads que n„o as permite executar em paralelo ou quando o sistema n„o faz uso de threads. Na Figura 5, por outro lado, temos um cenŠrio bem diferente, com vŠrias threads executando paralelamente e otimizando o uso da CPU.
Figura 5. Escalonamento de threads no modo round-robin implementando paralelismo.
Desde seu inŪcio a plataforma Java foi projetada para suportar programaÁ„o concorrente. De lŠ para cŠ, principalmente a partir da vers„o 5, foram incluŪdas APIs de alto nŪvel que nos fornecem cada vez mais recursos para a implementaÁ„o de tarefas paralelas, como as APIs presentes nos pacotes java.util.concurrent.*.
Saiba que toda aplicaÁ„o Java possui, no mŪnimo, uma thread. Esta ť criada e iniciada pela JVM quando iniciamos a aplicaÁ„o e sua tarefa ť executar o mťtodo main() da classe principal. Ela, portanto, executarŠ sequencialmente os cůdigos contidos neste mťtodo atť que termine, quando a thread encerrarŠ seu processamento e a aplicaÁ„o poderŠ ser finalizada.
Em Java, existem basicamente duas maneiras de criar threads:
Na Listagem 1, de forma simples e objetiva, ť apresentado um exemplo de como implementar uma Thread para executar uma subtarefa em paralelo. Para isso, primeiramente ť necessŠrio codificar um Runnable, o que pode ser feito diretamente na criaÁ„o da Thread, como demonstrado na Listagem 1, ou implementar uma classe průpria que estenda Runnable. Posteriormente, basta executŠ-lo com um objeto Thread atravťs do mťtodo start().
Listagem 1. Exemplo de thread implementando a interface Runnable.
public class ExemploThread { public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { //cůdigo para executar em paralelo System.out.println("ID: " + Thread.currentThread().getId()); System.out.println("Nome: " + Thread.currentThread().getName()); System.out.println("Prioridade: " + Thread.currentThread().getPriority()); System.out.println("Estado: " + Thread.currentThread().getState()); } }).start(); } }
Neste exemplo pode-se observar tambťm o cůdigo utilizado para buscar alguns dados da thread atual, tais como ID, nome, prioridade, estado e atť mesmo capturar o cůdigo que ela estŠ executando. Alťm de tais informaÁűes que podem ser capturadas, ť possŪvel manipular as threads utilizando alguns dos seguintes mťtodos:
A forma clŠssica de se criar uma thread ť estendendo a classe Thread, como demonstrado na Listagem 2. Neste cůdigo, temos a classe Tarefa estendendo a Thread. A partir disso, basta sobrescrever o mťtodo run(), o qual fica encarregado de executar o cůdigo da thread.
Na prŠtica, nossa classe Tarefa ť responsŠvel por realizar o somatůrio do intervalo de valores recebido no momento em que ela ť criada e armazenŠ-lo em uma variŠvel para que possa ser lido posteriormente.
Listagem 2. Cůdigo da classe Tarefa estendendo a classe Thread.
public class Tarefa extends Thread { private final long valorInicial; private final long valorFinal; private long total = 0; //mťtodo construtor que receberŠ os par‚metros da tarefa public Tarefa(int valorInicial, int valorFinal) { this.valorInicial = valorInicial; this.valorFinal = valorFinal; } //mťtodo que retorna o total calculado public long getTotal() { return total; } /* Este mťtodo se faz necessŠrio para que possamos dar start() na Thread e iniciar a tarefa em paralelo */ @Override public void run() { for (long i = valorInicial; i <= valorFinal; i++) { total += i; } } }
Listagem 3. Cůdigo da classe Exemplo, utiliza a classe Tarefa.
public class Exemplo { public static void main(String[] args) { //cria trÍs tarefas Tarefa t1 = new Tarefa(0, 1000); t1.setName("Tarefa1"); Tarefa t2 = new Tarefa(1001, 2000); t2.setName("Tarefa2"); Tarefa t3 = new Tarefa(2001, 3000); t3.setName("Tarefa3"); //inicia a execuÁ„o paralela das trÍs tarefas, iniciando trÍs novas threads no programa t1.start(); t2.start(); t3.start(); //aguarda a finalizaÁ„o das tarefas try { t1.join(); t2.join(); t3.join(); } catch (InterruptedException ex) { ex.printStackTrace(); } //Exibimos o somatůrio dos totalizadores de cada Thread System.out.println("Total: " + (t1.getTotal() + t2.getTotal() + t3.getTotal())); } }
Para testarmos o paralelismo com a classe da Listagem 2, criamos a classe Exemplo com o mťtodo main(), responsŠvel por executar o programa (vide Listagem 3). Neste exemplo, apůs criar as threads, chama-se o mťtodo start() de cada uma delas, para que iniciem suas tarefas. Logo apůs, em um bloco try-catch, temos a invocaÁ„o dos mťtodos join(). Este faz com que o programa aguarde a finalizaÁ„o de cada thread para que depois possa ler o valor totalizado por cada tarefa.
Observe, na Listagem 3, que cada tarefa recebe seu intervalo de valores a calcular, sendo somado, ao todo, de 0 a 3000, mas e se tivťssemos uma ķnica lista de valores que gostarŪamos de somar para obter o valor total? Neste caso, as threads precisariam concorrer pela lista. Isso ť o que chamamos de concorrÍncia de dados e geralmente traz consigo diversos problemas.
A concorrÍncia de dados ť um dos principais problemas a se enfrentar quando empregamos multithreading em uma aplicaÁ„o. Ela ť capaz de gerar desde inconsistÍncia nos dados compartilhados atť erros em tempo de execuÁ„o. No entanto, felizmente isto pode ser evitado, sendo necessŠrio, portanto, se precaver para que nosso aplicativo n„o apresente tais problemas.
Uma boa forma de evitar problemas de concorrÍncia ť sincronizar as threads que compartilham dados entre si. A partir disso, estas threads passam a executar em sincronia com outras, e assim, uma por vez acessarŠ o recurso. O sincronismo previne que duas ou mais threads acessem o mesmo recurso simultaneamente. Por outro lado, temos as threads assŪncronas, que executam independentemente umas das outras e geralmente n„o compartilham recursos, como ť o caso do exemplo das Listagens 2 e 3.
No exemplo da Listagem 4, por sua vez, ť possŪvel visualizar trÍs threads disputando a mesma variŠvel varCompartilhada para incrementŠ-la de forma assŪncrona. Basicamente, a ideia desse cůdigo ť incrementar uma variŠvel com diferentes valores e, a cada valor gerado, adicionŠ-lo em uma lista (ArrayList).
Listagem 4. Exemplo de concorrÍncia utilizando lista assŪncrona.
import java.util.ArrayList; import java.util.Collections; import java.util.List; public class ExemploAssincrono1 { private static int varCompartilhada = 0; private static final Integer QUANTIDADE = 10000; private static final List<Integer> VALORES = new ArrayList<>(); public static void main(String[] args) { Thread t1 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { VALORES.add(++varCompartilhada); } } }); Thread t2 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { VALORES.add(++varCompartilhada); } } }); Thread t3 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { VALORES.add(++varCompartilhada); } } }); t1.start(); t2.start(); t3.start(); try { t1.join(); t2.join(); t3.join(); } catch (InterruptedException ex) { ex.printStackTrace(); } int soma = 0; for (Integer valor : VALORES) { soma += valor; } System.out.println("Soma: " + soma); } }
No entanto, ao executar este algoritmo ť provŠvel que seja gerada a exceÁ„o java.lang.ArrayIndexOutOfBoundsException, devido ŗ concorrÍncia pela lista, visto que hŠ mais de uma thread tentando inserir dados nela. Como o ďponto fracoĒ desta estrutura de dados ť seu mecanismo din‚mico de tamanho variŠvel, a cada novo valor a ser inserido ť preciso expandir a lista. Desta forma, a thread perde tempo para fazer esta operaÁ„o, aumentando assim a possibilidade de ser pausada pelo escalonador. Quando isto acontece e alguma outra thread tenta realizar a mesma operaÁ„o de add(), a exceÁ„o ť gerada. Com o intuito de solucionar esse problema, uma das opÁűes ť adotar uma lista sincronizada, conforme o cůdigo a seguir:
private static final List<Integer> VALORES = Collections.synchronizedList(new ArrayList<>());Apesar de solucionar o problema anterior, ainda ť possŪvel que a thread sofra interrupÁ„o durante o incremento da variŠvel varCompartilhada e passe a gerar valores inconsistentes. Isto porque no processo atual de incremento da variŠvel, primeiramente deve ser pego o valor atual desta, somŠ-lo com 1 e ent„o obter o novo valor a ser armazenado.
Esse problema acontece porque nesse cůdigo existem trÍs threads alterando o valor da mesma variŠvel (nesse caso, com o operador ++) e o escalonador, quando aloca uma thread ao processador, permite que ela execute seu cůdigo por um determinado perŪodo de tempo e depois a interrompe, possibilitando que outra thread ocupe seu lugar e opere sobre os mesmos dados. Assim, quando a thread anterior voltar a processar, trabalharŠ com valores desatualizados.
Para aferir o resultado deste algoritmo, toda atualizaÁ„o de valor da variŠvel varCompartilhada ť adicionada a uma lista e ao final ť realizada a soma de todos esses valores. Por causa das situaÁűes supracitadas, no entanto, o resultado gerado a cada execuÁ„o pode ser diferente. Isto demonstra que o incremento de uma variŠvel assŪncrona em threads ť, sem dķvidas, um problema.
O exemplo apresentado na Listagem 5 traz uma derivaÁ„o do cůdigo da Listagem 4. Neste caso, o List foi substituŪdo por um Set, que suporta a inserÁ„o de valores de modo assŪncrono e ainda garante a unicidade dos valores inseridos. Assim, n„o mais teremos problemas com o ArrayList e poderemos dar sequÍncia ŗ demonstraÁ„o do problema de concorrÍncia com a varCompartilhada.
Listagem 5. Exemplo de concorrÍncia utilizando HashSet.
import java.util.HashSet; import java.util.Set; public class ExemploAssincrono2 { private static int varCompartilhada = 0; private static final Integer QUANTIDADE = 10000; private static final Set<Integer> VALORES = new HashSet<>(); public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { boolean novo = VALORES.add(++varCompartilhada); if (!novo) { System.out.println("JŠ existe: " + varCompartilhada); } } } }).start(); new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { boolean novo = VALORES.add(++varCompartilhada); if (!novo) { System.out.println("JŠ existe: " + varCompartilhada); } } } }).start(); new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { boolean novo = VALORES.add(++varCompartilhada); if (!novo) { System.out.println("JŠ existe: " + varCompartilhada); } } } }).start(); } }
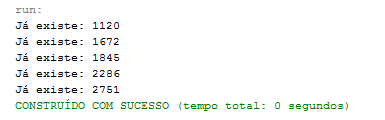
Ao executar este algoritmo diversas vezes ť possŪvel observar (vide Figura 6) que ele imprime no console alguns valores a serem inseridos que jŠ existem no Set, o que demonstra que as threads est„o incrementando a variŠvel, mas em algum momento geram o mesmo valor. Isso acontece por causa da concorrÍncia pela variŠvel varCompartilhada de maneira assŪncrona, onde ao incrementar esta variŠvel, mais de uma thread acaba gerando o mesmo valor.
Figura 6. Resultado no console com a execuÁ„o da Listagem 5.
Caso n„o seja uma opÁ„o substituir o ArrayList, uma alternativa para solucionar o problema obtido na Listagem 4 ť sincronizar o objeto concorrido; neste caso, a lista (vide Listagem 6). Isso ť possŪvel porque todo objeto Java possui um lock associado, que pode ser disputado por qualquer trecho de cůdigo sincronizado e em qualquer thread.
Listagem 6. Exemplo de sincronizaÁ„o de variŠvel com bloco de cůdigo sincronizado.
import java.util.ArrayList; import java.util.List; public class ExemploBlocoSincronizado { //declaraÁ„o das variŠveis - vide Listagem 4 public static void main(String[] args) { Thread t1 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { synchronized (VALORES) { VALORES.add(++varCompartilhada); } } } }); Thread t2 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { synchronized (VALORES) { VALORES.add(++varCompartilhada); } } } }); Thread t3 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { synchronized (VALORES) { VALORES.add(++varCompartilhada); } } } }); //Idem Listagem 4... } }
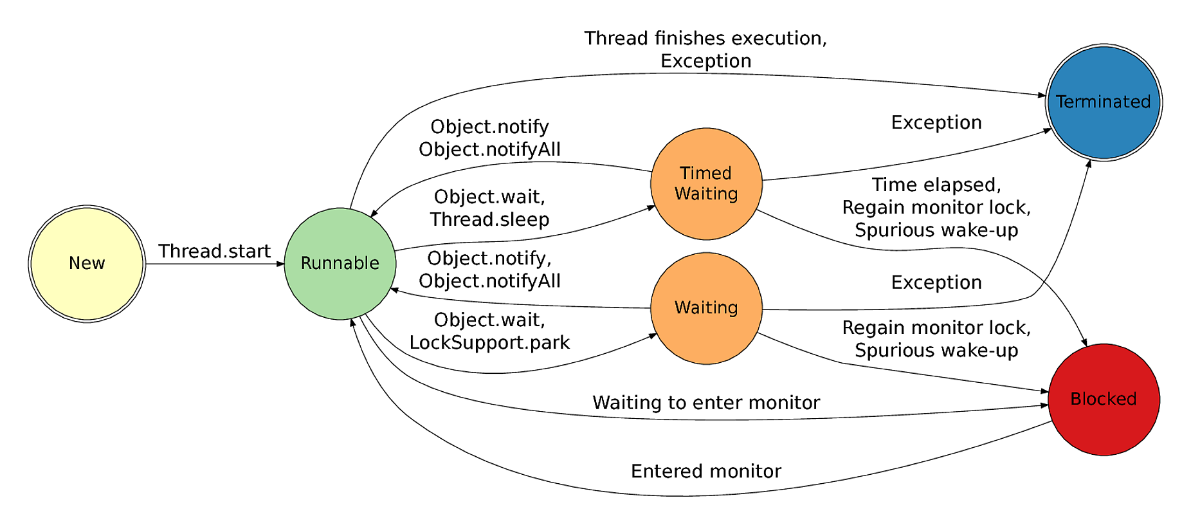
Um bloco sincronizado previne que mais de uma thread consiga executŠ-lo simultaneamente. Para isso, a thread que for utilizar esse bloco adquire o lock associado ao objeto sincronizado e as demais que tentarem acessŠ-lo entrar„o em estado de BLOCKED, atť que o objeto seja liberado. Na Figura 7 ť possŪvel observar o ciclo de vida de uma thread, da sua criaÁ„o ŗ sua finalizaÁ„o.
A seguir s„o descritos os possŪveis estados que elas podem assumir:
Figura 7. Ciclo de vida de uma thread.
Outra forma de acessar um dado compartilhado entre threads ť criando um mťtodo sincronizado. Essa tťcnica ť muito parecida com a anterior, mas ao invťs de sincronizar o mesmo bloco de cůdigo em cada thread, ele ť transferido para um mťtodo que contťm a notaÁ„o synchronized na assinatura. Assim, as threads ter„o que invocŠ-lo para realizar a operaÁ„o sobre o dado concorrente. Veja um exemplo na Listagem 7.
Listagem 7. Exemplo de mťtodo sincronizado.
import java.util.ArrayList; import java.util.List; public class ExemploMetodoSincronizado { //Idem Listagem 4... public static void main(String[] args) { Thread t1 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { incrementaEAdd(); } } }); Thread t2 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { incrementaEAdd(); } } }); Thread t3 = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < QUANTIDADE; i++) { incrementaEAdd(); } } }); //Idem Listagem 4 } private synchronized static void incrementaEAdd() { VALORES.add(++varCompartilhada); } }
Quando ť preciso utilizar tipos primitivos de forma concorrente uma boa opÁ„o ť adotar seu respectivo tipo atŰmico, presente no pacote java.util.concurrent.atomic. Este tipo de objeto disponibiliza operaÁűes como incremento atravťs de mťtodos průprios e s„o executadas em baixo nŪvel de hardware, de forma que a thread n„o serŠ interrompida durante o processo. Deste modo n„o ť necessŠrio sincronizar o objeto, gerando um algoritmo sem bloqueios e muito mais rŠpido. Veja o cůdigo a seguir:
private static AtomicInteger varCompartilhada = new AtomicInteger(0);Neste caso, ao invťs de utilizar um Integer para armazenar o valor, foi instanciado um AtomicInteger. Com isso, pode-se trocar o varCompartilhada++ pela chamada varCompartilhada.incrementAndGet(), que realizarŠ uma funÁ„o semelhante de forma atŰmica, o que garantirŠ que a thread n„o seja interrompida no meio do processo de incremento da variŠvel.
A interface Runnable ť utilizada desde as primeiras versűes da plataforma Java e como todos jŠ sabem, ela fornece um ķnico mťtodo Ė run() Ė que n„o aceita par‚metros e n„o retorna valor, assim como n„o pode lanÁar qualquer tipo de exceÁ„o. No entanto, e se precisŠssemos executar uma tarefa em paralelo e ao final obter um resultado como retorno? Para solucionar esse problema, vocÍ poderia criar um mťtodo na classe que implementa Thread ou Runnable e esperar pela conclus„o da tarefa para acessar o resultado, assim como no cenŠrio da Listagem 8.
Listagem 8. Exemplo de leitura de resultado em tarefa com Thread.
ThreadTarefa t = new ThreadTarefa(); t.start(); //inicia o trabalho da thread t.join(); //aguarda a thread finalizar String valor = t.getRetornoTarefa(); //acessa o resultado do processamento da tarefa.
Basicamente n„o hŠ nada de errado com esse cůdigo, mas a partir do Java 5 este processo pode ser feito de forma diferente, graÁas ŗ interface Callable. Deste modo, em vez de ter um mťtodo run(), a interface Callable oferece um mťtodo call(), que pode retornar um objeto qualquer, alťm da grande vantagem de poder capturar uma exceÁ„o gerada pela tarefa da thread.
Para tirar proveito dos benefŪcios de um objeto Callable, ť altamente recomendŠvel n„o utilizar um objeto Thread para executŠ-lo, e sim alguma outra API, como:
As implementaÁűes apresentadas nas Listagens 9 e 10 demonstram uma boa prŠtica no uso de Callables. Este cůdigo cria trÍs tarefas que levam um determinado tempo para concluir e, ao terminar, retornam o nome da thread que a realizou. O cůdigo da tarefa se encontra na classe ExemploCallable, que implementa a interface Callable, com retorno do tipo String. Com esta interface a tarefa que se deseja executar deve ser implementada no mťtodo call() (vide Listagem 9), o qual ť invocado ao executar o objeto Callable.
Listagem 9. Exemplo de classe implementando Callable.
import java.util.concurrent.Callable; public class ExemploCallable implements Callable<String> { private final long tempoDeEspera; public ExemploCallable(int time) { this.tempoDeEspera = time; } @Override public String call() throws Exception { Thread.sleep(tempoDeEspera); return Thread.currentThread().getName(); } }
Listagem 10. Exemplo de tarefas com retorno utilizando Callable.
package javamagazine.threads; import java.util.Arrays; import java.util.List; import java.util.concurrent.ExecutionException; import java.util.concurrent.ExecutorCompletionService; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class ExemploRetornoDeTarefa { public static void main(String[] args) { List<ExemploCallable> tarefas = Arrays.asList( new ExemploCallable(8000), new ExemploCallable(4000), new ExemploCallable(6000)); ExecutorService threadPool = Executors.newFixedThreadPool(3); ExecutorCompletionService<String> completionService = new ExecutorCompletionService<>(threadPool); //executa as tarefas for (ExemploCallable tarefa : tarefas) { completionService.submit(tarefa); } System.out.println("Tarefas iniciadas, aguardando conclus„o"); //aguarda e imprime o retorno de cada uma for (int i = 0; i < tarefas.size(); i++) { try { System.out.println(completionService.take().get()); } catch (InterruptedException | ExecutionException ex) { ex.printStackTrace(); } } threadPool.shutdown(); } }
O cůdigo da Listagem 10 tem o objetivo de criar e executar trÍs tarefas armazenadas em uma lista. Para simular uma diferenÁa no tempo de execuÁ„o das threads, cada uma foi desenvolvida para aguardar um certo tempo em milissegundos, que lhe ť fornecido no mťtodo construtor. Antes de executŠ-las, no entanto, note que ť criado um pool de threads com um ExecutorService, o qual posteriormente ť utilizado para criar um ExecutorCompletionService, que serŠ encarregado de executar as tarefas e tambťm nos serŠ ķtil para receber o retorno de cada uma delas conforme forem concluindo.
Dito isso, uma a uma as tarefas s„o executadas atravťs do mťtodo submit() e, por fim, ť utilizado o mťtodo take(), para buscar a tarefa concluŪda, e o mťtodo get(), que lÍ o retorno dela e o imprime no console (Figura 8).
Figura 8. Resultado da Listagem 10 no console.
Um recurso bastante utilizado no desenvolvimento de software s„o as coleÁűes de dados. Na plataforma Java estas estruturas est„o disponŪveis em uma sťrie de implementaÁűes para os mais diversos fins. Como sabemos, n„o hŠ nenhum ďmistťrioĒ em declarŠ-las, no entanto, como ť comum nos depararmos com bugs ao acessar essas estruturas de maneira concorrente, vale dedicar um tůpico deste artigo para explorar suas peculiaridades.
Dentre as coleÁűes disponŪveis no Java, existem variados tipos de estruturas de dados, como, listas, pilhas e filas, e estas, por sua vez, ainda se subdividem quanto a forma de implementaÁ„o, que compreende:
Sabendo disso, preferencialmente, opte por utilizar coleÁűes concorrentes, ao invťs das sincronizadas, pois as coleÁűes concorrentes possuem maior escalabilidade e suportam modificaÁűes simult‚neas de diversas threads sem precisar estabelecer um bloqueio. JŠ as coleÁűes sincronizadas tÍm sua performance degradada devido ao bloqueio que precisam estabelecer quando uma thread as acessa. Logo, isso tambťm significa que somente uma thread por vez pode modificŠ-las.
Um detalhe que costuma passar despercebido nas entrelinhas da programaÁ„o concorrente ť que n„o existe a garantia de execuÁ„o paralela ou de que cada thread vai executar em um nķcleo diferente. Criar threads apenas sugere ŗ JVM que aquilo seja paralelizado. Por exemplo, vocÍ pode ter um processador de quatro nķcleos e criar um aplicativo com quatro threads que processem exaustivamente, mas isso n„o lhe garante que cada uma das quatro threads ser„o executadas por um nķcleo diferente, t„o pouco consumir„o 100% de processamento. Portanto, n„o basta criar threads pensando que isto ť a soluÁ„o dos seus problemas. Neste caso, ao criar threads em demasia estar-se-ia degradando a performance, jŠ que a JVM gastaria muito tempo com o escalonamento delas, se comparado ao tempo total de processamento utilizado pelas threads.
Primeiramente, a aplicaÁ„o deve ser inteligente o bastante para criar o nķmero ideal de threads, ou seja, deve ser levada em consideraÁ„o a quantidade de processadores/nķcleos disponŪveis no sistema. Criar um nķmero de threads menor do que o nķmero de nķcleos disponŪveis gera desperdŪcio. Por outro lado, gerar um nķmero excessivamente maior de threads, causarŠ outro problema. SerŠ perdido mais tempo com o escalonamento das threads do que com as průprias tarefas que elas precisam executar, e assim, por mais que se esteja consumindo 100% da CPU, n„o se tem o desempenho mŠximo que se pode atingir.
Para amenizar este problema, um recurso muito ķtil da plataforma Java pode ser verificado no cůdigo apresentado a seguir, que permite ler a quantidade de nķcleos disponŪveis. A partir disso, podemos calcular o nķmero ideal de threads necessŠrias para atingir os 100% de processamento sem desperdŪcios, quando temos uma aplicaÁ„o que precisa realizar um cŠlculo exaustivo:
int nucleos = Runtime.getRuntime().availableProcessors();O frameworkFork/Join, introduzido na vers„o 7 da plataforma Java, ť uma implementaÁ„o da interface ExecutorService que auxilia o desenvolvedor a tirar proveito das arquiteturas multicore. Esta API foi projetada para as tarefas que podem ser quebradas em pequenas partes recursivamente, com o objetivo de usar todo o poder de processamento disponŪvel para melhorar o desempenho da aplicaÁ„o.
O exemplo apresentado nas Listagens 11 e 12 demonstra um cenŠrio onde o objetivo ť buscar, recursivamente em um sistema de arquivos, os arquivos com determinada extens„o. Ao iniciar, a tarefa recebe um diretůrio base onde o algoritmo comeÁa as buscas. O conteķdo do diretůrio ť ent„o analisado e caso haja outra pasta dentro desta, ť criada outra tarefa para analisar aquele diretůrio, e assim recursivamente o algoritmo realiza a busca pelos arquivos e retorna os resultados ŗ tarefa pai.
Tecnicamente, para realizar este processo foi implementada uma classe que estende RecursiveTask e recebe um List de String, o qual ť utilizado para informar o tipo de retorno da tarefa (vide Listagem 11). Ao criar a tarefa, ou seja, uma inst‚ncia da classe ProcessadorDePastas, ť necessŠrio informar por par‚metros o diretůrio base onde se iniciarŠ a busca e a extens„o de arquivo pela qual se darŠ a busca.
Quando se estende a classe RecursiveTask, deve ser implementado o mťtodo compute(), que ť responsŠvel por desempenhar a tarefa desejada, assim como devemos codificar o mťtodo run(), quando se implementa a interface Runnable. … neste mťtodo que estŠ especificada a busca pelos arquivos. Nele, o ponto mais importante pode ser verificado na recursividade, local que cria as tarefas paralelas com a chamada ao mťtodo fork() para cada pasta localizada dentro da pasta na qual se estŠ pesquisando. Ao final, cada subtarefa retorna os dados de sua busca ŗ tarefa que a criou, e esta, por sua vez, adiciona estes dados na lista ďtarefasĒ. Este ť o processo de desempilhar a recurs„o, que ť realizado atť chegar ŗ primeira tarefa criada na classe ForkJoinMain, momento este em que os dados s„o retornados para a lista resultados pelo mťtodo join() (vide Listagem 12).
Listagem 11. Exemplo de tarefa Fork/Join.
import java.io.File; import java.util.ArrayList; import java.util.List; import java.util.concurrent.RecursiveTask; public class ProcessadorDePastas extends RecursiveTask<List<String>> { private final String diretorio; private final String extensao; public ProcessadorDePastas(String diretorio, String extension) { this.diretorio = diretorio; this.extensao = extension; } @Override protected List<String> compute() { List<String> lista = new ArrayList<>(); List<ProcessadorDePastas> tarefas = new ArrayList<>(); File arquivo = new File(diretorio); File conteudo[] = arquivo.listFiles(); if (conteudo != null) { for (int i = 0; i < conteudo.length; i++) { if (conteudo[i].isDirectory()) { ProcessadorDePastas tarefa = new ProcessadorDePastas(conteudo[i].getAbsolutePath(), extensao); tarefa.fork(); tarefas.add(tarefa); } else if (verificaArquivo(conteudo[i].getName())) { lista.add(conteudo[i].getAbsolutePath()); } } } if (tarefas.size() > 50) { System.out.printf("%s: %d tarefas executando.\n", arquivo.getAbsolutePath(), tarefas.size()); } addResultadosDaTarefa(lista, tarefas); return lista; } private void addResultadosDaTarefa(List<String> lista, List<ProcessadorDePastas> tarefas) { for (ProcessadorDePastas item : tarefas) { lista.addAll(item.join()); } } private boolean verificaArquivo(String nome) { return nome.endsWith(extensao); } }
Na Listagem 12 temos o cůdigo responsŠvel por iniciar a tarefa principal, ler e exibir os resultados. Para tal, foram criadas trÍs tarefas base que far„o as buscas em trÍs pastas distintas, e a fim de executŠ-las, foi instanciado um pool de threads com um ForkJoinPool. Este tipo de pool gerencia de forma mais eficiente o trabalho das threads, pois utiliza uma tťcnica chamada de ďroubo de tarefaĒ para executar as tarefas em espera. Nesta abordagem cada thread possui uma fila de tarefas em espera e no momento em que uma thread n„o tiver mais nada em sua fila, poderŠ ďroubarĒ o trabalho de outra, possibilitando mais uma melhoria na performance.
Listagem 12. Exemplo de uso da tarefa Fork/Join.
import java.util.List; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.TimeUnit; public class ForkJoinMain { public static void main(String[] args) { ProcessadorDePastas sistema = new ProcessadorDePastas("C:/Windows", ".exe"); ProcessadorDePastas aplicativos = new ProcessadorDePastas("C:/Program Files", ".exe"); ProcessadorDePastas documentos = new ProcessadorDePastas("C:/users", ".doc"); ForkJoinPool pool = new ForkJoinPool(); pool.execute(sistema); pool.execute(aplicativos); pool.execute(documentos); do { System.out.printf("----------------------------------------\n"); System.out.printf("-> Paralelismo: %d\n", pool.getParallelism()); System.out.printf("-> Threads Ativas: %d\n", pool.getActiveThreadCount()); System.out.printf("-> Tarefas: %d\n", pool.getQueuedTaskCount()); System.out.printf("-> Roubos: %d\n", pool.getStealCount()); System.out.printf("----------------------------------------\n"); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } while ((!sistema.isDone()) || (!aplicativos.isDone()) || (!documentos.isDone())); pool.shutdown(); List<String> resultados; resultados = sistema.join(); System.out.printf("Sistema: %d aplicativos encontrados.\n", resultados.size()); resultados = aplicativos.join(); System.out.printf("Aplicativos: %d encontrados.\n", resultados.size()); resultados = documentos.join(); System.out.printf("Documentos: %d encontrados.\n", resultados.size()); } }
Por fim, saiba que enquanto o aplicativo processa ť possŪvel extrair algumas informaÁűes ķteis, a fim de monitorar o trabalho do framework e do pool de threads. Estes dados podem ser obtidos com o průprio objeto do pool, atravťs dos seguintes mťtodos:
A vers„o 8 da plataforma Java tem como uma das suas principais caracterŪsticas o suporte a expressűes Lambda, recurso que foi projetado com o intuito de facilitar a programaÁ„o funcional e reduzir o tempo de desenvolvimento. Isso pode ser exemplificado criando um objeto Thread, como expűe o cůdigo da Listagem 13, onde ť possŪvel notar que a criaÁ„o do objeto Runnable se torna implŪcita, reduzindo de cinco para duas a quantidade de linhas necessŠrias para a criaÁ„o de uma thread.
new Thread(() -> { //Cůdigo da tarefa a ser executada }).start();
Ainda no Java 8, uma nova abstraÁ„o, chamada Stream, foi desenvolvida. Esta permite processar dados de forma declarativa, assim como possibilita a execuÁ„o de tarefas utilizando vŠrios nķcleos sem que seja necessŠrio implementar uma linha de cůdigo multithreading, atravťs da funÁ„o parallelStream. Quando um stream ť executado em paralelo, a JVM o particiona em vŠrios substreams, os quais s„o iterados individualmente por threads e, por fim, seus resultados s„o combinados (veja Listagem 14).
Alťm de ser extremamente simples e funcional, em poucas linhas ť possŪvel extrair vŠrias informaÁűes de uma lista numťrica, como valor mŠximo, mŪnimo, soma total e mťdia, sem ter que se preocupar em desenvolver estas funÁűes. E mesmo que sua lista n„o seja numťrica, ainda assim se tornou mais fŠcil transformar ou extrair informaÁűes por meio das expressűes lambda.
Listagem 14. Exemplo utilizando ParallelStream.
import java.util.ArrayList; import java.util.List; import java.util.LongSummaryStatistics; import java.util.Random; public class ExemploParallelStream { public static void main(String[] args) { List<Long> numeros = new ArrayList<>(); Random random = new Random(); for (int i = 0; i < 10000000; i++) { numeros.add(random.nextLong()); } LongSummaryStatistics stats = numeros.parallelStream().mapToLong((x) -> x ).summaryStatistics(); System.out.println("Maior nķmero na lista: " + stats.getMax()); System.out.println("Menor nķmero na lista: " + stats.getMin()); System.out.println("Soma de todos os nķmeros: " + stats.getSum()); System.out.println("Mťdia de todos os nķmeros: " + stats.getAverage()); } }
O Java foi uma das primeiras plataformas a fornecer suporte a multithreading no nŪvel de linguagem e agora ť uma das primeiras a padronizar utilitŠrios e APIs de alto nŪvel para lidar com threads, como a introduÁ„o do framework Fork/Join na vers„o 7, e a API de streams e o suporte a expressűes lambda na vers„o 8.
Atualmente, qualquer computador ou smartphone tem mais de um nķcleo de processamento e a cada novo lanÁamento esta quantidade sů aumenta, assim como a import‚ncia do software ser desenvolvido em multithreading. Atendendo a esse cenŠrio, o Java fornece uma base sůlida para a criaÁ„o de uma ampla variedade de soluÁűes paralelas.
Para finalizar, note que ť possŪvel alcanÁar bons resultados com as tťcnicas aqui demonstradas. Contudo, sempre utilize a programaÁ„o concorrente com bastante atenÁ„o, pois ao manipular dados compartilhados entre threads poderŠ cair em alguns cenŠrios de depuraÁ„o bem difŪceis.

Utilizamos cookies para fornecer uma melhor experiÍncia para nossos usuŠrios, consulte nossa polŪtica de privacidade.