Utilizando o select para formatar dados em relatórios – Parte 02
Resumo
Alguns relatórios gerados a partir de instruçőes SELECT permitem a apresentaçăo dos dados para os usuários na forma de lista, onde os valores das colunas săo colocados linha a linha. Em determinadas situaçőes a quantidade dos dados precisa ser divida em colunas com o objetivo de facilitar a leitura do relatório. Este artigo apresenta uma maneira de dividir os dados entre as colunas apresentando-os alternadamente.
Dividindo os dados
Uma duplicaçăo dos dados como a que foi apresentada năo faz muito sentido. Dividiremos os dados colocando-os lado a lado nas colunas semelhantes, isto é, na primeira linha colocaremos o valor 1 para a coluna ID, ‘A’ para Nome e 16/09/2005 para a coluna Data. Na mesma linha vamos colocar o valor 2 para a coluna ID1, ‘B’ para NOME1 e 15/09/2005 para a coluna DATA1.
Com os dados neste novo formato gastaríamos apenas duas linhas no relatório ao invés de quatro para mostrar todos os dados. O leitor do relatório seguiria uma linha horizontal imaginária durante a leitura, facilitando o entendimento dos dados. A Tabela 3 apresenta os dados no formato desejado, considerando apenas as quatro linhas da tabela TB_SEPARA.

Tabela 3. Desejável divisăo dos dados através das colunas.
Para aplicar esta divisăo dos dados e colocá-los neste formato devemos partir de um caso particular primeiro, ou seja, consideraremos que a tabela tem uma quantidade par de registros. Depois trataremos do caso onde a quantidade de registros da tabela é ímpar.
A idéia utilizada para colocar nos dados neste formato é pensar em dividir os dados e depois relacioná-los. Analisando os dados da ‘primeira tabela’, aquela que manipulamos através do alias A, podemos perceber que os ID’s săo ímpares. Computacionalmente falando, o resto da divisăo por dois de cada um dos ID’s do alias A deve ser igual 1. De forma análoga, os ID’s do alias B devem ser pares, ou seja, o resto da divisăo por dois destes ID’s deve ser zero. A aplicaçăo do operador módulo (%) nos permite efetuar esta divisăo e obter somente as linhas cujos ID’s săo pares, para o alias A, e as linhas cujos ID’s săo ímpares, para o alias B.
Até aqui planejamos como iremos separar os dados entre os alias, que serăo implementados através de sub-querys na nossa instruçăo SELECT. Se executarmos a instruçăo apresentada na Listagem 2:
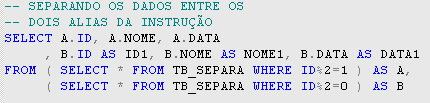
Listagem 2. Instruçăo SELECT que divide os dados entre os dois alias.
Năo vamos obter o que desejamos. O problema da instruçăo apresentada na Listagem 2 é que o SQL Server, assim como muitos bancos de dados, faz um cross join com os dados das tabelas utilizadas na instruçăo SELECT quando năo aplicamos uma regra de join entre as tabelas da instruçăo. O que precisamos fazer agora é implementar uma regra de join que relacione corretamente os dados dois alias A e B.
Analisando os dados das colunas ID e ID1 na Tabela 3 podemos perceber que o valor da coluna ID1 é sempre o valor da coluna ID mais um. Esta será a nossa regra do join, que pode ser vista na instruçăo SELECT da Listagem 3. Na cláusula WHERE utilizamos a coluna ID para o alias B, pois é somente na lista de colunas da instruçăo que trocamos o nome da coluna para ID1.
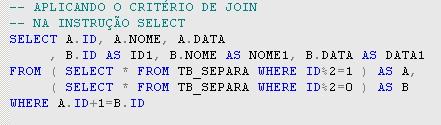
Listagem 3. Instruçăo SELECT com o critério de join.
No SQL Server temos duas maneiras de fazer joins: podemos utilizar a cláusula INNER JOIN ou fazer o join como na instruçăo da Listagem 3, relacionando as colunas na cláusula WHERE. Qualquer uma das duas maneiras pode ser utilizada, pois elas năo influenciam no resultado final que a instruçăo gera.
Executando a instruçăo SELECT da Listagem 3 obteremos os dados da maneira que desejamos e que foram mostrados na Tabela 3. E para o caso onde o número de linhas da tabela é ímpar ?
Neste caso é preciso definir como a linha ‘a mais’ será mostrada. Uma maneira adequada é mostrar esta linha ‘a mais’ é inseri-la no primeiro conjunto de linhas (colunas do alias A) e deixar as colunas correspondentes do segundo conjunto de linhas (colunas do alias B) com o valor NULL, que pode ser trocado na aplicaçăo que apresenta os dados ou através do uso da estrutura CASE do SQL Server.
A modificaçăo necessária na instruçăo SELECT é simples: basta utilizar um LEFT OUTTER JOIN, ou seja, indicar na instruçăo SELECT que as linhas do alias A que năo se relacionarem com as linhas do alias B também devem ser incluídas no resultado. A instruçăo final é apresentada na Listagem 4.
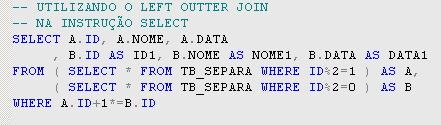
Listagem 4. Instruçăo SELECT que utiliza um LEFT OUTTER JOIN.
Notem que o operador *= foi implementado para indicar o LEFT OUTTER JOIN, que pode ser trocado sem problemas pela outra maneira de se fazer left joins no SQL Server. Supondo que a tabela TB_SEPARA tenha cinco linhas, a instruçăo SELECT da Listagem 4 irá transformar os dados para o formato exibido na Tabela 4.

Tabela 4. Divisăo da quantidade ímpar de dados.
Conclusăo
Este artigo apresentou uma implementaçăo que duplica os dados de uma tabela através da criaçăo de novas colunas e da separaçăo dos dados, desde que haja uma coluna na tabela que apresente uma numeraçăo seqüencial sem falhas. Algumas instruçőes SELECT foram apresentadas para implementar esta divisăo utilizando o dialeto T-SQL, que pode ser facilmente convertido para outros dialetos do SQL. Outras maneiras de dividir os dados podem ser implementadas, com a divisăo dos dados entre colunas, mas isso é assunto para um próximo artigo.

