… bastante comum se deparar com a necessidade de armazenar dados hier·rquicos em um sistema de informaÁ„o. Esses dados s„o aqueles que costumam ser visualizados na forma de ·rvore, com ligaÁıes entre nÛs pai e seus respectivos nÛs filhos. Alguns exemplos tÌpicos incluem composiÁ„o de produtos (Bill of Materials ñ BOM) e relaÁıes entre chefe/subordinado. ¿s vezes, atÈ mesmo a principal entidade de um modelo segue esta estrutura, como È o caso dos sistemas de fÛruns com suas mensagens aninhadas.
Quem j· precisou usar bancos de dados relacionais para atender a este tipo de situaÁ„o sabe que a modelagem pode ser intrincada e exigir um certo grau de raciocÌnio na definiÁ„o da melhor soluÁ„o. Afinal, trata-se de informaÁıes dispostas em uma hierarquia, com um n˙mero muitas vezes indeterminado de nÌveis. Dependendo da soluÁ„o adotada, alguns tipos de consulta podem exigir processamento recursivo, e outras podem atÈ mesmo ser difÌceis de formular.
O que muitos n„o sabem È que existem formas bastante interessantes de tratar hierarquias, usando modelos de dados dos mais diversos. Como n„o poderia deixar de ser, cada abordagem tem seus custos e benefÌcios, e esses s„o precisamente os aspectos discutidos neste artigo. Divirta-se avanÁando de seÁ„o em seÁ„o, ou como bom projetista de ·rvore, pulando de galho em galho.
Para usar um exemplo bem genÈrico e conhecido por todos, escolhemos o problema de modelagem das relaÁıes de subordinaÁ„o. Afinal, dentro de uma corporaÁ„o, infelizmente quase todos tÍm um chefe.
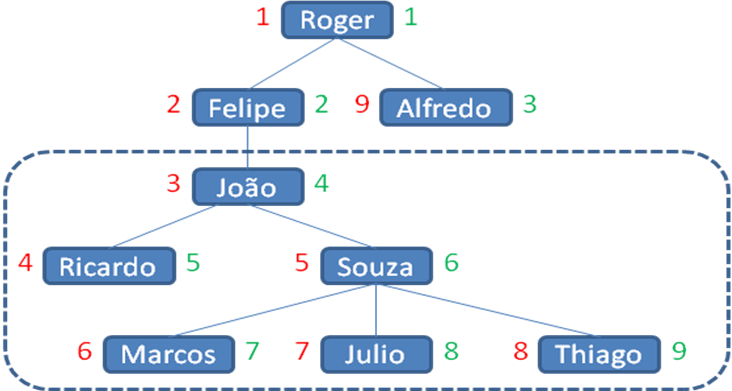
A Figura 1 mostra as relaÁıes de chefia em uma empresa fictÌcia. Para comeÁar, vamos analisar os componentes representados nesta ·rvore. Quando se fala sobre estruturas hier·rquicas, costuma-se utilizar uma nomenclatura prÛpria. Por exemplo, os elementos da ·rvore s„o chamados de nÛs, ou vÈrtices, e as ligaÁıes entre elementos s„o chamadas de arcos.
As relaÁıes (grau de parentesco) entre os nÛs tambÈm recebem nomes. NÛ pai (parent) È aquele que aparece acima de algum outro nÛ, enquanto um nÛ filho (child) aparece abaixo, tanto direta quanto indiretamente. Como j· se pode imaginar, nÛ irm„o (sibling) È o que possui o mesmo pai direto. Uma ·rvore tambÈm È composta por nÌveis que indicam a altura dos nÛs. Por exemplo, Roger, o Diretor Executivo, est· no primeiro nÌvel, enquanto seus subordinados diretos est„o no segundo.
Outro conceito importante que vale a pena destacar È o de caminhamento em ·rvores. O caminhamento se refere ý ordem em que os nÛs s„o acessados. Em ·rvores, existem dois tipos b·sicos, chamados de caminhamento em largura e em profundidade.
No primeiro deles (em largura), os nÛs s„o acessados da esquerda para a direita, dando prioridade para os nÛs de nÌvel mais alto. Na Figura 1, essa ordem È denotada pelos n˙meros destacados em verde. J· no segundo tipo (em profundidade), a prioridade È dada para os nÛs filhos. Na Figura 1, essa ordem È denotada pelos n˙meros destacados em vermelho. Essa, na verdade, È a forma mais corriqueira de se acessar nÛs quando o interesse È o de geraÁ„o de relatÛrios.
V·rios tipos de consulta podem ser formulados em modelos hier·rquicos. Neste artigo, analisaremos dois tipos apenas, que chamaremos de consulta ìDesceî e consulta ìSobeî. Na consulta ìDesceî, o objetivo È encontrar todas as relaÁıes de subordinaÁ„o existentes a partir de um certo nÛ da ·rvore. Por exemplo, supondo que queiramos saber quem s„o os subordinados do Jo„o, a resposta esperada È a parte tracejada na Figura 1. J· na consulta ìSobeî, o objetivo È descobrir os nomes de todos os chefes de alguÈm (diretos e indiretos). No caso do Jo„o, a resposta seria o conjunto composto por Roger->Felipe->Jo„o (o prÛprio objeto de consulta faz parte da resposta, e os registros s„o exibidos do chefe menos direto para o mais direto).
No decorrer do artigo, mostraremos como estas duas consultas podem ser respondidas usando formas alternativas de modelagem. Vale destacar que os questionamentos que ser„o suscitados para estes casos s„o genÈricos, e as respostas encontradas poder„o servir como guia geral para a soluÁ„o de diversos outros tipos de consulta hier·rquica.
O primeiro modelo que estudaremos È o descrito na Tabela 1. O esquema, que possui dados de funcion·rios, È um dos mais comuns quando se trata de modelos hier·rquicos, e recebe o nome de modelo adjacente. O nome deve-se ao fato de que a informaÁ„o do chefe (idChefe) È armazenada juntamente com outros dados do funcion·rio. Perceba a existÍncia de um autorrelacionamento entre idChefe e id.
| Funcion·rio | ||
| Id | Nome | idChefe |
| 1 | Roger | Null |
| 2 | Felipe | 1 |
| 3 | Alfredo | 1 |
| 4 | Joao | 2 |
| 5 | Ricardo | 4 |
| 6 | Souza | 4 |
| 7 | Marcos | 6 |
| 8 | Julio | 6 |
| 9 | Tiago | |
Quando se trata do modelo adjacente, uma das formas de resolver consultas È fixando (hardcoding) os critÈrios de junÁ„o SQL. A Listagem 1 mostra como ficariam os comandos SQL necess·rios para responder ýs consultas ìSobeî e ìDesceî. O par‚metro ì:IDî corresponde ao funcion·rio a partir de onde deve ser montada a resposta, que chamaremos de funcion·rio base. O mesmo par‚metro aparecer· nos demais exemplos descritos neste artigo para referenciar o funcion·rio base.
Consulta 1 ñ Subordinados (Consulta Desce)
SELECT base.id, base.nome, sub.id, sub.nome
FROM funcionario base LEFT JOIN funcionario sub
ON sub.idChefe = base.id
WHERE b.idChefe = :ID
ORDER BY base.id, sub.id
Consulta 1 ñ Chefes (Consulta Sobe)
SELECT chefe1.id, chefe1.nome, chefe2.id, chefe2.nome
FROM funcionario base, funcionario chefe1, funcionario
chefe2
WHERE base.id = :ID AND base.idChefe = chefe1.id
AND chefe1.idChefe = chefe2.id
ORDER BY chefe1.id, chefe2.id O problema com esta abordagem se torna evidente ao analisarmos a cl·usula WHERE. As junÁıes usadas conseguem atingir atÈ dois nÌveis hier·rquicos: no caso da consulta ìDesceî, dois nÌveis abaixo, e na consulta ìSobeî, dois nÌveis acima. No entanto, como costuma ocorrer com casos reais, n„o existem limites para os nÌveis de largura e profundidade da ·rvore. Assim sendo, se novos nÌveis fossem acrescidos, essas relaÁıes extras de subordinaÁ„o n„o seriam capturadas pelas consultas. Isso implicaria em manutenÁ„o de cÛdigo para que as consultas fossem adaptadas.
Supondo que o n˙mero de nÌveis seja constante, ainda assim o mÈtodo descrito merece algumas ressalvas. Em primeiro lugar destacamos o n˙mero de junÁıes necess·rias, equivalente ao n˙mero de nÌveis existentes entre o funcion·rio base e a raiz (para a consulta ìSobeî) ou entre o funcion·rio base e o ˙ltimo nÌvel (para a consulta ìDesceî). Dependendo da altura da ·rvore, o tempo necess·rio para o processamento dessas junÁıes pode se tornar proibitivo.
Outro fator que deve ser considerado È a redund‚ncia de dados, como demonstrado na Tabela 2. A tabela exibe o resultado de uma consulta ìDesceî adaptada que traz todos subordinados de Roger. As cÈlulas pintadas representam informaÁıes que j· foram capturadas em algum registro anterior. Como se pode ver, a redund‚ncia nesse caso chega a quase 50% dos resultados.
| Nivel 1 | Nivel 2 | Nivel 3 | Nivel 4 | Nivel 5 |
| Roger | Felipe | Joao | Ricardo | Null |
| Roger | Felipe | Joao | Souza | Marcos |
| Roger | Felipe | Joao | Souza | J˙lio |
| Roger | Felipe | Joao | Souza | Thiago |
| Roger | Alfredo | null | Null | Null |
Uma forma de evitar a prÈfixaÁ„o dos critÈrios de junÁ„o È atravÈs do uso de funÁıes recursivas, explorando as facilidades existentes nas linguagens de programaÁ„o. A Listagem 2 mostra um pseudocÛdigo que atende ýs consultas ìSobeî e ìDesceî.
Consulta 1 ñ Subordinados (Consulta Desce)
FUN«√O ExibeSubordinados(id, edentaÁ„o)
//camada de BD
SELECT id, nome
FROM funcionario WHERE idChefe = :id
//camada de software
FA«A ENQUANTO houver registros de funcionario
Realiza a endentaÁ„o
imprime funcionario.nome
//chamada recursiva
ExibeSubordinados(funcionario.id, edentaÁ„o+1)
FIM DA FUN«√O
//para imprimir os subordinados de Jo„o (id = 4)
ExibeSubordinados(4,1);
Consulta 1 ñ Chefes (Consulta Sobe)
FUN«√O EncontraChefes(id) //Consulta Sobe
//camada de BD
SELECT chefe.id, chefe.nome
FROM funcionario base, funcionario chefe
WHERE base.id = :ID AND base.idChefe = chefe.id
//camada de software
SE for encontrado algum registro
imprime chefe.nome
//chamada recursiva
EncontraChefes(chefe.id)
FIM DA FUN«√O
//Encontrar chefes do Jo„o (id = 4)
EncontraChefes(4); Quanto ý consulta ìDesceî, o cÛdigo recursivo vai sucessivamente obtendo/imprimindo os subordinados de cada funcion·rio, empregando o caminhamento em profundidade. A funÁ„o È genÈrica e permite que a impress„o comece em qualquer nÌvel da ·rvore atravÈs do fornecimento do identificador correto. Se o valor fornecido for nulo, a ·rvore inteira È impressa. O cÛdigo tambÈm descreve em linhas gerais como o controle de endentaÁ„o pode ser feito para garantir que a disposiÁ„o hier·rquica dos funcion·rios no relatÛrio possa ser visualmente compreendida.
O cÛdigo referente ý consulta ìSobeî segue a mesma linha do anterior. Em uma iteraÁ„o do algoritmo, È descoberto quem È o chefe do funcion·rio passado como par‚metro. AlÈm de serem impressos, os dados do chefe s„o repassados para a funÁ„o para que a iteraÁ„o seguinte descubra quem est· no nÌvel superior, e assim sucessivamente atÈ atingir o nÌvel m·ximo.
Conta a favor desta abordagem a sua simplicidade. O cÛdigo demonstrado È bastante intuitivo e poderia ser facilmente aplicado para resolver os problemas propostos neste artigo. No entanto, se trata de uma saÌda custosa, pois cada nÛ visitado gera uma consulta extra. Por exemplo, considerando a ·rvore da Figura 1, e supondo que se deseje imprimir a ·rvore inteira, nove consultas teriam que ser submetidas ao banco. Parece um n˙mero razo·vel, mas n„o se esqueÁa que estamos trabalhando com uma ·rvore bastante pequena. Em uma corporaÁ„o com muitos funcion·rios, o Ùnus de comunicaÁ„o com o banco tornaria esta soluÁ„o extremamente invi·vel.
Ainda considerando linguagens de programaÁ„o, pode-se reduzir os custos de comunicaÁ„o com o banco de dados atravÈs de um processo inicial de carga total para a memÛria. Nesse processo, todos os registros de funcion·rios s„o carregados para a memÛria onde ficam residentes em uma estrutura de ·rvore.
A consulta SQL de carga È simples, como mostra a Listagem 3. O trabalho maior fica a cargo da linguagem de programaÁ„o, que dever· criar os objetos relativos aos funcion·rios e associ·-los aos seus chefes. Com todos os dados em memÛria, consultas s„o respondidas atravÈs do caminhamento da ·rvore.
//ObtÈm todos os dados
SELECT f.id, f.nome, f.idChefe
FROM funcionario f Como benefÌcio desta abordagem, tÍm-se todos os recursos da linguagem de programaÁ„o ý disposiÁ„o para a realizaÁ„o das consultas, o que assegura um poder de express„o muito maior do que o de uma linguagem declarativa como a SQL. Outra vantagem em relaÁ„o ao mÈtodo anterior est· no n˙mero reduzido de acessos ao banco (necess·rios apenas no momento de carga inicial).
Caso n„o seja possÌvel manter os dados em sess„o, a saÌda È recriar a ·rvore a cada requisiÁ„o ao servidor. Aqui È importante ter cuidado. Caso a tabela possua muitos registros, a consulta pode ser muito custosa. Na verdade, se o n˙mero de registros for muito elevado, atÈ mesmo manter a ·rvore em memÛria È perigoso. Se este for o caso, talvez seja melhor escolher outra alternativa.
Nas duas seÁıes anteriores, vimos como os problemas propostos s„o resolvidos quando se delega a complexidade para a camada de software. Nesta seÁ„o, o enfoque È oposto. Boa parte do processamento È realizada dentro de uma stored procedure (SP), deixando para a camada de software o simples trabalho de impress„o dos resultados obtidos.
A Listagem 4 mostra stored procedures em MySQL usadas para encontrar as respostas. Como se pode ver, as SPs s„o bastante parecidas. Os dois algoritmos utilizam uma tabela auxiliar, usada para armazenar resultados parciais. Basicamente, no decorrer do processamento s„o realizadas buscas em largura, jogando para a tabela auxiliar os registros que forem sendo encontrados.
Para a consulta ìDesceî, a cada iteraÁ„o s„o buscados os registros cujos chefes j· estiverem na tabela de resposta. Para a consulta ìSobeî, a cada iteraÁ„o s„o buscados os registros cujos subordinados j· estiverem na tabela de resposta. A clausula IGNORE È prÛpria do MySQL e garante que n„o ocorrer· erro ao se tentar inserir registros que j· existirem na tabela.
Consulta 1 ñ Subordinados (Consulta Desce)
DROP PROCEDURE IF EXISTS calculaArvore;
DELIMITER go
CREATE PROCEDURE calculaArvore(raiz INT )
BEGIN
DROP TABLE IF EXISTS arvore;
CREATE TABLE arvore
SELECT id, idChefe, 0 AS nivel
FROM funcionario
WHERE idChefe = raiz;
ALTER TABLE arvore ADD PRIMARY KEY(id);
REPEAT
INSERT IGNORE INTO arvore
SELECT f.id, f.idChefe, arv.nivel+1
FROM funcionario f
JOIN arvore arv ON f.idChefe = arv.id;
UNTIL Row_Count() = 0 END REPEAT;
END;
go
Consulta 2 ñ Chefes (Consulta Sobe)
DROP PROCEDURE IF EXISTS calculaArvore;
DELIMITER go
CREATE PROCEDURE calculaArvore(raiz INT )
BEGIN
DROP TABLE IF EXISTS arvore;
CREATE TABLE arvore
SELECT id, idChefe, 0 AS nivel
FROM funcionario
WHERE id = raiz;
ALTER TABLE arvore ADD PRIMARY KEY(id);
REPEAT
INSERT IGNORE INTO arvore
SELECT f.id, f.idChefe, arv.nivel+1
FROM funcionario f
JOIN arvore arv ON arv.idChefe = f.id;
UNTIL Row_Count() = 0 END REPEAT;
END;
go A computaÁ„o comeÁa a ficar mais densa ý medida que a tabela auxiliar aumenta, pois a cada iteraÁ„o os dados dessa tabela s„o cruzados com os dados da tabela ìFuncionarioî. Outro efeito desagrad·vel È o desperdÌcio de processamento na geraÁ„o de registros redundantes, pois o conjunto de dados usado em uma interaÁ„o para encontrar resultados È um subconjunto dos dados usados na interaÁ„o seguinte. Ou seja, mesmo reduzindo os custos de comunicaÁ„o com o SGBD, os custos internos de processamento podem se tornar expressivos. Dependendo da polÌtica de seguranÁa configurada pelo DBA, È bem possÌvel que consultas demoradas sejam interrompidas por timeout.
Se for esse o caso, n„o se preocupe, existem diversos tipos de SP que podem ser usadas. A que foi mostrada acima usa particularidades do MySQL, e consegue fugir do processamento recursivo, t„o temido por alguns. Outros tipos de SP s„o mais genÈricos (n„o ficam restritos a algum SGBD especÌfico) e usam estratÈgias diferentes para buscar os dados de interesse. Por exemplo, uma abordagem genÈrica bastante comum emprega tabelas auxiliares que tem por objetivo empilhar informaÁıes. Em um momento posterior, estas informaÁıes s„o desempilhadas e tratadas j· na ordem correta de caminhamento.
Observe que, para a consulta ìDesceî, os registros s„o disponibilizados na ordem de caminhamento em largura. … necess·rio levar isso em consideraÁ„o na hora de elaborar o algoritmo que consumir· esses dados, principalmente se o objetivo for a geraÁ„o de relatÛrios de subordinaÁ„o. No caminhamento em largura, muitos dos nÛs lidos sÛ ser„o impressos mais adiante. Assim, È preciso mantÍ-los em memÛria atÈ o momento em que eles forem processados. Antes de adotar uma soluÁ„o baseada no caminhamento em largura, verifique se essa sobrecarga È aceit·vel. J· no caminhamento em profundidade os nÛs s„o lidos na ordem em que devem ser impressos. A princÌpio isso parece evitar o uso desnecess·rio de recursos computacionais. No entanto, dependendo de como a soluÁ„o foi desenvolvida, parte das vantagens dessa forma de caminhamento s„o perdidas. Por exemplo, caso a soluÁ„o seja baseada em recursividade, È possÌvel que alguns recursos precisem ser alocados, seja na forma de registros em memÛria ou conexıes extras com o banco de dados.
A seÁ„o anterior mostrou como problemas de consultas hier·rquicas podem ser resolvidos usando Stored Procedures. Apesar desse recurso estar presente em praticamente todos SGBDs comerciais, a sintaxe para criaÁ„o das SPs È prÛpria de cada fornecedor. Isso dificulta processos de migraÁ„o de bancos de dados, pois todas SPs precisariam ser convertidas para o novo formato. Caso vocÍ esteja muito satisfeito com seu banco, e n„o se preocupa com o uso de recursos especÌficos, siga lendo esta seÁ„o.
O que apresentaremos se chama Common table Expressions (CTE). Esse recurso permite gerar resultados intermedi·rios, que s„o complementados atravÈs de chamadas recursivas que usam os mesmos resultados intermedi·rios. A capacidade de chamar a si prÛprio possibilita que estruturas hier·rquicas sejam processadas de forma simples.
A Listagem 5 mostra como responder as consultas ìSobeî e ìDesceî utilizando CTE. O cÛdigo usa a sintaxe prÛpria do PostGres, mas com poucas adaptaÁıes ele pode ser traduzido para sintaxes de outros bancos, como DB2 e SQL Server.
Consulta 1 ñ Subordinados (Consulta Desce)
WITH RECURSIVE chefe AS
(
SELECT id, nome, idChefe, 0 AS nivel
FROM funcionario WHERE id= :ID
UNION ALL
-- chamada recursiva
SELECT sub.id, sub.nome, sub.idChefe, nivel+1
FROM funcionario sub
JOIN chefe ON (sub.idChefe = chefe.id)
)
SELECT * FROM chefe ORDER BY nivel;
Consulta 2 ñ Chefes (Consulta Sobe)
WITH RECURSIVE sub AS
(
SELECT id, name, idChefe, 0 AS nivel
FROM funcionario WHERE id= :ID
UNION ALL
-- chamada recursiva
SELECT chefe.id, chefe.name, chefe.idChefe, nivel+1
FROM funcionario chefe
JOIN sub ON (sub.idChefe = chefe.id)
)
SELECT * FROM sub ORDER BY nivel DESC; Para a consulta ìDesceî, o resultado intermedi·rio pode ser gerado inicialmente com um registro base, correspondente ao chefe de interesse. Uma chamada recursiva seria usada para encontrar os subordinados desse chefe. Para esses subordinados, uma nova chamada recursiva seria usada para encontrar seus respectivos subordinados, e assim por diante. No final, todos os registros encontrados s„o unidos. O efeito È parecido a SP demonstrada na seÁ„o anterior, com os registros finais gerados na ordem de caminhamento em largura. No entanto, o mecanismo empregado para a geraÁ„o da resposta È mais eficiente, n„o calculando registros redundantes e usando conjuntos de dados mais enxutos durante a computaÁ„o. J· a consulta ìSobeî se assemelha tanto com a consulta ìDesceî que dispensa muita explicaÁ„o. A ˙nica diferenÁa È que a recurs„o È usada para buscar os chefes, e com isso o critÈrio de junÁ„o (chefe=idChefe) precisa ser invertido. Vale ressaltar que esse artifÌcio n„o est· presente em todos SGBDs. Por exemplo, o MySQL n„o possui suporte a esse tipo de chamada recursiva. Para tratar dados hier·rquicos no MySQL, ou usa-se algum mÈtodo baseado em SQL ANSI ou usa-se stored procedures como as descritas na seÁ„o anterior. J· outros SGBDs n„o apenas suportam CTE, mas oferecem outras possibilidades para fins parecidos. Por exemplo, o CONNECT BY da Oracle resolve consultas hier·rquicas de uma maneira relativamente simples.
Outro ponto que merece destaque È um que j· foi mencionado antes. O grande inconveniente das soluÁıes comentadas nessa seÁ„o, seja CTE, SPs ou CONNECT BY, È o fato de que elas usam linguagens propriet·rias. Se porventura surgir a necessidade de migrar para outro fornecedor de banco de dados, todo cÛdigo propriet·rio precisar· ser convertido. Em alguns casos a convers„o pode ser intuitiva, mas de qualquer forma, ser· algo a mais com o que se preocupar.
A Tabela 3 mostra como ficam os dados de exemplo depois da adiÁ„o destes atributos. Opcionalmente, a tabela poderia ser dividida verticalmente em duas, deixando a tabela original com informaÁıes prÛprias do funcion·rio (ex. ìIdî, ìnomeî) e a tabela derivada com informaÁıes de controle de hierarquia (ìrankî, ìnÌvelî, ìidChefeî). A divis„o torna o modelo mais modular, uma vez que ele ajuda a definir o papel de cada tabela do modelo. Por outro lado, as consultas hier·rquicas passam a conter junÁıes extras para associar os registros divididos. Para fins did·ticos, neste artigo optamos pela soluÁ„o mais simples, e mantivemos tudo em uma ˙nica tabela. Em aplicaÁıes reais, caber· ao projetista escolher a opÁ„o que julgar mais conveniente.
| Funcion·rio | ||||
| id | Nome | idChefe | rank | NÌvel |
| 1 | Roger | Null | 1 | 1 |
| 2 | Felipe | 1 | 2 | 2 |
| 3 | Alfredo | 1 | 9 | 2 |
| 4 | Joao | 2 | 3 | 3 |
| 5 | Ricardo | 4 | 4 | 4 |
| 6 | Souza | 4 | 5 | 4 |
| 7 | Marcos | 6 | 6 | 5 |
| 8 | Julio | 6 | 7 | 5 |
| 9 | Tiago | 6 | 8 | 5 |
Com base nas informaÁıes da Tabela 3, pode-se usar o SQL da Listagem 6 para imprimir toda a ·rvore de funcion·rios.
//ObtÈm todos os dados
SELECT nome, nivel
FROM funcionario
ORDER BY rank Observe o uso do atributo rank. Ao ordenar a consulta por esse atributo, se garante que os registros sejam lidos na ordem com que devem ser inseridos na ·rvore (leitura em profundidade). No entanto, sua utilidade se restringe a poucos casos. Por exemplo, o atributo È ˙til se for necess·rio imprimir um relatÛrio com todos os nÌveis de profundidade (o que È um subcaso da consulta ìDesceî). Na maioria dos outros casos, seria necess·rio usar algumas das soluÁıes mostradas anteriormente.
J· o atributo nÌvel ajuda no controle da endentaÁ„o. Com base no valor desse atributo sabe-se qual a tabulaÁ„o que deve ser empregada na impress„o. Esse atributo representa uma forma de evitar que a endentaÁ„o tenha que ser calculada via linguagem de programaÁ„o, como foi demonstrado nas primeiras seÁıes do artigo. O problema passa a ser atualizar os valores do atributo quando os dados de hierarquia sofrerem modificaÁıes.
Na seÁ„o anterior foi mostrado um modelo onde um atributo (rank) armazena a posiÁ„o do elemento dentro da ·rvore, com base no caminhamento por profundidade. Nesta seÁ„o, veremos um modelo que segue esta mesma linha, mas que pode ser empregado em um n˙mero maior de problemas.
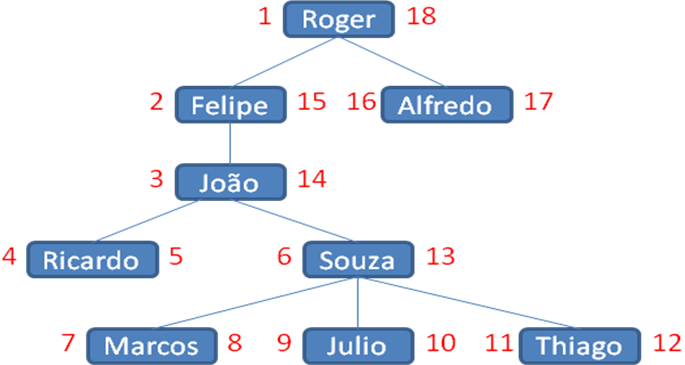
Em vez de um atributo, teremos dois atributos cujo propÛsito È armazenar o posicionamento do elemento. Vamos cham·-los de dir (direita) e esq (esquerda).
A Figura 2 mostra a ·rvore j· preenchida com esta nova informaÁ„o posicional. O preenchimento ocorre da seguinte forma: um valor È incrementado conforme se caminha pela ·rvore em profundidade. Quando se passa por um elemento na descida, o valor da esquerda È atualizado com o prÛximo incremento. Quando se passa por um elemento na subida, o valor da direita È atualizado.
A Tabela 4 mostra como ficaria o novo esquema de acordo com este modelo. Observe que o atributo ìidChefeî foi removido, uma vez que È possÌvel obter esta informaÁ„o atravÈs dos atributos ìesqî e ìdirî.
VocÍ deve estar se perguntando como calcular os valores no momento de alteraÁıes nesta tabela. Neste artigo n„o mostraremos como isso È feito, mas fique tranquilo. Existem scripts que atualizam corretamente estes atributos, quando um funcion·rio for incluÌdo, removido ou remanejado.
| Funcionario | ||||
| Id | Nome | Esq | Dir | Nivel |
| 1 | Roger | 1 | 18 | 1 |
| 2 | Felipe | 2 | 15 | 2 |
| 3 | Alfredo | 16 | 17 | 2 |
| 4 | Joao | 3 | 14 | 3 |
| 5 | Ricardo | 4 | 5 | 4 |
| 6 | Souza | 6 | 13 | 4 |
| 7 | Marcos | 7 | 8 | 5 |
| 8 | Julio | 9 | 10 | 5 |
| 9 | Tiago | 11 | 12 | 5 |
Observando a ·rvore da Figura 2, podemos perceber uma caracterÌstica importante. Se compararmos algum nÛ filho com qualquer um de seus nÛs pai, veremos que o atributo ìesqî do nÛ filho È sempre maior do que o atributo ìesqî do pai, e menor do que o atributo ìdirî do pai. Essa propriedade È garantida pela forma como os atributos s„o calculados, e se mostra particularmente ˙til para responder consultas nesse modelo.
Um exemplo de sua serventia fica evidente na Listagem 7. Para encontrar os subordinados de algum chefe, primeiro criamos duas inst‚ncias da tabela ìFuncionarioî, uma para representar o chefe e outra para buscar seus subordinados. O prÛximo passo È comparar os atributos ìesqî e ìdirî do chefe escolhido com o atributo ìesqî de cada um dos funcion·rios existentes. J· para buscar os chefes de algum funcion·rio, basta fazer a correlaÁ„o contr·ria, definindo o subordinado escolhido e comparando os atributos ìesqî e ìdirî usando a lÛgica inversa.
Como j· demonstrado em outro exemplo, o atributo ìnivelî È usado para controlar a altura na ·rvore. Esse atributo È ˙til para a endentaÁ„o dos resultados na consulta ìDesceî, pois ajuda a determinar quem È o chefe direto dos funcion·rios retornados. Na verdade, essa informaÁ„o È desnecess·ria. Existe uma correlaÁ„o entre os atributos ìesqî e ìdirî que responde essa pergunta. Deixaremos para vocÍ a miss„o de analisar os dados e resolver esse dilema.
Consulta 1 ñ Subordinados (Consulta Desce)
SELECT sub.id, sub.nome, sub.nivel
FROM funcionario base, funcionario sub
WHERE sub.esq <= base.dir AND sub.esq >= base.esq
AND base.id = :ID
ORDER BY sub.esq
Consulta 2 ñ Chefes (Consulta Sobe)
SELECT chefe.id, chefe.nome
FROM funcionario chefe, funcionario base
WHERE base.esq <= chefe.dir AND base.esq >= chefe.esq
AND base.id = :ID
ORDER BY chefe.esq As consultas da Listagem 7 obtÈm um Ûtimo desempenho se comparadas com as abordagens anteriores. Com apenas uma junÁ„o È possÌvel descobrir todos subordinados ou todos os chefes de alguÈm. No entanto, nem todas as tarefas possuem a mesma simplicidade. Na verdade, tarefas que deveriam ser simples exigem a adoÁ„o de scripts complexos. Por exemplo, a exclus„o de algum funcion·rio pode requerer que boa parte dos demais funcion·rios tenham seus atributos ìesqî e ìdirî atualizados. Uma forma de minimizar esse problema envolve o uso de valores mais ìespalhadosî para os atributos ìesqî e ìdirî. A escolha correta de valores para esses atributos pode evitar que alteraÁıes em algum nÛ da ·rvore tenham que ser propagados para nÛs vizinhos.
As operaÁıes de consulta tambÈm podem exigir uma boa dose de processamento em alguns casos especÌficos. Por exemplo, para descobrir o subordinado (ou o chefe) imediato de algum funcion·rio, s„o necess·rios trÍs autorrelacionamentos e uma subconsulta, sendo que o modelo adjacente puro resolve o problema com apenas um autorrelacionamento.
Para casos como esse, n„o existe fÛrmula m·gica que torne a consulta mais enxuta. Caso vocÍ decida que o Nested Set Model È ideal para as suas necessidades, o que pode ser feito È identificar subconsultas que s„o disparadas com muita frequÍncia e transform·-las em visıes. Isso n„o elimina a necessidade de subconsultas, mas agiliza seu processamento. No final das contas, seja qual for o modelo que vocÍ escolher, um bom tuning sempre ter· o seu valor.
Nesta seÁ„o mostraremos soluÁıes baseadas em modelos de enumeraÁ„o de caminho. Esses modelos se caracterizam pelo uso de um atributo especial, cuja funÁ„o È armazenar o caminho hier·rquico dos elementos. Dois submodelos se destacam: EnumeraÁ„o de VÈrtice (Node Enumeration) e EnumeraÁ„o de Arco (Edge Enumeration), sendo que a denominaÁ„o depende do conte˙do que È armazenado no atributo.
A Tabela 5 mostra um exemplo de EnumeraÁ„o de VÈrtice. O caminho atÈ um funcion·rio est· indicado no atributo ìcaminhoî. Esse atributo armazena o identificador do prÛprio funcion·rio concatenado com os identificadores de seus chefes. Usamos a barra (/) para separar os identificadores. Contudo, qualquer caractere pode ser usado, desde que se possa garantir que ele n„o ir· aparecer como parte de algum identificador. Assim como no modelo plano, o atributo nÌvel È usado unicamente para controle de endentaÁ„o. Quem achar melhor removÍ-lo, poder· fazer a endentaÁ„o via linguagem de programaÁ„o, inferindo o nÌvel pelo n˙mero de barras (/) presentes no atributo ìcaminhoî.
| Funcionario | ||||
| Id | Nome | idChefe | Caminho | NÌvel |
| 1 | Roger | Null | 1 | 1 |
| 2 | Felipe | 1 | 1/2 | 2 |
| 3 | Alfredo | 1 | 1/3 | 2 |
| 4 | Joao | 2 | 1/2/4 | 3 |
| 5 | Ricardo | 4 | 1/2/4/5 | 4 |
| 6 | Souza | 4 | 1/2/4/6 | 4 |
| 7 | Marcos | 6 | 1/2/4/6/7 | 5 |
| 8 | Julio | 6 | 1/2/4/6/8 | 5 |
| 9 | Tiago | 6 | 1/2/4/6/9 | 5 |
A Listagem 8 mostra as consultas que resolvem os problemas ìSobeî e ìDesceî. Para encontrar os subordinados, a ideia È procurar por registros cujo caminho contenha o caminho do registro base, o que no MySQL pode ser obtido atravÈs do operador POSITION. O operador POSITION tambÈm È utilizado para encontrar os chefes, porÈm de forma oposta. Desta vez a ideia È procurar por registros cuja sequÍncia esteja contida na sequÍncia do registro base. … importante ressaltar que as duas consultas demonstradas recorrem a funÁıes de string para chegar atÈ um resultado. Por esse motivo, para agilizar a busca, È interessante que seja criado algum Ìndice sobre o atributo ìcaminhoî.
Consulta 1 ñ Subordinados (Consulta Desce)
SELECT sub.nome, sub.id, sub.nivel
FROM funcionario base, funcionario sub
WHERE POSITION(base.caminho IN sub.caminho)
AND base.id = :ID
ORDER BY sub.caminho;
Consulta 2 ñ Chefes (Consulta Sobe)
SELECT chefe.nome, chefe.id
FROM funcionario base, funcionario chefe
WHERE POSITION(chefe.caminho IN base.caminho)
AND base.id = :ID
ORDER BY chefe.caminho; Na enumeraÁ„o de arco, o atributo ìcaminhoî recebe um conte˙do diferente. Em vez do identificador do prÛprio registro, usa-se um n˙mero de sequÍncia prÛprio que identifica a posiÁ„o de um elemento embaixo do seu pai. A Tabela 6 mostra como ficariam os dados se o caminho fosse gerado dessa forma.
| Funcionario | ||||
| id | nome | idChefe | Caminho | nÌvel |
| 1 | Roger | Null | 1 | 1 |
| 2 | Felipe | 1 | 1/1 | 2 |
| 3 | Alfredo | 1 | 1/2 | 2 |
| 4 | Joao | 2 | 1/1/1 | 3 |
| 5 | Ricardo | 4 | 1/1/1/1 | 4 |
| 6 | Souza | 4 | 1/1/1/2 | 4 |
| 7 | Marcos | 6 | 1/1/1/2/1 | 5 |
| 8 | Julio | 6 | 1/1/1/2/2 | 5 |
| 9 | Tiago | 6 | 1/1/1/2/3 | 5 |
Os mesmos algoritmos usados na EnumeraÁ„o de VÈrtice podem ser usados na EnumeraÁ„o de Arco, sendo que os resultados s„o bastante parecidos. A diferenÁa pode ocorrer na ordem com que os elementos irm„os s„o exibidos. A ordem È definida pelo atributo caminho. Na EnumeraÁ„o de VÈrtice, este atributo possui identificadores dos registros, o que torna difÌcil controlar a sequÍncia em que os registros irm„os s„o retornados.
J· com a EnumeraÁ„o de Arco, o caminho È composto por um n˙mero sequencial, cujo valor È determinado pela lÛgica de inserÁ„o que o projetista elaborou. Assim, caso se deseje preservar uma determinada ordem entre irm„os, a EnumeraÁ„o de Arco È mais adequada. Apenas esteja ciente de que ser· necess·rio um trabalho extra para que os n˙meros sequenciais sejam gerados de acordo.
TambÈm È importante observar que existe um limite para o n˙mero de nÌveis que esses modelos suportam, e esse limite est· relacionado com o tamanho do atributo ìCaminhoî. Por exemplo, suponha que esse atributo seja um char de 255 posiÁıes, e que os identificadores possam ter no m·ximo cinco dÌgitos cada (m·ximo 99999). Nessas circunst‚ncias, s„o suportados atÈ 51 nÌveis, sem que o tamanho do atributo estoure. Dependendo dos requisitos do projeto, tal quantidade de nÌveis pode variar entre adequada, razo·vel e atÈ mesmo arriscada. Antes de tomar uma decis„o, verifique quais s„o as reais necessidades, tanto imediatas quanto de longo prazo. Afinal, ainda que se possa adaptar o modelo para suprir nÌveis excedentes (por exemplo, atravÈs da adiÁ„o de um novo atributo de caminho), este trabalho acaba gerando um estresse que poderia ser evitado.
De certa forma, a abordagem apresentada nesta seÁ„o tambÈm se baseia na informaÁ„o de caminho. A diferenÁa fundamental È que, em vez de um ˙nico atributo, m˙ltiplos atributos s„o necess·rios, um para cada nÌvel da ·rvore.
A Tabela 7 mostra os atributos necess·rios para a nossa ·rvore de exemplo, juntamente com os valores que foram atribuÌdos para eles. Se compararmos estas informaÁıes com o caminho armazenado na Tabela 6, veremos que a lÛgica deste modelo se aproxima bastante da lÛgica empregada na EnumeraÁ„o de Arco.
O n˙mero de nÌveis preenchidos (diferentes de zero) mostra a altura do funcion·rio dentro da hierarquia. Por exemplo, o Diretor Executivo (grau m·ximo na instituiÁ„o) est· no topo, pois apenas um nÌvel est· preenchido. Os subordinados recebem os mesmos valores atribuÌdos para seus respectivos chefes, com exceÁ„o do atributo que indica o seu prÛprio nÌvel. Este recebe um n˙mero sequencial, que indica a ordem do subordinado embaixo do seu chefe.
| Funcionario | |||||||
| id | Nome | nivel1 | nivel2 | nivel3 | nivel4 | nivel5 | nÌvel |
| 1 | Roger | 1 | 0 | 0 | 0 | 0 | 1 |
| 2 | Felipe | 1 | 1 | 0 | 0 | 0 | 2 |
| 3 | Alfredo | 1 | 2 | 0 | 0 | 0 | 2 |
| 4 | Joao | 1 | 1 | 1 | 0 | 0 | 3 |
| 5 | Ricardo | 1 | 1 | 1 | 1 | 0 | 4 |
| 6 | Souza | 1 | 1 | 1 | 2 | 0 | 4 |
| 7 | Marcos | 1 | 1 | 1 | 2 | 1 | 5 |
| 8 | Julio | 1 | 1 | 1 | 2 | 2 | 5 |
| 9 | Tiago | 1 | 1 | 1 | 2 | 3 | 5 |
A Listagem 9 mostra os comandos usados para responder as duas consultas propostas. Para popular espaÁo, usamos apelidos curtos para os funcion·rios base (b), chefe (c) e subordinado (s).
O comando SQL usado para encontrar os subordinados È bastante simples. A relaÁ„o entre o funcion·rio base e seus subordinados È alcanÁada atravÈs de uma comparaÁ„o dos seus nÌveis. … importante observar que a comparaÁ„o precisa ser feita pelo atributo correto, que È aquele que indica a altura do funcion·rio base. No caso da Jo„o, trata-se do atributo ìnivel3î.
Para que a impress„o do relatÛrio respeite o caminhamento em profundidade, È preciso ordenar os registros pelos nÌveis, conforme indicado no comando SQL. Os nÌveis tambÈm podem ser usados para controle de endentaÁ„o. Quanto mais nÌveis diferentes de zero, maior ser· a tabulaÁ„o dada na impress„o.
Para encontrar os chefes de um funcion·rio, aplica-se a lÛgica inversa da usada para encontrar os subordinados, como em outros casos mostrados no artigo. Para orientar a comparaÁ„o de nÌveis, verifica-se o atributo ìnivelî do funcion·rio ìchefeî em vez do atributo ìnivelî do funcion·rio ìbaseî.
Como se pode ver, o atributo ìnivelî tem um papel importantÌssimo. Com ele, È possÌvel criar consultas genÈricas compostas por critÈrios condicionais (CASE-WHEN). Sem ele, os critÈrios de comparaÁ„o teriam que ser ajustados dependendo da altura do funcion·rio que se deseja pesquisar, o que tornaria a consulta engessada. A soluÁ„o que apresentamos aqui È na verdade uma adaptaÁ„o do modelo Chandler, visto que o modelo original n„o faz menÁ„o ao uso desse atributo.
Consulta 1 ñ Subordinados (Consulta Desce)
SELECT s.id, s.nome, s.nivel
FROM funcionario b, funcionario s
WHERE b.id = :ID AND
CASE
WHEN b.nivel= 1 THEN b.nivel1 = s.nivel1
WHEN b.nivel= 2 THEN b.nivel2 = s.nivel2
WHEN b.nivel= 3 THEN b.nivel3 = s.nivel3
WHEN b.nivel= 4 THEN b.nivel4 = s.nivel4
WHEN b.nivel= 5 THEN b.nivel5 = s.nivel5
END
ORDER BY c.nivel1, c.nivel2, c.nivel3, c.nivel4, c.nivel5;
Consulta 2 ñ Chefes (Consulta Sobe)
SELECT c.id, c.nome, c.nivel
FROM funcionario b, funcionario c
WHERE b.id = :ID AND
CASE
WHEN c.nivel = 1 THEN b.nivel1 = c.nivel1
WHEN c.nivel = 2 THEN b.nivel2 = c.nivel2
WHEN c.nivel = 3 THEN b.nivel3 = c.nivel3
WHEN c.nivel = 4 THEN b.nivel4 = c.nivel4
WHEN c.nivel = 5 THEN b.nivel5 = c.nivel5
END
ORDER BY c.nivel1, c.nivel2, c.nivel3, c.nivel4, c.nivel5; J· vimos que o MÈtodo Chandler se aproxima bastante do modelo de EnumeraÁ„o de Arco, ao menos conceitualmente. Isso nos leva ý conclus„o lÛgica de que esse mÈtodo pode tambÈm ser aplicado nos moldes da EnumeraÁ„o por VÈrtice. A Tabela 8 mostra o Modelo de Chandler adaptado (mais uma vez), usando identificadores dos registros como os valores dos nÌveis, em vez de n˙meros sequenciais.
| Funcionario | |||||||
| id | Nome | nivel1 | nivel2 | nivel3 | nivel4 | nivel5 | nivel |
| 1 | Roger | 1 | 0 | 0 | 0 | 0 | 1 |
| 2 | Felipe | 1 | 2 | 0 | 0 | 0 | 2 |
| 3 | Alfredo | 1 | 3 | 0 | 0 | 0 | 2 |
| 4 | Joao | 1 | 2 | 4 | 0 | 0 | 3 |
| 5 | Ricardo | 1 | 2 | 4 | 5 | 0 | 4 |
| 6 | Souza | 1 | 2 | 4 | 6 | 0 | 4 |
| 7 | Marcos | 1 | 2 | 4 | 6 | 7 | 5 |
| 8 | Julio | 1 | 2 | 4 | 6 | 8 | 5 |
| 9 | Tiago | 1 | 2 | 4 | 6 | 9 | 5 |
Para imprimir uma sub·rvore, ou listar os chefes, o processo È exatamente igual ao usado na Listagem 9. Nenhuma linha precisaria ser modificada. O benefÌcio desse novo padr„o de representaÁ„o de nÌveis se torna aparente em outros tipos de consulta. Por exemplo, o chefe direto de alguÈm pode ser descoberto com uma consulta simples. Outro exemplo bacana envolve descobrir o chefe que est· a uma certa altura de alguÈm, sendo a altura definida por um critÈrio de seleÁ„o. A resoluÁ„o desse problema fica como exercÌcio para vocÍ.
Para quem estiver se perguntando, o nome deste mÈtodo È dedicado a pessoa que garantiu os direitos de propriedade intelectual da ideia. Chega a surpreender o fato de alguÈm ter conseguido patentear o modelo, pois se trata de uma soluÁ„o que sempre foi de conhecimento p˙blico (ou pelo menos aparentava ser). De qualquer forma, o MÈtodo Chandler foi concebido como uma forma de evitar as operaÁıes com strings necess·rias com os modelos de EnumeraÁ„o de Caminho. No entanto, ele usualmente requer o uso de consultas pouco intuitivas, como acabamos de ver nos exemplos. AlÈm disso, trata-se de uma soluÁ„o um tanto amarrada. Afinal, alÈm da dificuldade em montar consultas genÈricas (que conseguimos vencer com o uso de um atributo extra), È preciso saber de antem„o quantos nÌveis devem ser suportados. Se a ·rvore crescer alÈm do esperado, novos atributos precisariam ser adicionados, e estas mudanÁas de esquema quase nunca s„o vistas com bons olhos.
De certo modo, linguagens de programaÁ„o s„o mais propÌcias para realizar determinadas operaÁıes, especialmente sobre modelos hier·rquicos. Isso ocorre porque as linguagens normalmente usadas s„o procedurais. Isto È, cabe ao desenvolvedor especificar exatamente o que deve ser feito, usando pequenos blocos de construÁ„o. Isso lhe d· uma flexibilidade tremenda, e abre a possibilidade para que algoritmos dos mais complexos possam ser implementados.
Com SQL È diferente. Trata-se de uma linguagem declarativa, onde o desenvolvedor especifica o que deve ser feito, e n„o como. Linguagens declarativas s„o naturalmente mais limitadas, servindo para um tipo especÌfico de operaÁ„o. No caso do SQL, as operaÁıes ocorrem sobre relaÁıes. Esse È o seu forte. … por isso que, ao modelar hierarquias como relaÁıes È esperado encontrar dificuldades em especificar alguns tipos de consulta.
Uma possibilidade ainda n„o mencionada envolve utilizar linguagens de consulta voltadas a dados hier·rquicos, como XPath/XQuery. Xquery È uma linguagem declarativa, assim como SQL. A diferenÁa È que ela foi projetada para modelos hier·rquicos, sendo baseada em caminhos de acesso e uma sÈrie de recursos com os quais j· estamos acostumados, como caracteres coringa e filtros. Ou seja, para consultas hier·rquicas, essa linguagem se torna naturalmente mais expressiva do que a linguagem SQL.
Deixamos a Listagem 10 como exemplo de consulta que pode ser criada por meio desse paradigma. A consulta lÍ um documento XML contendo dados de funcion·rios e retorna um documento XML contendo a ·rvore de subordinaÁ„o desses funcion·rios.
Consulta 1 ñ Subordinados (Desce)
declare function acme:exibeSub($func) {
<Func nome="{$func/nome}">
<Subordinados>
{
for $f in //Funcionario[idChefe = $func/id]
return acme:exibeSub($f)
}
</Subordinados>
</Func>
};
//exibe os subordinados do diretor executivo
acme:exibeSub (//Funcionario[empty(idChefe/text())])Como mencionado, a consulta XQuery da Listagem 10 requer um documento XML como entrada. Se estamos trabalhando com uma base relacional, isso significa que terÌamos que primeiro converter os dados para um formato compatÌvel com XQuery. Por exemplo, poderÌamos carregar os dados para uma ·rvore DOM e processar os relacionamentos de subordinaÁ„o a partir daÌ. Essa soluÁ„o lembra a que foi explicada na seÁ„o ìCarga Total para a MemÛriaî, sÛ que nesse caso usamos SQL para carregar os dados e XQuery para navegar por eles.
Em vez dessa soluÁ„o hÌbrida, onde duas linguagens de consulta s„o necess·rias, tambÈm se poderiam utilizar bancos de dados XML nativos. Nesses bancos de dados, toda informaÁ„o È modelada em formato XML. Naturalmente, a linguagem de consulta oficial È baseada em XPath e XQuery. No entanto, tais bancos de dados n„o s„o muito populares, e seu uso È mais voltado para certos tipos especÌficos de aplicaÁ„o. Por exemplo, quando a finalidade mais comum dos dados È o transporte para outros sistemas, e esse transporte È realizado via XML, talvez seja mais indicado que esses dados j· estejam armazenados em XML. Quando a finalidade mais comum È o consumo direto por aplicaÁıes, o apelo deste tipo de banco diminui bastante.
Isso vale para os bancos de dados orientados a objetos, ou objeto-relacionais. Seu uso È mais aconselhado para a manipulaÁ„o de dados complexos, como aqueles envolvidos em aplicaÁıes de biologia molecular e manipulaÁ„o de objetos espaciais. AlÈm do mais, o processamento de consultas hier·rquicas n„o È exatamente o forte desse paradigma. Por um lado, o acesso navegacional atravÈs de ponteiros simplifica e agiliza o processamento de muitos tipos de consulta. No entanto, a capacidade de navegar pelos objetos acaba n„o ajudando muito quando os dados est„o dispostos em uma hierarquia de muitos nÌveis. Nesses casos, um banco de dados relacional apoiado por uma boa modelagem pode ser a melhor saÌda.
Outra possibilidade envolve abandonar de vez os bancos relacionais e partir para SGBDs hier·rquicos, como o IMS da IBM (ler Nota do DevMan 1). Pelo nome, podemos supor que bancos hier·rquicos s„o a melhor pedida para processar consultas hier·rquicas. Ser·? … importante n„o fazer julgamentos precipitados. Bancos hier·rquicos s„o conhecidos pela rapidez com que os dados s„o acessados. No entanto, seu uso È um tanto complexo, principalmente para os mais jovens, acostumados com as linguagens de programaÁ„o de quarta geraÁ„o.
Para exemplificar, no caso do IMS, o acesso aos dados poderia ocorrer atravÈs de uma aplicaÁ„o escrita em COBOL que realizasse chamadas ao IMS via DL/I. Isso significa criar um programa altamente estruturado onde o acesso aos dados È realizado atravÈs de ·reas mapeadas chamadas de blocos de controle. Depois disso tudo, talvez ainda seja necess·rio encapsular a aplicaÁ„o COBOL em um adaptador que aceite comandos SQL, para que uma aplicaÁ„o escrita em Java consiga acessar os dados. Isso sem falar que o IMS deve ser executado em plataformas do tipo mainframe.
Ou seja, trata-se de uma soluÁ„o complexa e acima de tudo cara, tanto para a aquisiÁ„o dos produtos/plataformas necess·rios quanto para a criaÁ„o e manutenÁ„o das aplicaÁıes. AlÈm do mais, cabe ressaltar que os SGBDs hier·rquicos s„o Ûtimos para consultas simples. J· consultas complexas, como aquelas em que È necess·rio realizar o cruzamento entre diversos tipos de dados, s„o muitas vezes mais bem atendidas por bancos de dados relacionais.
Neste artigo descrevemos diversos mÈtodos que podem ser usados para o armazenamento e consulta de dados hier·rquicos. Para exemplificar, apresentamos soluÁıes para duas consultas bastante comuns, uma que descobre os chefes de algum funcion·rio e outro que descobre quem s„o os seus subordinados. O material apresentado tem a intenÁ„o de servir de base para a criaÁ„o de soluÁıes que necessitem de dados hier·rquicos. Deixaremos para vocÍ o trabalho de descobrir como os mÈtodos podem ser usados para responder outros tipos de consulta, e o que deve ser feito para facilitar o armazenamento das informaÁıes.
Com um card·pio t„o variado de opÁıes, a pergunta que deve ser respondida È qual a melhor soluÁ„o para o processamento de consultas hier·rquicas. Para respondÍ-la, È imperativo que outras perguntas sejam respondidas antes: Que tipos de consulta hier·rquica s„o necess·rios? Qual a frequÍncia com que as consultas ser„o disparadas? Qual o volume de dados que ser· acessado? Quantas transaÁıes simult‚neas dever„o ser suportadas? E por ˙ltimo, mas n„o menos importante, quanto sua empresa est· disposta a pagar por isso?
Pense bem antes de tomar a decis„o. Afinal, escolhas bem embasadas s„o fundamentais na carreira de alguÈm. … importante lembrar que, alÈm dos mÈtodos demonstrados, pessoas tambÈm caminham pelo organograma da empresa. Por isso faÁa as escolhas certas, e o prÛximo relatÛrio hier·rquico poder· estar de cara nova. Vai que seu nome apareÁa alguns nÌveis acima?
Livro ìJoe Celko"s Trees and Hierarchies in SQL for Smartiesî, escrito por Joe Celko (2004).


Utilizamos cookies para fornecer uma melhor experiÍncia para nossos usu·rios, consulte nossa polÌtica de privacidade.