De uma forma simples, data warehouses e data marts existem para responder questűes que as pessoas tÍm sobre os negůcios. S„o uma base de informaÁűes consolidadas, integrada e n„o volŠtil, para apoiar os processos de tomada de decisűes estratťgicas, tŠticas e tambťm operacionais de organizaÁűes. Esta funÁ„o contrasta fortemente com o propůsito dos sistemas transacionais (sistemas que apoiam a operaÁ„o da empresa) e requer que o desenho ou o modelo de dados do data warehouse siga princŪpios completamente diferentes. VŠrios aspectos considerados de extrema import‚ncia na modelagem de sistemas transacionais como a aplicaÁ„o de rŪgidas regras de normalizaÁ„o s„o, muitas vezes, deixados de lado ao se modelar um data warehouse ou data mart.
Este artigo tem por objetivo mostrar os detalhes que envolvem uma das tťcnicas utilizadas para a modelagem dos dados em data warehouses e tambťm em data marts, a modelagem dimensional. Essa tťcnica segue a chamada escola Ralph Kimball, introdutor do conceito do star schema. Na segunda parte deste artigo, a ser publicada em ediÁ„o futura da SQL Magazine, apresentaremos detalhadamente o ďstar schemaĒ e sua variaÁ„o normalizada: o snowflake schema. Na terceira parte, abordaremos outra tťcnica utilizada para modelagem apenas de data warehouses, a modelagem relacional diversificado, que segue a chamada escola Bill Inmon, considerado o ďpaiĒ do conceito de data warehouse.
As tťcnicas de modelagem dimensional de um data warehouse, se aplicadas corretamente, garantem que o desenho do data warehouse reflita a forma de pensar dos analistas de negůcio e gerentes da empresa e possa ser usado eficazmente para atender os seus requisitos de negůcio. AliŠs, este ť o princŪpio bŠsico da modelagem de um data warehouse: discutir diretamente com o usuŠrio final sua vis„o do modelo de negůcios e fazer com que esta vis„o seja refletida na base de informaÁűes.
Saiba mais: Curso de Python
O data warehouse deve ser desenhado para transpor os limites de cada um dos sistemas transacionais. Ele ť construŪdo para responder questűes que n„o est„o limitadas ŗs transaÁűes ou aos sistemas individuais, apresentando, desta forma, uma vis„o integrada e completa dos negůcios. Uma das tťcnicas utilizadas para se obter um modelo para o data warehouse que identifique e represente as informaÁűes importantes para o modelo de negůcios ť a modelagem dimensional ou multidimensional. Quando bem definido, o modelo dimensional pode ser uma ajuda de valor incalculŠvel para as Šreas de negůcio, apoiando e otimizando todo o processo de tomada de decisűes. O modelo dimensional representa:
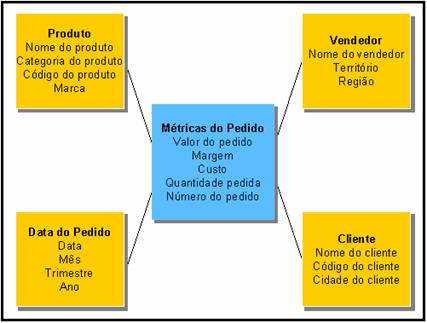
A Figura 1 apresenta um modelo dimensional simplificado para um processo de pedidos. As mťtricas definidas neste modelo est„o no quadro central e as dimensűes est„o representadas nos quadros ao redor das mťtricas. As mťtricas s„o sumariadas (agregadas) ou detalhadas de acordo com o interesse da anŠlise a ser feita sobre os dados. Este modelo ť fŠcil de ser entendido por uma pessoa da Šrea de negůcios, jŠ que ďas coisas que eu avalioĒ est„o na parte central do diagrama e ďas formas de se olhar para elasĒ est„o nos quadros em volta.
Fica fŠcil perceber que estes quadros facilmente se transformar„o em tabelas (com alguns atributos adicionais) utilizadas para armazenar toda a informaÁ„o necessŠria. Um modelo como este n„o muda muito ao ser implementado em um banco de dados relacional (RDBMS). Cada quadro com os atributos de uma dimens„o se torna uma tabela, chamada de tabela dimens„o, e o quadro central se torna uma grande tabela, chamada tabela fato, que contťm, por vezes, milhűes ou bilhűes de linhas.
Porťm, os modelos dimensionais nem sempre s„o implementados em bases de dados relacionais. Existem no mercado bancos de dados multidimensionais (MDDBS), que armazenam informaÁűes em um formato diferente, frequentemente chamado de cubos. Os cubos s„o construŪdos de tal forma que, cada combinaÁ„o de atributos das dimensűes com uma mťtrica, ť calculado antecipadamente ou ť calculado muito rapidamente.
Entretanto, a natureza de um banco de dados multidimensional tambťm significa que n„o ť possŪvel manipular volumes de dados extremamente grandes jŠ que uma transaÁ„o de anŠlise dos dados, com uma ferramenta OLAP (Online Analytical Processing), que envolva um grande volume de dados vai consumir grande quantidade de memůria ou simplesmente n„o se efetuarŠ. Alťm disso, o nķmero de atributos dimensionais armazenados em um cubo pode impactar o tempo de carga, o tamanho e o desempenho do cubo.
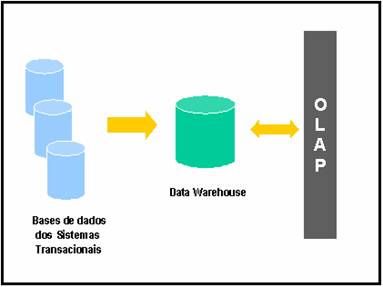
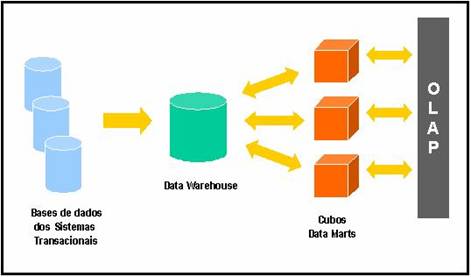
Uma das alternativas para solucionar estes problemas pode ser a implementaÁ„o do modelo dimensional em um banco de dados relacional e, apůs isto, utilizŠ-lo como fonte para carga posterior de subconjuntos de dados nos cubos. Esta abordagem ť muito utilizada em empresas que querem executar anŠlises em subconjuntos de um grande conjunto de dados armazenados em um data warehouse. Quando esta abordagem ť implementada, o data warehouse como um todo fica armazenado no banco de dados relacional, enquanto que partes ou segmentos deste data warehouse s„o copiadas e armazenadas em cubos, que s„o chamados de data marts. Estas arquiteturas bŠsicas de implementaÁ„o est„o representadas nas Figuras 2 e 3.
Nesta parte do artigo ainda n„o iremos nos preocupar com as tecnologias de implementaÁ„o fŪsica dos modelos de dados, mas apenas analisaremos as etapas de modelagem necessŠrias para atender qualquer tipo de implementaÁ„o, seja em um banco relacional ou multidimensional.
O processo de modelagem dimensional ť composto por algumas etapas cujo objetivo ť levantar e representar as necessidades de anŠlise e de informaÁűes dos usuŠrios de determinada Šrea de negůcios. A Tabela 1 apresenta uma vis„o geral deste processo. Nas seÁűes seguintes discutiremos cada uma destas etapas.
| Passo | Perguntas a serem feitas para o usuŠrio | Elementos a serem definidos no modelo |
| 1 | O que estamos avaliando? | Fatos ou mťtricas (sempre um valor numťrico). |
| 2 | Como ser„o avaliados ou analisados? | Dimensűes de negůcios relacionadas ŗs mťtricas. |
| 3 | Qual o nŪvel mais baixo de detalhe das informaÁűes? | Granularidade das informaÁűes em cada dimens„o. |
| 4 | Como se espera agrupar ou sumariar as informaÁűes? | Hierarquia de agrupamento das informaÁűes em cada dimens„o. |
Este passo vai definir o que queremos avaliar no data warehouse/data mart, ou seja, os fatos. Estes fatos s„o os nķmeros que ser„o medidos e analisados atravťs das diferentes dimensűes de negůcios (que ser„o definidas no passo 2). A seleÁ„o dos fatos que ir„o compor o modelo do data warehouse ť relativamente simples. Uma vez definida a Šrea de negůcios que estamos modelando, a lista de fatos a serem utilizados responde ŗ quest„o: ďO que estamos avaliando?Ē. Estes fatos s„o os nķmeros com os quais o usuŠrio lida. Para exemplificar todo o processo de modelagem utilizaremos um modelo para a Šrea comercial. Nosso usuŠrio pode ser um gerente comercial de uma rede de lojas que tem por necessidade avaliar, por exemplo, a quantidade de itens vendidos, o valor de venda, o custo de cada um dos itens e a margem produzida. Note que estes valores devem ser trazidos dos sistemas transacionais onde ť mantida cada uma destas mťtricas. Nem sempre as mťtricas s„o originadas em um sů sistema. Por esta raz„o, ť necessŠrio bastante cuidado ao se definir os processos que far„o extraÁ„o, transformaÁ„o e carga (ETL) destes valores, dos sistemas transacionais para o data warehouse.
Em nosso exemplo da Šrea comercial, o gestor quer analisar tambťm, alťm das mťtricas realizadas, os valores que haviam sido planejados (devem ser trazidos provavelmente de um sistema de planejamento e orÁamento), bem como valores calculados do planejado sobre o realizado.
Algumas das mťtricas poder„o ser calculadas durante o processo de extraÁ„o, transformaÁ„o e carga e ser„o armazenadas no data warehouse jŠ calculadas ou ent„o poder„o ser calculadas diretamente, em tempo de consulta, pelas ferramentas OLAP. Nesta etapa da modelagem, todas as mťtricas (calculadas ou trazidas da base transacional) ser„o tratadas da mesma forma.
Assim, em nosso exemplo, as mťtricas ou fatos que este usuŠrio necessita avaliar s„o:
Apůs termos definido as mťtricas que ser„o armazenadas no data warehouse/data mart, passamos a definir cada uma das dimensűes relacionadas ŗs mťtricas. Nesta etapa vamos perguntar ao usuŠrio ďComo as mťtricas ser„o analisadas?Ē, ou seja, sob quais dimensűes de negůcio avaliaremos os fatos? Por exemplo, cada uma das mťtricas precisa ser analisada ao longo do tempo. Isto significa analisar a quantidade de itens vendidos por mÍs, ou talvez atť mesmo por dia. Poderemos tambťm comparar perŪodos de vendas analisando, por exemplo, a quantidade de itens vendidos no ķltimo mÍs em comparaÁ„o com o mesmo mÍs no ano anterior. Atravťs de sugestűes e exemplos, vamos dando ďdicasĒ para que o usuŠrio entenda o que estamos querendo identificar, ao mesmo tempo que ele vai nos informando suas necessidades de anŠlise das informaÁűes.
Em nosso exemplo, as dimensűes de negůcio a serem implementadas (conforme necessidades especificadas pelo usuŠrio) ser„o:
Agora temos que verificar se cada mťtrica se relaciona com todas as dimensűes definidas, jŠ que cada conjunto de mťtricas deve ser analisado atravťs do mesmo conjunto de dimensűes. Para isto, podemos perguntar se cada mťtrica pode ser analisado ao longo de cada dimens„o, por exemplo: ďFaz sentido analisar o valor das vendas por produto? E por loja? E ao longo do tempo?Ē.
Uma vez definidas as dimensűes de negůcio atravťs das quais as mťtricas ser„o analisadas, ť importante saber qual o nŪvel de detalhe, ou granularidade, mais baixo que serŠ avaliado. Em nosso exemplo, podemos comeÁar pela dimens„o Tempo. Podemos questionar o usuŠrio da seguinte forma: ďQual o nŪvel de detalhe desejado? Faz sentido avaliar a mťtrica quantidade vendida por dia?Ē. Assim, para cada uma das mťtricas definidas, vamos identificar qual o nŪvel mais baixo de detalhe que serŠ armazenado no data warehouse. Se, para a dimens„o Tempo o nŪvel mais baixo de detalhe for dia, ent„o todas as mťtricas dever„o ser obtidas com valores por dia. Para o nosso exemplo consideraremos o nŪvel de granularidade mais baixo como sendo:
Assim, os processos de ETL que ir„o trazer as informaÁűes dos sistemas transacionais para o data warehouse devem fazÍ-lo no nŪvel mais baixo de granularidade especificado para cada uma das dimensűes. Desta forma, para a mťtrica valor da venda devemos trazer o valor de venda realizado para cada item de produto, em cada dia e em cada loja. A Tabela 2 mostra um subconjunto das informaÁűes necessŠrias para se preparar o data warehouse do nosso exemplo.
| Tempo (Dia) | Produto (Item) | Geografia (Loja) | Valor da venda (R$) | Quantidade de itens | PreÁo mťdio de venda (R$) | ... |
| 05/01/2004 | LŠpis nį 2 Ė Faver Carel | Loja 04 | 78,00 | 65 | 1,20 | ... |
| 05/01/2004 | LŠpis nį 2 Ė Faver Carel | Loja 06 | 150,00 | 125 | 1,20 | ... |
| 05/01/2004 | Caneta Clic azul - fina | Loja 04 | 117,60 | 84 | 1,40 | ... |
| 05/01/2004 | Caneta Clic vermelha - fina | Loja 04 | 39,20 | 28 | 1,40 | ... |
| ... | ... | ... | ... | ... | ... | ... |
| 23/03/2004 | Caneta Clic azul - fina | Loja 06 | 123,00 | 82 | 1,50 | ... |
| 23/03/2004 | Bloco recibo Jordel | Loja 12 | 132,50 | 53 | 2,50 | ... |
| ... | ... | ... | ... | ... | ... | ... |
Note que apesar do usuŠrio desejar um determinado nŪvel de granularidade, ť importante saber se a informaÁ„o estŠ disponŪvel neste nŪvel de detalhe nos sistemas transacionais. Por exemplo, de nada adianta o usuŠrio querer analisar as informaÁűes de vendas diŠrias se os sistemas transacionais n„o tÍm estas informaÁűes disponŪveis.
Como mostrado na Tabela 2, serŠ preparada uma linha para cada loja, em cada dia com as vendas de cada item de produto e os valores somados ou calculados para cada mťtrica. Por exemplo, na primeira linha temos, para o dia 5 de janeiro de 2004, do produto LŠpis nį 2 Faver Carel, na Loja 04, o valor total das vendas, a quantidade total de itens vendidos e assim sucessivamente para as outras mťtricas.
Os dados estar„o armazenados no data warehouse no nŪvel de detalhe estabelecido, porťm, normalmente o usuŠrio desejarŠ analisar agrupamentos destas informaÁűes como: ďQual o total de canetas vendidas, nas lojas do estado de S„o Paulo, no ķltimo semestre?Ē. Esta pergunta jŠ indica que deveremos nos preocupar com o agrupamento, ou sumarizaÁ„o das informaÁűes armazenadas no data warehouse. Para isto, ť necessŠrio ent„o definir quais as possibilidades de agrupamento das informaÁűes que o usuŠrio deseja, especificando a hierarquia destes agrupamentos em cada uma das dimensűes de negůcio.
Uma hierarquia que parece natural em nosso exemplo ť a que se apresenta na dimens„o tempo. Meses normalmente s„o agrupados em bimestres ou trimestres, que por sua vez s„o agrupados em semestres e em anos. Apesar de ser natural, ť importante saber o que o usuŠrio necessita jŠ que alguns modelos de negůcio requerem agrupamentos temporais diferentes e mesmo para uma hierarquia t„o natural quanto esta, ainda assim ť necessŠrio modelar o data warehouse para que seja possŪvel efetuar este tipo de agrupamento. Em nosso exemplo, vamos considerar as seguintes hierarquias:
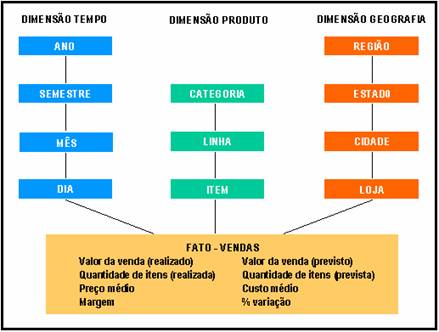
Com estas informaÁűes em m„os, podemos iniciar a modelagem do data warehouse/data mart, partindo de uma vis„o lůgica baseada nas informaÁűes obtidas com os usuŠrios. Uma forma de representaÁ„o bastante simples, porťm muito eficaz ť a apresentada na Figura 4. Com este diagrama, ť possŪvel discutir diretamente com o usuŠrio e validar as informaÁűes obtidas.
Atť o momento ainda n„o iniciamos realmente a modelagem da base de dados que irŠ conter o data warehouse, porťm, todas as atividades realizadas atť agora s„o de extrema import‚ncia para entender o modelo de negůcios que iremos representar. … importante envolver os usuŠrios finais na validaÁ„o da vis„o que obtivemos atť este ponto pois, como em todos os tipos de sistemas, qualquer erro pode ser corrigido neste momento ainda com um custo muito baixo.
Na segunda parte deste artigo iremos discutir os dois esquemas mais utilizados na modelagem dimensional de data warehouses e data marts: o Star Schema e o Snowflake Schema com suas principais variaÁűes, dando continuidade ao exemplo aqui analisado.
 :
:
Utilizamos cookies para fornecer uma melhor experiÍncia para nossos usuŠrios, consulte nossa polŪtica de privacidade.