O tema analisado neste artigo é fundamental para desenvolvedores que buscam formas de investirem seu tempo e suas habilidades em processos prioritários para as atividades de desenvolvimento em vez de terem que realizar integralmente a configuraçăo de ambientes, como servidores, redes, load balancers e bancos de dados. Além disso, o artigo é orientado aos desenvolvedores que precisam garantir alta disponibilidade ŕs suas aplicaçőes em um ambiente auto escalável e com alta demanda por flexibilidade.
Nos últimos anos temos visto a evoluçăo do conceito de Cloud Computing e como esta definiçăo expande cada vez mais suas fronteiras. Hoje já temos uma série de subclassificaçőes que, individualmente, se materializam em forma de serviços, por exemplo: IaaS – Infrastructure as a Service, PaaS – Platform as a Service, SaaS – Software as a Service, STaaS – Storage as a Service, NaaS – Network as a Service, entre outros.
Uma das características destes serviços é a elasticidade, ou seja, a alocaçăo dinâmica de recursos computacionais baseada na demanda da aplicaçăo. Com a elasticidade, vocę consegue responder prontamente ao aumento súbito de requisiçőes, alocando novos servidores automaticamente. Além disso, diminui drasticamente o risco de indisponibilidade por falha e mantém o tempo de resposta da aplicaçăo mais estável.
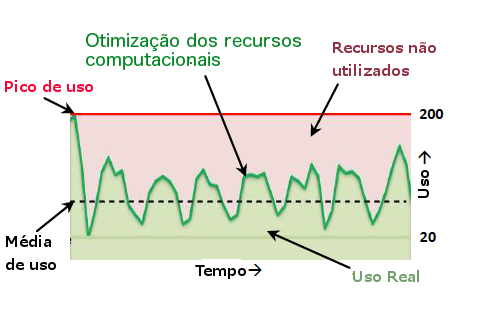
Outro benefício da elasticidade, é que vocę năo precisa investir antecipadamente em uma infraestrutura que será necessária apenas em alguns momentos de pico. O gráfico da Figura 1 mostra uma comparaçăo entre o uso otimizado de recursos versus o modelo tradicional de investimentos antecipados.
Os desenvolvedores também foram beneficiados com este novo modelo. As ofertas de plataformas para implantaçăo de sistemas (PaaS), automatizadas e parametrizadas, dăo flexibilidade e velocidade na criaçăo dos ambientes usuais de projetos, como os de testes, homologaçăo ou produçăo. A grande vantagem é que os desenvolvedores năo precisam mais instalar sistemas operacionais, configurar servidores, redes, load balancers, ou seja, cuidar de todo o ambiente que envolve a aplicaçăo. Como a plataforma está totalmente disponível em forma de serviço, o único foco do time de desenvolvimento será a própria aplicaçăo, o que reduz o custo do projeto, uma vez que toda a operaçăo de TI que estava envolvida na implantaçăo, alocaçăo e gestăo de ambientes, agora é fornecida como serviço.
Neste artigo vamos focar na oferta de plataforma da Amazon Web Services (AWS), chamada de Elastic Beanstalk. Este serviço năo exige nenhum uso de API específica ou qualquer outra personalizaçăo da sua aplicaçăo, o que facilita a adoçăo por aplicaçőes já existentes. Para demonstrar seus recursos criaremos uma aplicaçăo Web e a tornaremos totalmente elástica, ou seja, baseado em métricas previamente estabelecidas, a quantidade de servidores poderá aumentar ou diminuir para atender o novo volume de requisiçőes. Desta maneira, para testar a elasticidade da plataforma, simularemos um comportamento aleatório de acessos, com picos de requisiçőes. Feita a simulaçăo, novos servidores serăo instanciados automaticamente e depois, quando o volume de requisiçőes cair, deverăo ser finalizados de maneira transparente.
Além do Elastic Beanstalk, também usaremos um outro serviço da AWS, o Elastic Load Balancing. Este serviço será usado para fazer a distribuiçăo de carga entre os servidores, ou seja, distribuir as requisiçőes dos usuários pelos servidores da aplicaçăo. Esse serviço é muito importante para a nossa aplicaçăo, já que a quantidade de servidores irá variar em períodos de pico. Sendo assim, novos servidores estarăo disponíveis para responder as requisiçőes e o loadbalancer deve ser inteligente para adicioná-los ŕ lista de servidores disponíveis, assim como removę-los quando eles năo mais estiverem em funcionamento.
Como dito, criaremos uma aplicaçăo para testar estes recursos. Ela terá apenas uma lista de funcionários tabelada e permitirá a ediçăo dos dados na própria tabela. Esta tabela editável de funcionários será construída com o framework JavaScript ExtJS 4 e será totalmente desacoplada do servidor, sendo alimentada apenas por serviços RESTful.
Do lado do servidor, criaremos os serviços RESTful utilizando a implementaçăo do JAX-RS chamada Jersey. Como banco de dados, usaremos outra oferta da Amazon Web Services, chamada RDS (Relational Database Service). Assim, a criaçăo e a configuraçăo do banco de dados também serăo delegadas ŕ plataforma, novamente fazendo com que o time de desenvolvimento possa se dedicar a outras responsabilidades. Discutiremos em mais detalhes cada um dos serviços ao longo do artigo e todo o conteúdo desenvolvido estará disponível no site da Java Magazine.
Vale ressaltar que para a maioria dos serviços da AWS existe uma faixa de uso que garante gratuidade pelo período máximo de um ano, contando da data de criaçăo da conta. Para entender mais sobre esta faixa de serviços gratuitos, acesse o endereço na seçăo de referęncias.
Para construir a aplicaçăo usaremos a IDE Eclipse com o plugin AWS Toolkit for Eclipse. Vocę pode baixar a última versăo do Eclipse a partir do endereço indicado na seçăo Links. Para instalar o plugin da AWS, acesse o menu Help > Install New Software, de dentro da IDE. Feito isso, informe o endereço http://aws.amazon.com/eclipse no campo Work with e tecle Enter. Em seguida selecione a opçăo AWS Toolkit for Eclipse, conforme a Figura 2, e siga até o final do processo de instalaçăo. Logo após, reinicie o Eclipse.
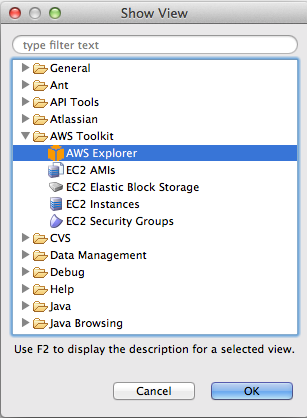
Após instalar o plugin e reiniciar o Eclipse, acesse o menu Window > Show View > Other, e escolha a opçăo AWS Explorer, como mostra a Figura 3.
Esta visualizaçăo dará acesso aos serviços da AWS, porém vocę precisará de uma conta. Para se registrar, realize os passos a seguir:
Feito isto vocę terá sua conta ativa e estará pronto para usufruir dos serviços da AWS. Agora, efetue o login, acesse a área chamada Security Credentials e localize a regiăo que mostra suas chaves, Access Keys. Vocę precisará delas neste artigo.
Uma das vantagens da plataforma da AWS é que ela oferece os mesmos serviços em diferentes regiőes do mundo, ou seja, vocę pode implantar sua aplicaçăo em um datacenter localizado no Brasil, ou EUA, ou Europa, ou em qualquer outra regiăo em que ela ofereça o serviço. Neste artigo vamos criar toda a infraestrutura da aplicaçăo no Brasil, o que diminui acentuadamente a latęncia de rede, comparada com outras ofertas de PaaS localizadas fora da América Latina.
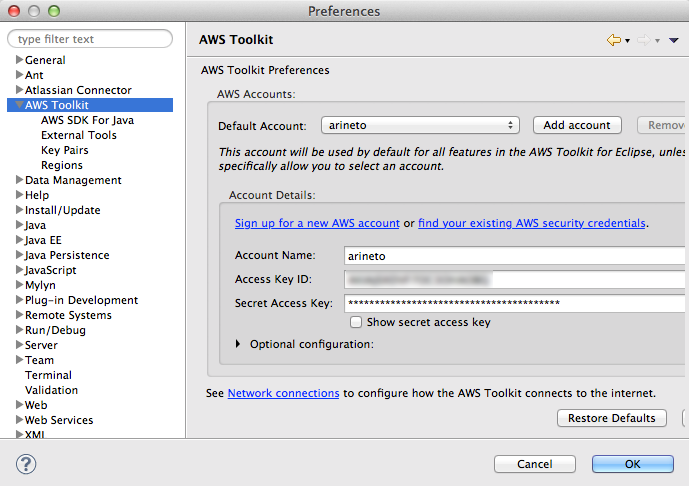
Primeiro vamos configurar a sua conta da AWS no Eclipse, para depois escolher a regiăo. Deste modo, acesse a área de preferencias da IDE e informe os dados da sua conta como mostra a Figura 4. Toda conta na AWS possui pelo menos uma Access Key ID e uma Secret Access Key. Como dito anteriormente, vocę pode obter estas informaçőes na área chamada Security Credentials, dentro da área administrativa da AWS. Sem a chave o toolkit năo poderá acessar os serviços da AWS diretamente.
Feito isto, na coluna do lado esquerdo, escolha a opçăo Regions e selecione a opçăo South America (Săo Paulo). Assim, terminamos a configuraçăo do plugin e definimos em qual regiăo vamos trabalhar. Vamos entăo começar a construir a aplicaçăo.
Para criar uma nova aplicaçăo, acesse o menu File > New > Other, e entăo navegue até a pasta AWS e escolha a opçăo AWS Java Web Project. Neste momento vocę pode pensar: e se já tenho a minha aplicaçăo? Năo tem problema, vocę poderá implantá-la da mesma maneira.
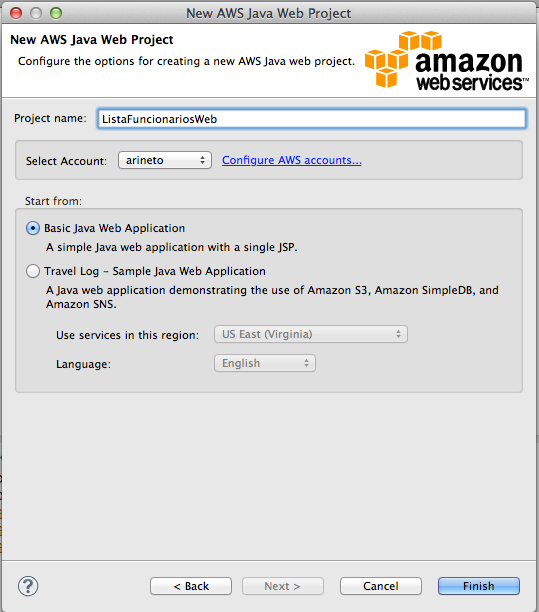
Na próxima tela, informe o nome da aplicaçăo, certifique que sua conta da AWS foi selecionada e que a opçăo Basic Java Web Application esteja selecionada, como mostra a Figura 5.
Quando concluído, vocę terá um novo projeto Web com configuraçőes e estruturas semelhantes ŕ de um projeto normal do Eclipse. A diferença está nos pacotes de bibliotecas que virăo configurados, por exemplo, a AWS SDK for Java, que dará acesso ŕ API de manipulaçăo dos serviços da AWS.
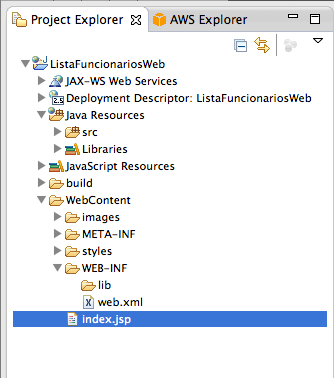
Na Figura 6, podemos observar a estrutura do projeto criado. Veja que já existe um arquivo JSP criado. Este arquivo é um exemplo de acesso ŕ API da AWS e pode ser estudado posteriormente. Para este artigo, remova todo o seu conteúdo e adicione o código da Listagem 1.
<%@ page language="java" contentType="text/html; charset=utf-8"
pageEncoding="utf-8"%>
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-type" content="text/html; charset=utf-8">
<title>Lista Funcionários Web</title>
</head>
<body>
<h1>Lista de Funcionários Web</h1>
</body>
</html>Vamos entăo implantar esta aplicaçăo. Para isso, clique com o botăo direito sobre o nome do projeto e escolha a opçăo AWS Web Services > Deploy to AWS Elastic Beanstalk. Uma nova janela aparecerá e vocę poderá escolher o servidor no qual deseja implantar sua aplicaçăo. Dentro da pasta Amazon Web Services, escolha o servidor Tomcat 7 e clique em Next.
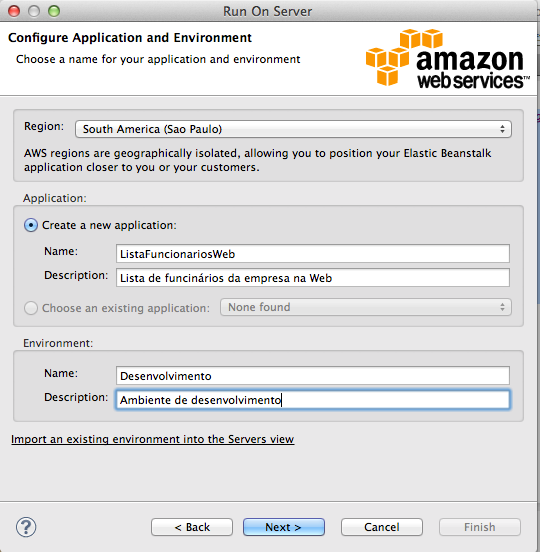
Na próxima tela vocę dará uma nome para a sua aplicaçăo. Este será o nome utilizado pelo Elastic Beanstalk para identificá-la. Logo abaixo vocę terá os campos para criaçăo do Environment, que servirá para termos o controle do ambiente no qual a sua aplicaçăo será implantada. Por exemplo, podemos ter diferentes ambientes que definem estados da sua aplicaçăo ou do release, como: Desenvolvimento, Homologaçăo, Produçăo, etc.
Outra vantagem de se utilizar este serviço é o versionamento da sua aplicaçăo a cada nova implantaçăo, podendo eliminar janelas de manutençăo, efetuar correçőes ou até mesmo rollbacks entre versőes. Além disso, vocę poderá criar um ambiente de implantaçăo completamente novo e redirecionar os usuários do ambiente antigo para o novo automaticamente.
Em nosso exemplo, vamos criar um ambiente chamado Desenvolvimento. Veja como ficará esta tela na Figura 7.
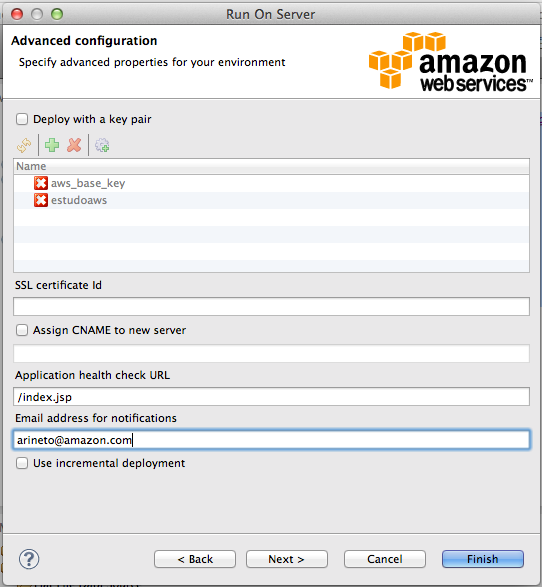
Na próxima tela, como mostra a Figura 8, podemos informar um par de chaves para acessar os servidores criados pelo Elastic Beanstalk. Esta é outra grande vantagem deste serviço, o acesso aos servidores nos quais estăo instalados o Tomcat 7.
Informe também a URL de health check. Este endereço será usado pela plataforma para definir se a aplicaçăo ainda está respondendo. Cada aplicaçăo pode usar a URL que mais representa seu estado de disponibilidade. Em nosso exemplo, vamos usar apenas /index.jsp. Vocę também pode definir um e-mail para receber notificaçőes. Prossiga para a próxima tela.
Na próxima tela, a sua aplicaçăo já estará selecionada para implantaçăo. Depois de clicar em Finish, o processo de implantaçăo começará.
No final deste processo teremos sua aplicaçăo sendo executada na infraestrutura da Amazon e disponível na Internet através de uma URL pública. Seguem algumas atividades que aconteceram automaticamente durante esta implantaçăo:
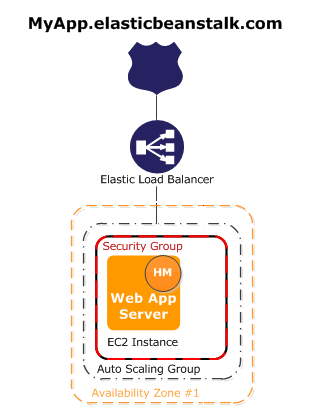
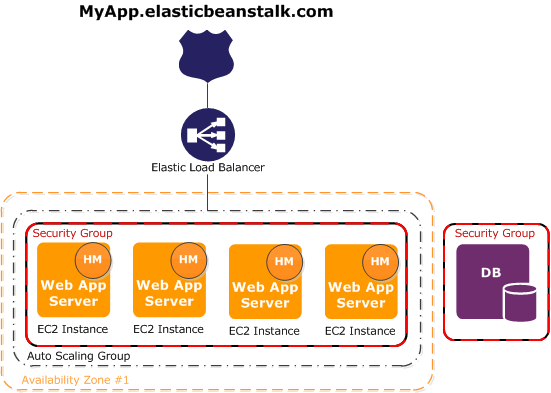
A Figura 9 demonstra uma visualizaçăo simplificada da arquitetura criada automaticamente para vocę. Para ter uma URL pública, sua aplicaçăo foi registrada no serviço de DNS da Amazon, chamado Route 53. Além de traduzir o seu domínio (minhaapp.com.br) para endereços numéricos, IPs, ele fornece vários recursos para melhorar a performance da sua aplicaçăo, viabilizar a construçăo de planos de Disaster Recovery ou simplesmente adicionar pesos diferentes por rota de IP.
Para melhorar a performance da sua aplicaçăo, caso tenha usuários espalhados pelo globo, vocę pode implantá-la em diferentes Regiőes, por exemplo: US East (N. Virginia) e South America (Săo Paulo). Deste modo, para cada requisiçăo, o Route 53 decidirá a regiăo do globo que deverá atendę-la, baseado na melhor latęncia para o usuário.
O serviço de Load Balancer também foi configurado e redirecionado para a sua aplicaçăo (veja a Figura 9). O endereço de health check que configuramos é muito importante para o Load Balancer. Ele será utilizado para avaliar a saúde dos servidores e dependendo do tempo de resposta a própria infraestrutura configurada poderá decidir se um novo servidor é necessário. Faremos este teste no final do artigo.
Note, ainda na Figura 9, que a aplicaçăo está localizada dentro de tręs áreas, săo elas: Availability Zone #1, Auto Scaling Group e Security Group. Para entender a primeira, temos que lembrar que cada Regiăo na AWS pode ser formada por vários datacenters geograficamente separados. Cada datacenter é chamado de Availability Zone. Sendo assim, vocę poderá usar mais de um datacenter para implantar a sua aplicaçăo, garantindo que se algo aconteça com um, a sua aplicaçăo ainda continuará respondendo do outro. Este tipo de técnica deverá fazer parte do seu plano de alta disponibilidade.
A segunda área, Scaling Group, define a elasticidade da sua aplicaçăo, ou seja, quantos servidores vocę gostaria de ter executando sua aplicaçăo e, caso seja necessário melhorar a performance, quantos servidores devem ser adicionados até que se atinja o número máximo. Veremos mais detalhes sobre esta configuraçăo ao longo do artigo.
A terceira área, Security Group, define as regras de firewall para as instâncias de servidores. Da maneira como implantamos a nossa aplicaçăo, apenas a porta 80 (HTTP) foi liberada para acesso.
Quando a implantaçăo acabar, o toolkit abrirá a página padrăo da sua aplicaçăo já na URL pública. A Figura 10 mostra o resultado da implantaçăo.
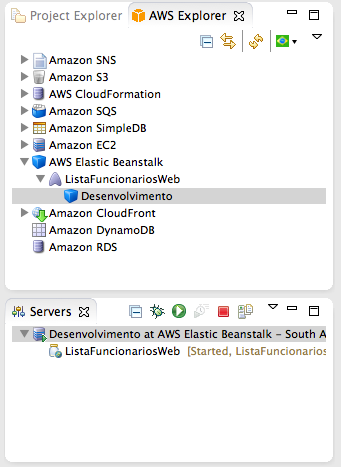
Dentro da IDE Eclipse, agora que a aplicaçăo já foi implantada, vocę verá novos itens nas Views AWS Explorer e Servers, como mostra a Figura 11.
Através da View AWS Explorer, vocę pode abrir a configuraçăo do ambiente. Para isso, clique duas vezes sobre o ambiente Desenvolvimento. Isso abrirá a janela de configuraçăo, iniciando com um resumo, seguido de todos os recursos alocados para sua aplicaçăo, configuraçőes simples e avançadas, eventos do processo de implantaçăo e logs.
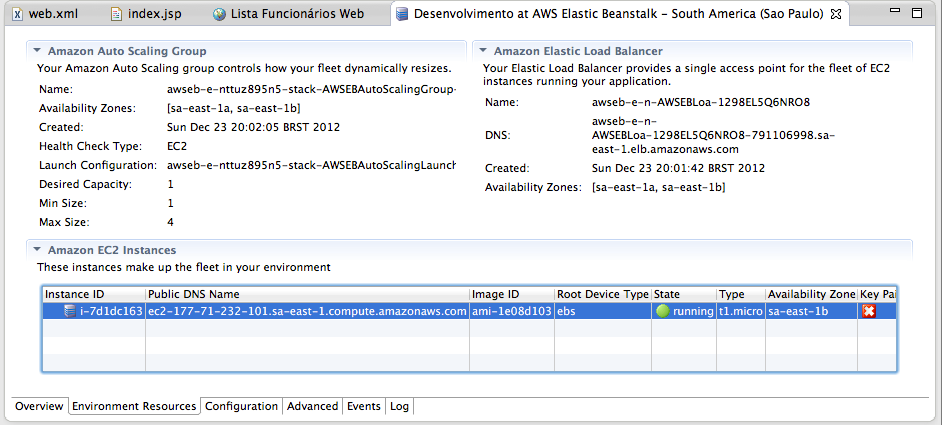
Uma aba desta janela que é importante é a Environment Resources, usada para visualizar os recursos utilizados pela sua aplicaçăo. Esta tela mostrará todos os servidores (neste caso apenas 01), a configuraçăo de elasticidade da sua aplicaçăo (Auto Scaling Group) e a configuraçăo do Load Balancer. A Figura 12 mostra esta tela e a sua configuraçăo.
Para criar o banco de dados, teremos que acessar a ferramenta de administraçăo da AWS na Internet, já que o plugin para o Eclipse năo possui a funcionalidade de criaçăo de bancos. Na Internet vocę terá ainda mais funcionalidades além das oferecidos pelo plugin, como monitoraçăo dos recursos utilizados e acesso a várias outras configuraçőes avançadas.
Para acessar diretamente o console de administraçăo, clique com o botăo direito sobre o Server dentro da view Servers e acesse o menu Amazon Web Services > Go to AWS Management Console. Feito isso, vocę será levado ŕ página padrăo do Elastic Beanstalk.
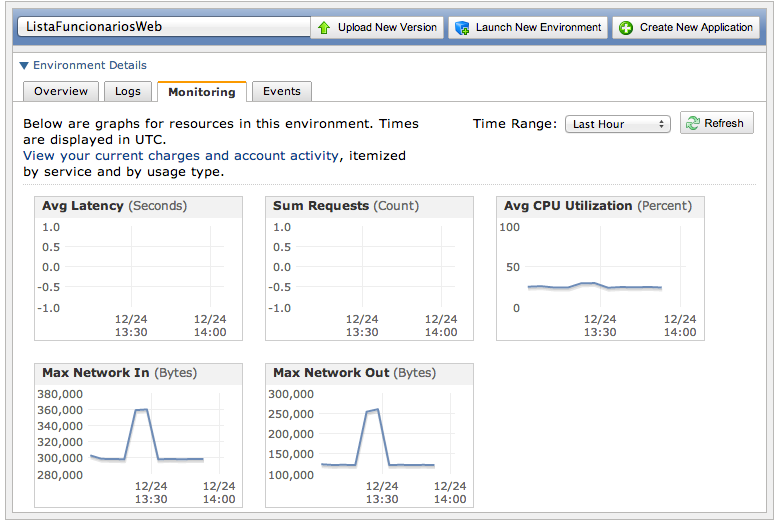
Vocę pode explorar esta tela ŕ vontade. Uma dica interessante, vá até a aba Monitoring, dentro de Environment Details, para visualizar os relatórios de monitoraçăo dos recursos. A Figura 13 mostra os gráficos desta tela. Caso queira ver mais detalhes em cada um dos gráficos, clique sobre o gráfico desejado que uma nova janela se abrirá. Desta tela vocę poderá ver a média de uso de CPU, quantidade de requisiçőes e até mesmo a latęncia média de resposta da sua aplicaçăo.
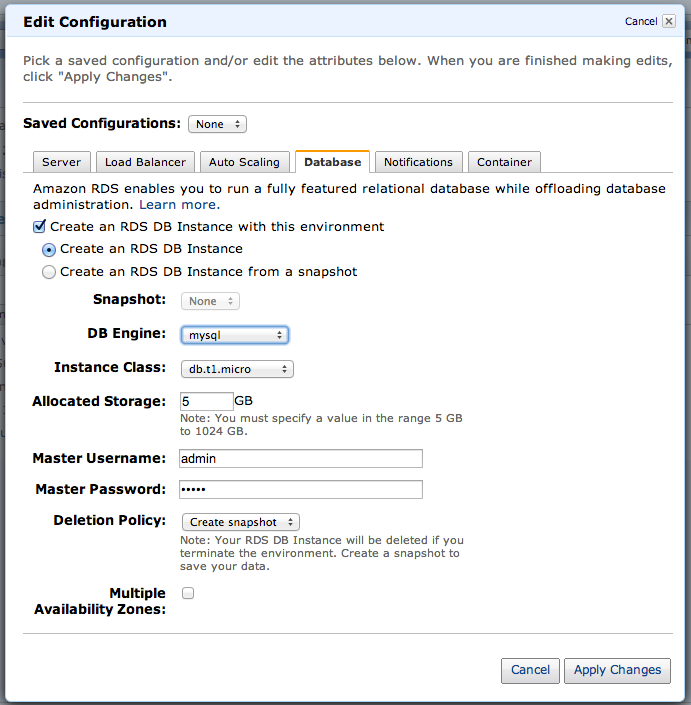
Agora volte para a aba Overview e clique em Edit Configuration. Na janela que se abrirá, acesse a aba Database. Nesta aba vocę poderá configurar uma instância de banco de dados e relacionar esta instância com a sua aplicaçăo. Há algumas configuraçőes nesta tela que săo importantes. Por exemplo, vocę poderia usar uma cópia (snapshot) de outro banco para iniciar a sua nova instância. Outra opçăo é escolher qual a engine de banco que vocę quer. Neste caso escolhemos MySQL, mas vocę pode criar outros tipos de instâncias na AWS, como Oracle e SQL Server. Como vocę está relacionando a sua aplicaçăo com um banco de dados, também é possível escolher qual a política de remoçăo do banco, quando o seu ambiente for terminado. Neste caso, escolhemos que quando o ambiente for finalizado, queremos uma cópia como backup.
A última opçăo é muito especial, Multiples Availability Zones. Esta opçăo cria duas instâncias de banco de dados em diferentes datacenters (Availability Zone), porém dentro da mesma Regiăo (Săo Paulo) e mantém a sincronia entre os dois bancos. Caso ocorra algum problema com a instância principal, a outra substitui automaticamente. Para a sua aplicaçăo isso acontecerá de maneira transparente, já que o endereço de conexăo com o banco năo sofrerá nenhuma alteraçăo.
Portanto, deixe a configuraçăo desta tela como mostra a Figura 14. Logo após, clique no botăo Apply Changes.
A criaçăo do banco levará alguns minutos e no final vocę terá um endereço para conexăo. Assim que terminar esta etapa, volte ao Eclipse e atualize a view AWS Explorer. Expanda a opçăo Amazon RDS e veja que agora há um banco configurado. Neste banco, clique duas vezes para se conectar e informe a senha configurada.
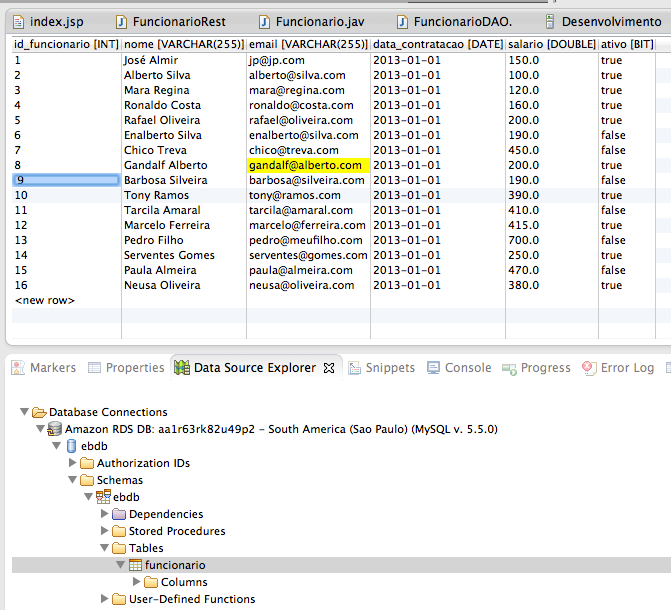
Na aba Database Explorer do Eclipse vocę encontrará o banco de dados já conectado e com um schema padrăo criado, chamado “ebdb”. Com o botăo direito do mouse, clique sobre a conexăo do banco e escolha a opçăo Open SQL Scrapbook. Na janela que se abrirá, defina o nome do seu banco e execute a DDL da Listagem 2. Esta DDL é para a criaçăo da única tabela da nossa aplicaçăo.
CREATE TABLE funcionario (
id_funcionario INT NOT NULL AUTO_INCREMENT,
nome VARCHAR(255) NOT NULL,
email VARCHAR(255) NULL,
data_contratacao DATE NULL,
salario DOUBLE NULL,
ativo BIT(1),
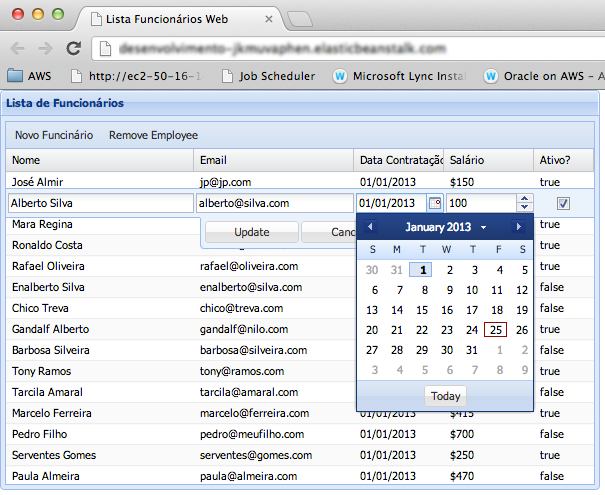
PRIMARY KEY(id_funcionario));Depois que a tabela foi criada, clique com o botăo direito sobre ela e escolha a opçăo Data > Edit, que abrirá a tabela para ediçăo. Nesta janela, clique sobre os campos para adicionar conteúdo e novos registros. A Figura 15 mostra um exemplo de preenchimento desta tabela. Cada registro representa um funcionário e todos serăo listados pela nossa aplicaçăo de exemplo.
Em nossa aplicaçăo de exemplo, usaremos serviços RESTful para prover os dados ŕ camada de apresentaçăo. Para a construçăo dos serviços usaremos a implementaçăo de referęncia da API JAX-RS, chamada Jersey, que é disponibilizada como open source e provę grande facilidade na criaçăo de serviços através de anotaçőes. O endereço para download do Jersey se encontra na seçăo Links.
Há várias maneiras de baixar o Jersey, a principal é utilizando o Maven (usado, entre outras coisas, para automatizar o processo de gestăo de dependęncias entre bibliotecas). Neste artigo, vamos baixar apenas um arquivo .zip, que possui as bibliotecas principais para se utilizar o Jersey. Deste modo, acesse o endereço indicado na seçăo Links e na página que se abrirá, procure por “zip of Jersey”. Em seguida baixe o arquivo indicado no site.
Assim que concluir o download, descompacte e copie o conteúdo da pasta lib para dentro da pasta WEB-INF/lib do seu projeto no Eclipse. Ela deverá apresentar o conteúdo como mostra a Figura 16.
Agora que já temos as bibliotecas necessárias, vamos criar duas classes: Funcionario e FuncionarioRest. A primeira classe define a principal entidade do sistema, o funcionário. Vamos utilizá-la para transportar os dados pesquisados no banco. Além disso, o Jersey usará esta classe para a conversăo de objeto Java para JSON, que será o formato de resposta em nossos serviços RESTful. A conversăo de Java para JSON será feita automaticamente pelo Jersey baseado nas anotaçőes JAXB da classe. A Listagem 3 mostra como deve ficar a classe Funcionario.
Note que usamos apenas uma anotaçăo JAXB, @XmlRootElement. Esta anotaçăo vai informar ao framework de conversăo do Jersey que esta classe pode ser transformada e que seu elemento raiz começará pela definiçăo da própria classe.
Para a classe FuncionarioRest, por enquanto adicione o conteúdo da Listagem 4. Vamos usar este código temporariamente apenas para testar se o ambiente está funcionando corretamente. As anotaçőes que utilizamos definem o caminho que publicaremos o serviço (@Path), seguido da definiçăo do método que receberá as requisiçőes HTTP GET (@GET) e qual o formato do dado que o serviço retornará, neste caso vamos retornar JSON (@Produces(“application/json”)).
Para finalizar, precisamos configurar o Jersey para interceptar todas as requisiçőes que tiverem o endereço começando com /rest/*. Portanto, edite o arquivo WEB-INF/web.xml e adicione o código da Listagem 5 entre as tags.
package com.minhaapp.model;
import java.sql.Date;
import javax.xml.bind.annotation.XmlRootElement;
@XmlRootElement
public class Funcionario {
private int idFuncionario;
private String nome;
private String email;
private Date dataContratacao;
private Double salario;
private boolean ativo;
//getters and setters
}
package com.minhaapp.rest;
import java.util.*;
import javax.ws.rs.*;
import com.minhaapp.model.Funcionario;
@Path("/funcionarios")
public class FuncionarioRest {
@GET
@Produces("application/json")
public List<Funcionario> getListaFuncionarios(){
Funcionario funcionario = new Funcionario();
funcionario.setNome("Ari Dias");
List<Funcionario> funcionarios = new ArrayList<Funcionario>();
funcionarios.add(funcionario);
return funcionarios;
}
}
<servlet>
<servlet-name>Jersey Web Application</servlet-name>
<servlet-class>com.sun.jersey.spi.container.servlet.ServletContainer
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>Jersey Web Application</servlet-name>
<url-pattern>/rest/*</url-pattern>
</servlet-mapping>Feito isto, testaremos se o nosso serviço REST está corretamente configurado e se a transformaçăo de Java para JSON está ocorrendo corretamente. Para isto, faça uma nova implantaçăo no ambiente do Elastic Beanstalk. Caso queira acelerar o processo de implantaçăo, vocę pode configurar o serviço para usar implantaçőes incrementais. Assim, apenas o que foi alterado será enviado para o ambiente do Beanstalk, acelerando o processo de upload. Para configurar a implantaçăo incremental, clique duas vezes sobre o servidor e marque a opçăo Use Incremental Deployments, localizada na coluna do lado direito.
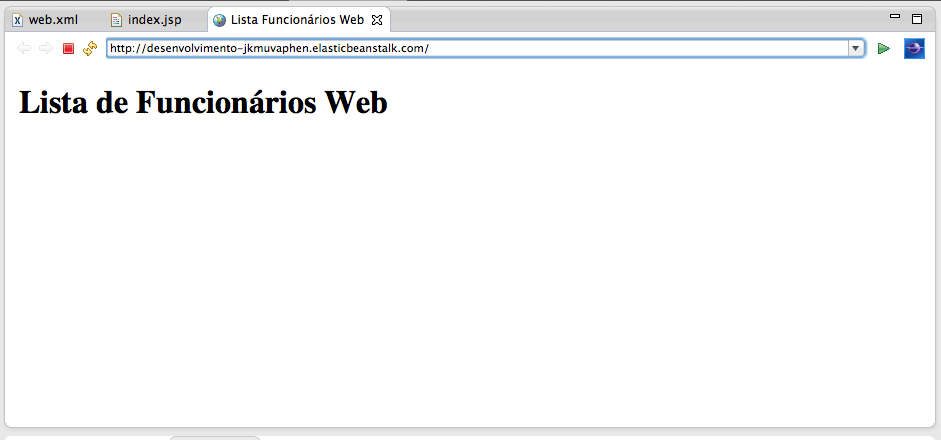
Após o final da implantaçăo, sua aplicaçăo abrirá na URL padrăo, index.jsp. Substitua o nome deste arquivo por rest/funcionários. Se tudo estiver correto, o Jersey interceptará esta requisiçăo e a entregará ao método getListaFucionário() da classe FuncionarioRest. O resultado deverá ser como mostra a Figura 17.
Agora que já temos o serviço que provę os dados, precisamos criar uma camada de apresentaçăo. Para isto, usaremos um framework moderno e já maduro para construçăo de aplicativos Web, o ExtJS.
A empresa responsável por este framework se chama Sencha e oferece vários outros produtos, inclusive um dos mais conceituados frameworks para desenvolvimento de aplicativos móveis, o Sencha Touch. Para mais informaçőes, veja o endereço de referęncia na seçăo Links. Do site da empresa Sencha, baixe o ExtJS. Lembre-se de escolher a licença que melhor se adapte ao seu modelo comercial, já que o ExtJS possui vários modelos de licença. Para este artigo, já que estamos disponibilizando todo o código fonte de exemplo, vamos baixar a versăo compatível com a GPL license v3, que incentiva programas Open Source.
Após baixar o ExtJS, crie uma pasta no seu projeto chamada extjs, dentro de WebContent. Depois copie do arquivo baixado a pasta resources e o arquivo ext-all.js. Ao final deste processo, a estrutura da pasta WebContent/extjs deverá estar exatamente como a da Figura 18.
Feito isto, vamos alterar o arquivo index.jsp e adicionar a tabela editável que exibirá todos os funcionários vindos diretamente do nosso serviço REST (/rest/funcionarios). Assim, primeiramente temos que adicionar o arquivo de estilo do ExtJS e seu arquivo JavaScript. A Listagem 6 mostra o arquivo index.jsp e o cabeçalho após a inclusăo dos arquivos do ExtJS.
<head>
<meta http-equiv="Content-type" content="text/html;
charset=utf-8">
<title>Lista Funcionários Web</title>
<link rel="stylesheet" href="extjs/resources/
css/ext-all.css" type="text/css" />
<script type="text/javascript"
src="extjs/ext-all.js"></script>
</head>O ExtJS também conta com o carregamento automático de dependęncias, porém năo usaremos neste artigo. No entanto, usaremos a capacidade de MVC do framework. Para isso, a primeira coisa que definiremos será o nosso modelo de dados, que será informado dentro do próprio arquivo index.jsp. Segue o código da definiçăo do modelo:
Ext.define('Funcionario', {
extend: 'Ext.data.Model',
fields: [ 'nome', 'email',
{ name: 'dataContratacao', type: 'date', dateFormat: 'd/m/Y' },
{ name: 'salario', type: 'float' },
{ name: 'ativo', type: 'bool' }] });
Com o modelo de dados pronto, vamos usar um recurso do ExtJS chamado de Store. Podemos considerar uma Store como se fosse um datasource. Uma Store será conectada ŕ tabela e será responsável por carregar e salvar todas as alteraçőes feitas nos dados. Para traduzir a mensagem JSON do servidor no modelo de dados que definimos no ExtJS, a Store deve possuir um Reader. Este Reader interpretará cada registro de funcionário vindo do servidor e criará para cada registro um objeto chamado Record. A seguir, temos a definiçăo da Store que será definida no arquivo index.jsp, dentro da tag:
Ext.create('Ext.data.Store', {
model: 'Funcionario',
proxy: { type: 'ajax', url: 'rest/funcionarios',
reader: { type: 'json'}
} });Observe que definimos o modelo dos dados e logo após especificamos uma URL (/rest/funcionarios), de onde virá a lista de funcionários.
Feito isto, temos o modelo e a origem dos dados configurados. Nos falta agora criar a interface gráfica. Para isso, usaremos outro componente do ExtJS, a tabela editável. A Listagem 7 mostra o código necessário para adicionar este componente em nossa página.
Na primeira linha vocę encontra a chamada ŕ funçăo que criará a tabela: Ext.create('Ext.grid.Panel', { … })
Logo em seguida vęm os parâmetros como, por exemplo, o ID do componente DOM onde a tabela deverá ser desenhada (renderTo), qual a origem de dados (store), título e tamanho.
Ext.create('Ext.grid.Panel', {
title: 'Lista de Funcionários',
store: store,
renderTo: 'listafuncionarios-grid',
width: 600,
height: 400,
frame: true,
columns: [{
header: 'Nome',
dataIndex: 'nome',
flex: 1,
editor: {
allowBlank: false
}
}, {
header: 'Email',
dataIndex: 'email',
width: 160,
editor: {
vtype: 'email'
}
}, {
xtype: 'datecolumn',
header: 'Data Contrataçăo',
dataIndex: 'dataContratacao',
width: 90,
editor: {
xtype: 'datefield',
format: 'd/m/Y'
}
}, {
xtype: 'numbercolumn',
header: 'Salário',
dataIndex: 'salario',
format: '$0,0',
width: 90,
editor: {
xtype: 'numberfield'
}
}, {
header: 'Ativo?',
dataIndex: 'ativo',
width: 60,
editor: {
xtype: 'checkbox'
}
}]
});Depois definimos as colunas e relacionamos cada uma delas com um campo do modelo de dados (Funcionario). Assim que os dados do serviço chegarem ŕ página, o Reader interpretará os dados de cada funcionário, criando o Record e salvando dentro do Store. No entanto, precisamos ainda definir o que será mostrado em cada linha da tabela. Por isso a necessidade de mapear cada coluna com um atributo do funcionário. Para isso, usamos o atributo dataIndex. O código a seguir mostra a configuraçăo de uma coluna na tabela:
columns: [{
header: 'Nome',
dataIndex: 'nome'
}]Ainda no arquivo index.jsp, adicione dentro da tag um componente, que será usado pelo framework para posicionar a tabela criada. Veja a definiçăo do na sequęncia:
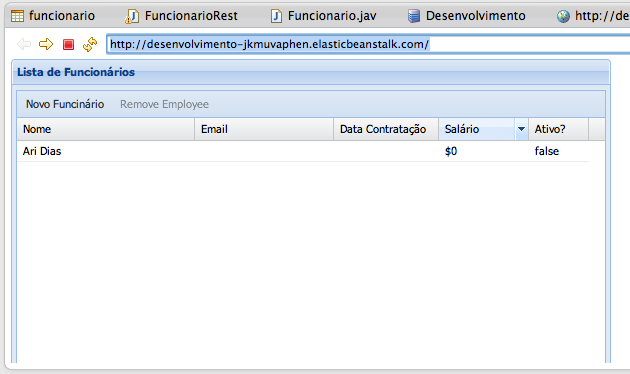
Com isto, já podemos reimplantar a aplicaçăo e testar o resultado da integraçăo da tabela com nosso serviço REST. Lembre-se que até o momento o nosso serviço REST ainda năo retorna dados do banco de dados. A Figura 19 mostra o resultado atual da lista de funcionários. Vale lembrar também que o código completo da aplicaçăo estará disponível no site da Java Magazine.
Agora que a integraçăo entre a camada de apresentaçăo e os serviços REST está funcionando, vamos ao passo final, conectar ao banco de dados e buscar a lista de todos os funcionários. Para conectar ao banco de dados precisaremos da URL de conexăo. Esta URL pode ser encontrada na configuraçăo da conexăo com o banco dentro do Eclipse. Portanto, clique sobre a conexăo com o banco dentro da aba Data Source Explorer e escolha a opçăo Properties.
A URL apresentada estará no seguinte formato: jdbc:mysql://xxxxxxx.yyyyyyy.sa-east-1.rds.amazonaws.com:3306/ebdb
Esta URL define o endereço de conexăo JDBC do seu banco, e onde vocę vę xxxx.yyyy, na sua conexăo estará o endereço do seu banco.
Como o nosso objetivo neste artigo năo é a criaçăo de uma camada complexa de acesso a dados, criaremos uma classe bem simples para fazer a conexăo com o banco e executar a query que buscará os dados dos funcionários. Esta classe serve apenas para representar a busca dos dados e năo deve ser usada para um sistema em produçăo.
A Listagem 8 mostra o código da classe FuncionarioDAO. Veja que usamos a URL de conexăo diretamente em nosso código, porém esta URL poderia ser configurada como um parâmetro da aplicaçăo através do próprio Elastic Beanstalk.
Năo vamos explorar neste artigo todas as possibilidades de parametrizaçăo que o Elastic Beanstalk fornece, entretanto, vale ressaltar algumas que săo mais usadas, como: memória alocada para o heap da JVM, habilitar debug remoto, Session Stickiness entre o Load Balancer e os servidores (mantém o usuário conectado ao mesmo servidor durante toda a sua sessăo) e parâmetros genéricos, configurados como chave-valor.
Ainda sobre a conexăo para acesso a dados, năo se esqueça de baixar o driver do MySQL e adicionar na biblioteca da aplicaçăo, dentro da pasta WEB-INF/lib. Para baixar o driver do MySQL, acesse o endereço informado na seçăo Links.
Criada a classe de acesso a dados, vamos entăo alterar o código do serviço REST para usá-la. A Listagem 9 mostra o código final do método do serviço. Observe o uso da nova classe para criar a lista de funcionários (List).
Com isso, estamos quase prontos para testar a nossa tabela editável com todos os funcionários listados. Em seguida, uma nova implantaçăo será necessária para atualizar a aplicaçăo nos servidores do Elastic Beanstalk. Quando a implantaçăo terminar, carregue novamente a página index.jsp. Ela deverá mostrar a tabela editável semelhante ŕ da Figura 20.
import java.sql.*;
import java.util.*;
import com.minhaapp.model.Funcionario;
public class FuncionarioDAO {
public List<Funcionario> buscaFuncionarios() {
List<Funcionario> funcionarios = new ArrayList<Funcionario>();
Connection con = null;
Properties connectionProps = new Properties();
connectionProps.put("user", "xxxxxx");
connectionProps.put("password", "xxxxxx");
Statement stmt = null;
String query = "select id_funcionario, nome, email,
data_contratacao, salario, ativo from funcionario";
try {
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager
.getConnection(
"jdbc:mysql://xxxxxx.yyyyyy.sa-east-1.rds.amazonaws.com:3306/ebdb",
connectionProps);
stmt = con.createStatement();
ResultSet rs = stmt.executeQuery(query);
while (rs.next()) {
int idFuncionario = rs.getInt("id_funcionario");
// carrega o restando dos atributos do recordset
funcionarios.add(new Funcionario(idFuncionario, nome, email,
dataContratacao, salario, ativo));
}
} catch (Exception e) {
// tratamento de erros
} finally {
// fechando a conexăo
}
return funcionarios;
}
}
package com.minhaapp.dao
@GET
@Produces("application/json")
public List<Funcionario> getListaFuncionarios(){
FuncionarioDAO funcDAO = new FuncionarioDAO();
List<Funcionario> funcionarios = funcDAO.buscaFuncionarios();
return funcionarios;
}Para testar a elasticidade da sua aplicaçăo, vamos supor o seguinte cenário: sua aplicaçăo ficou pronta, e agora vocę fará várias campanhas de marketing ao longo dos próximos meses. Algumas campanhas serăo veiculadas na parte da manhă, pela TV e outras serăo através de marketing online, em grandes portais. Desta maneira, vocę já sabe que terá picos de acesso, porém năo sabe o tamanho do sucesso que terá.
Neste cenário, vocę tem dois caminhos: a compra de uma infraestrutura necessária de forma antecipada (upfront), porém sem a certeza de que ela será suficiente, além do investimento realizado no trabalho de gestăo de tudo que foi adquirido; ou, como descrevemos no início do artigo, vocę pode optar por uma infraestrutura elástica, como a fornecida pelo Elastic Beanstalk.
Como abordado anteriormente neste artigo, a sua aplicaçăo deve estar preparada para suportar grandes volumes de tráfego em momentos de pico. No entanto, quando este volume decrescer, o ideal é que ela também consuma menos recursos computacionais, fazendo com que seu custo de infraestrutura e de gestăo acompanhe o momentum da sua aplicaçăo, sem investimentos adiantados, sem grandes custos de gerenciamento e diminuindo os riscos.
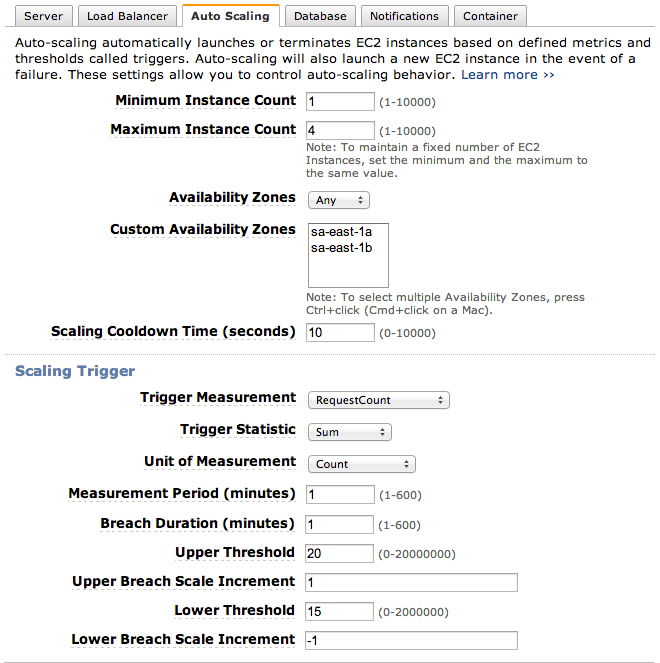
Quando se trata da plataforma da AWS, isso significa configurar um Auto Scaling Group. Vocę pode ver a configuraçăo atual dentro da janela de configuraçăo do seu ambiente, dando um duplo clique no servidor configurado pelo toolkit. Ao invés de usarmos a configuraçăo fornecida pelo toolkit, usaremos o console da web, onde temos mais opçőes. Para abrir diretamente o console da web, clique com o botăo direito sobre o servidor e acesse a opçăo Amazon Web Services > Go to AWS Management Console. Uma página será aberta no seu navegador padrăo. Nesta página, expanda a opçăo Environment Details e clique em Edit Configuration. Em seguida, acesse a aba Auto Scaling e deixe sua configuraçăo conforme mostra a Figura 21.
O Auto Scaling Group define o número mínimo e máximo de servidores através dos parâmetros Minimum e Maximum Instance Count. Logo abaixo vocę poderá escolher se deseja que os servidores sejam distribuídos automaticamente entre Availability Zones diferentes, ou seja, entre datacenters geograficamente distribuídos. O atributo Cooldown permite configurar a quantidade de segundos que o serviço deve esperar depois de tomada uma decisăo de aumentar ou diminuir o número de servidores.
A segunda parte desta tela definirá as métricas do gatilho que aumentará ou diminuirá o número de servidores. Em nosso exemplo, vamos utilizar a quantidade de requisiçőes, medidas a cada 1 minuto. Caso a quantidade de requisiçőes que atingirem o Load Balancer ultrapassar a quantidade de 20, um servidor será adicionado ao grupo. Caso baixe de 20 requisiçőes, um servidor será removido. Vale lembrar que a quantidade máxima e mínima de servidores sempre será respeitada.
Do seu navegador, acesse algumas vezes a aplicaçăo no intervalo de um minuto. Assim vocę fará com que a configuraçăo do Auto Scaling Group dispare novas instâncias de servidores automaticamente, com a sua aplicaçăo já instalada e configurada. Quando vocę parar com as requisiçőes, as novas instâncias serăo terminadas, já que o limite inferior de acessos foi alcançado.
A Figura 22 mostra a nova realidade da arquitetura da sua aplicaçăo. Observe que adicionamos agora mais servidores no Auto Scaling Group e o banco de dados.
Os serviços de Cloud Computing oferecidos pala Amazon Web Services proporcionam novas fronteiras para a sua aplicaçăo. O que antes era difícil, como implantar em poucos minutos sua aplicaçăo em diferentes datacenters ou aumentar e diminuir sua infraestrutura baseada na demanda, agora está ao alcance de todos.
Esta flexibilidade vem viabilizando várias iniciativas de Startups, que precisam crescer rapidamente caso o sucesso repentino bata a porta, além de diminuir o investimento inicial. E para as empresas de grande porte, este modelo reduz drasticamente os custos de construçăo e gestăo da infraestrutura, além de prover dinamismo em novos projetos e processos de inovaçăo.
Esse novo modelo de computaçăo vem sendo adotado massivamente em todo o mundo, tanto em mercados maduros como nos emergentes. Sem dúvida podemos considerar que Cloud Computing já é uma realidade e está ao alcance de todos. E vocę, quanto tempo ainda vai esperar para levar a sua aplicaçăo para a Nuvem?


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.