Confira: Business Intelligence Tutorial
Este artigo aborda as melhores práticas empregadas na criaçăo de um processo de Business Intelligence utilizando-se de um case fictício. Serăo descritos os passos necessários para a criaçăo de um processo de ETL, bem como da modelagem e publicaçăo da parte lógica do cubo (metadados) e, por fim, a visualizaçăo dos dados em uma ferramenta OLAP. Este processo foi desenvolvido com a suíte Pentaho Business Analytics, uma ferramenta gratuita e escalável.
Mais especificamente, nesta segunda parte serăo descritos as etapas necessários para a criaçăo das transformaçőes responsáveis por migrar os dados da base Origem, a do sistema transacional (OLTP), para a base Destino (OLAP), a base analítica. Esta foi modelada em formato estrela e será a responsável por armazenar os dados do cubo de Produtos Vendidos da empresa fictícia, Magazine Setorial.
Entender na prática como definir um processo de migraçăo de dados no contexto de uma soluçăo de business intelligence. A realizaçăo correta desta etapa é fundamental para o sucesso do projeto uma vez que os dados nem sempre estăo prontos e no formato adequado, sendo necessários ajustes e transformaçőes antes de podermos utilizá-los.
Na primeira parte deste artigo foram abordados os principais conceitos de Business Intelligence e, para exemplificá-los, foi proposto o case de uma loja de departamentos fictícia, formada por diversas filiais e com a necessidade de analisar os dados de suas vendas. Na sequęncia do artigo, foi apresentada a suíte Pentaho, capaz de contemplar os requisitos e regras de negócio elencados. Além disso, a base de dados Origem foi analisada e o raciocínio necessário para a modelagem da base Destino, em formato estrela, foi descrito. Por fim, as etapas para a configuraçăo do Pentaho Data Integration foram descritas.
Os resultados desse trabalho dăo subsídios para que, nesta segunda e última parte do artigo, o processo de ETL seja criado, juntamente com os metadados do cubo, sua publicaçăo no servidor web e a análise dos dados em uma ferramenta OLAP.
Com a base OLAP modelada, significa que as principais decisőes já foram tomadas, restando agora a tarefa de migrar os dados para a estrutura proposta. Entretanto, năo é raro que sejam necessários pequenos ajustes na modelagem devido a algum detalhe que tenha passado despercebido na análise inicial.
Nesta segunda parte do artigo serăo descritos os passos necessários para a criaçăo das transformaçőes responsáveis por migrar os dados da base Origem, a do sistema transacional (OLTP), para a base Destino (OLAP), a base analítica, modelada em formato estrela e responsável por armazenar os dados do cubo de Produtos Vendidos da empresa fictícia, Magazine Setorial. Estas transformaçőes serăo responsáveis por popular as dimensőes dim_data, dim_produto, dim_cliente, dim_vendedor, dim_notafiscal e a tabela fato, ft_notafiscal_produto.
Na continuidade, serăo apresentados os passos necessários para criar um Job, que tem a responsabilidade de executar todas as transformaçőes criadas, na sequęncia correta e também os passos para instalar e iniciar o serviço do servidor de BI, no qual o Pentaho User Console (PUC) está inserido, e o serviço do Pentaho Administrator Console (PAC), que tem, entre outras responsabilidades administrativas, a funçăo de manter as conexőes JNDI, que dăo acesso ŕs bases de dados envolvidas nas ETLs. Săo descritas também as etapas necessárias para a instalaçăo, via Pentaho Marketplace, do plugin da ferramenta OLAP Saiku Analytics.
Finalizando, outra ferramenta da suíte será descrita, o Pentaho Schema Workbench, responsável por gerar e publicar o modelo lógico do cubo, fundamental para a análise de dados que será empreendida neste artigo por meio da utilizaçăo de uma ferramenta OLAP.
A Java Naming and Directory Interface (JNDI) é uma API para acesso a serviços de diretórios. Ela permite que aplicaçőes cliente descubram e obtenham dados ou objetos através de um nome.
A API JNDI é utilizada em aplicaçőes Java que acessam recursos externos, como bases de dados, filas ou tópicos JMS e componentes Java EE. Os administradores do sistema gravam objetos administrados num serviço de diretório disponibilizado pelo servidor de aplicaçőes (normalmente) e a aplicaçăo busca estes objetos através da JNDI (lookup).
A dimensăo tempo, presente na maioria dos projetos de BI, é de grande valia, pois permite analisar os dados levando em consideraçăo o momento em que o fato ocorreu. Para este case, existe a necessidade de agruparmos os dados por ano, trimestre, męs e dia. Diante disso, será criada a dimensăo tempo denominada dim_data, que receberá um registro para cada dia do ano, a partir de uma data pré-determinada.
Para se definir o período que será abrangido por esta dimensăo, é necessária uma análise dos dados da tabela de nota fiscal, a partir da qual percebe-se que a menor data de venda é 01/01/2008. Para que sejam analisadas as vendas já efetuadas e permitir que este processo de geraçăo de registros năo precise ser reexecutado por um período considerável, deve-se gerar as datas a partir da primeira venda e por dias suficientes para que haja registros para pelo menos os próximos 10 anos a partir da data atual. Estes registros de datas futuras também săo úteis para análises preditivas, traçando uma estimativa para o futuro com base nos dados históricos.
A dimensăo dim_data pode ter sua estrutura ainda mais simples que a proposta neste case ou, pelo contrário, ser mais rica em detalhes que, dependendo do negócio, podem ser interessantes como, por exemplo, se o dia é um fim de semana, primeiro ou último dia da semana, primeiro ou último dia do męs, etc.
Os registros para esta dimensăo podem ser criados de diversas maneiras como, por exemplo, por meio de stored procedures que fazem os cálculos no banco de dados e até mesmo por planilhas prontas para download, disponíveis em sites como o kinballgroup.com e encontradas ao se pesquisar no Google por “date dimension xls”. Na maioria destes casos, no entanto, alguma adaptaçăo será necessária, dependendo das colunas que compőem a dimensăo ou dos idiomas envolvidos. Apesar disso, independente da estratégia escolhida para a geraçăo destes dados, esta dimensăo poderá ser compartilhada entre todos os futuros cubos.
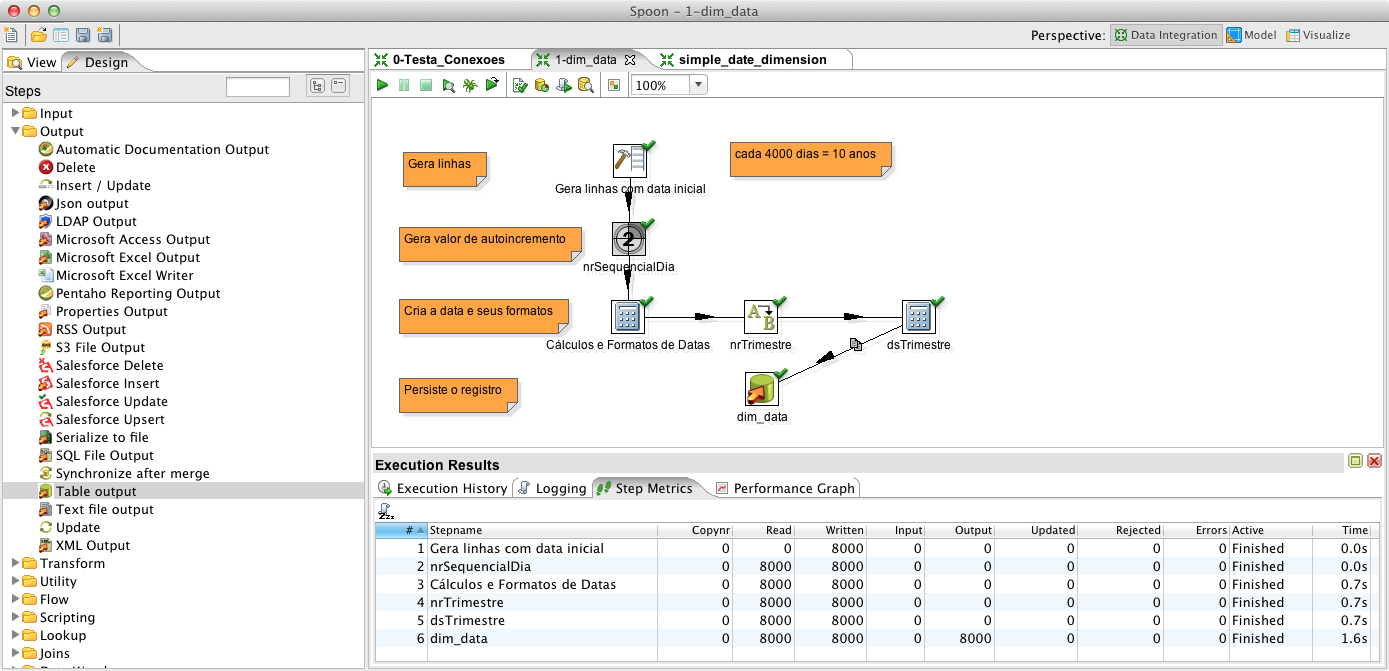
Para gerar os dados da dimensăodim_data, utilizando o PDI, é necessário realizar um conjunto de passos. Inicialmente, crie uma transformaçăo e salve-a com o nome: “1-dim_data”. É ela que conterá todas as informaçőes sobre o processo de transformaçăo de dados, permitindo sua automaçăo.
Em seguida, arraste um componente Generate Rows, que como o nome sugere, tem a responsabilidade de gerar n linhas, com x colunas, especificando o nome, tipo de dado e o valor de cada uma delas. Dę o nome de “Gera linhas com data inicial” e, em Limit, informe o número de linhas desejadas. Como o primeiro registro da dimensăo será referente ŕ data da primeira venda e o objetivo é gerar registros para, pelo menos os próximos 10 anos a partir da data atual, informe o valor 8000, que será suficiente para gerar registros de 01/01/2008 até 01/01/2028.
Feito isso, em Fields, informe o único campo desejado, com o nome “dtInicio”, tipo Date, formato “yyyyMMdd” e em Value informe a data inicial “20080101”. Com isso definimos qual tipo de dado será gerado em nosso banco. Em seguida, para verificar se está tudo ok, faça um Preview dos dados e clique em OK para fechar o step.
O próximo passo é arrastar o componente Add sequence, que gera um número sequencial, e criar uma seta de ligaçăo entre os dois steps. Edite o step Add sequence, dę o nome de “nrSequencialDia”, preencha com este mesmo valor o campo Name of value, para que seja criada uma coluna com este nome em nosso resultset (de 8000 linhas) e clique em OK.
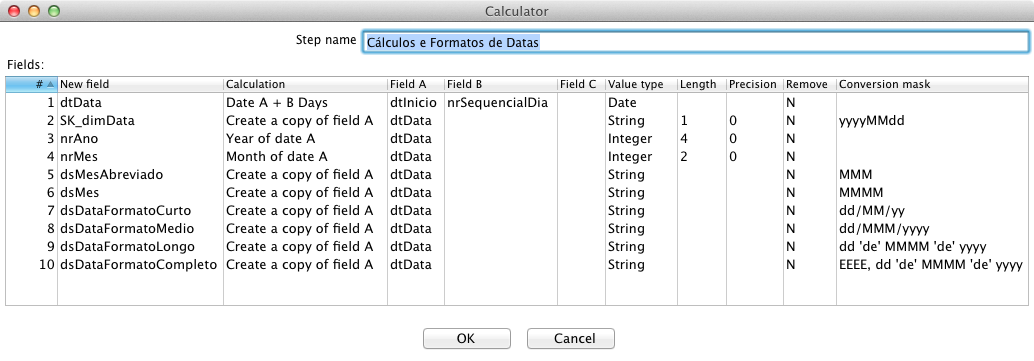
Ainda nesta etapa, arraste o step Calculator adicionando-o ao fluxo da ETL, dę o nome de “Cálculos e Formatos de Datas”, inclua uma linha para cada variável a ser calculada, preencha as colunas de acordo com a Figura 1 e perceba a riqueza de opçőes que este componente disponibiliza (desde o tratamento de strings, como escape e unescape HTML, até funçőes de cálculos com números e datas). Neste componente foram criadas 10 variáveis necessárias para o preenchimento da dimensăo dim_data. A primeira é “dtData” que será obtida somando a data inicial, “01/01/2008”, com o número sequencial criado pelo componente Add sequence. As outras variáveis serăo criadas com base na data obtida e servem para representá-la em diversos formatos.
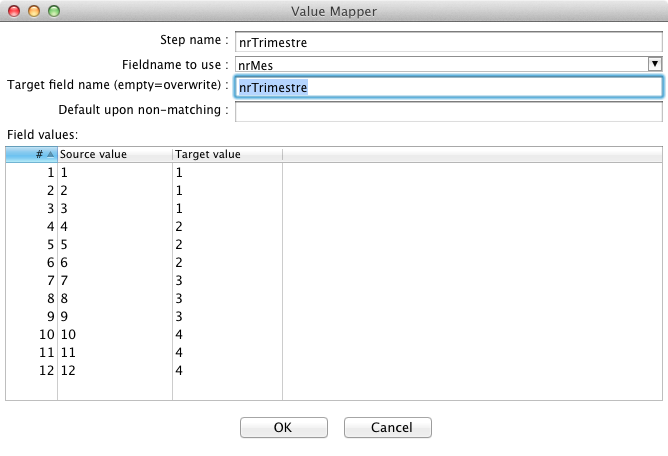
Agora partiremos para a definiçăo dos atributos referentes ao trimestre. Como alternativa para năo complicar o raciocínio com o step Calculator, também capaz de executar esta atividade, inclua o step Value Mapper, que é uma tabela de mapeamento do tipo “de-para”, onde é feita a relaçăo entre o número do męs e o número do trimestre correspondente, conforme indica a Figura 2.
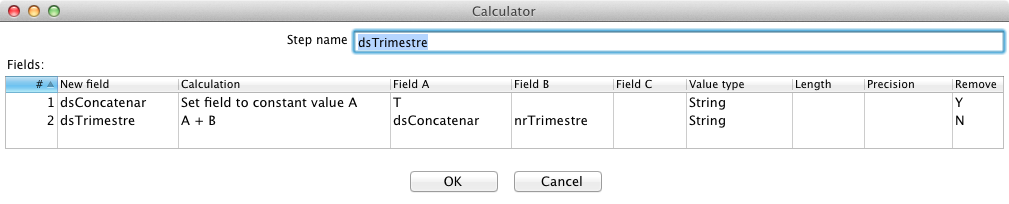
Para gerar a última coluna necessária, onde teremos a descriçăo do trimestre, com valores T1, T2, T3 e T4, concatene a letra “T” com nrTrimestre. Para isto, inclua um novo step Calculator e insira uma linha para cada variável a ser criada, preenchendo as colunas conforme a Figura 3. Repare que a primeira variável criada, dsConcatenar, está com o valor “Y” em Remove. Isto indica que ela só existirá neste step e năo fará parte do resultset.
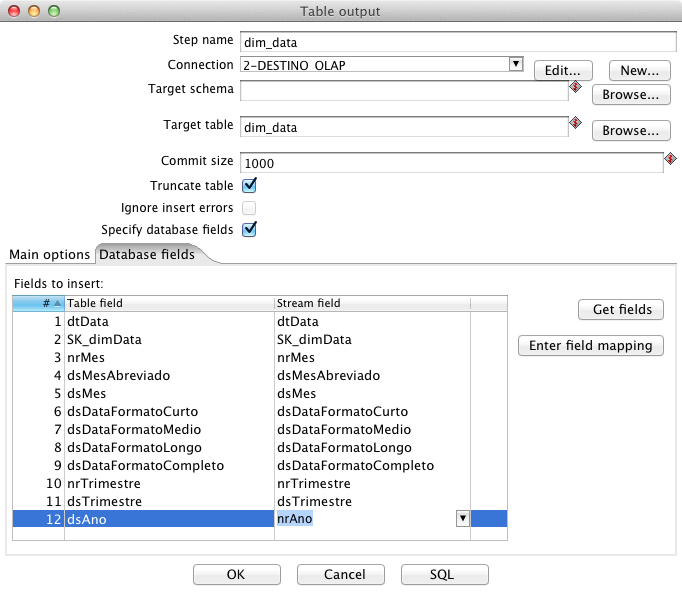
Em seguida, para persistir os dados no banco, inclua ao fluxo da ETL o componente Table output e edite-o, com dois cliques.
Nesse momento, dę o nome de dim_data e selecione a conexăo para a base Destino. Em Target table escreva dim_data e marque as opçőes Truncate table e Specify database fields para que, na segunda aba, de nome Database fields, seja possível fazer o mapeamento das colunas que receberăo valor neste Insert, proporcionado pelo componente.
Dando continuidade, para que o PDI preencha automaticamente a tabela deste componente com os nomes das colunas a serem afetadas, clique em Get fields, e quando perguntado pelo PDI se o usuário deseja limpar os valores já preenchidos e incluir uma linha para cada campo da tabela informada, selecione Clear and add all, após em Edit field mapping e entăo em OK. Neste momento, o PDI montará automaticamente o mapeamento das colunas pela semelhança dos nomes, sendo necessário apenas fazer o vínculo entre “nrAno” e “dsAno”, tarefa necessária nos casos em que o nome da coluna do resultset năo for igual ao nome da coluna no banco, como demonstra a Figura 4.
Implementados os passos anteriores, execute a transformaçăo a partir do menu Action > Run e obtenha uma tela como a apresentada na Figura 5 que confirma a inclusăo de 8000 linhas em 1.6 segundo.
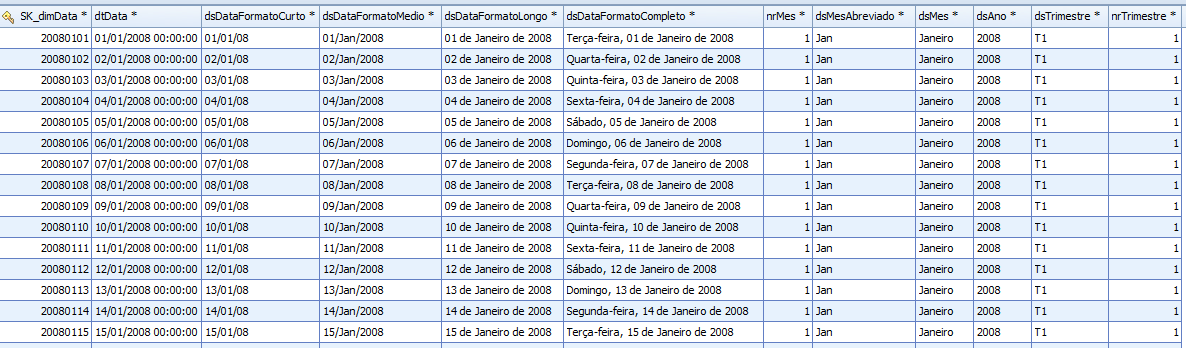
Por fim, confira o resultado obtido e perceba que os dados foram gerados no idioma adotado pelo computador em que o PDI está instalado, que neste caso é o portuguęs, como demonstra a Figura 6.
A ETL desta dimensăo será a mais trabalhosa se comparada ŕs demais deste processo, pois as próximas terăo, tăo somente, a responsabilidade de mover os dados para a base analítica, já que os dados deste case necessitam apenas da concatenaçăo dos campos DDD e telefone celular para gerar um campo único, formatado.
De acordo com os requisitos e regras de negócio propostos neste case, descritos na parte 1 deste artigo, a dimensăo “dim_produto” năo possui a necessidade de que seus dados sejam versionados. Além disso, as informaçőes sobre a categoria dos produtos ficará nesta mesma dimensăo, uma vez que um produto sempre está atrelado a uma mesma categoria. A adoçăo de uma coluna para o código do produto e outra para o código da categoria do produto năo é obrigatória, embora seja uma boa prática. Dessa forma, a performance do processo de ETL é melhorada, pois um lookup em uma coluna do tipo inteiro é muitas vezes mais rápido do que em uma coluna do tipo string. Nesta dimensăo fica claro que os atributos de produto e categoria estăo desnormalizados, ou seja, repetidos em todos os registros. Esta redundância é uma das características do BI para agilizar a leitura dos dados sem se preocupar com o espaço em disco gasto.
Com o objetivo de evitar repetiçăo neste artigo, uma vez que o funcionamento do PDI está esclarecido, a partir deste ponto năo será mais especificado a todo step criado que este deve ser ligado ao fluxo da ETL por meio de um hop (seta).
Para criar a ETL responsável por popular a dimensăo dim_produto com os dados do sistema transacional é necessário realizar um conjunto de passos. Inicialmente, crie uma transformaçăo e salve-a com o nome: “2-dim_produto”. Novamente, esta transformaçăo será responsável por manter todo o fluxo que definiremos a partir de agora de forma que possamos executá-la com maior agilidade.
O segundo passo é arrastar um componente Table input, dę o nome de “Lę produto” e selecione no combo Connection a conexăo para a base Origem. Este componente é utilizado para ler os dados do banco de dados, via SQL.
Em seguida, clique em Get SQL select statement, selecione com um duplo clique a tabela “produto” e entăo clique em Yes, para que o SQL seja montado com todos os nomes das colunas, ao invés de um simples, porém năo recomendado, “Select * from”. Faça um Preview dos dados e clique em OK.
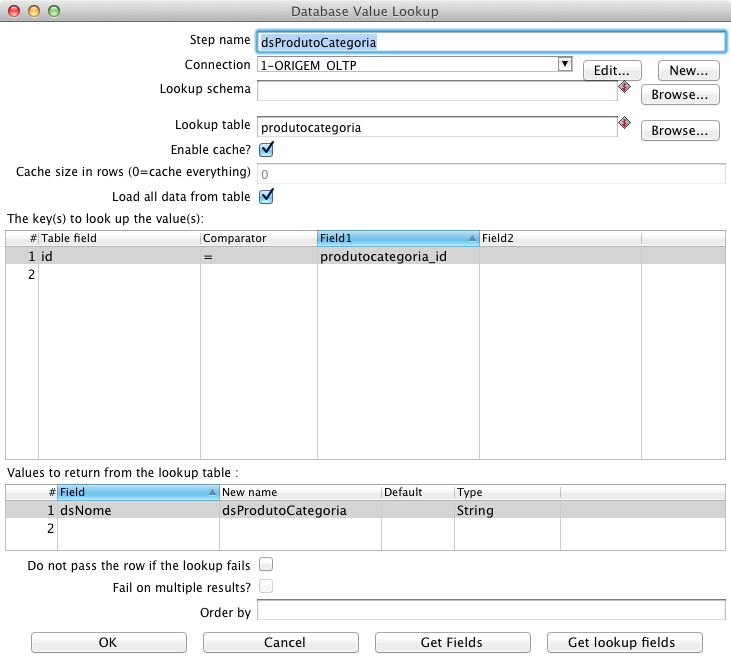
Para recuperar o nome da categoria de produtos a que este produto está relacionado, inclua no fluxo um step Database lookup, chame-o de “dsProdutoCategoria”, selecione a conexăo Origem e em Lookup table preencha com o nome da tabela em que se deseja fazer a consulta, “produtocategoria”. Em seguida, para habilitar o cache e carregar todo o conteúdo desta tabela em memória e, dessa forma, melhorar a performance, marque Enable cache e Load all data from table.
Na primeira tabela deste componente, The Keys(s) to lookup the value(s), indique os campos utilizados como chave neste lookup, equivalente ŕ cláusula Where de um SQL. Como indica a Figura 7, o campo Table field recebe “id” e o campo Field1 recebe “produtocategoria_id”, com Comparator “=”. Na segunda tabela deste componente, Values to return from the lookup table, săo indicados os campos que se deseja buscar no banco de dados e o nome que se deseja atribuir a eles. No caso, Field recebe “dsNome” e New name recebe “dsProdutoCategoria”.
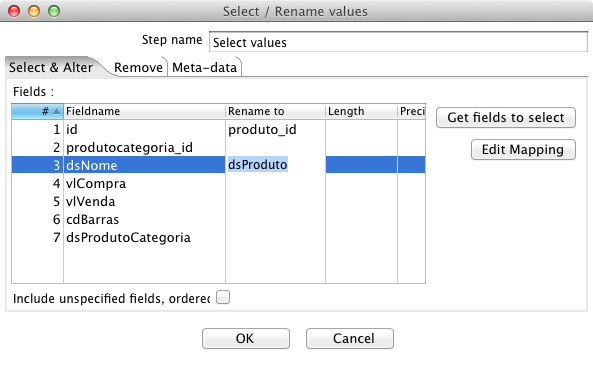
Na continuidade, inclua o step Select Values. Este step tem a finalidade de organizar o fluxo dentro do PDI, uma vez que é possível renomear as colunas, excluí-las do fluxo ou ainda alterar o seu tipo, precisăo e formato. Na primeira aba, chamada Select & Alter, clique em Get fields to select e em Clear and add all. Isto faz com que os nomes de todas as colunas sejam trazidos automaticamente, deixando os dados prontos para serem manipulados. Feito isso, renomeie a coluna “id”, para “produto_id” e “dsNome” para “dsProduto”, conforme a Figura 8. Na aba Remove, remova do fluxo as colunas “vlCompra”, “vlVenda” e “cdBarras” pois năo precisaremos delas e entăo clique em OK. Assim que o step for fechado, clique com o botăo direito em Show input fields e verifique os campos que entraram no fluxo. Por fim, clique em Show output fields e verifique os campos que saíram deste step e formam o resultset.
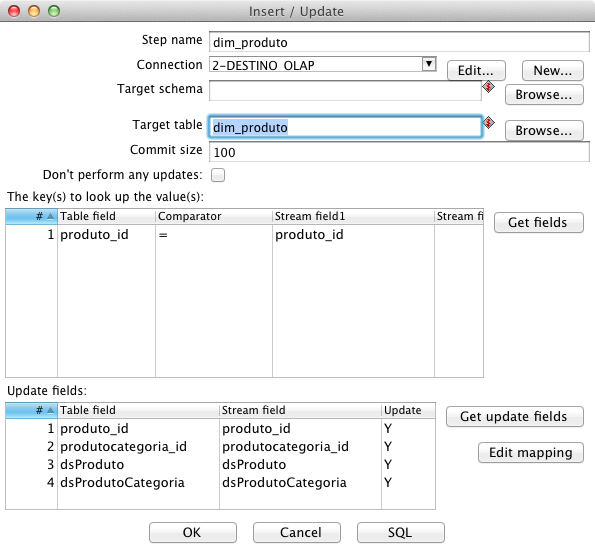
Superados os passos anteriores, todos os dados da base transacional referentes ao produto estăo prontos. Para salvá-los na base analítica, arraste o componente Insert/Update, que antes de fazer o insert verifica se o registro já existe na base. Caso exista, ele faz o update nos campos desejados. Para isso, edite o step, dę o nome de “dim_produto”, selecione a conexăo para a base Destino e em Target table preencha ou selecione em Browse o nome “dim_produto”. Da mesma forma que no componente de Database Lookup, na primeira tabela deste step, deve-se informar os campos-chave, no caso, “produto_id”. Na segunda tabela deste componente constam as colunas que farăo parte do Insert/Update. Observe a Figura 9.
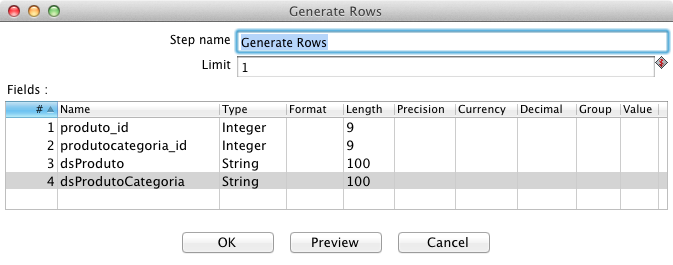
Como boa prática, é interessante que toda dimensăo tenha o seu primeiro registro com atributos sem valor, para que no momento da ETL da tabela fato, se porventura o lookup pelo id do produto falhar, o registro aponte para este registro default. Estes registros ficam persistidos no banco e evidenciam a falha nos dados, na lógica ou no processamento de alguma ETL, ficando mais fácil de perceber e corrigir a năo conformidade. Para isso, inclua um componente Generate Rows e gere uma linha, mas ao invés de ligá-lo ao final do fluxo da ETL, faça com que ele seja outra fonte de dados para o step “dim_produto”. Os nomes e tipos das colunas devem ser os mesmos e estar na mesma ordem que os campos observados em Show input fields do step Insert/Update, como expőe a Figura 10.
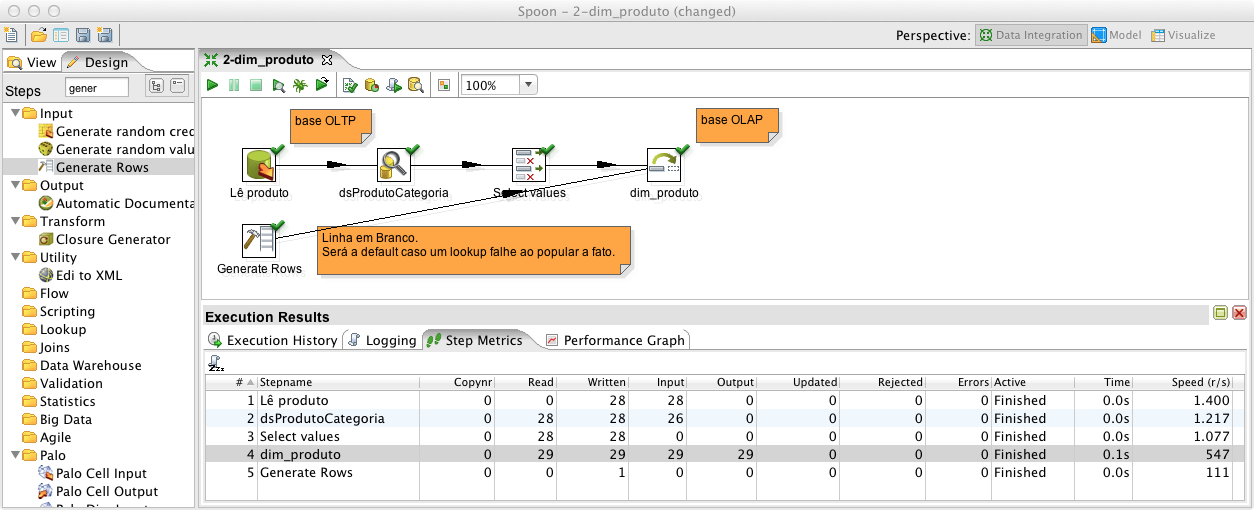
Por fim, execute a transformaçăo, que terá a aparęncia observada na Figura 11. Perceba nos dados da base analítica que o registro default com dados nulos, oriundos do step Generate Rows, foi incluído antes dos outros, com o valor da coluna “SK_dimProduto“ igual a 1. Caso esta ETL seja executada mais de uma vez, deixe o Generate Rows habilitado apenas na primeira, para que o insert/update năo gere uma linha em branco a cada execuçăo. Isto porque a condiçăo do lookup em “dim_produto” nunca será satisfeita e seria incluído um novo registro com valores nulos, pois por definiçăo, năo se pode comparar qualquer valor a valores nulos.
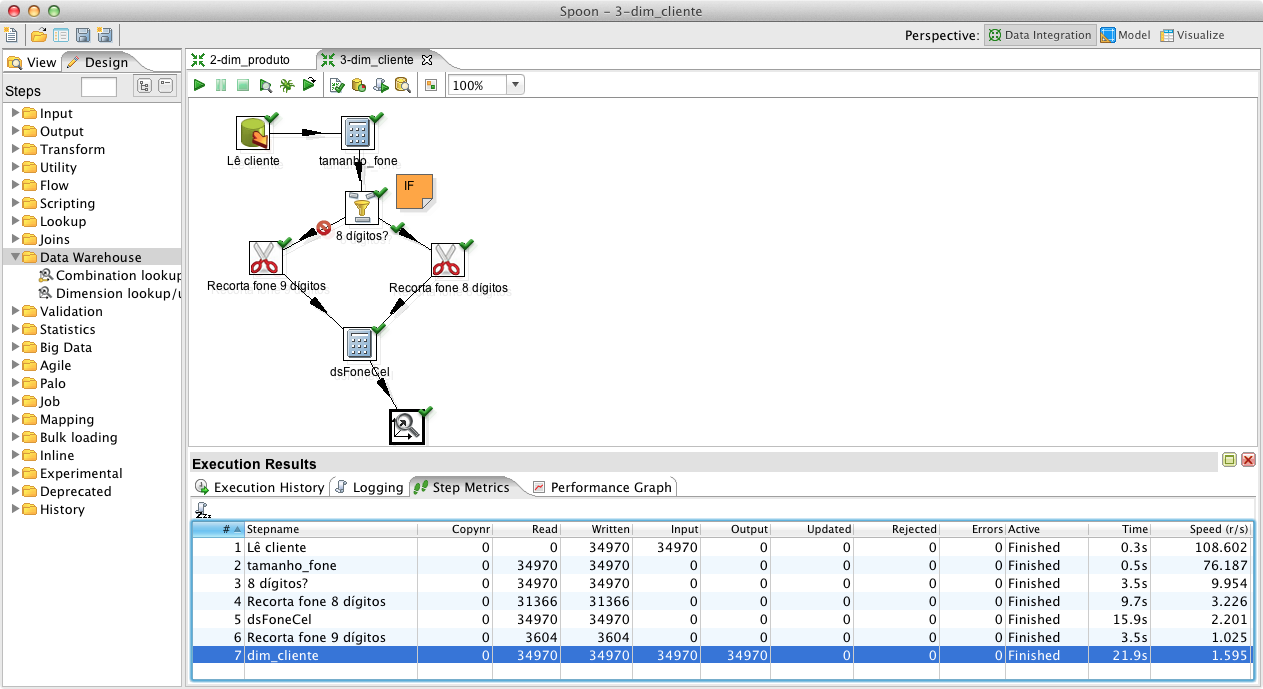
A partir dos requisitos e regras de negócio propostos neste case foi definido que a dimensăo dim_cliente tem a necessidade de que seus dados sejam versionados e que uma nova coluna seja criada, concatenando o DDD com o telefone no seguinte formato: (99) 9999-9999 ou (99) 99999-9999, dependendo se o telefone conta com 8 ou 9 dígitos. Para popular esta dimensăo com os dados do sistema transacional, inicialmente crie uma transformaçăo e salve-a com o nome: “3-dim_cliente”.
Com a transformaçăo definida, arraste um componente Table input, dę o nome de “Lę cliente”, selecione a conexăo para a base Origem em Get SQL select statement e aponte para a tabela cliente, trazendo os nomes de suas colunas. Para fins de conferęncia, clique em Preview, visualize os dados obtidos e feche o step.
Para converter o inteiro “nrCelular” na string “dsCelular“, inclua o componente Calculator e crie uma linha para a primeira variável, chamada, em New field, de “dsCelular”. Em Calculation, selecione Create a copy of field A. Depois, em Field A, selecione “nrCelular”, em Value type selecione string, em Length preencha “9” e em Conversion mask preencha com “#”. Para descobrir a quantidade de dígitos do número do telefone celular, crie uma linha para a segunda variável, a coluna “tamanho_fone”, em Calculation selecione Return the length of a string A, em Field A selecione “dsCelular” e em Value type selecione Integer, conforme a Figura 12.
Visando distribuir o fluxo da ETL e recuperar o prefixo do telefone conforme a quantidade de caracteres, de 8 ou 9 dígitos, inclua o step Filter rows e chame-o de “8 digitos?”. Ele é o famigerado if que toda linguagem de programaçăo precisa ter. De acordo com uma condiçăo, o fluxo segue para um ou outro lado. Ainda neste step, em The condition, selecione nos tręs campos da condiçăo a ser imposta os valores “tamanho_fone”, “=” e “8”. Caso esta condiçăo seja verdadeira, o fluxo segue para o step que estiver selecionado em Send ‘true’ data to step, caso contrário, o fluxo segue para o step selecionado em Send ‘false’ data to step. Assim que os próximos steps forem ligados ao Filter rows, o PDI perguntará se o fluxo é para a condiçăo verdadeira ou para a falsa.
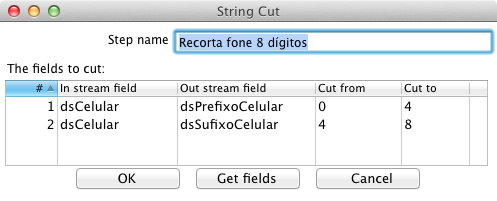
A meta agora é separar o prefixo do sufixo do número do telefone celular de 8 dígitos. Para isto, inclua o componente Strings cut com o nome “Recorta fone 8 dígitos”, ligando-o ao step Filter rows, criado no passo anterior, definindo que este caminho deve ser percorrido caso a condiçăo definida seja verdadeira. De modo semelhante ŕ Figura 13, crie duas novas colunas, a partir de “dsCelular”, chamadas “dsPrefixoCelular” e “dsSufixoCelular”. A primeira recebe o valor referente ŕ substring da posiçăo 0 até a 4, enquanto a segunda recebe o valor referente ŕ substring da posiçăo 4 até a 8.
Duplique o step criado no passo anterior a partir dos simples comandos de copiar e colar. Feito isto, ligue o step criado ao step Filter rows, adicionado no passo 4 deste tópico, definindo que é para ser seguido caso a condiçăo definida seja falsa. Chame-o de “Recorta fone 9 dígitos” e altere os valores para que o prefixo receba valores dos caracteres 0 a 5, enquanto o sufixo, dos caracteres 5 a 9.
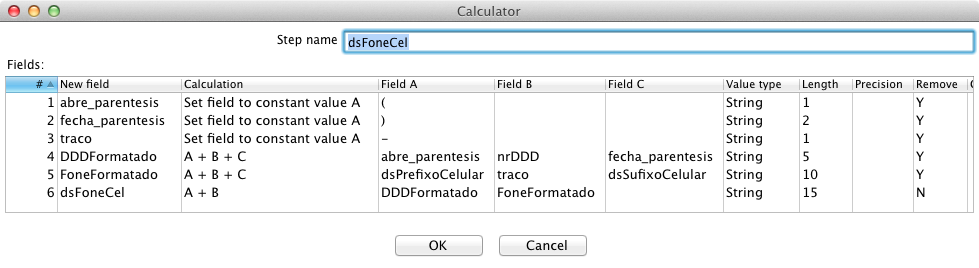
A última tarefa é criar a nova string, concatenando as strings extraídas. Deste modo, inclua um novo step Calculator, ligue-o ao fluxo do fone de 8 dígitos e preencha como na Figura 14. Repare que foram criadas duas constantes, “abre_parentesis” com o valor “(“ e “fecha_parentesis” com o valor “) ”, com um espaço após o paręntese para facilitar a criaçăo da string “dsFoneCel”, com o número de telefone formatado.
Um recurso interessante do PDI é fazer com que esses dois fluxos criados, após o step Filter Rows, convirjam em um único step, unificando o fluxo dos dados na ETL. Isto só será possível, no entanto, se o resultset dos dois fluxos tiverem as colunas com o mesmo nome, na mesma ordem e com o mesmo tipo de dados. Para unificar o fluxo dos dados, faça o link do step “Recorta fone 9 dígitos” criado no item 6 deste tópico e vincule-o ao Calculator criado no item 7.
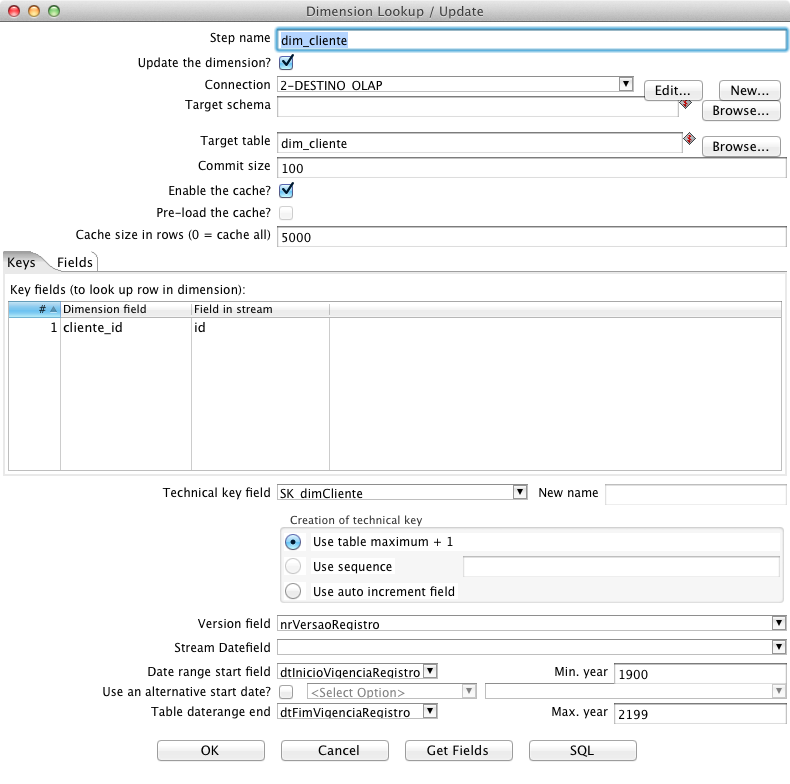
Com a finalidade de persistir os dados na SCD, isto é, uma dimensăo com versionamento dos dados, o step chamado Dimension lookup/update é necessário. Assim, inclua este step e chame-o de dim_cliente, selecione a conexăo de Destino e informe dim_cliente em Target table. Da mesma forma que foi feito nos steps de lookup, e Insert/Update, na aba Keys, deve-se informar os campos chave desta informaçăo, que identificam o registro na base transacional. Neste caso, em Dimension field deve-se selecionar a coluna da base OLAP, cliente_id, e, em Field in stream, a coluna da base OLTP, id. Logo abaixo da aba Keys, em Technical key field, selecione a surrogate key SK_dimCliente, em Version field clique em nrVersaoRegistro, em Data range start field selecione dtInicioVigenciaRegistro e em Table daterange end clique em dtFimVigenciaRegistro, como demonstra a Figura 15. Com estas informaçőes o PDI tem subsídios para fazer o versionamento das informaçőes de maneira automatizada, ajustando os valores do número da versăo e das datas início e fim de vigęncia dos registros.
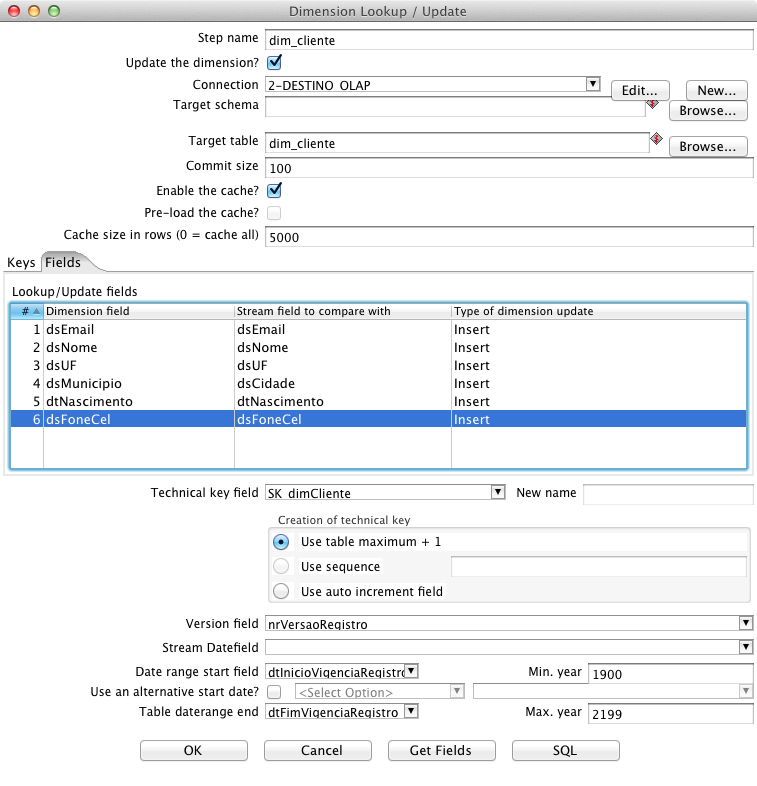
Na segunda aba, chamada Fields, faz-se o mapeamento das colunas afetadas versus as colunas do resultset. Uma terceira coluna, chamada Type of dimension update, exige um dos dois valores, Insert ou Update, para configurar a açăo que o componente executará ao verificar o valor destes campos na dimensăo dim_cliente. Na primeira situaçăo, caso o registro tenha sofrido alteraçăo com relaçăo ao valor já gravado no banco, um novo registro será inserido com o número da versăo acrescido em um. No segundo caso, o valor é simplesmente sobrescrito. Confira o mapeamento na Figura 16.
Implementados os passos anteriores, execute a transformaçăo, que se parecerá com a da Figura 17. Neste case, executado em um notebook pessoal com recursos limitados, foram lidas, transformadas e incluídas 34.970 linhas em 21 segundos. Para finalizar a ETL desta dimensăo, verifique os dados obtidos e perceba que o componente Dimension lookup/update cria automaticamente o registro com valores nulos.
Dando continuidade ŕ criaçăo das ETLs, as dimensőes dim_vendedor e dim_notafiscal devem ter seus dados populados, seguindo exatamente as mesmas técnicas vistas nos tópicos anteriores. Com o intuito de ganhar produtividade, reaproveite o trabalho já criado nas primeiras ETLs para popular as dimensőes restantes. Por exemplo, para iniciar o desenvolvimento da ETL de Vendedor, salve com outro nome a de Cliente, pois săo muito semelhantes. De igual forma, para agilizar a criaçăo da transformaçăo responsável por migrar as Notas Fiscais, salve com outro nome a ETL de Vendedor e faça as adaptaçőes necessárias. Todas as transformaçőes estăo disponíveis no site da SQL Magazine.
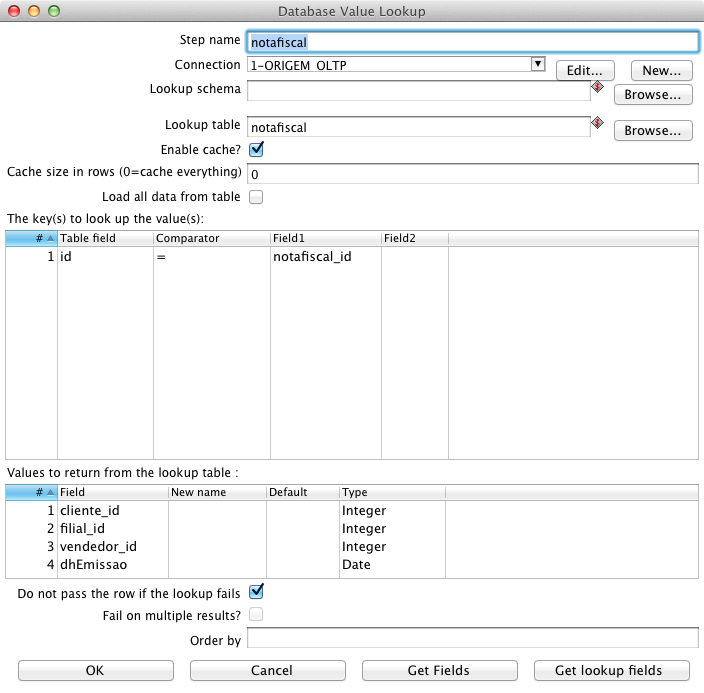
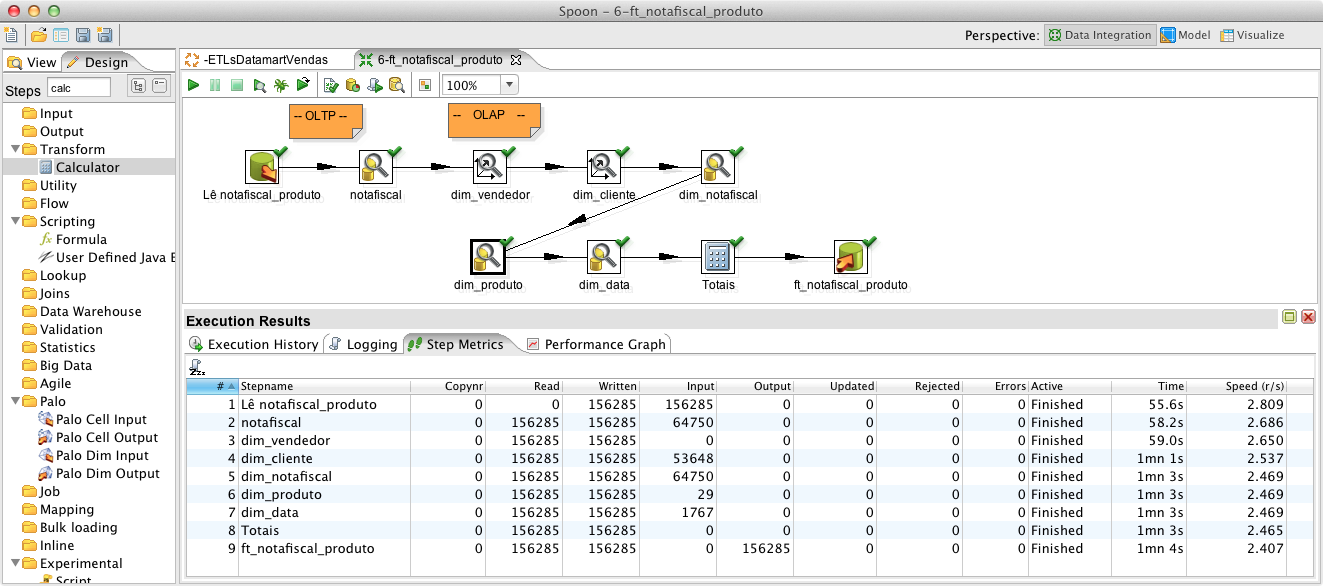
A fato é a tabela central em um esquema estrela, contendo em sua chave primária as chaves estrangeiras para todas as Dimensőes e em seus atributos as colunas referentes ŕs Medidas. Esta tabela é a mais importante de um cubo, pois é com base nela que o servidor de BI faz todos os cálculos, como será explicado no tópico “Modelo Lógico – Metadados do Schema”. Para preenchę-la com os dados do sistema transacional, de forma semelhante a como procedemos anteriormente, crie uma transformaçăo e salve-a com o nome: ”6-ft_notafiscal_produto”. Assim como foi feito nos exemplos anteriores, arraste um componente Table input, dę o nome de notafiscal_produto, selecione a conexăo para a base Origem e busque todas as colunas. Isto permitirá que vocę manipule as informaçőes. Em seguida, acrescente ao fluxo o componente Database lookup e recupere as colunas de notafiscal da base Origem, conforme a Figura 18.
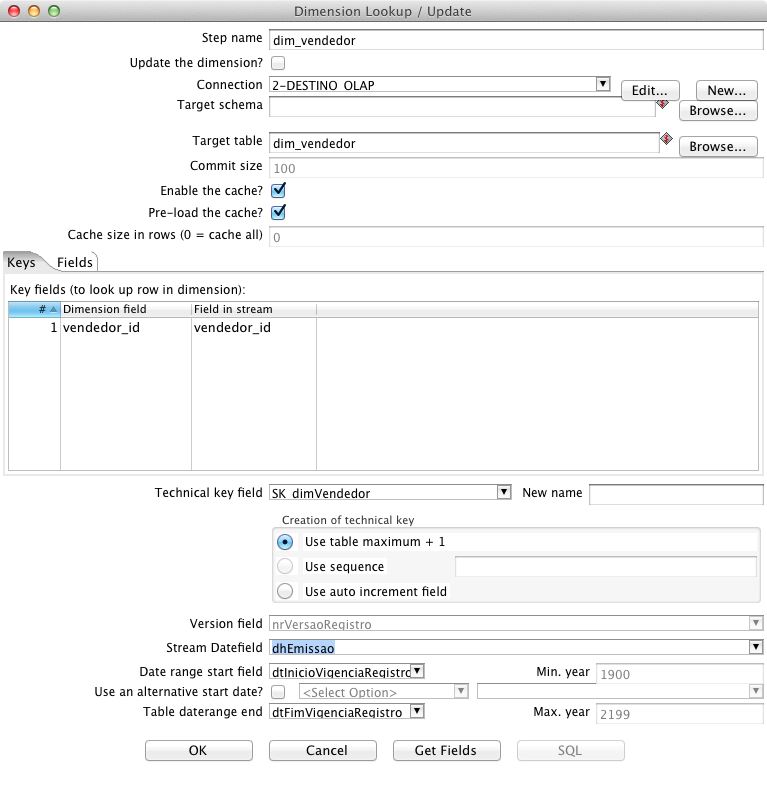
Nesta etapa do processo, os ids utilizados na base transacional já foram obtidos, sendo necessária a busca dos ids correspondentes nas respectivas dimensőes da base analítica. A recuperaçăo da chave do registro na dimensăo, a SK, é feita normalmente com o componente Database lookup, entretanto o lookup nos casos de dimensőes SCD, que tęm seus dados versionados, exige uma atençăo especial, uma vez que se deve recuperar o id do registro vigente na data em que ocorreu cada fato, e năo o registro vigente no momento da execuçăo do processo.
A maneira mais simples de fazer o lookup em uma dimensăo SCD é incluir um step Dimension lookup/update, que como o próprio nome diz, pode ser utilizado tanto para persistir quanto para fazer o lookup em uma dimensăo SCD. Para o lookup, somente é necessário preencher a primeira aba, de acordo com a Figura 19. É importante ater-se ao campo Stream Datefield, que deve receber o nome da coluna com a data do fato. Este step retorna o valor da chave da dimensăo em questăo, marcada em Technical Key Field, neste caso SK_dimVendedor.
Para recuperar a chave do registro nas outras dimensőes, crie o step Dimension lookup/update para a dim_cliente, que é SCD, e os steps Database lookup para as dimensőes simples dim_notafiscal, dim_produto e dim_data. Nos lookups de notafiscal e produto, lembre-se de deixar o valor um como default para evidenciar a falha caso năo encontre o registro, e no lookup da data, o default, neste caso, seria “20080101”.
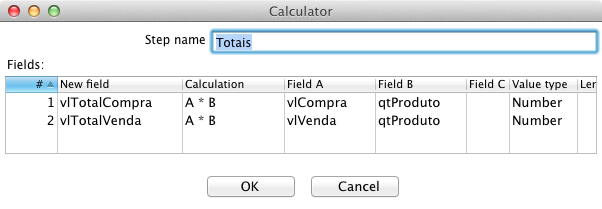
Antes de gravar os dados, deve-se avaliar se o cubo será insumo para análises que levarăo em conta, na maioria das vezes, o valor total de compra e venda, ou seja, o valor multiplicado pela quantidade de produtos, ou se será mais comum a necessidade de obter estatísticas levando em conta a quantidade vendida de cada produto em uma nota fiscal. Para este case, entendeu-se que a quantidade é de menor importância, entăo o processo deve agilizar ao máximo as pesquisas referentes aos valores totais. Para isto, as colunas de valor serăo persistidas já multiplicadas pela quantidade vendida. Estes cálculos, como será visto na continuidade, podem ser feitos no cubo por meio de Calculated Members, com uma fórmula entre as colunas físicas existentes, dando origem a um valor calculado, sem a necessidade de tę-los como atributo da tabela fato. Assim, inclua um step Calculator, conforme a Figura 20.
Para persistir os dados da tabela fato ft_notafiscal_produto, acrescente o componente Table output. Também poderia ser utilizado o step Insert/Update para esta tarefa. Por fim, execute a transformaçăo e migre 156 mil linhas em pouco mais de um minuto, como demonstra a Figura 21. Esta seria tanto a carga inicial quanto a ETL diária, lembrando que em um ambiente de produçăo, devem ser lidos apenas os registros incluídos ou alterados após o último processo de ETL, tornando o processo ainda mais rápido.
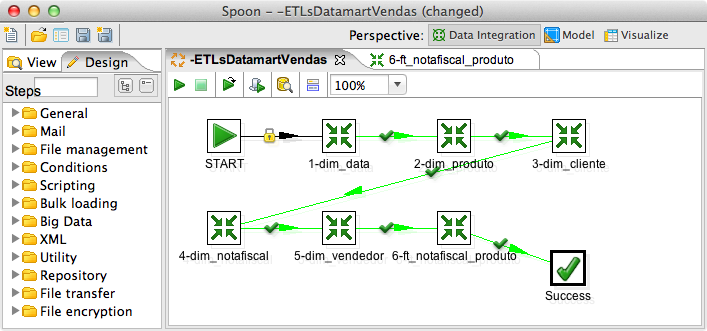
Para executar várias transformaçőes na sequęncia correta e dispará-las através de uma única açăo, o PDI conta com a funcionalidade dos Jobs, apresentada na Figura 22. Além disso, os Jobs podem executar tarefas de gerenciamento de arquivos, de FTP, de envio de e-mails em caso de sucesso ou, em caso de falha, enviar, por e-mail, os arquivos de log gerados pelo Pentaho. É bastante utilizado também para executar SQLs e outras atividades muito úteis como a possibilidade de se verificar se uma tabela já existe, para que o processo entăo a crie automaticamente ou confirmar se determinado web service está no ar antes de executar determinada açăo.
Os Jobs, bem como as transformaçőes, podem ser chamados a partir da linha de comando (pelos componentes Pan e Kitchen), via HTTP (pelo Carte), pelas interfaces web (PUC e PAC) ou ainda, executados automaticamente em horário e periodicidade configuráveis, por meio de um BI-Server, que terá algumas das suas principais funcionalidades brevemente descritas a seguir.
O BI-Server refere-se, como o próprio nome diz, ŕ camada servidora da Suíte Pentaho, que é composta pelo Pentaho User Console (PUC) e pelo Pentaho Administrator Console (PAC). Juntos, săo responsáveis pela segurança e regras de negócio, sendo constituídos por diversos componentes. Os principais săo: o Tomcat, como servidor de aplicaçăo para o PUC; o Jetty, como servidor light de aplicaçăo para o PAC; o Hibernate, para o mapeamento objeto-relacional; o Hypersonic, como SGBDR; o Quartz, para agendamentos de processos; e o Spring, como framework de desenvolvimento Java. O PUC conta ainda com as bibliotecas de todas as ferramentas da suíte, como o PDI, Pentaho Analysis Server (Mondrian OLAP Server), Pentaho Report Designer (JFreeReport) e Pentaho Data Mining (Weka).
Como todos os componentes săo de código aberto e amplamente difundidos no mercado, a configuraçăo é simples e as possibilidades de adaptaçőes săo ilimitadas. Um recurso importante é a integraçăo com autenticadores sigle sign-on (SSO) de usuários como LDAP, Active Directory ou com aplicaçőes Java via Spring.
Outro recurso importante para viabilizar o trabalho em equipe e facilitar a manutençăo das ETLs é a possibilidade de armazená-las em um repositório Pentaho no banco de dados ao invés de, como feito neste artigo, armazená-las em arquivos. Para criar este repositório, basta acessar no PDI o menu Tools > Repository > Connect. Em Repository, clique no botăo com o sinal de + e crie a configuraçăo para o repositório a ser criado. Em seguida, selecione Kettle database repository, configure a conexăo com o SGBDR desejado, dę um nome para o repositório e, por fim, clique em Create or Upgrade. O repositório será criado e estará pronto para armazenar todo o processo de ETL, bastando para isso conectar-se a ele pelo PDI.
Para que o BI-Server também possa acessar as ETLs deste repositório, útil para a futura automatizaçăo da execuçăo dos processos, após executado o passo 1 deste tópico, deve-se configurar o arquivo biserver-ce/pentaho-solutions/system/kettle/settings.xml, alterando o repository.type de “files” para “rdbms”, incluindo em repository.name o nome com que o repositório foi criado e ajustando, caso necessário, o usuário do repositório, em repository.userid, e sua senha, em epository.password.
Para instalar e configurar o BI-Server, inicialmente faça o download da última versăo do BI-Server, que na escrita deste artigo é a 4.8.0-stable, no endereço indicado na seçăo Links e efetue a configuraçăo do servidor da mesma forma que foi indicada para o PDI, simplesmente descompactando o arquivo .zip. Repare que foram criadas duas pastas, sendo uma para o PAC e outra para o BI-Server e o PUC. Para que o BI-Server tenha acesso ŕs bases de dados envolvidas, complete a configuraçăo incluindo o driver JDBC, mencionado na primeira parte deste artigo no tópico “Drivers JDBC”, em bi-server-ce\tomcat\lib.
Dependendo do sistema operacional do servidor, execute o BI-Server simplesmente clicando em start-pentaho.bat ou via linha de comando, executando /start-pentaho.sh. A soluçăo pode ser acessada pelo endereço http://localhost:8080 utilizando o usuário padrăo joe e a senha password. Após a conexăo estabelecida, altere o idioma do PUC pelo menu View > Languages > Portuguęs Brasil, e pelo menu Visualizar > Navegador, torne visível a parte esquerda da tela, onde é possível navegar pelas pastas com as soluçőes criadas e disponibilizadas ao usuário final. Para armazenar os arquivos deste case, clique com o botăo direito do mouse nesta área e em Nova Pasta crie uma pasta chamada SQLMagazine.
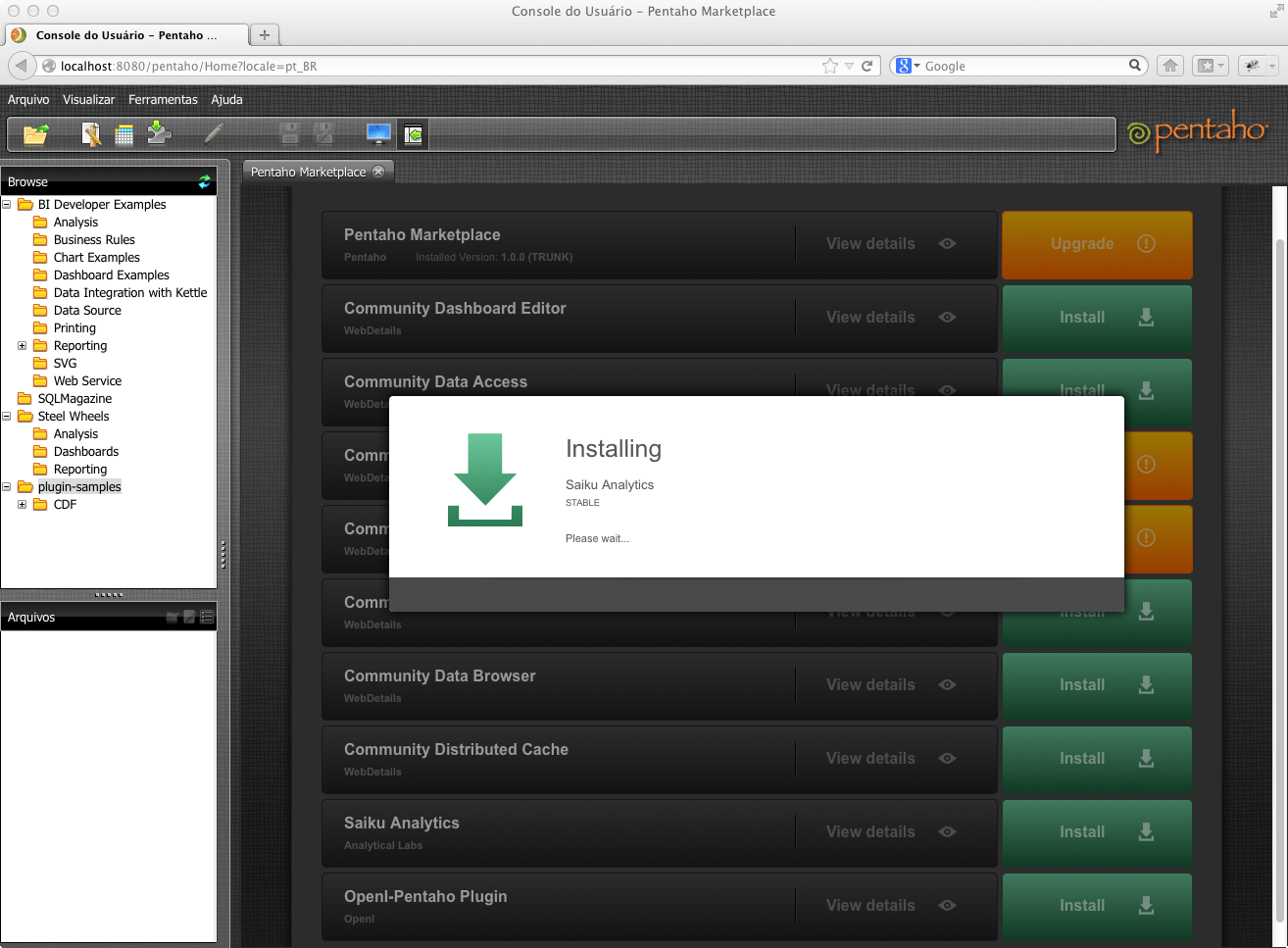
Ainda no PUC, para incluir no BI-Server um navegador OLAP feito com jQuery, acesse o menu Ferramentas > Pentaho Market Place e instale o plugin Saiku Analytics, clicando no botăo Install correspondente, tal como se visualiza na Figura 23.
Para publicar no BI-Server schemas ou reports por meio de suas respectivas ferramentas Pentaho Schema Workbench e Pentaho Report Designer, deve-se informar a senha de publicaçăo cadastrada no arquivo biserver-ce/pentaho-solutions/system/publisher_config.xml, como demonstra a Listagem 1. Neste caso, a senha foi definida como 1234, sem criptografia.
Listagem 1. Configurando a senha para publicaçőes.
<publisher-config>
<publisher-password>1234</publisher-password>
</publisher-config>Para facilitar toda a configuraçăo das fontes de dados, o Pentaho trabalha com conexőes JNDI. Isto quer dizer que é dado um nome para a configuraçăo criada para a conexăo com o banco e as ferramentas da suíte podem utilizá-la. A administraçăo destas conexőes é feita pela interface do PAC e permite que a aplicaçăo de homologaçăo năo precise de nenhuma alteraçăo quando passar para o ambiente de produçăo, pois as conexőes terăo o mesmo nome, porém apontando para bases distintas.
Para seguir com a criaçăo de uma conexăo JNDI no BI-Server, necessária para que o cubo a ser criado tenha acesso ŕ base de dados analítica, inicie o serviço do PAC de acordo com o SO executando administration-console\start-pac.bat ou administration-console/start-pac.sh. Este serviço é provido pelo servidor light de aplicaçőes Jetty, que pode ser acessado pelo mesmo endereço que o BI-Server na porta 8099. Neste case, o serviço do Pentaho Administrator Console está disponível no endereço http://localhost:8099/ através do usuário admin e da senha password. Pela interface do PAC săo gerenciados, na primeira aba, Users & Roles, os Usuários e seus Grupos, enquanto na segunda aba, Databases Connections, săo gerenciadas as conexőes JNDI. Na terceira aba, Services, o cache de diversos serviços é administrado, enquanto que na quarta e última aba, Scheduler, săo gerenciados os processos agendados.
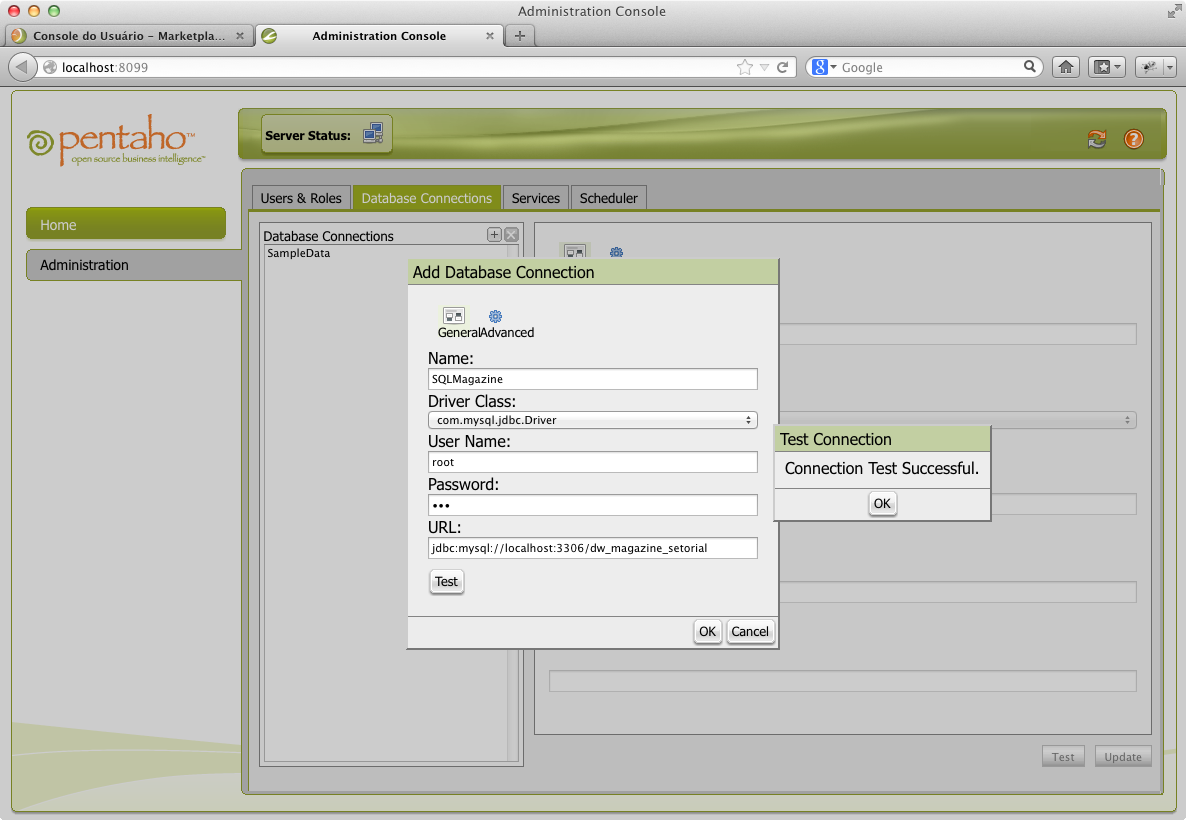
Para criar a conexăo JNDI (vide Figura 24), clique em Database Connections e adicione uma conexăo com o nome “SQLMagazine”. De acordo com o driver JDBC instalado, selecione em Driver Class com.mysql.jdbc.Driver e preencha a URL com a string de conexăo JDBC jdbc:mysql://localhost:3306/dw_magazine_setorial, que foi criada obedecendo ao formato: jdbc:SGBDR:endereço: porta/database.
Vencidas as etapas anteriores, os dados do datamart de “Vendas” estăo prontos para serem visualizados em um cubo multidimensional, restando apenas as tarefas de criar e publicar a camada de metadados, necessária para que o servidor OLAP, o Mondrian, possa converter adequadamente as queries multidimensionais MDX em diversas queries SQL ANSI, se utilizando de suas funçőes de agregaçăo como group by, sum, count, max, min, avg, etc., submetendo-as, posteriormente, ao banco de dados. É dentro deste servidor OLAP que săo gerenciados, por exemplo, os cálculos necessários para a extraçăo das informaçőes geradas pelo cubo, feitos a partir das Medidas elencadas nesta modelagem, as quais se referem a atributos da tabela fato, central no esquema estrela.
A camada de metadados possibilita que sejam usados nomes mais intuitivos e fáceis de serem compreendidos pelos usuários, que năo estăo habituados com a nomenclatura utilizada em um banco de dados. Além disso, faz parte desta modelagem, embora năo seja foco deste artigo, o controle de acesso ao Schema, determinando a visibilidade de cubos, dimensőes, hierarquias e medidas por usuários e grupos de usuários.
Esta modelagem lógica nada mais é que um arquivo no formato XML, responsável pelo mapeamento da estrutura física e pela definiçăo do formato em que as informaçőes deverăo ser apresentadas. Este mapeamento contém um Schema, que por sua vez pode ser composto por vários Cubos. Neste case, temos o Schema “Vendas” e o cubo de “Produtos Vendidos”, recordando que um cubo é formado por uma tabela fato, diversas dimensőes e ao menos uma medida. Para contemplar todos os requisitos deste case, serăo necessárias as dimensőes Cliente, Vendedor, NotaFiscal, Produto e Data, além das medidas Quantidade, Valor Compra, Valor Venda e da medida calculada Valor Lucro.
Vale registrar que toda dimensăo terá uma ou mais hierarquias, que servem para criar agrupamentos. Neste case, teremos hierarquias em Vendedor, com os níveis Filial e Vendedor e em Produto, com níveis para Categoria e Produto. Seguindo os mesmos princípios, os Clientes poderiam estar agrupados por UF, criando-se uma hierarquia com os níveis UF e Cliente.
A ferramenta da suíte que auxilia na criaçăo do XML do esquema é o Pentaho Schema Workbench (PSW). Para criar a parte lógica do cubo, faça o download da última versăo, atualmente a 4.4.0, no endereço indicado na seçăo Links e proceda a configuraçăo, tal como realizado com o PDI. É necessária também a cópia do .jar do JDBC e a criaçăo da conexăo para a base analítica, conforme vistos no tópico “Download, Instalaçăo e Configuraçăo do PDI”, na primeira parte deste artigo. Esta ferramenta está disponibilizada no Sourceforge, dentro do projeto Mondrian, ao invés de estar na suíte Pentaho. Isto porque ela é utilizada por outras ferramentas de Open Source Business Intelligence (OSBI).
Finalizada a configuraçăo do PSW, é necessário criar e publicar no BI-Server o arquivo com os metadados do cubo Vendas. Para isso, crie um Schema e salve-o com o nome “SQLMagazine.xml”, e, entăo, na parte superior esquerda da tela do PSW, clique em Schema e no campo name, ao lado direito da tela, preencha com o nome “Vendas”.
Em seguida, clique com o botăo direito em Schema e entăo em Add Cube. Clique no cubo criado e dę o nome de “Produtos Vendidos”. Para entender melhor o que está acontecendo, a cada passo aqui elencado, verifique o fonte do arquivo gerado com o nome SQLMagazine.XML. É recomendada a utilizaçăo de uma ferramenta especializada em ediçăo de arquivos XML, com realce de sintaxe, o que facilita a descoberta de năo conformidades no código.
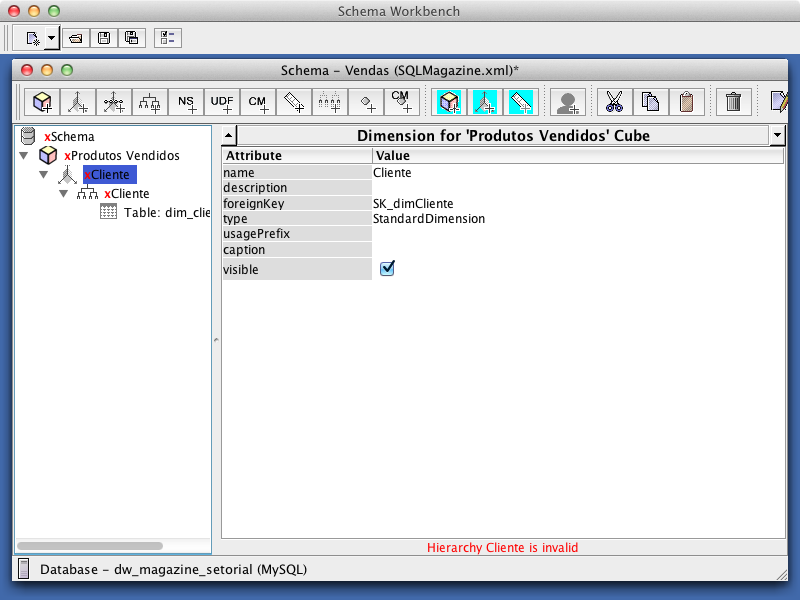
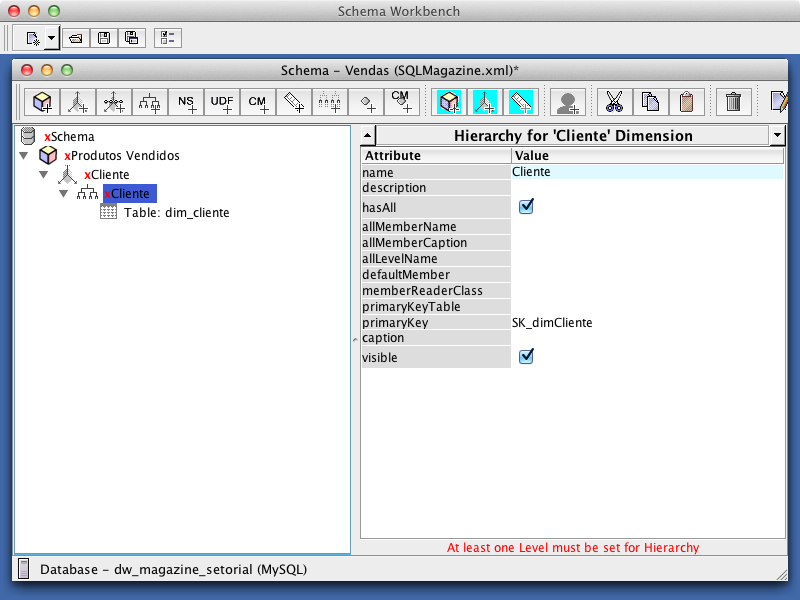
Para criar a dimensăo Cliente, clique com o botăo direito no cubo e entăo em Add Dimension. Logo após, clique na dimensăo criada e dę o nome de “Cliente”. Na sequęncia, para incluir a hierarquia Cliente na dimensăo de mesmo nome, clique com o botăo direito nesta dimensăo e entăo em Add Hierarchy, dando a esta o nome de “Cliente”. Para vincular a dimensăo do cubo com a tabela do banco de dados, clique com o botăo direito na hierarquia criada e depois em Add Table, selecionando em name, a tabela dim_cliente.
Continuando o vínculo da dimensăo com a tabela correspondente, clique na dimensăo Cliente e selecione em foreignKey a coluna SK_dimCliente, conforme a Figura 25. Em seguida, siga o mesmo procedimento que o item anterior, clicando na hierarquia Cliente, mas no campo primaryKey, conforme a Figura 26.
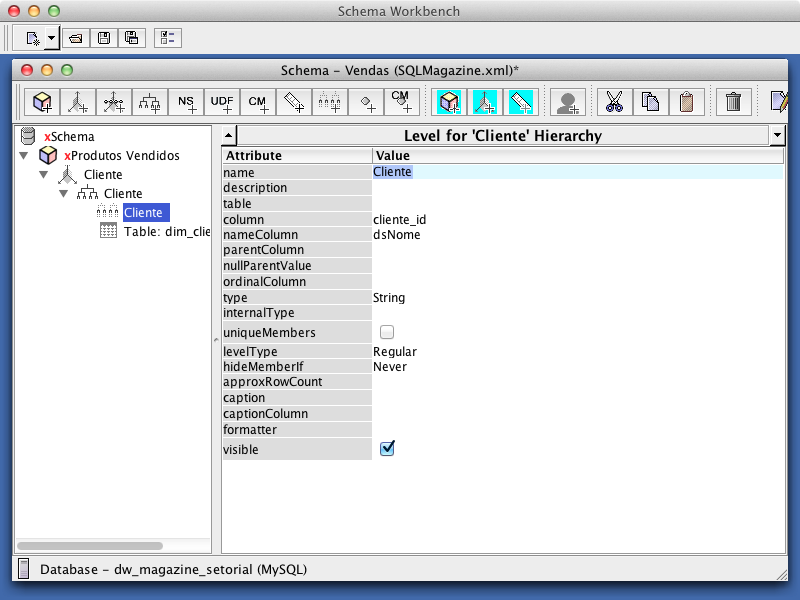
Para adicionar o nível da hierarquia Cliente, clique com o botăo direito nesta hierarquia e em Add Level. Em column, selecione “cliente_id” e em nameColumn, selecione “dsNome”, como mostra a Figura 27. Repare que o fato de indicar qual é a coluna chave faz com que as dimensőes SCD tenham o mapeamento igual ŕs dimensőes simples. Para que o mapeamento seja considerado funcional, a sua tabela fato deve ser definida, como alertado ao clicar no cubo Produtos Vendidos, pela mensagem apresentada em vermelho “Fact name must be set”.
Para incluir a tabela fato no mapeamento, clique com o botăo direito sobre o cubo Vendas, em Add Table e em name, selecione “ft_notafiscal_produto”. Feito isso, a mensagem de erro ao clicar no cubo passa a ser “Cube must contain mesures”, indicando que faltam informaçőes sobre as Medidas para que o mapeamento seja considerado válido.
Com a finalidade de incluir as Medidas, clique com o direito no cubo Vendas. Em Add Measure inclua a Medida com o nome “Quantidade” e, em aggregator, selecione “sum”, em column, “qtProduto” e em datatype, “integer”. Siga o mesmo procedimento para criar as Medidas “Valor Compra” e “Valor Venda”, com a diferença que estes últimos tęm Numeric como datatype e totalizam, respectivamente, as colunas “vlCompra” e “vlVenda”. Perceba, neste momento, que o mapeamento está funcional, pois a mensagem de alerta se apagou.
Com o intuito de criar a medida calculada que informará o lucro obtido, que năo está persistido no banco de dados, clique com o botăo direito no cubo “Produtos Vendidos” e em Add Calculated Member. Em name, preencha com “Valor Lucro” e em formula|formulaElement, insira a fórmula “[Measures].[Valor Venda] - [Measures].[Valor Compra]”.
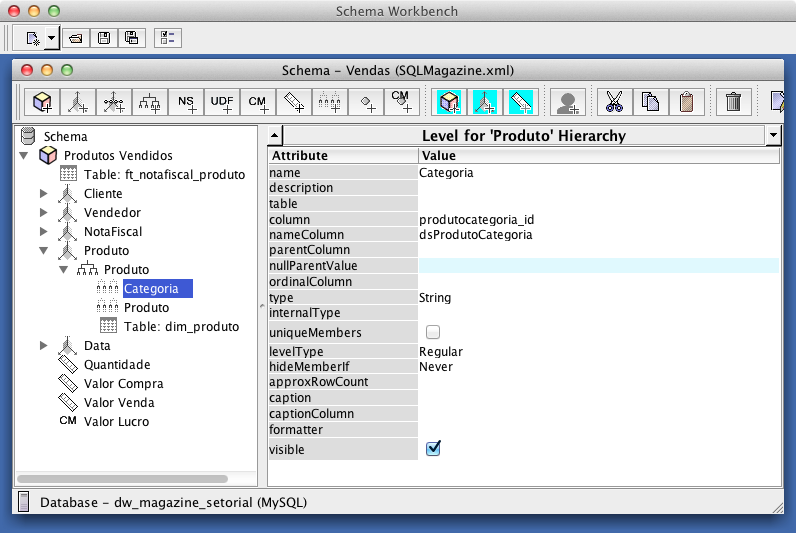
Para criar a dimensăo Vendedor, siga os passos de 3 a 7 deste tópico, com a diferença de que esta terá uma hierarquia e dois níveis, um para a Filial e outro para o Vendedor. Desta forma, os vendedores de uma filial estarăo sempre agrupados. Continue seguindo os mesmos passos do mapeamento da dimensăo Vendedor e crie a camada lógica para a dimensăo dim_produto, que terá um nível para Categoria e outro para Produto. Crie também a camada lógica para a dimensăo dim_notafiscal, que terá um único nível na hierarquia. Observe a Figura 28.
Finalizando o mapeamento, crie a dimensăo de nome “Data” com o valor de type igual a TimeDimension, ao invés do valor default StandardDimension e entăo inclua a hierarquia chamada Data, que possui em seu primeiro nível o Ano, com LevelType igual a TimeYears. Os níveis Trimestre, Męs e Dia seguem a mesma lógica, alterando o valor de LevelType para TimeQuarters, TimeMonths ou TimeDays, respectivamente. Isto permite ao BI-Server uma perfeita representaçăo dos dados temporais, dentro de uma timeline.
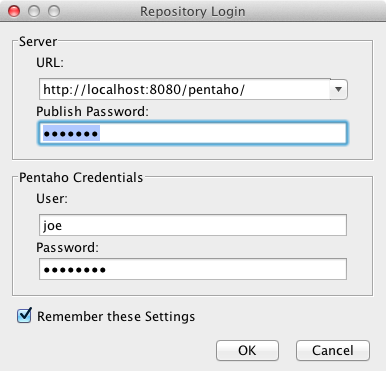
Para publicar os metadados no BI-Server, clique em Publish no menu File do PSW e insira os dados de publicaçăo, de acordo com a Figura 29. Em Publish Password, insira a senha configurada na Listagem 1, informe o usuário default joe, a senha password e clique em Ok.
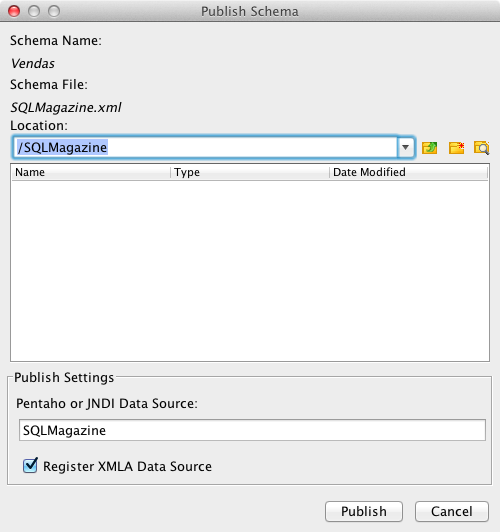
Finalizando a publicaçăo dos metadados, na tela que será aberta, selecione a pasta em que deseja salvar o XML, neste case a pasta SQLMagazine, criada no passo 2 do tópico “Instalando o BI-Server”. Como apresenta a Figura 30, em Pentaho or JNDI Data Source, preencha com o nome da conexăo criada no PAC, demonstrada no item 5 do tópico “Instalando o BI-Server”, e marque a opçăo Register XMLA Data Source. Isto faz com que o PSW, além de copiar o XML para o local especificado, também registre automaticamente no Mondrian que este Schema foi mapeado, em biserver-ce/pentaho-solutions/system/olap/datasources.xml. Por fim, clique em Publish e aguarde a mensagem Published Successful.
Após a publicaçăo dos metadados é necessário fazer um refresh no cache do Mondrian e para isto algumas alternativas estăo disponíveis. Uma destas alternativas é, dentro do PUC, pelo menu Ferramentas > Atualizar > Mondrian Schema Cache. O mesmo resultado pode ser obtido dentro do PAC, na aba Services > Refresh BI Server, clicando no botăo Mondrian Cache.
Encerrados os passos anteriores, o schema está publicado e disponível para que as análises sejam feitas, demonstrando o potencial que uma aplicaçăo de Business Intelligence oferece. Entretanto, para isso, é necessária a utilizaçăo de uma ferramenta OLAP, que permite “navegar” no cubo e criar análises multidimensionais.
Na atual versăo livre do Pentaho, em sua instalaçăo default, o navegador OLAP disponível é o JPivot. Entretanto, este navegador é tido como deprecated, e năo estará disponível nas próximas versőes da suíte. Diante disso, como alternativa, será utilizado neste case o plugin Saiku Analytics, que é um navegador OLAP mais atrativo e funcional. Cabe registrar que a versăo paga do Pentaho conta com o Pentaho Analysis, um navegador OLAP ainda mais completo.
Caso o Pentaho apresente um comportamento inesperado quando os passos elencados adiante forem seguidos, leia o que o log descreve, armazenado em biserver-ce/tomcat/logs/catalina.out, pois costuma ser bastante elucidativo.
Para analisar os dados com o Saiku Analytics, na barra de ferramentas do PUC, clique no ícone vermelho, de nome New Saiku Analytics. Feito isto, será aberta uma aba com o navegador OLAP, que permite criarmos análises nos Schemas e Cubos publicados. Para permitir melhor visualizaçăo deste plugin em uma nova aba do browser, clique duas vezes na aba criada dentro do PUC.
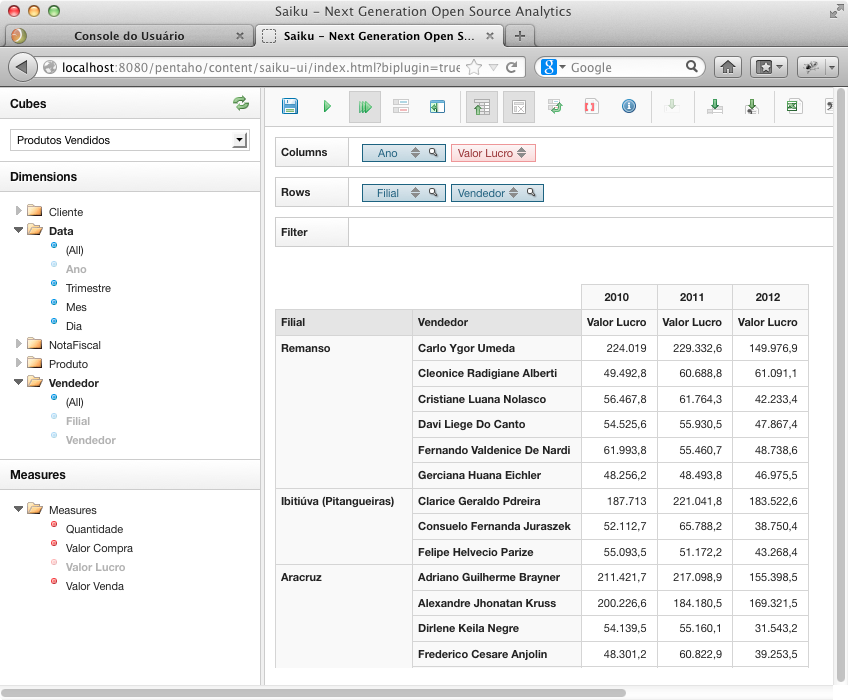
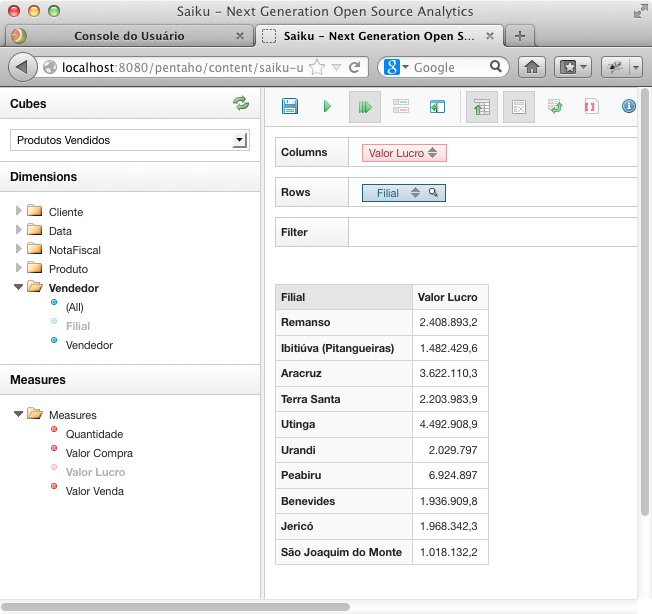
Agora selecione no combo chamado Cubos, dentro do Schema Vendas, o cubo Produtos Vendidos. As dimensőes e medidas serăo apresentadas logo abaixo deste combo, permitindo que os níveis de suas hierarquias sejam selecionados com um clique e entăo arrastados e soltados em Columns, Rows ou Filters, de acordo com o resultado desejado. Na Figura 31 foi totalizado o lucro por filial, arrastando Valor Lucro para Columns e Filial para Rows.
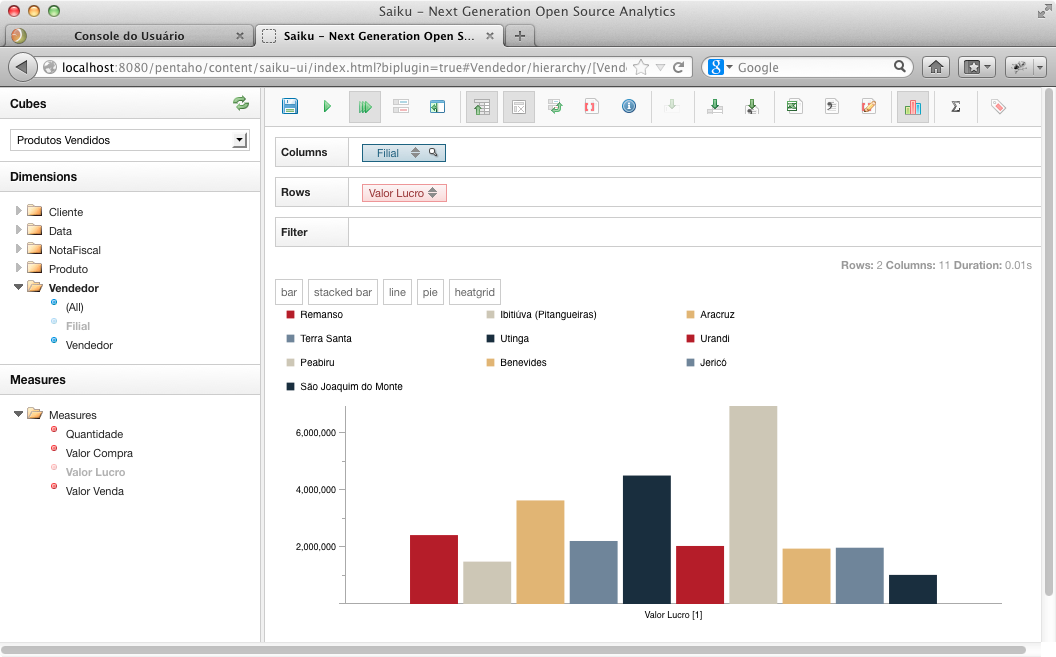
Para que os eixos sejam invertidos, ou seja, os níveis que estiverem dispostos em Columns sejam dispostos em Rows e vice-versa, clique em Swap axis na barra de ferramentas do Saiku. Após, clique no ícone Toggle Chart e veja o gráfico gerado (Figura 32).
Incrementando a análise, clique novamente em Swap axis e em Toggle Chart e acrescente o Ano junto ŕs colunas. Em seguida, clique na lupa, ao lado do Ano, selecione os anos desejados, de 2010 a 2012, confirme com OK e verifique o resultado. Na sequęncia, inclua a coluna Vendedor e tenha um resultado como o exposto na Figura 33.
Concluídas as etapas elencadas neste case percebe-se, navegando no cubo com a ferramenta OLAP, que săo inúmeras as possibilidades de cruzamento de informaçőes. A partir de entăo é possível constatar o quanto estas funcionalidades săo valiosas e desejadas por empresas de todos os portes, ramos e nacionalidades.
Este artigo teve como principal objetivo desmistificar Business Intelligence, demonstrando que BI năo é um “bicho de sete cabeças”. Dentre as soluçőes disponíveis no mercado para implementaçăo de um processo de BI, a escolha de uma delas é sempre uma tarefa de especial relevância. Neste contexto, para contemplar os requisitos propostos no case fictício, optou-se pela suíte Pentaho, que se revela como uma excelente opçăo, pois além de ser uma ferramenta completa e escalável, é gratuita.
Na criaçăo deste processo de BI, inúmeras decisőes tiveram de ser tomadas, sempre vislumbrando contemplar os requisitos elencados pelo cliente. A necessidade de tomar tais decisőes evidencia que o BI se enquadra na categoria de Serviços, pois diferente dos tradicionais Produtos “de prateleira”, as soluçőes săo desenvolvidas sob medida, considerando as necessidades de cada projeto, na medida em que os ambientes, negócios e requisitos se diferem.
Um dos fatores mais atrativos do Pentaho é o fato de ser altamente escalável, permitindo que o projeto de BI se inicie com uma configuraçăo de hardware pequena e, conforme o projeto evolui, esta configuraçăo possa ser melhorada. Para maximizar a performance, existe a possibilidade de executar as ETLs em um cluster de servidores ou de termos um cluster de servidores para fazer o cache dos dados de todas as queries e seus parâmetros, por exemplo. Outra técnica muito útil é no mapeamento da tabela fato, utilizando-se de tabelas agregadas, que armazenam os valores pré-computados dos agrupadores proporcionados pelos cubos, de acordo com as dimensőes, hierarquias e medidas definidas nele. A estrutura de cada uma destas tabelas e a devida query para gerar os seus dados podem ser criados com a utilizaçăo da ferramenta Pentaho Aggregation Designer.
Vale registrar, no entanto, que os conceitos e técnicas aqui apresentados săo suficientes para contemplar os requisitos elencados pelos clientes, na maioria dos projetos de BI. Entretanto, a criaçăo de um cubo é apenas a primeira parte deste desenvolvimento, satisfazendo os usuários experientes e conhecedores do negócio com o poder de análise que uma ferramenta OLAP proporciona. Agora que os dados estăo prontos para serem “consumidos”, provavelmente outras formas de saídas serăo necessárias, focadas nos diversos perfis de usuários que cada negócio exige. Relatórios e dashboards, por exemplo, mostram informaçőes em formatos pré-estabelecidos, sempre úteis para o acompanhamento de determinados indicadores. Entretanto, o desenvolvimento destes e sua correta compreensăo demandam novos artigos, assim como as técnicas de otimizaçăo, configuraçőes e deploy para o ambiente de produçăo.
Para os leitores que tiverem interesse em aprofundar seu conhecimento acerca de todas as ferramentas da suíte, aconselha-se a leitura da documentaçăo por ela disponibilizada. A documentaçăo pode ser acessada no PUC pelo menu Ajuda > Documentaçăo, onde estăo os tutoriais para instalaçăo e upgrade do BI-Server, além de guias para administraçăo e desenvolvimento Pentaho.
No atual estágio de desenvolvimento da cultura de Business Intelligence, percebe-se que muitas empresas tęm optado, com sucesso, pela contrataçăo de consultorias para criar um processo e implantar suas soluçőes de BI. Este é um cenário bastante atrativo, visto que a capacitaçăo da equipe interna ocorre no decorrer deste processo e em pouco tempo ela será capaz de suprir todas as necessidades de manutençăo e até de desenvolvimento.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.

 <
<