A utilizaçăo de ferramentas CASE (Computer-Aided Software Engineering) para modelagem de dados é muito importante para a qualidade do modelo, bem como para garantir uma documentaçăo atualizada e, consequentemente, maior facilidade de manutençăo de sistemas em produçăo, apoiando etapas importantes na análise e projeto de software.
Existem no mercado várias ferramentas CASE para este propósito, sendo na sua maioria produtos comerciais. Este artigo apresenta a ferramenta DBDesigner, uma ferramenta gratuita e de código aberto para modelagem de dados.
Características da DBDesigner
A DBDesigner é uma ferramenta CASE para a modelagem de dados que trabalha com o modelo lógico, desenvolvida pela fabFORCE sob a licença GNU GPL (General Public License). É um software multiplataforma (Windows 2k/XP e Linux KDE/GNOME) implementado em Delphi/Kylix. Além de permitir a modelagem, criaçăo e manutençăo de bancos de dados, esta ferramenta possibilita também a engenharia reversa, gerando o modelo de dados a partir de um banco existente, e ainda possibilita o sincronismo entre o modelo e o banco.
A DBDesigner foi construída originalmente para oferecer suporte ao MySQL, porém oferece também suporte ŕ engenharia reversa e sincronizaçăo a outros SGBDs como Oracle, SQL Server, SQLite e outros que permitam acesso via ODBC (Open Database Connectivity).
Conhecendo a DBDesigner
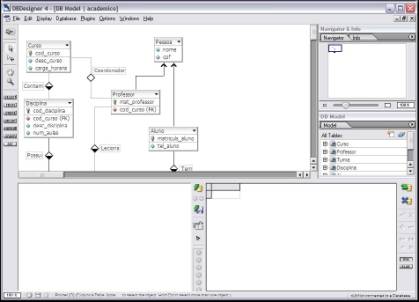
A janela principal da DBDesigner se divide em cinco áreas, como pode ser visto na Figura 1.
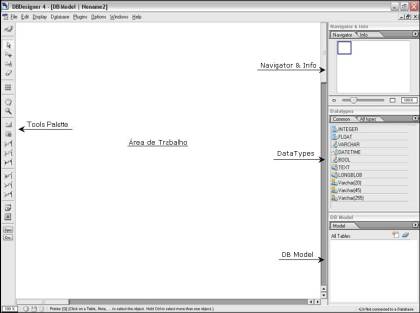
Na Área de Trabalho săo inseridas as tabelas e seus respectivos relacionamentos. A Tools Palette contém os componentes mais utilizados na criaçăo e manutençăo das tabelas. O Navigator & Info permite o controle da visualizaçăo da área de trabalho possibilitando navegar no diagrama. Os DataTypes mostram os tipos possíveis de dados e o DB Model apresenta as tabelas com seus campos e os relacionamentos com outras tabelas.
Construindo um modelo
Para demonstrar as funcionalidades da DBDesigner, é apresentada a construçăo de um fragmento do modelo de dados de um sistema acadęmico, representando suas tabelas com atributos e relacionamentos, năo tendo o objetivo de ser um exemplo completo.
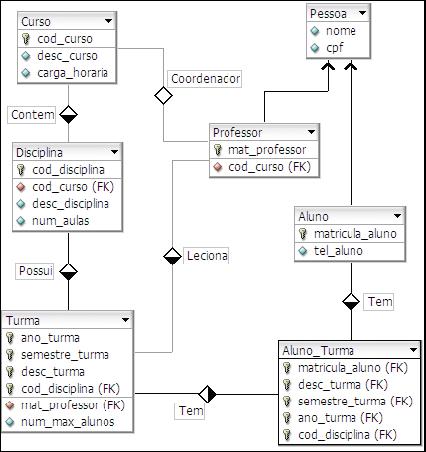
O fragmento do modelo mostrado na Figura 2 é composto pelas tabelas Aluno, Disciplina, Curso, Professor, Turma, Aluno_Turma e Pessoa, com seus relacionamentos. O tipo dos atributos e os índices foram omitidos para que o modelo fique mais claro. É importante citar que a tabela Turma é uma entidade fraca da tabela Disciplina, ou seja, a existęncia da primeira tabela é dependente da segunda. Pode-se notar que o atributo cod_disciplina (chave primária da tabela Disciplina) é inserido na tabela Turma năo apenas como chave estrangeira, mas também como chave primária. Observa-se ainda um relacionamento de generalizaçăo entre as tabelas Pessoa, Professor e Aluno, sendo que a tabela Pessoa representa os atributos comuns das tabelas Professor e Aluno.
Neste artigo será utilizada a notaçăo EER (Extended Entity-Relationship), uma extensăo do modelo entidade relacionamento originalmente proposto por Peter Chen, padrăo da DBDesigner. Nesta notaçăo, o relacionamento é representado por um losango. A Figura 3 representa o relacionamento 1:N entre as tabelas Curso e Disciplina, simbolizando que um curso contém várias disciplinas (lado fechado do losango) e uma disciplina é de um único curso (lado aberto do losango). O losango totalmente aberto representa um relacionamento 1:1.
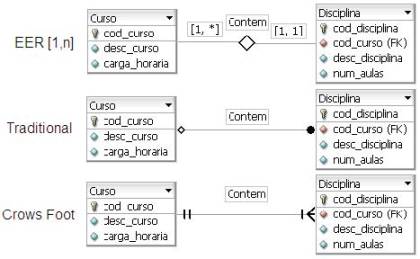
Entretanto, existem outras notaçőes disponíveis e, para alternar entre elas, deve-se utilizar o menu Display / Notation e escolher a notaçăo desejada. A Figura 4 apresenta o mesmo relacionamento 1:N utilizando as demais notaçőes disponibilizadas pela ferramenta.
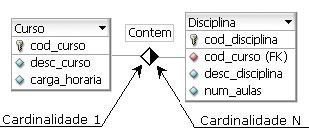
Na representaçăo das tabelas (ver Figura 5), ŕ frente de cada atributo, existe uma imagem que expőe o que este representa. Atributos que săo chaves primárias tęm o símbolo ŕ sua esquerda e ficam separados logo abaixo do nome da tabela. Os atributos que săo chaves estrangeiras vęm seguidos do símbolo (FK), uma Foreign Key, precedidos do símbolo quando năo fazem parte da chave primária. Já o símbolo precede aqueles atributos comuns, que năo representam nenhum tipo de chave.

Através do menu Display é possível personalizar a visualizaçăo do modelo, de maneira a atender as necessidades do usuário. Por exemplo, é possível escolher entre exibir todos os atributos das tabelas (Display / Table Columns / Attribute Level), apenas as chaves primárias (Display / Table Columns / Primary Key Level) ou nenhum atributo (Display / Table Columns / Entity Level). Exibir ou esconder o tipo dos campos (Display / Table Columns / Physical Schema Level), as chaves estrangeiras (Display / Table Columns / Show Foreign Keys), os índices (Display – Table Indices – List Table Indices) e também os nomes dos relacionamentos (Display – Display Relation Names).
No menu Options definem-se algumas propriedades em relaçăo ao modelo. Por exemplo, a configuraçăo padrăo éque os atributos que representam chaves estrangeiras săo exibidos com o nome da tabela de origem a frente do nome do atributo propriamente dito (Options / Model Options / Editing Options / Add Source Table Name To Foreign Key Column’s Name). No fragmento de modelo aqui mostrado foi desabilitada esta opçăo. Para que tenha efeito, esta opçăo deve ser desabilitada antes da criaçăo do modelo, sendo inútil a alteraçăo desta opçăo após o início de sua construçăo. Neste menu se encontram também as opçőes de alterar o idioma do aplicativo (năo incluído portuguęs), a fonte usada, dentre outras opçőes que podem ser alteradas seguindo o perfil do usuário.
Inserindo as tabelas
A primeira etapa para construir o estudo de caso deste artigo é inserir as tabelas e seus atributos. O primeiro passo é criar a tabela Curso. Deve-se inserir na área de trabalho uma tabela (ícone New Table localizado na Tools Palette). Para definir as propriedades como nome da tabela e seus atributos, dentre outras características de uma tabela, deve-se clicar duas vezes sobre o objeto criado. Feito isto, uma janela para a alteraçăo de propriedades da tabela é aberta, de acordo com a Figura 6.
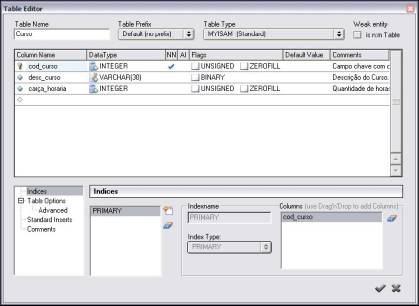
A primeira propriedade a ser modificada é o nome da tabela através da opçăo Table Name, que deve ser alterada para Curso. A seguir, săo definidos os campos e os tipos de dados associados a esta tabela através da parte principal da janela, seguindo as seguintes definiçőes:
- Column Name: nome do campo. O primeiro campo por padrăo é definido como chave primária;
- DataType: o tipo do campo. Pode-se escolher entre os tipos de campos pré-definidos;
- NN: campo obrigatório, ou seja, marcando este campo, proíbe-se de existir um registro na tabela sem o seu preenchimento. Năo é permitido desmarcá-lo caso o campo seja parte da chave primária;
- AI: define o campo como sendo Auto-Incremento;
- Flags: săo propriedades definidas para o campo, em funçăo do tipo de dados selecionado, como UNSIGNED, ZEROFILL e BINARY;
- Default Value: determina um valor padrăo para o campo. Caso năo seja digitado nenhum valor ao inserir um registro, o valor a ser assumido por este campo é o valor definido nesta propriedade;
- Comments: utilizado para comentários. Muito útil para lembrar a finalidade do campo.
Um índice chamado PRIMARY é criado automaticamente para a chave da tabela, sendo possível definir mais índices de acordo com a necessidade. Para isto, é utilizada a parte inferior da janela apresentada na Figura 6. Para adicionar outros índices deve-se clicar sobre o botăo com o símbolo , escolher o nome do índice e confirmar. É necessário definir qual campo vai ser indexado pelo índice criado, sendo possível criar um índice utilizando mais de um campo. Neste estudo de caso, a tabela Curso é indexada pelo campo desc_curso para que se possa ordenar e fazer buscas mais rapidamente através deste campo. Para isso, deve-se clicar sobre este campo e arrastá-lo até o canto inferior direito, denominado Columns.
Depois de ter alterado todas as propriedades necessárias da tabela, deve-se confirmar as modificaçőes clicando no botăo no canto direito inferior . Com isso finaliza-se a criaçăo da tabela.
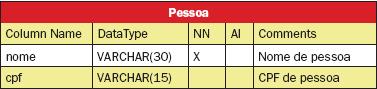
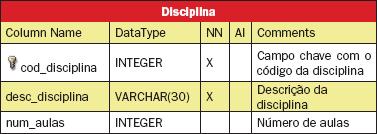
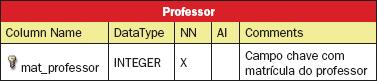
No exemplo anterior é mostrada a criaçăo da tabela Curso. Da mesma maneira, abaixo săo apresentadas as estruturas das tabelas Pessoa, Aluno, Disciplina, Professor e Turma, respectivamente descritas nas Tabelas 1 a 5, sem os atributos relativos aos relacionamentos, que serăo criados posteriormente.
Pessoa
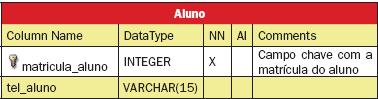
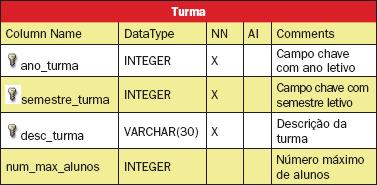
Um fato importante em relaçăo ŕ tabela Turma é que a chave é composta por mais de um atributo. Para definir a chave desta maneira clica-se sobre o ícone , que está ŕ esquerda do nome do campo, nas propriedades da tabela. Após clicar sobre este ícone ele se torna um desenho de uma chave , tornando-o parte da chave primária.
Definindo os relacionamentos
Depois das tabelas criadas, devem ser definidos os relacionamentos entre elas. O primeiro relacionamento é entre a tabela Professor e Curso e possui cardinalidade 1:1, ou seja, um professor pode ser coordenador de um curso assim como um curso é coordenado por um professor. Para criar este relacionamento, deve-se clicar sobre o botăo (New 1:1 Non-Identifying Relation), em seguida sobre a tabela Professor e finalmente sobre a tabela Curso. Uma linha é traçada ligando as duas tabelas envolvidas. Para renomear este relacionamento é necessário clicar duas vezes sobre a linha que o representa e alterar a propriedade Relation Name para Coordenador. Nota-se que uma chave estrangeira é criada na tabela Curso, fazendo a ligaçăo entre as tabelas.
O próximo relacionamento a ser criado é entre as tabelas Curso e Disciplina. É um relacionamento de cardinalidade 1:N que define que um curso pode ser composto por várias disciplinas, assim como uma disciplina compőe um único curso. O procedimento para criar este relacionamento é clicar sobre o botăo (New 1:n Non-Identifying Relation) da Tools Palette e, em seguida, clicar sobre a tabela Curso e finalmente sobre a tabela Disciplina. Observa-se que neste caso a ordem em que se clica nas tabelas é importante para definir qual tabela possui a cardinalidade 1 e qual tabela terá a cardinalidade N. Além disso, vale mencionar que a tabela de lado N é que recebe a chave estrangeira.
Outro relacionamento que deve ser criado possui cardinalidade N:N e mostra a ligaçăo entre as tabelas Turma e Aluno. Este relacionamento define que uma turma pode ser freqüentada por vários alunos, assim como um aluno freqüenta várias turmas. A definiçăo deste relacionamento é feita a partir do clique no botăo (New n:m Relation), seguido de um clique sobre a tabela Turma e finalmente sobre a tabela Aluno. Pode-se notar que a tabela que faz o relacionamento N:N é criada automaticamente. Muitas vezes é conveniente renomear esta tabela para que tenha um nome significativo. Para isso, deve-se clicar duas vezes sobre ela e alterar a propriedade Table Name para Aluno_Turma.
Como mencionado anteriormente, a tabela Turma é uma entidade fraca da tabela disciplina e, para criar este tipo de relacionamento usa-se o botăo (New 1:N Relation), seguido de um clique sobre a tabela Disciplina e finalmente sobre a tabela Turma. Ao se usar este tipo de relacionamento pode-se notar que além do campo cod_disciplina ir para a tabela Turma como chave estrangeira, ele também aparece como chave primária.
Por fim, o último tipo de relacionamento utilizado é a generalizaçăo. Este tipo de relacionamento possibilita a criaçăo de tabelas genéricas para que posteriormente possam ser usados seus atributos em conjunto com outras tabelas. Para definir um relacionamento deste tipo entre as tabelas Pessoa (que é utilizada no exemplo como uma tabela genérica) e Aluno, deve-se clicar sobre o botăo (New Generalization), seguindo de um clique sobre a tabela Pessoa e finalmente sobre a tabela Aluno.
Para finalizar a construçăo do modelo devem-se construir os demais relacionamentos entre as tabelas Turma e Professor e a generalizaçăo entre Pessoa e Professor.
Criando o banco de dados
Pouco adiantaria uma ferramenta de modelagem que fizesse apenas o desenho de um modelo e năo permitisse a criaçăo automatizada do banco de dados propriamente dito. A DBDesigner permite que esta tarefa seja executada de duas maneiras diferentes. Uma das maneiras é gerar os comandos SQL de criaçăo do banco de dados e depois mandar executar através de uma interface do SGBD. Para isto deve-se clicar sobre o menu File / Export / SQL Create Script. Ao clicar nesta opçăo pode-se observar uma janela com algumas opçőes para a geraçăo do script SQL, permitindo gerar os scripts apenas das tabelas selecionadas, criar ou năo as chaves primárias, os índices e outras opçőes (ver Figura 7).
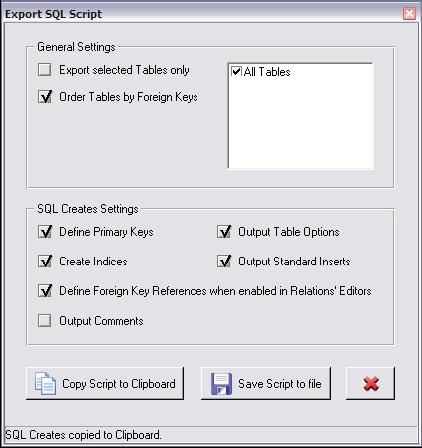
Ainda nesta figura, para que os relacionamentos sejam gerados, deve-se marcar a opçăo Define Foreign Key References when enabled in Relations’ Editors. A opçăo Create Indices cria um índice no banco para cada chave estrangeira definida no modelo.
Depois de escolhidas as opçőes desejadas, pode-se salvar o script SQL em um arquivo texto, escolhendo a opçăo Save Script to file, ou apenas enviar este código para a área de transferęncia, utilizando a opçăo Copy Script to ClipBoard. A Listagem 1 apresenta um trecho do script SQL gerado pela ferramenta para a criaçăo das tabelas Curso e Disciplina.
CREATE TABLE Curso (
cod_curso INTEGER NOT NULL,
desc_curso VARCHAR(30) NULL,
carga_horaria INTEGER NULL,
PRIMARY KEY(cod_curso)
);
CREATE TABLE Disciplina (
cod_disciplina INTEGER NOT NULL,
cod_curso INTEGER NOT NULL,
desc_disciplina VARCHAR(30) NULL,
num_aulas INTEGER NULL,
PRIMARY KEY(cod_disciplina),
INDEX Disciplina_FKIndex1(cod_curso),
FOREIGN KEY(cod_curso)
REFERENCES Curso(cod_curso)
ON DELETE NO ACTION
ON UPDATE NO ACTION
);
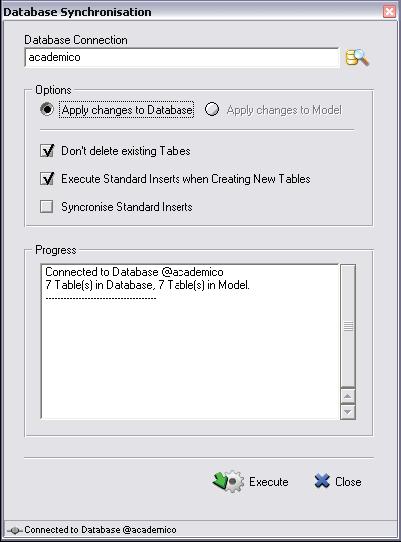
A outra maneira de se criar o banco de dados é através de uma conexăo direta com o SGBD, através do menu Database / Database Synchronisation. Este menu, além de criar o banco de dados, também é usado para manter o sincronismo entre o modelo e o banco. Ao clicar neste menu é apresentada a janela Select Database Connection para que se possa escolher um banco de dados existente ou criar uma nova conexăo de banco de dados (ver Figura 8).
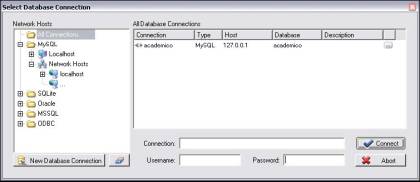
Para criar uma nova conexăo deve-se clicar sobre o botăo New Database Connection. Uma outra janela, Database Connection Editor (ver Figura 9) é aberta para que se possa escolher as opçőes de configuraçăo da conexăo que está sendo criada. Neste exemplo é utilizado o MySQL para a configuraçăo da conexăo com o banco.
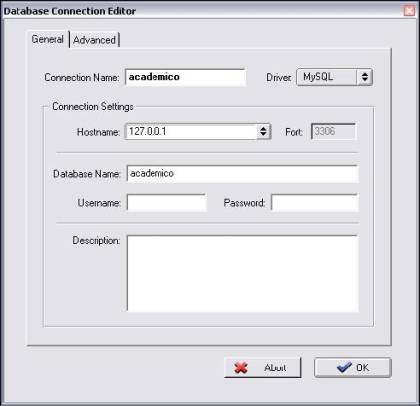
Após ter feito esta configuraçăo, deve-se clicar no botăo OK para confirmar. E, na janela Select Database Connection, clica-se sobre o botăo Connect para fazer a conexăo com o banco. Surgirá uma nova janela (ver Figura 10) para que possam ser feitas algumas configuraçőes em relaçăo ao sincronismo, como năo apagar as tabelas já existentes no banco de dados mesmo que tenham sido retiradas do modelo, dentre outras opçőes. Depois de ter personalizado estas configuraçőes, deve-se clicar sobre o botăo Execute. Neste ponto, a DBDesigner se encarrega de fazer toda a criaçăo das tabelas do banco de dados ou o sincronismo entre o banco existente e o modelo. Um “log” é mostrado na janela com as informaçőes das execuçőes feitas.
Executando consultas em SQL
Depois de ter criado o banco de dados, a DBDesigner permite que sejam executados comandos SQL, através do menu Display / Query Mode (ou botăo na Tools Palette). Ao selecionar esta funcionalidade, nota-se que na parte inferior da janela surgem algumas opçőes como pode ser observado na Figura 11.
A parte inferior esquerda desta janela é o local onde se digita o código SQL e, após isso, clica-se no botăo (Execute SQL Query). Caso exista algum resultado a ser exibido, é apresentado no lado direito desta janela.
A DBDesigner permite também a criaçăo automática de parte do código SQL. Para isto, deve-se clicar sobre alguma tabela e arrastar o cursor do mouse para que apareçam algumas opçőes a serem selecionadas, como Select, Update,Insert e Delete. Com o botăo do mouse ainda pressionado, posiciona-se o cursor na opçăo desejada e, ao soltar o botăo, o código SQL é automaticamente gerado. Para retornar ao modo de projeto, seleciona-se o menu Display / Design Mode (ou o botăo na Tools Palette).
Engenharia reversa
O caminho normal na construçăo do banco de dados é fazer o modelo e posteriormente partir para a construçăo do banco propriamente dito. Porém, este caminho pode se inverter quando já se tem um banco de dados criado e deseja-se obter o modelo deste banco. Isto é muito útil quando năo se tem documentaçăo atualizada do banco.
Como dito anteriormente no artigo, uma das características da DBDesigner é a possibilidade de se fazer engenharia reversa. A título de exemplo, será mostrado como fazer uma engenharia reversa utilizando o próprio banco gerado anteriormente. Para isso, deve-se selecionar o menu Database / Reverse Engineering na janela Select Database Connection, selecionando o banco de dados ao qual se quer conectar, e entăo clica-se no botăo Connect. Uma janela é exibida para que possam ser feitas algumas configuraçőes (ver Figura 12).
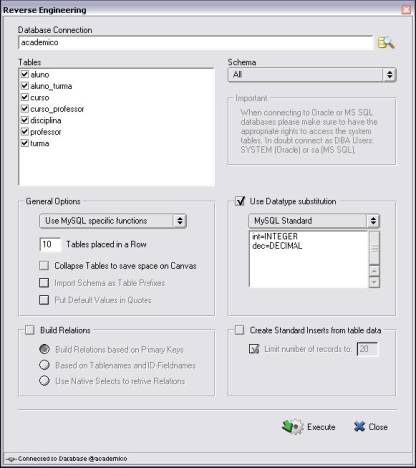
Em Tables, devem-se selecionar todas as tabelas que irăo compor o modelo. Em General Options săo definidas as propriedades para visualizaçăo do modelo gerado. Marcase a opçăo Build Relations para que os relacionamentos sejam gerados, deixando selecionada a opçăo Build Relations based on Primary Keys, para a geraçăo dos relacionamentos baseados nas chaves primárias.
Após ter definido as configuraçőes necessárias, deve-se clicar no botăo Execute. O modelo é criado automaticamente e apresentado na área de trabalho.
Outras funcionalidades
Uma característica da DBDesigner é salvar os seus arquivos em formato XML (Extensible Markup Language), ao invés de utilizar um formato proprietário. Isso facilita a importaçăo e exportaçăo de modelos de outras ferramentas para a DBDesigner ou desta para outras eventuais ferramentas. Como exemplo, pode-se importar modelos em XML gerados pela ferramenta CASE ERwin. A Listagem 2 apresenta um fragmento do XML gerado pela DBDesigner.
XPos=”105” YPos=”128” TableType=”0” TablePrefix=”0” nmTable=”0”
Temporary=”0” UseStandardInserts=”0” StandardInserts=”\n”
TableOptions=”DelayKeyTblUpdates=0\nPackKeys=0\nRowChecksum=0
nRowFormat=0\nUseRaid=0\nRaidType=0\n” Comments=”” Collapsed=”1”
IsLinkedObject=”0” IDLinkedModel=”-1” Obj_id_Linked=”-1”
OrderPos=”3” >
idDatatype=”5” DatatypeParams=”” Width=”-1” Prec=”-1”
PrimaryKey=”1” NotNull=”1” AutoInc=”1” IsForeignKey=”0”
DefaultValue=”” Comments=”Campo chave com o c\243digo do curso”>
Uma outra funcionalidade útil desta ferramenta é a geraçăo de documentaçăo em formato HTML, através da opçăo Plugins / HTMLReport (ver Figura 13).
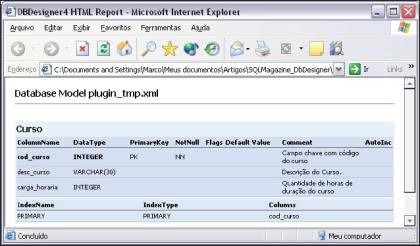
Conclusőes
A DBDesigner é uma ferramenta para a construçăo de modelos de dados, fácil de usar, com um aprendizado relativamente rápido, e que proporciona uma boa produtividade na sua utilizaçăo. Tudo isto com a vantagem de ser uma ferramenta gratuita e com o código fonte aberto.
A possibilidade de sincronismo entre o modelo e o banco é de grande importância para o sucesso desta ferramenta. Isso faz com que manutençőes futuras no banco sejam feitas de maneira rápida e eficiente. E o fato de salvar e recuperar arquivos no padrăo XML é importante para a possibilidade de comunicaçăo entre diferentes ferramentas.













