


Existem vários fatores importantes para se fazer replicaçőes em um banco de dados, mas tręs deles merecem destaque:
Agora que sabemos as vantagens vamos entăo entender como funciona a replicaçăo entre servidores com o MySQL, que possui dois tipos de replicaçăo: a master-slave e a master-master.
A master-slave faz com que o slave receba as atualizaçőes do master, enquanto as inserçőes e ediçőes acontecem apenas no último, ou seja, o slave funciona apenas para leituras. É uma configuraçăo muito útil quando temos a maior parte dos acessos ao sistema/site para consulta. Um bom exemplo seria um blog onde a necessidade de escrita é direcionada ao banco master e o resto pode ser direcionado a um ou mais slave.
A arquitetura master-slave pode ser observada na Figura 1, onde temos um servidor master que fornece os dados ao slave, e como o único servidor que pode fazer escrita é o servidor master, este năo conhece os slaves, mas apenas gera um arquivo com os logs do banco para que eles utilizem para sincronizar seus dados com os do servidor.
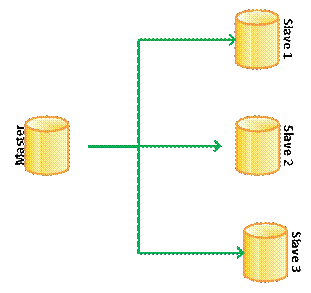
Figura 1. Arquitetura master-slave.
Para exemplificar vamos configurar um modelo de arquitetura master-slave seguindo os cinco passos a seguir:
Nosso exemplo foi trabalhado com tręs máquinas com sistema operacional Windows, sendo uma delas master e duas slave. O master tem o IP 192.168.0.11, o slave 1 o IP 192.168.0.22 e o slave 2 o IP 192.168.0.23.
Para iniciarmos vamos configurar o nosso master, mas antes devemos saber se o log binário já está ligado. Para isso, com o terminal do MySQL aberto devemos digitar a seguinte linha de comando:
SHOW GLOBAL VARIABLES WHERE Variable_name = 'log_bin';Após isso vamos ter uma saída no terminal semelhante a esta:
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | OFF |
+---------------+-------+Para quem tem o MySQL Workbench, pode ver essa informaçăo no "Status and System Variables" na aba "System Variables" utilizando a filtragem por "log_bin", como pode ser observado na Figura 2.
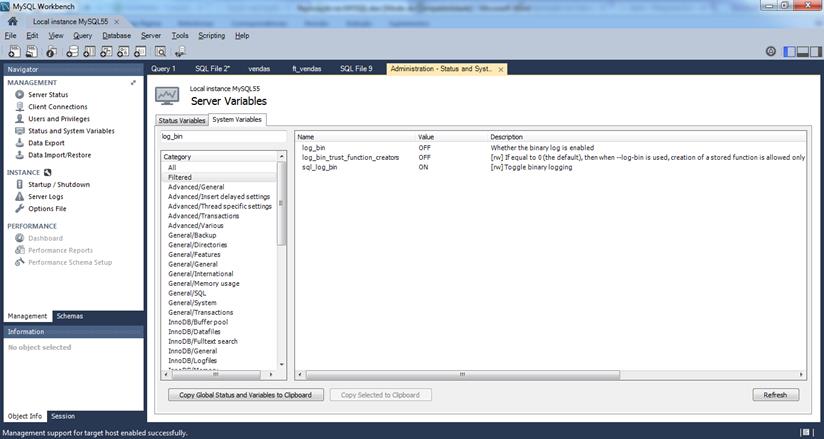
Figura 2. MySQL Workbench
Se o valor for "OFF", como no nosso exemplo, significa que nosso log năo está ligado e devemos entăo ligá-lo. Para isso vamos abrir o arquivo my.ini, que se encontra normalmente em "C:\ProgramData\MySQL\MySQL Server X.Y", onde "X.Y" é o número da sua versăo do MySQL. Abram o arquivo .ini e, no final, adicionem a seguinte configuraçăo:
# Número de identificaçăo do servidor.
server-id=1Nessa configuraçăo definimos o número do nosso servidor, e como esse é o master, foi definido o número 1, e para os demais vamos definir as demais sequęncias. Lembre-se que năo pode ocorrer de dois servidores terem o mesmo número. A segunda alteraçăo que faremos é adicionar ao final do arquivo a seguinte configuraçăo:
# Localizaçăo do arquivo de log binário
log-bin="C:/ProgramData/MySQL/MySQL Server X.Y/Data/bin-log"Nessa configuraçăo estamos definindo o caminho e o prefixo dos nosso logs binários.
Depois disso basta reiniciarmos o nosso serviço e, ao efetuar uma nova consulta, a variável "log_bin" devemos obter o valor "ON", e năo mais "OFF" como visto anteriormente. Ao reiniciar o serviço serăo criados dois arquivos no diretório definido para o bin-log: o bin-log.index e bin-log.000001.
Com isso nosso servidor master está pronto para replicar.
Devemos configurar agora um usuário com permissőes para copiar os dados do servidor master, entăo devemos criar um usuário para esse processo. Para isso, com o terminal do MySQL aberto, vamos usar o seguinte comando para criar o usuário "replica":
GRANT REPLICATION SLAVE ON *.* TO 'replica'@'%' IDENTIFIED BY '123';Com esse comando vamos criar e dar permissőes especiais para a cópia de dados ao usuário chamado "replica", que se conecta de qualquer IP e que tem a senha "123".
Por segurança o IP deve ser definido e todos os IP’s devem ser adicionados, mas como no nosso caso teremos dois servidores slave, e para năo ter que utilizar o comando mais de uma vez, alteramos o IP para dar uma permissăo genérica para todos os IP's.
Essa etapa deve ser feita apenas para quem já tem banco em produçăo e está adicionando a replicaçăo após os dados já terem sido inseridos em base de dados. Caso sua base seja nova essa etapa é desnecessária.
Já que
vamos replicar e até o momento o arquivo de log năo estava sendo gerado,
significa que apenas as alteraçőes a partir da geraçăo do log serăo replicadas.
Mas, e os dados que já existem em base?
Esses dados devem ser levados para os outros servidores através de backups.
Entăo, para gerar nosso backup vamos utilizar o comando:
mysqldump -u root -p --database <base> --master-data=1 > c:\backup.sqlOnde <Base> é a base que será replicada. No teste utilizamos apenas a base "test" do MySQL.
Dica: No caso de replicar todas as bases de dados podemos utilizar o parâmetro --all-databases.
No teste utilizamos apenas a base "test" do MySQL e o parâmetro "--master-data=1 " cria um lock, atrasando assim as escritas em banco para que o backup esteja com os dados corretos até o momento de seu início e para que o servidor năo pare. O backup foi feito no nosso "C:".
Agora devemos recuperar esses dados nos servidores slave: para isso utilizem o comando:
mysql -h 192.168.0.22 -u root -p < c:\backup.sqlCom esse comando executamos o restore no slave 1, e para isso basta que o usuário tenha permissăo de acessar o servidor remotamente.
Agora basta executar o mesmo comando para slave 2 e com nosso ambiente preparado vamos entăo dar início a configuraçăo dessas máquinas.
Lembre-se que essa etapa deve ser repetida para cada servidor slave. Nessa parte vamos configurá-los e a primeira coisa a ser feita é colocar o número do servidor, se năo existir. Verifique se o número năo coincide com o de outro servidor. Entăo no arquivo .ini adicionem ou alterem a propriedade "Server-id" para o número do servidor corresponde.
Depois disso temos que configurar o servidor para sincronizar com o master, para isso devemos ir nele e, com o terminal de comando do MySQL aberto, execute a seguinte linha de comando:
SHOW MASTER STATUS;Será apresentado um resultado semelhante a esse:
+----------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+----------------+----------+--------------+------------------+
| bin-log.000001 | 350 | | |
+----------------+----------+--------------+------------------+Utilizaremos as informaçőes de file e position no nosso servidor slave para configurar de onde ele irá começar a sincronizar: como năo houve nenhuma alteraçăo no banco essa posiçăo ainda é a mesma de antes do backup. Caso seu banco esteja em produçăo essa informaçăo deve ser pega no momento do backup ou no arquivo de backup, logo abaixo da descriçăo "Position to start replication" em "CHANGE MASTER", onde também teremos as informaçőes do file, que é o nome do arquivo bin-log e a posiçăo.
Com essas informaçőes em măos vamos configurar o slave; execute dentro do terminal do MySQL do slave o seguinte comando:
CHANGE MASTER TO
MASTER_HOST='192.168.0.11' ,
MASTER_USER='replica' ,
MASTER_PASSWORD='123' ,
MASTER_LOG_FILE='bin-log.000001',
MASTER_LOG_POS=350 ;Onde:
Como podemos observar, os valores de file e position foram utilizados na configuraçăo de master_log_file e master_log_pos, respectivamente.
Agora com tudo configurado, basta que iniciarmos o serviço de réplica do slave, utilizando para isso o seguinte comando:
START SLAVE;E para finalizarmos devemos reiniciar o serviço do MySQL para que todas as configuraçőes sejam carregadas com sucesso, principalmente as que foram efetuadas no arquivo .ini (no nosso caso apenas o número do servidor). Com o servidor iniciado temos entăo a réplica funcionando. Vamos entăo monitorar e testar.
Para monitorar basta utilizar o seguinte comando no terminal do MySQL do slave que desejamos monitorar:
SHOW
SLAVE STATUS \GSerá apresentada uma tela contendo resultados como os da Figura 3. Nessa tela podemos monitorar se ocorreu algum erro, quem é o usuário da réplica, a porta, o último erro, entre outras informaçőes. Nessa tela temos que ficar atentos as linhas:
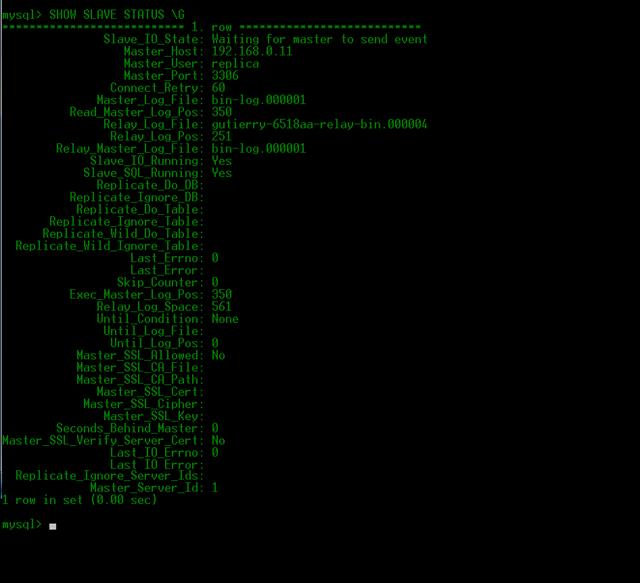
Figura 3. Monitoramento servidor slave
Para testarmos se está tudo funcionando, basta efetuar alguma alteraçăo no master e repetir o comando anterior: veremos que o Exec_Master_Log_Pos foi alterado. E se efetuarmos a consulta na tabela que a alteraçăo foi feita, vamos ver que essa alteraçăo já está persistida no slave.
A master-master faz com que um servidor master seja tanto master quanto slave do outro servidor, assim, năo só podendo escrever quanto podendo receber as atualizaçőes do seu master. Nesse caso, as inserçőes e ediçőes acontecem em todos os servidores.
É uma configuraçăo muito útil quando existe a necessidade de todos os servidores efetuarem a leitura e escrita dos dados. Um bom exemplo seria um sistema crítico, como num balanceamento de carga, que pode ser feito a qualquer servidor, independente do que o usuário irá fazer.
A arquitetura master-master pode ser observada na Figura 4, onde temos um servidor master que acaba sendo slave de um outro master.
Essa arquitetura tem um problema, que é trabalhar em arquitetura anel, onde um servidor só pode ser master de um e slave de um, e caso um dos servidores caia, a replicaçăo daquele ponto em diante fica comprometida até que o servidor seja reestabelecido.

Figura 4. Arquitetura master-master.
Um outro problema muito enfrentado na master-master é a geraçăo de id automático pelo banco, e para resolver o que vemos muito por aí é definir um servidor para gerar números ímpares e o outro servidor apenas números pares, mas com isso ficamos limitados a apenas dois servidores. Para resolver isso da melhor forma vamos criar um exemplo com tręs servidores, como no exemplo anterior.
Para iniciarmos podemos usar os mesmos passos do master-slave e vamos adicionar mais quatro passos:
Antes de iniciarmos temos que definir quem irá replicar e quem irá ser o master de quem. Para esse exemplo faremos assim: Servidor 1 será o slave do servidor 3, o servidor 3 será slave do servidor 2, que por sua vez será slave do servidor 1.
Observaçăo:Caso o banco já esteja populado e em produçăo, convém efetuar as configuraçőes em uma janela de manutençăo.
Como visto anteriormente na configuraçăo do master-slave, devemos ativar o log binário dos demais servidores, e para isso basta seguir o procedimento anterior para cada servidor. Em seguida confira se ele está ativo e se os arquivos foram gerados corretamente.
O processo é o mesmo que no slave, e deve ser feito para cada servidor. Como cada servidor vai ler apenas um servidor, podemos entăo deixar a permissăo apenas para o IP do slave correspondente, assim, manteremos o nome do usuário anterior e executar o grant nos demais servidores.
Nessa etapa devemos alterar os dados do master dos slave para o seu master correspondente, e năo mais a um central. Para isso devemos pegar as informaçőes de logs binários e a posiçăo do novo servidor master e em seguida aplicar as alteraçőes com "change master", como no exemplo do master-slave.
Após a configuraçăo dos slave vamos agora efetuar as alteraçőes para que os autoincrement năo se repitam. Para isso vamos alterar os arquivos ini de cada servidor:
No servidor 1 vamos adicionar as seguintes linhas:
auto-increment-increment = 3
auto-increment-offset = 1
No servidor 2 vamos adicionar as seguintes linhas:
auto-increment-increment = 3
auto-increment-offset = 2
No servidor 3 vamos adicionar as seguintes linhas:
auto-increment-increment = 3
auto-increment-offset = 3Isso vai impedir que o servidor gere um id que o outro servidor possa gerar. Lembre-se que o "auto-increment-increment" serve para informamos de quantos em quantos números vamos inserir, e esse valor será preenchido com o número de servidores. O "offset" será para determinar qual o valor inicial para o autoincrement. Com isso teremos um resultado de ids igual ao observado na Tabela 1.
| Servidor 1 | Servidor 2 | Servidor 3 |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
| 10 | 11 |
|
| 14 |
|
|
| 18 |
Tabela 1. Simulaçăo da geraçăo de Id
Com isso resolvemos o problema dos IDs duplicados entre servidores.
Para monitorar basta utilizar o comando "SHOW SLAVE STATUS \G" no terminal do MySQL, como fizemos no exemplo do master-slave. Nesse caso devemos monitorar todas as máquinas, visto que todas elas săo slave. Para testar basta inserimos alguma informaçăo em algum dos servidores e conferir se os demais receberam essa atualizaçăo.
O MySQL nos permite também definir quais bancos e quais tabelas iremos replicar: para isso basta que nos slave adicionemos as seguintes linhas:
replicate-do-db = '<nome_do_banco>'
replicate-do-table = '<nome_da_tabela>'Com esse estudo podemos criar mais de um servidor de banco de dados e replicar suas informaçőes, deixando um servidor com exclusividade para uma tarefa sem afetar o desempenho do outro. Podemos utilizar o conceito de master-master para efetuar um melhor balanceamento de carga ou melhorar o desempenho de uma aplicaçăo ao se trabalhar com banco de dados locais, aumentando a disponibilidade e segurança de nossas aplicaçőes.
Espero que tenham gostado e até a próxima.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.