O objetivo desse artigo é apresentar a instruçăo SELECT e seus detalhes de uso, principais características, algumas diferenças na sua implementaçăo entre os diferentes fabricantes de SGBD, assim como suas melhores práticas e, desde o início, como escrevę-la de forma que tenha sempre boa performance.
Nosso foco principal será a preparaçăo de instruçőes SELECT que tragam o resultado de duas ou mais tabelas, isto é, façam joins entre estas tabelas e retorne seus dados num único comando. Serăo apresentados uma série de exemplos para ilustrar e tornar o seu entendimento mais fácil.
Com esses conceitos vocę descobrirá qual tipo de join se adapta corretamente ao seu problema, como escrevę-lo da forma correta, e também que pode escrever muito menos linhas de código na sua aplicaçăo porque uma instruçăo SELECT poderá fazer grande parte desse trabalho para vocę.
Portanto, se vocę é um desenvolvedor, vocę já utilizou ou utilizará essa instruçăo. Assim, nada melhor do que conhecer seus detalhes e como utilizá-la de maneira que torne sua aplicaçăo o mais eficiente possível no acesso aos seus dados.
Em um artigo publicado na ediçăo 129, fizemos uma introduçăo ŕ instruçăo SELECT da linguagem SQL. Nele apresentamos sua forma básica de uso de tal modo que vocę já conseguisse escrever as primeiras instruçőes, recuperando dados do seu banco de dados, utilizando funçőes muito úteis no seu dia a dia.
Este artigo avançará mais profundamente nessa mesma instruçăo SELECT. Vamos colocar seu conhecimento da instruçăo em seu nível intermediário. Suficiente para utilizá-la em 90% das situaçőes enfrentadas diariamente por um desenvolvedor.
Novamente, utilizaremos as melhores práticas como nossa orientaçăo primordial. Como melhores práticas vocę poderá entender: instruçőes simples, escritas de forma clara e correta, e apresentando a melhor performance possível.
O foco nesse artigo será como apresentar os dados de duas ou mais tabelas em uma única instruçăo, isto é, como montar joins. Vamos apresentar e conceituar os diferentes tipos de joins e suas diferentes formas de escrevę-los.
O assunto central deste artigo săo as várias formas de join, ou combinaçăo de várias tabelas em uma única instruçăo. Para se combinar tabelas, é primordial conhecer como estas tabelas foram modeladas e se relacionam.
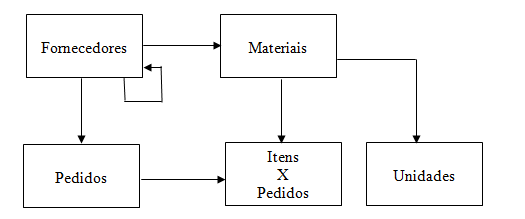
Năo conseguiríamos escrever um join sem saber quais săo as colunas de duas tabelas que definem o seu relacionamento. Portanto, para termos sucesso e clareza em nossos exemplos, vamos apresentar o modelo de dados que será utilizado para desenvolvermos as instruçőes SELECT ao longo desse artigo.
Na Figura 1 é possível ver o esquema simplificado dos relacionamentos entre as tabelas. Nosso objetivo aqui năo é falar sobre este tipo de esquema, chamado de Modelo de Entidades e Relacionamentos, que tem muito mais símbolos do que os apresentados aqui. Por isso, apresentaremos rapidamente o que ele está descrevendo.
Nesse conjunto de tabelas, temos a listagem dos materiais (tabela Materiais) utilizados por uma empresa fictícia para a qual vamos montar nossos exemplos. Cada um desses materiais é comprado de uma empresa fornecedora (tabela Fornecedores).
Temos também os pedidos de compra que foram feitos para cada fornecedor (tabela Pedidos), com seus respectivos itens (tabela “Itens x Pedidos”), isto é, quais materiais foram solicitados nos pedidos. A última tabela é a tabela de unidades. Nela estăo as definiçőes das unidades de medida utilizadas para contar ou medir os itens.
As setas que ligam uma tabela, ou entidade, as outras representam os relacionamentos que existem entre elas. O sentido da seta indica qual tabela é pai e qual é filha nesse relacionamento, estando a filha do lado da seta.
Para ficar mais claro, existe uma seta entre a tabela de Fornecedores e Materiais, apontando para tabela Materiais. Isto indica que existe um relacionamento entre as duas tabelas e que a tabela Materiais é filha da tabela Fornecedores.
Assim, a tabela Materiais deverá possuir uma coluna que identifique qual a empresa fornecedora é a que oferece aquele material. Na lista de atributos, ou colunas, das tabelas apresentadas, é possível notar que existe uma coluna cod_fornecedor na tabela Materiais e este é exatamente o propósito dela, indicar quem é o seu fornecedor.
A intençăo deste pequeno modelo năo é sermos exaustivos em todas as possibilidades de negócio que poderiam ser definidas nesse conjunto de tabelas, mas apenas utilizá-las como exemplo. Só para exemplificar uma regra de negócio que năo é atendida por este modelo, um Material só pode ser fornecido por uma empresa fornecedora. Năo existe aqui como armazenar ou representar um material oferecido por mais de um fornecedor. A seguir săo apresentados os atributos de cada tabela:
Note que na lista de colunas de cada tabela uma ou mais colunas ou atributos estăo destacadas em negrito. Elas săo as colunas chamadas de chave primária de cada tabela, isto é, as colunas que identificarăo unicamente cada linha de dados de cada tabela. A coluna destacada na tabela Fornecedores é a cod_fornecedor. Isto significa que cada fornecedor deverá ter um código único, representado nessa coluna, e esse código identificará apenas um fornecedor.
A coluna cod_fornecedor aparece também na tabela Materiais. Isto serve para identificarmos que aquele material é oferecido pelo fornecedor que aparecer com o código ao lado. A coluna cod_fornecedor, quando aparece na tabela Materiais para definir o relacionamento, é chamada de chave estrangeira. A Listagem 1 apresenta os dados de exemplo desse conjunto de tabelas.
select * from fornecedores;
+-----------+-------------------------------------------+----------------+----------------------+
| cod_forne | nome | cidade_sede | grupo_cod_fornecedor |
+-----------+-------------------------------------------+----------------+----------------------+
| ABC | ABC Materiais Eletricos | Vitoria | NULL |
| XYZ | XYZ Materiais de Escritorio | Rio de Janeiro | HiX |
| Hidra | Hidra Materiais Hidraulicos | Sao Paulo | HiX |
| HiX | HidraX Materiais ElČtricos e Hidraulicos | Sao Paulo | NULL |
+-----------+-------------------------------------------+----------------+----------------------+
select cod_material, cod_fornecedor, nome, descricao from materiais order by cod_material;
+--------------+----------------+----------------------------+---------------------------------+
| cod_material | cod_fornecedor | nome | descricao |
+--------------+----------------+----------------------------+---------------------------------+
| 123 | ABC | Tomada eletrica 10A Nova | Tomada eletrica 10A padrao novo |
| 234 | ABC | Disjuntor 25A | Disjuntor eletrico 25A |
| 345 | XYZ | Resma Papel A4 | Resma papel branco A4 |
| 456 | XYZ | Toner Imp HR5522 | Toner impressora HR5522 |
| 678 | Hidra | Cano PVC 1/2 | Cano PVC 1/2 pol |
| 679 | Hidra | Cano PVC 3/4 | Cano PVC 3/4 pol |
| 680 | Hidra | Medidor hidr 1/2 | Medidor hidraulico 1/2 pol |
| 681 | Hidra | Joelho 1/2 | Conector Joelho 1/2 pol |
| 682 | Hidra | Junta 1/2 | Cano PVC 1/2 pol |
| 1234 | ABC | Tomada eletrica 20A Nova | Tomada eletrica 20A padrao novo |
| 2345 | XYZ | Caneta Azul | Caneta esferografica azul |
| 4567 | XYZ | Grapeador | Grampeador mesa pequeno |
| 4568 | XYZ | Caneta Marca Texto Amarela | Caneta Marca Texto Amarela |
| 4569 | XYZ | Lapis HB | Lapis Preto HB |
+--------------+----------------+----------------------------+---------------------------------+
select cod_material, quant_estoque, quant_estoque_min,
cod_unidade from materiais order by cod_material;
+--------------+---------------+-------------------+-------------+
| cod_material | quant_estoque | quant_estoque_min | cod_unidade |
+--------------+---------------+-------------------+-------------+
| 123 | 12 | 5 | UN |
| 234 | 10 | 5 | UN |
| 345 | 32 | 20 | CX12 |
| 456 | 6 | 10 | UN |
| 678 | 6 | 10 | NULL |
| 679 | 8 | 10 | NULL |
| 680 | 3 | 2 | NULL |
| 681 | 18 | 15 | NULL |
| 682 | 0 | 15 | NULL |
| 1234 | 8 | 5 | UN |
| 2345 | 80 | 120 | UN |
| 4567 | 5 | 5 | UN |
| 4568 | 6 | 15 | CX100 |
| 4569 | 15 | 25 | UN |
+--------------+---------------+-------------------+-------------+
select * from pedidos;
+------------+----------------+-------------+------------------+-------------+-------------+
| num_pedido | cod_fornecedor | data_pedido | data_recebimento | quant_itens | valor_total |
+------------+----------------+-------------+------------------+-------------+-------------+
| 111 | XYZ | 2015-02-25 | 2015-03-31 | 200 | 75.00 |
| 115 | Hidra | 2014-02-10 | 2014-04-10 | 50 | 65.00 |
| 120 | XYZ | 2015-03-01 | 2015-03-21 | 200 | 75.00 |
+------------+----------------+-------------+------------------+-------------+-------------+
select * from itens_pedidos;
+------------+--------------+--------------+----------------+
| num_pedido | cod_material | quant_pedida | valor_unitario |
+------------+--------------+--------------+----------------+
| 111 | 2345 | 100 | 0.50 |
| 111 | 4569 | 100 | 0.25 |
| 115 | 682 | 50 | 1.30 |
| 120 | 4567 | 5 | 76.00 |
+------------+--------------+--------------+----------------+
select * from unidades;
+-------------+------------------------+
| cod_unidade | nome |
+-------------+------------------------+
| UN | Unidades |
| KG | Kilogramas |
| LT | Litros |
| CX12 | Caixa com 12 unidades |
| CX100 | Caixa com 100 unidades |
+-------------+------------------------+
Quando estamos falando do acesso aos dados de uma base de dados, eles podem serem chamados conjuntos, conjuntos de dados. Ao decorrer deste artigo vamos utilizar desta comparaçăo para facilitar o entendimento dos exemplos.
A teoria dos conjuntos estuda coleçőes de elementos. Associando com bancos de dados, nossos elementos săo os dados das tabelas. Utilizando nosso modelo de dados definido para este artigo, podemos identificar alguns exemplos de conjuntos de dados:
E, relembrando os conceitos combinaçăo de conjuntos temos:
A primeira característica da instruçăo SELECT que gostaríamos de apresentar nesse artigo é o caso mais simples de join, ou como se obter informaçőes de mais de uma tabela simultaneamente no mesmo comando. Ou, como unir ou juntar as informaçőes de mais de uma tabela na mesma instruçăo.
A sintaxe da instruçăo SELECT com uso de joins é:
SELECT <lista de colunas>
FROM <nome de uma ou mais tabelas>
WHERE <lista de condiçőes>O principal item a ser destacado agora é que, na cláusula FROM, em vez de apresentarmos o nome de apenas uma tabela, podemos incluir uma lista de tabelas, separadas por vírgulas. Temos ainda a mesma lista de colunas após a palavra SELECT e os mesmos tipos de condiçăo encontradas na cláusula WHERE.
Começando diretamente com um exemplo, se nós quiséssemos trazer a lista de todos os materiais junto ao nome dos seus fornecedores correspondentes, teríamos a instruçăo escrita da seguinte forma:
SELECT fornecedores.nome, materiais.nome
FROM fornecedores, materiais;Além da lista das duas tabelas, fornecedores e materiais, na cláusula FROM, temos ainda uma outra característica na lista de colunas seguidas ŕ palavra SELECT: cada coluna está prefixada com o nome da sua respectiva tabela. Isso só é necessário porque a coluna “nome” existe nas duas tabelas. Por esse motivo, temos que dizer para o SGBD de qual coluna, de qual tabela, estamos nos referenciando.
Tudo seria muito simples se pudéssemos parar um “join” por aqui, porém, o comando năo pode ser escrito apenas dessa forma. Desse jeito, o SGBD năo sabe como as duas tabelas se relacionam.
E sem dizermos como as tabelas Fornecedores e Materiais se relacionam, o SGBD vai interpretar que ele deve trazer para vocę todos os materiais para cada linha de fornecedor que ele encontrar.
Isto é, ele vai entender que o relacionamento existente é: todas as linhas da tabela de fornecedores se relacionam com todas as linhas da tabela de materiais e isso năo é verdade. Na realidade, um material é oferecido por apenas um fornecedor e nós precisamos dizer isso ao SGBD.
E a forma de dizer isso é incluindo uma restriçăo na cláusula WHERE onde vamos dizer para o banco de dados que ele deve nos trazer apenas os materiais relacionados aos seus fornecedores correspondentes, ou de outra forma, ele deve apresentar todos os fornecedores e os materiais que cada um tem disponível para comercializar. Assim, nosso comando complementado com a cláusula WHERE, ficaria conforme a Listagem 2.
SELECT fornecedores.nome “Nome Fornecedor”, materiais.nome “Nome Material”
FROM fornecedores, materiais
WHERE fornecedores.cod_fornecedor = materiais.cod_fornecedor;Esta restriçăo diz que o banco só deve nos retornar os nomes dos fornecedores e materiais para as linhas onde o código do fornecedor seja igual em ambas as tabelas. O resultado da execuçăo dessa instruçăo está representado na Listagem 3.
+--------------------------------+----------------------------------+
| Nome Fornecedor | Nome Material |
+--------------------------------+----------------------------------+
| ABC Materiais Eletricos | Tomada eletrica 10A Nova |
| ABC Materiais Eletricos | Tomada eletrica 20A Nova |
| ABC Materiais Eletricos | Disjuntor 25A |
| XYZ Materiais de Escritorio | Caneta Azul |
| XYZ Materiais de Escritorio | Resma Papel A4 |
| XYZ Materiais de Escritorio | Toner Imp HR5522 |
| XYZ Materiais de Escritorio | Grapeador |
| XYZ Materiais de Escritorio | Caneta Marca Texto Amarela |
| XYZ Materiais de Escritorio | Lapis HB |
| Hidra Materiais Hidraulicos | Cano PVC 1/2 |
| Hidra Materiais Hidraulicos | Cano PVC 3/4 |
| Hidra Materiais Hidraulicos | Medidor hidr 1/2 |
| Hidra Materiais Hidraulicos | Joelho 1/2 |
| Hidra Materiais Hidraulicos | Junta 1/2 |
+-------------------------------+-----------------------------------+Observe que aqui neste primeiro exemplo já estamos utilizando a definiçăo do relacionamento entre a tabela de Fornecedores e Materiais que apresentamos no modelo de dados.
Este é um dos conceitos principais de bancos de dados e que, no momento em que escrevemos uma instruçăo SELECT, deve estar em nossa mente, ou ao nosso alcance para consulta.
Se cod_fornecedor é a coluna que define o relacionamento entre as tabelas, entăo esta restriçăo tem que ser informada ao SGBD para que o relacionamento seja feito de forma correta. Foi por esse motivo que a cláusula WHERE foi inserida, informando que o cod_fornecedor das duas tabelas deve ser igual.
Observe também que colocamos “Nome Fornecedor” e “Nome Material” ao lado do nome do fornecedor e do material, separados apenas por um espaço.
Estes săo considerados nomes alternativos para as colunas, ou alias. O primeiro e principal objetivo desses alias é dar um nome melhor a cada coluna.
Já descrevemos a lógica da existęncia da restriçăo “fornecedores.cod_fornecedor = materiais.cod_fornecedor”, mas năo falamos ainda sobre o porquę esta restriçăo melhora a performance do comando.
Aqui já entra um conceito de implementaçăo física do banco de dados e que normalmente é criado na base de dados de todas as aplicaçőes antes dos desenvolvedores terem acesso a elas. Normalmente, o desenvolvedor năo precisaria saber disso, pois o administrador de banco de dados (DBA) já fez esse trabalho e já entrega a base de dados disponível com essa característica.
Este conceito é: para toda chave primária e toda chave estrangeira definidas em uma base de dados, devem existir índices de acesso correspondentes a elas. Sem nos aprofundarmos muito, conceitualmente os índices săo aceleradores de acesso a uma tabela do banco de dados.
Quando o DBA sabe que uma tabela será muito acessada por uma coluna especificamente, ele cria um índice para esta coluna. Isso faz com que o SGBD encontre a linha que vocę precisa de maneira muito mais eficiente do que ler todas as linhas da tabela para trazer as que vocę solicitou.
E, por definiçăo, o DBA cria índices para todas as chaves primárias e estrangeiras de todas as tabelas. Por isso, a performance do comando, quando é incluída a restriçăo pelas chaves primárias e secundárias, tem uma performance melhor. O SGBD saberá se resolver de uma forma mais eficiente.
Neste momento, também é importante notar que normalmente năo se relacionam tabelas por colunas que năo sejam as chaves primárias e secundárias das respectivas tabelas. Normalmente, este relacionamento năo fará sentido se for feito por outras colunas. Mas, existirăo exemplos onde, se vocę năo conhecer o modelo de relacionamentos entre as tabelas de uma base de dados, vocę será tentado a estabelecer um relacionamento por outras colunas. Isso năo só poderá trazer para vocę um resultado equivocado como também năo terá uma boa performance.
Vamos introduzir neste ponto um novo conceito que ajudará muito na clareza e facilidade de leitura da instruçăo SELECT: o alias do nome das tabelas. O alias é um sinônimo que vocę atribui a uma tabela. É uma outra forma de se referenciar ao nome da mesma. Quando escrevemos a instruçăo, prefixamos as colunas com os nomes das respectivas tabelas.
Simples e claro até aqui porque nosso exemplo possui apenas duas colunas. Se a instruçăo possuísse vinte colunas e vocę tivesse que prefixar o nome das respectivas tabelas antes de cada uma delas, seria um desperdício de espaço e tempo e, além disso, a legibilidade do comando estaria prejudicada. Por isso existe o alias. Veja a seguir o mesmo exemplo reescrito utilizando um alias simples para cada tabela:
SELECT f.nome, m.nome
FROM fornecedores f, materiais m
WHERE f.cod_fornecedor = m.cod_fornecedor;Note que colocamos uma letra “f” após apresentarmos a tabela fornecedores na cláusula FROM e da mesma forma, colocamos uma letra “m” após a tabela materiais. O “f” e “m” săo os alias que criamos para as tabelas fornecedores e materiais respectivamente. Poderia ser qualquer nome ou abreviaçăo, năo apenas uma letra.
Dessa forma, apresentado após o nome de uma tabela ele será o alias para aquela tabela e o SGBD saberá de qual tabela vocę está falando quando fizer referęncia a ele. Assim, todas as referęncias ŕs tabelas foram substituídas pelos alias correspondentes dentro da instruçăo, tornando o comando mais claro e legível.
Continuando nossa definiçăo de como “juntar” as informaçőes de duas ou mais tabelas, existe um conceito muito importante que devemos apresentar antes de prosseguir.
No exemplo que fizemos até aqui, listamos os nomes dos fornecedores e respectivos nomes dos materiais. Note que listamos apenas as informaçőes de fornecedores que estavam associadas aos respectivos materiais, isto é, quando os fornecedores e materiais existiam e eram iguais em ambas as tabelas. Este conceito de join é conhecido como inner join. Em um relacionamento desse tipo, somente serăo listadas as linhas de fornecedores e materiais correspondentes que existam em ambas as tabelas.
Pode existir, porém, um caso onde gostaríamos de listar todas as linhas de uma tabela mesmo que năo exista uma linha correspondente na tabela relacionada. Por exemplo, podemos querer a lista de todos os fornecedores junto com a soma de todos os pedidos realizados para eles, mas queremos todos os fornecedores mesmo aqueles que nunca tenhamos pedidos feitos para eles.
Para isso, precisamos fazer o join exatamente como realizado, porém com uma diferença sutil, para informar ao SGBD que queremos todos os fornecedores. Veja na Listagem 4 como ficaria este exemplo utilizando o inner join.
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome;Se o comando for executado dessa forma, o SGBD retornará a lista dos fornecedores que já fizeram algum tipo de pedido e o seu total ao lado de cada um. Mas năo é exatamente isso que queremos. Queremos todos os fornecedores, mesmo que nunca tenham feito pedidos. A alteraçăo sutil está na Listagem 5.
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor(+)
GROUP BY f.nome;Note o “(+)” ao lado do código do fornecedor, da tabela dos pedidos. Esta notaçăo utilizada pelo SGBD Oracle, diz para que tenhamos todas as linhas de fornecedores, mesmo que năo existam pedidos correspondentes, isto é, neste caso os pedidos sejam opcionais. O resultado da execuçăo deste comando está na Listagem 6.
+---------------------------------------------+---------------------+
| nome | SUM(p.valor_total) |
+---------------------------------------------+---------------------+
| ABC Materiais Eletricos | NULL |
| Hidra Materiais Hidraulicos | 65.00 |
| HidraX Materiais ElČtricos e Hidraulicos | NULL |
| XYZ Materiais de Escritorio | 150.00 |
+---------------------------------------------+---------------------+Os exemplos apresentados funcionam e săo a forma mais clara de se apresentar inner e outer joins. Utilizando sempre a cláusula WHERE para colocar as restriçőes de seleçăo, incluindo as restriçőes de join. Esta notaçăo, conhecida como notaçăo implícita, para inner joins existe para qualquer SGBD, porque ela năo possui nenhuma diferença de uma cláusula WHERE tradicional. Porém, o exemplo de outer join apresentado utiliza a notaçăo implícita oferecida pelo SQL do SGBD Oracle.
Outros fornecedores de SGBD possuem sintaxes diferentes para estas notaçőes implícitas. O SQL Server, por exemplo, utiliza o “*=” na comparaçăo da cláusula WHERE para indicar que a tabela que está ŕ esquerda é a que se quer todos os registros.
O SQL ANSI, porém, possui uma sintaxe adicional para joins, chamada de notaçăo explícita, que padroniza a sintaxe de todos os tipos de join, onde os mesmos ficam representados na cláusula FROM, quando vocę declara as tabelas, e năo na cláusula WHERE como apresentamos nos exemplos.
Geralmente, as pessoas năo costumam gostar muito desta sintaxe porque ela fica cada vez mais complexa ŕ medida que vocę acrescenta tabelas ao join e isso dificulta a leitura. Mas esta é uma questăo de padronizaçăo, e devemos aqui apresentar esta sintaxe diferenciada, porque vocę certamente passará por ela ao longo da sua vida profissional. Existem ainda SGBDs que năo implementam nenhum tipo de notaçăo implícita para outer joins. Por este motivo, é mais importante ainda que vocę a conheça.
Nos exemplos que apresentamos, o inner join foi introduzido utilizando a notaçăo implícita. Essa instruçăo seria representada na notaçăo explícita da seguinte forma:
SELECT f.nome, m.nome
FROM fornecedores f INNER JOIN materiais m
ON f.cod_fornecedor = m.cod_fornecedor;Note que a cláusula WHERE foi suprimida nesse caso. Esta cláusula só apareceria se quiséssemos realmente fazer uma restriçăo dos dados por algum valor específico.
Nos exemplos que apresentamos, o outer join foi introduzido utilizando a notaçăo implícita. Essa instruçăo seria representada na notaçăo explícita conforme a Listagem 7.
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f LEFT OUTER JOIN pedidos p
ON f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome;Existem duas grandes vantagens na notaçăo explícita: sua clareza e padronizaçăo. E, de novo, ela é comum em todos os SGBDs do mercado.
O nosso exemplo de joins de várias tabelas será um relatório de todos os pedidos do męs de fevereiro incluindo as informaçőes dos pedidos e os itens dos pedidos.
Este é um exemplo que parece bem simples, basta fazer um join das tabelas de pedidos e de itens dos pedidos e apresentar todas as informaçőes de ambas as tabelas. Observe a Listagem 8.
SELECT p.*, ip.*
FROM pedidos p, itens_pedidos ip
WHERE p.num_pedido = ip.num_pedido AND
year(data_pedido) = 2015 AND
month(data_pedido) = 2;Temos o resultado dessa instruçăo na Listagem 9.
+--------------+------------------+--------------+---------------------+--------------+------+
| num_pedido | cod_fornecedor | data_pedido | data_recebimento | quant_itens | valor_total |
+--------------+------------------+---------------+---------------------+--------------+------+
| 111 | XYZ | 2015-02-25 | 2015-03-31 | 200 | 75.00 |
| 111 | XYZ | 2015-02-25 | 2015-03-31 | 200 | 75.00 |
+--------------+------------------+---------------+---------------------+--------------+------+
+--------------+---------------+----------------+----------------+
| num_pedido | cod_material | quant_pedida | valor_unitario |
+--------------+---------------+----------------+----------------+
| 111 | 2345 | 100 | 0.50 |
| 111 | 4569 | 100 | 0.25 |
+--------------+---------------+----------------+----------------+Mas năo temos alguma coisa estranha? O que săo esses vários códigos listados? Como saber quem săo os fornecedores e o nome dos materiais de cada pedido? Estas informaçőes năo estăo nas tabelas de pedidos e itens dos pedidos, elas estăo nas tabelas de fornecedores e materiais.
Assim, para incluir essas informaçőes temos que incluir as tabelas onde elas existem: o nome dos fornecedores na tabela de fornecedores, o nome dos materiais na tabela de materiais, etc.
O comando completo ficaria conforme a Listagem 10, e seu resultado conforme a Listagem 11.
SELECT f.nome, p.num_pedido, p.data_pedido, p.data_recebimento,
p.quant_itens, p.valor_total, m.nome, ip.quant_pedida,
u.nome, ip.valor_unitario
FROM pedidos p,
itens_pedidos ip,
fornecedores f,
materiais m,
unidades u
WHERE p.num_pedido = ip.num_pedido AND
p.cod_fornecedor = f.cod_fornecedor AND
ip.cod_material = m.cod_material AND
m.cod_unidade = u.cod_unidade AND
year(data_pedido) = 2015 AND
month(data_pedido) = 2;
+------------------------------+--------------+---------------+--------------------+-------+
| nome | num_pedido | data_pedido | data_recebimento | quant_itens |
+------------------------------+--------------+---------------+--------------------+-------+
| XYZ Materiais de Escritorio | 111 | 2015-02-25 | 2015-03-31 | 200 |
| XYZ Materiais de Escritorio | 111 | 2015-02-25 | 2015-03-31 | 200 |
+------------------------------+--------------+---------------+--------------------+-------+
+------------+--------------+---------------+-----------+----------------+
| valor_total | nome | quant_pedida | nome | valor_unitario |
+------------+--------------+---------------+-----------+----------------+
| 75.00 | Caneta Azul | 100 | Unidades | 0.50 |
| 75.00 | Lapis HB | 100 | Unidades | 0.25 |
+-------------+-------------+---------------+------------+----------------+ Note que para apresentar todas as informaçőes textuais que precisávamos, tivemos que unir cinco tabelas, tręs além das tabelas bases iniciais. Note também que existe uma condiçăo de join para cada uma delas.
Seguindo o modelo de relacionamentos das tabelas, temos a tabela Pedidos que se relaciona com a tabela itens de pedidos. Isso está representado na cláusula WHERE por “p.num_pedido = ip.num_pedido”.
Para obter o nome dos fornecedores, tivemos que incluir o relacionamento de pedidos e fornecedores representado por “p.cod_fornecedor = f.cod_fornecedor”.
Já os materiais aparecem ao nível dos itens dos pedidos e para relacioná-los incluímos “ip.cod_material = m.cod_material”. E, finalmente, os itens dos pedidos também possuem unidades, que săo descritas na tabela de unidades, que se relacionam com os materiais e foram representados por “m.cod_unidade = u.cod_unidade”.
Observe também que incluímos na lista dos campos a retornar o nome dos fornecedores (f.nome), materiais (m.nome), e unidades (u.nomes).
O resultado apresentado năo tem a aparęncia de um relatório, năo possui uma formataçăo apresentável e também todas as informaçőes da tabela de pedidos estăo aparecendo repetidamente em cada linha correspondente a cada item do pedido. Isso é assim mesmo.
Esses săo os dados que vocę utilizará em seu programa, ou no seu software gerador de relatórios, para apresentaçăo. Os dados repetidos serăo agrupados pelo seu programa, ou pelo gerador de relatórios, para serem apresentados uma única vez. A sintaxe que utilizamos para as funçőes de ano e męs, e que săo a nossa única restriçăo real dos dados que queremos, săo do SGBD MySQL.
Como ficaria este join utilizando a notaçăo explícita? Observe a Listagem 12.
SELECT f.nome, p.num_pedido, p.data_pedido, p.data_recebimento,
p.quant_itens, p.valor_total, m.nome, ip.quant_pedida,
u.nome, ip.valor_unitario
FROM pedidos p
INNER JOIN fornecedores f ON p.cod_fornecedor = f.cod_fornecedor
INNER JOIN itens_pedidos ip ON p.num_pedido = ip.num_pedido
INNER JOIN materiais m ON ip.cod_material = m.cod_material
INNER JOIN unidades u ON m.cod_unidade = u.cod_unidade
WHERE year(data_pedido) = 2015 AND
month(data_pedido) = 2;Utilizar a notaçăo implícita ou explícita pode ser uma questăo de gosto, de clareza do texto da instruçăo ou uma questăo de padronizaçăo. Algumas empresas podem solicitar que os desenvolvedores sigam um padrăo na elaboraçăo das queries. Todos, porém, funcionam da mesma forma.
Aqui entra um questionamento interessante que povoa as mentes de muitos desenvolvedores: Por que entăo năo fazer duas queries separadas em vez de apenas uma? Por que agrupar todas as informaçőes de pedidos e itens dos pedidos em uma única query, mais complexa, que também me trará um esforço de programaçăo razoável, se eu posso ter duas queries, uma delas, um SELECT, listando apenas os pedidos, e para cada pedido uma segunda query para selecionar os seus itens?
A resposta para este questionamento é uma só: Performance! A cada vez que o SGBD tem uma nova query para execuçăo, ele tem que seguir os seguintes passos, e que podem variar de um fabricante para outro:
Os dois primeiros itens săo também conhecidos como “parse” da instruçăo. Eles normalmente consomem décimos ou centésimos de segundo. O terceiro item, a execuçăo da query, é o que normalmente consome um pouco mais, mas normalmente năo mais que alguns poucos segundos se a instruçăo estiver bem escrita.
A princípio, somente com estas informaçőes, năo haveria porque fazer o join. Quem năo pode aguardar dois ou tręs segundos por um relatório? O argumento de performance teria ido por água abaixo se năo houvessem a seguintes perguntas: Quantos pedidos vamos tratar? Quantos itens existem em média para cada pedido?
Se a resposta for uma dezena de pedidos, realmente năo teremos problemas de performance. Para falar a verdade, năo precisaríamos nem desenvolver uma aplicaçăo para isso. Mas, e se a resposta for que temos pedidos na ordem dos milhares por męs? Tomando como exemplo um montante de aproximadamente dois mil pedidos mensais, com uma média de cinco itens por pedido, se separássemos este join em duas queries, uma de pedidos e outra para os itens de cada pedido, teríamos a primeira sempre executando uma única vez.
Sem problemas. Mas, a segunda seria executada duas mil vezes. Se esta segunda instruçăo demorar um segundo para executar, o tempo total de execuçăo da segunda query 2000 vezes seria de 2000 segundos! Normalmente ninguém está disposto a aguardar mais de 30 minutos para ter o resultado de um relatório simples como este.
Mas ainda vamos ter alguém que afirme: mas o join de todas essas tabelas numa única query vai demorar mais para executar que se tivéssemos duas queries separadas.
Ainda assim, por que juntar? E a resposta é: sim, o join vai demorar um pouco mais. Mas se ele demorar mais do que 3 segundos, já poderíamos dizer que tem algo mais errado com o seu banco de dados.
Portanto, o SGDB executar para vocę o join de várias tabelas e te retornar o resultado todo de uma vez, em 99% dos casos será mais rápido que executar várias queries repetidamente. Portanto, o esforço vale a pena.
No exemplo de outer join que mostramos, a restriçăo f.cod_fornecedor = p.cod_fornecedor (+), da sintaxe implícita, fazia com que trouxéssemos todos os fornecedores, mesmo que năo houvessem pedidos correspondentes. Esta característica foi representada na sintaxe explícita, na cláusula FROM, dessa forma: FROM fornecedores f LEFT OUTER JOIN pedidos p ON f.cod_fornecedor = p.cod_fornecedor.
Mas e se quiséssemos o contrário? Se quiséssemos ter a lista de todos os pedidos, mesmo que năo existissem fornecedores correspondentes? Isso năo faz muito sentido no nosso exemplo, mas tecnicamente é possível. Vocę já poderia dizer que, na forma implícita, basta colocar o (+) do outro lado da igualdade, fazendo f.cod_fornecedor(+) = p.cod_fornecedor. O que é verdade e funciona. Aí teríamos a instruçăo completa desta forma:
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor(+) = p.cod_fornecedor;Mas temos ainda a forma explícita de notaçăo do outer join. E nessa forma ainda teríamos duas formas de representá-lo. A primeira, invertendo as tabelas Fornecedores e Pedidos na cláusula FROM, em relaçăo ao exemplo apresentado:
SELECT f.nome, SUM(p.valor_total)
FROM pedidos p LEFT OUTER JOIN fornecedores f
ON f.cod_fornecedor = p.cod_fornecedor;E a segunda utilizando uma outra sintaxe do outer join, o right outer join. Esta sintaxe diz ao SGBD para fazer exatamente o que precisamos, considerar a tabela da direita, pedidos, como a que terá todas as suas linhas apresentadas, independentemente de existirem fornecedores correspondentes. A instruçăo seria entăo escrita desta forma:
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f RIGHT OUTER JOIN pedidos p
ON f.cod_fornecedor = p.cod_fornecedor;Em todos os exemplos apresentados teríamos o mesmo resultado, e a performance da instruçăo seria exatamente a mesma. Săo apenas formas diferentes de se escrever uma mesma instruçăo.
Mas as sintaxes para diferentes possibilidades de joins năo terminam aqui. Temos ainda o full outer join. É importante salientar que este năo é suportado por alguns fabricantes de SGBDs.
O sentido do full outer join para nós seria:
No full outer join nós queremos as duas condiçőes simultaneamente. E a nossa instruçăo seria escrita conforme a Listagem 13.
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f FULL OUTER JOIN pedidos p
ON f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome;O resultado dessa instruçăo está representado na Listagem 14.
+-------------------------------------------+-------------------------+
| nome | SUM(p.valor_total) |
+--------------------------------------------+------------------------+
| ABC Materiais Eletricos | NULL |
| Hidra Materiais Hidraulicos | 65.00 |
| HidraX Materiais ElČtricos e Hidraulicos | NULL |
| XYZ Materiais de Escritorio | 150.00 |
+---------------------------------------------+-----------------------+Mas e se o full outer join năo for implementado pelo SGBD que vocę usa? A soluçăo é fazermos as duas queries independentes, uma para cada um dos joins definidos de forma separada anteriormente e depois utilizar a nossa teoria de conjuntos para juntar o resultado de ambas.
Para isso, vamos apresentar como fazer a uniăo dos dois conjuntos de dados do exemplo anterior do full outer join. Vamos introduzir o conceito da uniăo de queries.
Nosso conceito já está apresentado no exemplo do full outer join. Precisamos unir o resultado de duas queries, ou dois conjuntos de dados. A uniăo desses conjuntos de dados é realizada pelo operador union. Ele une o resultado de duas instruçőes SELECT.
Mas, para que isso aconteça, temos que ter um único princípio básico: o resultado de ambas as queries tęm que ter as mesmas colunas, na mesma sequęncia, e do mesmo tipo.
O SGBD năo tem como saber se semanticamente os dados săo os mesmos, por isso ele avalia apenas se o número de colunas é igual e se o tipo das colunas correspondentes em ambas as queries é igual ou equivalente.
Dessa forma, poderíamos simular o full outer join utilizando o operador union conforme a Listagem 15.
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f LEFT OUTER JOIN pedidos p
ON f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome
UNION
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f RIGHT OUTER JOIN pedidos p
ON f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome;O resultado da execuçăo deste comando será exatamente o mesmo resultado do full outer join apresentado na Listagem 14.
O operador union possui ainda a opçăo all. O operador union, quando escrito union all, simplesmente junta os dois resultados das duas queries para fornecer para vocę um resultado único, de um único SELECT, porém sem nenhuma análise sobre os dados unidos.
Existem casos onde o resultado da primeira e da segunda queries podem apresentar linhas com os mesmos valores em todas as colunas, isto é, linhas duplicadas. O operador union puro, sem a opçăo all, elimina essas duplicidades para vocę.
É como na teoria dos conjuntos. Se tivéssemos dois conjuntos de frutas:
O resultado do union all seria: laranja, limăo, maracujá, pera, uva verde e limăo. Note que o limăo apareceu duas vezes. Pode ser que vocę queira esse tipo de resultado, para quantificar, por exemplo, quantas vezes uma fruta aparece nos seus conjuntos.
Mas pode ser que năo, que vocę queira o conjunto final sem essas duplicidades. Aí, nesse caso, o resultado do union puro seria o ideal para vocę, porque traria como resposta a lista de frutas sem repetiçăo: laranja, limăo, maracujá, pera e uva verde.
A diferença dos resultados vocę já entendeu. O que é importante dizer agora é que, para retirar as duplicidades dos dois conjuntos, o operador union puro precisará trabalhar mais, e gastará mais tempo e processamento para realizar seu trabalho. Portanto, antes de utilizá-lo, tenha certeza de que é esse o resultado que vocę quer.
O exemplo apresentado ilustrou como o operador de queries union funciona unindo o resultado de duas queries. Mas e se quiséssemos que o resultado final ainda fosse classificado alfabeticamente pelo nome do fornecedor?
Se colocássemos a cláusula ORDER BY dentro de cada uma das queries, teríamos cada uma classificada, mas năo teríamos o resultado final classificado. Na realidade, os SGBDs nem permitem que vocę coloque cláusulas ORDER BY em queries que serăo ainda unidas.
A soluçăo nesse caso é colocar o ORDER BY no fim da última query. Assim, nosso resultado ficaria conforme a Listagem 16.
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f LEFT OUTER JOIN pedidos p
ON f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome
UNION
SELECT f.nome, SUM(p.valor_total)
FROM fornecedores f RIGHT OUTER JOIN pedidos p
ON f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome
ORDER BY f.nome;Simples, rápido e funcional. Teremos o resultado final da uniăo classificado pelo nome do fornecedor.
E vamos caminhando na teoria dos conjuntos. Vamos apresentar agora o operador de interseçăo. A interseçăo de dois conjuntos é o conjunto do que existir de comum, coincidente ou igual, entre os dois primeiros.
Utilizando o exemplo de conjuntos apresentado, para os conjuntos de frutas cítricas e frutas verdes, o resultado da sua interseçăo seria apenas a fruta limăo, que aparece em ambos os conjuntos iniciais.
Vamos entăo concretizar nosso conhecimento em interseçăo de queries apresentando duas queries de exemplo:
O resultado que vamos querer da sua interseçăo serăo os resultados de ambas, portanto serăo os fornecedores de quem compramos mais de R$50 em pedidos e, ao mesmo tempo, năo compramos dele há mais de um ano.
Vamos por partes. Para termos o resultado da primeira consulta precisaríamos executar o comando da Listagem 17.
SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome
HAVING SUM(p.valor_total)>50;Podemos ver seu resultado na Listagem 18. Note que fizemos um join de fornecedores e pedidos (f.cod_fornecedor = p.cod_fornecedor) e agrupamos pelo nome do fornecedor (GROUP BY f.nome).
Note que năo apresentamos a soma no resultado da query. Só queremos a lista dos fornecedores com esta condiçăo. Temos também que filtrar os fornecedores cujo total de pedidos seja superior ao valor estabelecido.
Se parássemos antes de filtrar, năo teríamos só os dos que compramos mais de R$50, teríamos todos. Portanto, precisamos acrescentar a cláusula HAVING para filtrar o resultado da agregaçăo.
+----------------------------------+
| nome |
+----------------------------------+
| Hidra Materiais Hidraulicos |
| XYZ Materiais de Escritorio |
+----------------------------------+ Para a segunda consulta precisaríamos da consulta apresentada na Listagem 19.
SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor AND
p.data_pedido < current_date - interval 1 year;O resultado desta query está na Listagem 20. Note que fizemos um join simples entre Fornecedores e Pedidos, semelhante a query anterior e que filtramos os pedidos com a data de pedido anterior a um ano em relaçăo ŕ data atual (p.data_pedido < current_date - interval 1 year). Esta sintaxe é do SGBD MySQL.
+----------------------------------+
| nome |
+----------------------------------+
| Hidra Materiais Hidraulicos |
+----------------------------------+Agora o que precisamos fazer é a interseçăo das duas instruçőes, conforme a Listagem 21.
SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome
HAVING SUM(p.valor_total)>50
INTERSECT
SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor AND
p.data_pedido < current_date - interval 1 year;O resultado está apresentado na Listagem 22, e como podemos observar, apenas o fornecedor que está presente no resultado das duas consultas é o resultado da interseçăo.
Porque năo fizemos uma única query para obter o resultado esperado das duas condiçőes? É possível se obter o mesmo resultado de outras formas. Utilizamos o exemplo apenas para demonstrar o uso do operador INTERSECT. Tudo que vai nos guiar em utilizar uma ou outra forma de se montar uma instruçăo SELECT é: clareza no detalhamento da instruçăo, para que ela seja legível e compreensível por quem mais precisar lę-la, e performance. Năo adianta escrevermos uma instruçăo legível, mas que demora longos minutos para executar.
+---------------------------------+
| nome |
+---------------------------------+
| Hidra Materiais Hidraulicos |
+---------------------------------+Já que estamos associando a teoria de conjuntos ŕ construçăo de consultas de acesso ŕs bases de dados, vamos mostrar o último operador de queries do nosso artigo. Ele opera a subtraçăo de queries, ou subtraçăo de conjuntos.
Tomaremos como base exatamente as mesmas duas queries do exemplo da interseçăo de consultas. Mas dessa vez queremos como resultado apenas os fornecedores de quem já compramos mais de R$50 em Pedidos, e que estăo ativos, isto é, de quem fizemos compras mais recentes do que um ano.
Ou, para utilizar a mesma query e atender ao nosso exemplo de subtraçăo de consultas, que este năo esteja na lista dos fornecedores de quem năo compramos a mais de um ano.
Como as queries dos exemplos um e dois já foram apresentadas e detalhadas, o que precisamos agora é somente a interaçăo entre elas de forma que o resultado da segunda seja excluído, subtraído, do resultado da primeira. Observe a Listagem 23.
SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor
GROUP BY f.nome
HAVING SUM(p.valor_total)>50
MINUS
SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor AND
p.data_pedido < current_date - interval 1 year;Apresentamos o resultado na Listagem 24, onde podemos ver que estăo exatamente os fornecedores resultantes da primeira consulta, excluídos os existentes na segunda consulta.
+-----------------------------+
| nome |
+-----------------------------+
| XYZ Materiais de Escritorio |
+-----------------------------+É importante salientar que alguns SGBDs também năo implementam o operador MINUS, mas, novamente, como existem inúmeras maneiras de se escrever uma query, e estamos utilizando o SGBD MySQL nestes exemplos, vou apresentar uma forma de contornar esta situaçăo.
Vamos apresentar um outro operador e uma outra forma de se escrever duas queries, uma dentro da outra. Vamos apresentar rapidamente o conceito de subqueries com o exemplo da Listagem 25 para suprir a falta do MINUS no MySQL.
SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor AND
f.nome NOT IN
(SELECT f.nome
FROM fornecedores f, pedidos p
WHERE f.cod_fornecedor = p.cod_fornecedor AND
p.data_pedido < current_date - interval 1 year
)
GROUP BY f.nome
HAVING SUM(p.valor_total)>50;Note que uma query está explicitamente dentro da outra. A interpretaçăo aqui seria: queremos a lista dos fornecedores dos quais já compramos mais de R$50 em Pedidos, porém, este resultado năo pode conter os nomes dos fornecedores de quem năo compramos a mais de um ano.
O operador NOT IN faz exatamente isso, exclui os fornecedores que estăo no conjunto retornado pela query seguinte. Observe também que a query dos fornecedores de quem năo compramos a mais de um ano está entre paręntesis.
O objetivo dos paręntesis é separar esta subquery da query mais externa, para que o SGBD năo misture as cláusulas da primeira query com as cláusulas da segunda. E desta forma, resolvemos a ausęncia do operador MINUS. O resultado de ambos os exemplos é exatamente o mesmo.
É importante apresentar também um conceito de join que, embora năo seja muito popular, ocorre de maneira mais comum do que possamos imaginar. O “auto-join”, ou o join de uma tabela com ela mesma.
Quando vemos este exemplo de join pela primeira vez, achamos que isso seria apenas uma teoria, năo faria sentido na vida real. Que seria uma das coisas que provavelmente nós nunca utilizaríamos profissionalmente e que estavam nos ensinando só para que nós soubéssemos que existia. Vamos apresentar um exemplo, diferente do modelo de dados apresentado, e que se utiliza do autorelacionamento para sua implementaçăo.
Imagine que tivéssemos uma tabela de funcionários de uma empresa. Nesta tabela tem que estar cadastrados todos os funcionários dessa empresa, incluindo a coordenaçăo, geręncia, diretoria, etc.
E queremos representar nesse modelo de dados quem é o chefe de quem. Em outras palavras, queremos conseguir representar quem é o coordenador de um ou um grupo de funcionários, quem é o gerente desse coordenador, quem é o diretor desse gerente, etc. E estamos assumindo que cada funcionário possui apenas um chefe.
Esta implementaçăo pode ser feita de várias maneiras, mas a maneira que escolhemos foi uma das mais simples: dizer com linha de cadastro do funcionário qual é o chefe dele.
Para representar isso no modelo de dados, precisaríamos apenas incluir uma coluna a mais nessa tabela, representando o código do funcionário que é o chefe desse funcionário.
Apresentaremos as colunas dessa tabela para o entendimento ficar mais fácil conforme a Figura 2.
Representamos apenas algumas colunas como exemplo da tabela de funcionários. Observe que existe uma coluna chamada matricula_chefe, que é onde será indicado qual é o chefe daquele funcionário. O funcionário chefe terá uma linha nesta mesma tabela para defini-lo.
Neste caso, como temos uma coluna da tabela que faz referęncia a uma outra linha da mesma tabela, dizemos que este é um auto relacionamento. Isto é, a tabela se relaciona com ela mesma e, no Modelo de Entidades e Relacionamentos, este auto relacionamento aparece como uma seta apontando para a própria tabela.
Vamos colocar alguns dados nessa tabela para que nosso exemplo fique mais concreto. Na Listagem 26 vocę poderá encontrar estes dados.
+-----------+-----------+---------+-----------------+
| matricula | nome | cargo | matricula_chefe|
+-----------+-----------+---------+-----------------+
| 1 | Marcus | Gerente | 2 |
| 2 | Marcelo | Diretor | NULL |
| 3 | Fernando | DBA | 1 |
| 4 | Leticia | DBA | 1 |
+-----------+----------+---------+-----------------+Agora, voltando ao auto join, como faríamos para listar o nome dos funcionários, seus respectivos cargos e o nome do chefe desse funcionário com o cargo do chefe? A soluçăo para nossa pergunta está na instruçăo da Listagem 27 e seu resultado na Listagem 28.
SELECT f.nome, f.cargo,
chefe.nome, chefe.cargo
FROM funcionarios f, funcionarios chefe
WHERE f.matricula_chefe = chefe.matricula;
+----------+---------+---------+----------+
| nome | cargo | nome | cargo |
+----------+---------+---------+----------+
| Fernando | DBA | Marcus | Gerente |
| Leticia | DBA | Marcus | Gerente |
| Marcus | Gerente | Marcelo | Diretor |
+----------+---------+---------+---------+Note que a tabela Funcionários aparece duas vezes no mesmo comando SELECT. Uma vez fazendo o papel da tabela de funcionários que queremos listar e a segunda vez, fazendo o papel da tabela dos chefes dos funcionários.
Colocamos um alias bem sugestivo na segunda representaçăo da tabela funcionários para ficar claro que, para a segunda estamos falando dos chefes, e năo dos funcionários (“funcionarios chefe”).
Perceba também que, da mesma forma que fizemos em todos os exemplos desse artigo, temos que representar como estas duas tabelas se relacionam.
Para isso, tivemos que dizer que a tabela de funcionários se relaciona com a tabela de chefes dos funcionários através do cod_funcionario_chefe dessa forma “f.cod_funcionario_chefe = chefe.cod_funcionario”. É como se tivéssemos realmente duas tabelas.
No resultado do exemplo do join, um inner join, observe que temos apenas tręs funcionários listados, e năo quatro como é a lista original dos funcionários. Observe que o funcionário que tem cargo de diretor năo aparece no resultado com o nome do seu chefe ao lado.
Note que nos dados originais o diretor apresenta um NULL no lugar da matrícula do chefe dele, isto é, ele năo tem chefe, ou o chefe dele năo está definido.
Para o exemplo, onde queríamos todos os funcionários com seus chefes ao lado, o resultado pode estar correto. Mas e se quiséssemos todos os funcionários com ou sem chefes? A soluçăo seria um outer join, onde incluiríamos todos os funcionários e os seus chefes seriam opcionais.
Este é o último conceito de join que vamos apresentar nesse artigo. Vamos mostrar este conceito aqui apenas para que vocę saiba que ele existe. Nunca vimos uma utilidade prática para ele e encontrá-lo numa query é motivo para pensarmos que estamos ŕ frente de um erro. Vocę vai entender o porquę.
Na sua notaçăo implícita, o cross join das tabelas de fornecedores e pedidos seria assim:
SELECT fornecedores.nome, materiais.nome
FROM fornecedores, materiais;
Vocę sentiu falta de alguma coisa? Este foi o nosso primeiro exemplo, onde dissemos que faltava a condiçăo de join e que neste caso, teríamos como retorno cada linha da tabela fornecedores listados ao lado de todas as linhas da tabela de materiais, isto é, como se multiplicássemos as linhas das duas tabelas. E concluímos que este join năo faria sentido dessa forma. Mas esta é a definiçăo do cross join!
Também podemos chamar este tipo de join de produto cartesiano entre as tabelas participantes. De novo a teoria de conjuntos.
Em alguns SGBDs ele é considerado como um erro de construçăo da instruçăo SELECT. Normalmente, sua execuçăo năo é impedida, mas em uma avaliaçăo do plano de execuçăo dessa query, isto é, o plano de como os dados serăo recuperados para serem apresentados para vocę, certamente teríamos uma sinalizaçăo de que o produto cartesiano existe para chamar sua atençăo para este possível erro na construçăo do join.
Se existe uma notaçăo implícita, existe também uma notaçăo explícita. Que seria assim:
SELECT fornecedores.nome, materiais.nome
FROM fornecedores CROSS JOIN materiais;
Onde fica explicitamente claro que queremos o produto cartesiano das duas tabelas. Mais uma vez, nem todos os SGBDs implementam este tipo de join.
Certamente, joins săo muito utilizados no dia a dia profissional de desenvolvedores de sistemas, e vocę certamente já construiu ou construirá vários. Tenha em mente tręs conceitos que destacamos ao longo desse artigo:
Um join deve ser escrito de forma a atender o resultado que vocę espera, que vocę consiga identificá-lo, lę-lo, de maneira direta e objetiva e ele deve executar de maneira eficiente. Esperamos ter dado base e argumentos suficientes para que vocę construa joins corretos e eficientes.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.