Veremos nesse artigo por que criar e como criar, como manter, qual a sua importância, melhores práticas, como funciona a “famosa” árvore binária, índices clusterizados e năo-clusterizados. Enfim, abordaremos tudo o que for importante saber para trabalhar bem essa feature básica e muito relevante nos bancos de dados objeto-relacionais.
Vale salientar, que os sources SQL / T-SQL aqui apresentados foram escritos e testados em ambiente Windows XP Professional, rodando SQL Server 2000 com Service Pack 4 instalado, usando o módulo Query Analyser.
O uso de índices pode trazer grandes melhorias para o desempenho do banco de dados. Pensando nisso, devemos entăo, primeiramente, entender como funciona o mecanismo que está trabalhando nos bastidores.
Os registros săo armazenados em páginas de dados, páginas estas que compőem o que chamamos de pilha, que por sua vez é uma coleçăo de páginas de dados que contém os registros de uma tabela. Cada página de dados tem seu tamanho definido em até 8 Kb, apresenta um cabeçalho, também conhecido como header, que contém arquivos de links com outras páginas e identificadores (hash) que ocupam a nona parte do seu tamanho total (8 Kb) e o resto de sua área é destinada aos dados. Quando săo formados grupos de oito páginas (64 Kb), chamamos este conjunto de extensăo, como mostra a Figura 1.
Os registros de dados năo săo armazenados em uma ordem específica, e năo existe uma ordenaçăo sequente para as páginas de dados. As páginas de dados năo estăo vinculadas a uma lista, pois implementam diretamente o conceito de pilhas. Quando săo inseridos registros em uma página de dados e ela se encontra quase cheia, as páginas de dados săo divididas em um link é estabelecido para marcaçőes e ligaçőes entre elas.
Dentro da Arquitetura de índices do SQL Server, (assunto que detalharemos mais ŕ frente) existem dois métodos para acesso a dados:
Mas a pergunta que surge rapidamente é, “Por que devo criar índices?”.
Os índices aceleram a recuperaçăo dos dados. Por exemplo, imagine que vocę compre um livro de 800 páginas para suas pesquisas acadęmicas e este năo apresente em seu conteúdo um índice reportando o seu conteúdo. Uma pesquisa talvez năo fosse tăo pavorosa, mas se vocę precisar de várias pesquisas, seria muito desagradável ficar horas procurando o conteúdo que deseja estudar. Por outro lado, um livro que apresente um índice de suas abordagens, se faz muito mais fácil e torna as pesquisas até prazerosas, pois teremos condiçăo de irmos direto ao ponto que queremos.
Índices săo sempre bem vindos em colunas de grande seletividade, como por exemplo, além da chave primária, que muitas vezes pode circular como identificador único da entidade na sua aplicaçăo, vocę pode ter também um índice para colunas que poderăo lhe auxiliar em consultas em que estas contarăo com a cláusula WHERE, precisando ou năo usar os operadores AND, OR ou *NOT, que muitas vezes, em casos específicos, alteram a performance da consulta.
Um bom exemplo da criaçăo necessária de índices, săo aplicaçőes bancárias que atendem ŕ caixas eletrônicos. Sempre que solicitamos uma determinada transaçăo ou mesmo informaçăo, tal solicitaçăo tende a ser cada vez mais rapidamente atendida. E quantos correntistas geralmente tęm os grandes bancos? Será que quanto mais correntistas, mais lenta será a consulta?
Se năo os índices, uma pesquisa pelo seu saldo demoraria quase o tempo de um almoço para retornar seu saldo ou mesmo, retornar uma resposta a sua solicitaçăo de saque. Uma vez tendo cięncia do funcionamento dos índices, respeitando a sua regra de negócios, uma consulta deverá ter resposta em tempo satisfatório.
Os índices săo muito bons no sentido de performance do banco de dados, otimizam as buscas de dados, mas, por outro lado, consomem muito espaço em disco, o que pode se tornar concorrente do próprio banco se vocę o detém em um espaço generoso ou pode se tornar caro quando de detém o banco em um storage.
Considere as seguintes observaçőes antes de criar índices:
A arquitetura de índice contemplada dentro do SQL Server 2000 compreende-se em torno de tipos de índices e pilha de dados.
Existem tręs tipos de índices:
Para manipular as pilhas, o SQL Server apresenta um mecanismo chamado “IAM” (Index Allocation Map), que contęm informaçőes sobre onde ŕs extensőes de uma pilha săo armazenadas. Săo usadas para navegar pela pilha e encontrar espaços disponíveis para os novos registros inseridos e, além disso, săo responsáveis por conectar as páginas de dados.
No caso que vocę tenha um atributo inteiro, definido como chave primária e sendo assim, declarado com IDENTITY, a pilha de dados poderá năo conter a mesma ordem física, caso seja uma tabela com grande volume de inserçőes e exclusőes. A Figura 2 mostra uma pilha contendo a chave primária ‘código’ e um índice qualquer ‘nome’. Olhando bem a figura vocę compreenderá que o mecanismo de arrumaçăo da pilha, rapidamente, após uma exclusăo seguida por um novo cadastro, faz a realocaçăo do novo registro e este é inserido onde anteriormente existia um valor. Resumindo, o mecanismo restaura o espaço para novos registros na pilha após exclusőes.
Os índices agrupados săo criados automaticamente na maioria das tabelas que criamos, pois, quando năo declaramos NONCLUSTERED em uma chave-primária, este campo automaticamente assume o valor de CLUSTERED. Mas, alguns fatos devem ser levados em conta na criaçăo de índices agrupados, tais como:
Os índices sem agrupamento săo úteis quando os usuários precisam de várias maneiras para pesquisar dados. Por exemplo, um leitor pode pesquisar frequentemente em um livro sobre jardinagem os nomes comuns e científicos das plantas. Vocę poderá criar um índice sem agrupamento para recuperar os nomes científicos e um índice de agrupamento para recuperar os nomes comuns.
Vocę tem toda flexibilidade para combinar declaraçőes SQL para manipular tais índices, como criar um índice sem agrupamento, que mantenha unicidade usando UNIQUE em meio ŕ declaraçăo de criaçăo de índice, que veremos mais ŕ frente.
Alguns fatos que devem ser entendidos:
No SQL Server podemos exibir, estando já no Query Analyser e conectando a uma base de dados, os mapas de alocaçăo de índices de forma bem fácil.
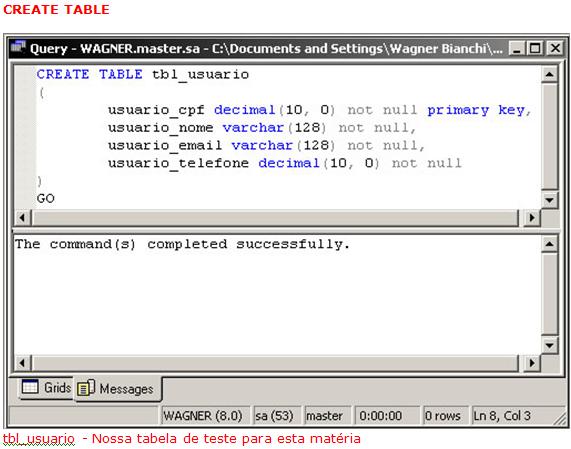
Vamos entăo, criar uma tabela para buscarmos em cima dela, algumas definiçőes de índices básicas e de grande relevância para a conceituaçăo, como mostra a Figura 3.
O seguinte comando exibe as informaçőes dos mapas, também conhecidos como “IAM”, já mencionado aqui neste artigo, como mostra a Figura 4.
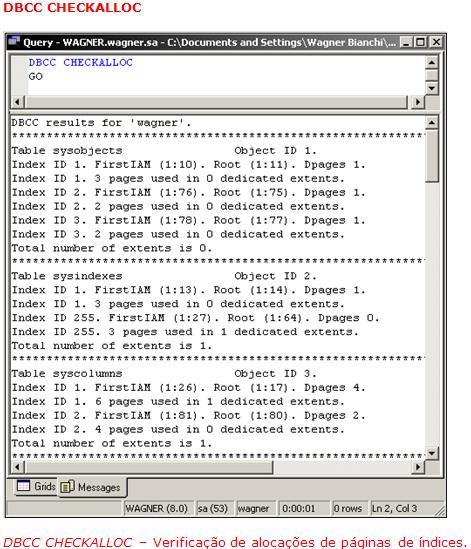
Executando o comando DBCC CHECKALLOC, visualizamos as páginas de alocaçăo de índices, quantidade de extensőes daquele determinado índice e a qual objeto do nosso banco de dados ele pertence.
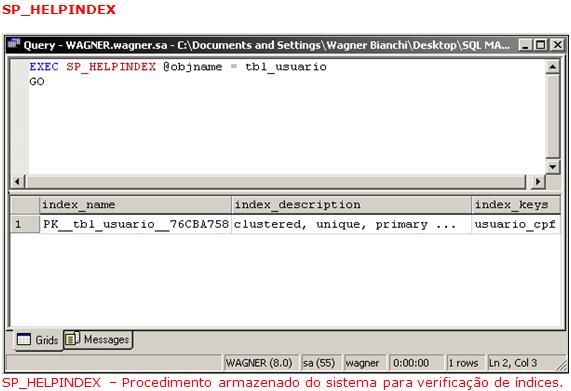
Temos também outro recurso próprio, uma system stored procedure, que nos ajuda a verificar índices próprios de uma tabela específica, dentro de um schema. O seguinte procedimento nos mostrará índices contidos em nossa tabela, como mostra a Figura 5.
Veja que a coluna index_name exibe o nome do índice que pertence ŕ tabela que passamos na declaraçăo @objname. Como só podemos criar um índice clusterizado/agrupado por entidade, podemos criar outros índices năo agrupados caso seja pertinente com a regra de negócios a ser aplicada. Na última imagem, podemos perceber também, a qual atributo da entidade está aplicado o índice e também suas descriçőes.
Lembrando que o nome do índice apresentado no como valor do atributo index_name poderá variar de servidor para servidor.
Todos os índices criados em uma base de dados dentro do SQL Server, tem suas informaçőes armazenadas em uma tabela chamada SYSINDEXES, que contém informaçőes estatísticas, como o número de registros e páginas de dados em cada tabela, além de descrever como localizar as informaçőes que săo apontadas pelos índices.
Levando em conta que cada tabela possui uma coleçăo de páginas de dados, cada tabela e índice săo identificados de forma exclusiva pela combinaçăo entre coluna identificadora (PK, por exemplo) e a coluna identificadora de índices (INDID).
A tabela do sistema sysindexes é o local central para informaçőes vitais sobre objetos como entidades e índices destas entidades. Contém informaçőes estatísticas, como o número de registros e páginas de dados em cada tabela. Além disso, descreve como localizar as informaçőes armazenadas em uma tabela de dados.
Os ponteiros de páginas da tabela sysindexes ancoram todas as coleçőes de páginas de tabelas e índices. Cada tabela possui uma coleçăo de páginas de dados, além de coleçőes de páginas adicionais para implementar cada índice definido para a tabela.
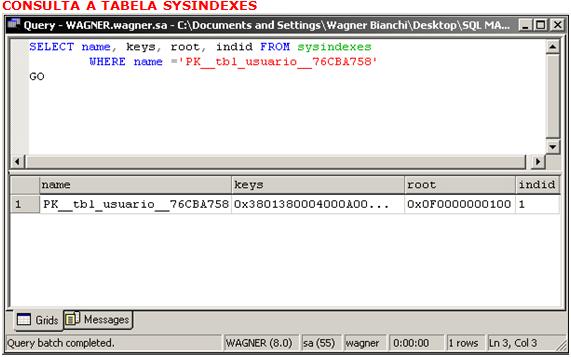
Um registro na tabela sysindexes de cada tabela e um índice é identificado de forma exclusiva pela combinaçăo entre a coluna identificadora de objetos (id) e a coluna identificadora de índices (indid), como mostra a Figura 6.
É fato que bancos de dados trabalham bem mais rápido com campos que armazenam números, já que os processadores, tanto de tecnologia Cisc (Complex Instruction Set Computer) quanto Risc (Reduced Instruction Set Computer), săo ótimos em comparar maiores, menores, múltiplos, divisores, iguais, diferentes, enfim, trabalham bem com números. Essa pequena abordagem se deve ao fato de tudo dentro de um sistema de computaçăo será analisado com conversőes binária ou hexadecimal. Com bancos de dados e mais precisamente com a tabela sysindexes também năo se faz contrário.
Descrevendo o que vemos na última imagem:
Quando năo existe nenhum índice em uma determinada tabela, o Otimizador de consultas é acionado e entăo utiliza a varredura de tabela para recuperar registro, uma das formas que este usa, a qual já vimos anteriormente.
Năo é uma boa prática visto que, em uma tabela com muitos registros ou mesmo uma tabela que possa ser considerada com grande, năo haverá apontamentos para indicar onde estăo os dados que estamos buscando. A performance em buscas desse tipo pode năo ser tăo satisfatória quando se deseja recuperar poucos dados.
Os registros săo retornados fora da ordem. Talvez eles sejam inicialmente retornados na mesma ordem da inserçăo, mas essa ordem năo será mantida, já que após algumas exclusőes as novas inserçőes ocuparăo esses espaços, tornando a ordem imprevisível.
Nesse caso, as disposiçőes índices e dados estarăo em planos diferentes, sendo que, os índices dispostos como um índice de um livro e os dados como o conteúdo do livro. Aí que entram as ideias de apontamentos. Os ponteiros indicam o local de armazenamento dos itens indexados na tabela subjacente.
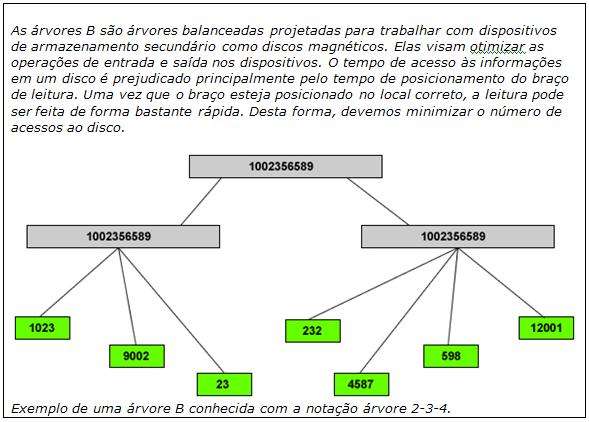
Os índices dentro da Arquitetura do SQL Server săo organizados, implementado o conceito de *árvore B, sendo que cada página de índice contém um cabeçalho de página seguido por registros de índice. Cada registro de índice contém um valor de chave e um ponteiro para outra página ou registro de dados, formando os cabeçalhos já vistos outrora aqui, conforme a Figura 7.
O SQL Server utiliza os níveis da árvore B com notaçőes nó de índice, nível raiz e nível folha ou nó folha. Quaisquer níveis entre os nós raiz e folha săo chamados de níveis intermediários. Cada página nas camadas intermediárias ou inferiores tem ponteiros ou apontamentos anteriores ou posteriores em uma lista dupla relacionada.
Em uma entidade que só contenha um índice sem agrupamento, os nós folha possuem localizadores de registros com apontamentos para registros de dados que contém os valore de chave. Cada ponteiro (RID ou ROWID – identificador de registro ou de linha) é criado com base na identificaçăo do arquivo, no número da página e no número do registro da página.
Os índices de agrupamento e sem agrupamento compartilham da mesma estrutura dentro da “árvore B”, mas com algumas diferenças:
Um índice de agrupamento (clusterizado ou ordenado) é como um índice remissivo de um livro, como já citamos, os assuntos estăo agrupados todos por uma ordem ascendente, facilitando a pesquisa de dados e localizaçăo deles dentro da árvore. Lembrando que năo importa se esta é muito ramificada devido ao seu tamanho.
Como um índice de agrupamento determina a sequęncia em que os dados săo armazenados em uma tabela, só pode haver um índice deste tipo por entidade.
Quando um índice sem agrupamento é adicionado a uma tabela que já tem um índice de agrupamento, o localizador de registro de cada índice sem agrupamento contém o valor de índice da chave de agrupamento do registro.
Quando forem usados índices de agrupamento e sem agrupamento em uma mesma tabela, as estruturas da árvore B e dos índices devem ser percorridas para que os dados sejam localizados. Isso gera custo alto com I/O.
Como o valor de um índice de agrupamento é maior do que o RID de 8 bytes usado para a pilha, os índices sem agrupamento podem ser substancialmente maiores em tabelas de agrupamento indexadas do que quando criados em pilhas. Se vocę mantiver baixos os valores de chave do índice de agrupamento, isso lhe ajudará a criar índices menores e mais rápidos.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.