Por que eu devo ler este artigo: Esse artigo é útil para quem deseja adentrar no mundo da computação serverless. Conheça uma das mais novas e promissoras áreas da computação que visa prover a execução de rotinas de software rápidas e baratas na nuvem, alocando o mínimo de recursos possíveis se, e somente se, requisições forem solicitadas ao servidor. Dessa forma, o leitor poderá entender como conectar o já conhecido mundo do .NET, C# e programação para Azure com as novas Azure Functions: os “pedaços” de código que executam independentemente no servidor.
Muito tem-se falado sobre o mundo serverless, à luz dos limites rompidos por tecnologias como AWS Lambda e Google Cloud Functions, temos agora a possibilidade de ser mais modular, ocupar menos recursos físicos (hardware, processamento, memória, etc.) e, consequentemente, gastar muito menos quando se trata de criar softwares.
Guia do artigo:
Computação serverless, em termos rápidos, é um modelo de execução de código onde a lógica do lado servidor se dá de forma stateless, isto é, sem estado, a partir de gatilhos (triggers), e via containers que são totalmente gerenciados por um terceiro. Muitas vezes sua definição é associada à Functions as a Service (FaaS), um termo mais popular para quando queremos focar mais na implementação em vez dos detalhes de como a aplicação irá ser deployada e/ou executada no servidor.
Em diferentes linguagens de programação, podemos encontrar os termos "função", "procedimento" e "método" referindo-se a diferentes tipos de rotinas executando uma tarefa. Neste contexto, o termo função não é específico da linguagem de programação, mas conceitual: na programação, uma função é uma seção nomeada de um programa que executa uma tarefa específica.
Ironicamente, a computação serverless não é, de fato, executada sem servidores. Em vez disso, ela envolve a terceirização do provisionamento e gerenciamento de servidores para um terceiro.
Quase todas as tecnologias de computação sem servidor existentes são disponibilizadas por grandes fornecedores de nuvem pública. A grande escala dos fornecedores de nuvens públicas atuais permite duas coisas para tornar o servidor ainda mais interessante:
Para ilustrar onde a computação serverless entraria em sua aplicação, vamos dar uma olhada em uma arquitetura clássica de três camadas. Nesta abordagem comumente utilizada, o aplicativo é dividido nas seguintes camadas:
A partir do momento que introduzimos o conceito de computação serverless, todas ou partes da sua aplicação na concepção que a conhece hoje, podem ser substituídas pelos containers serverless, ou FaaS. Dependendo da aplicação, funções podem lidar com toda a lógica de negócio, ou trabalhar em conjunto com outros tipos de serviços para constituir o todo desta camada. Por exemplo, considere uma aplicação que recebe dados de cartão de crédito de um usuário. Convencionalmente, teríamos várias camadas de serviços deployadas no servidor, que proveriam uma série de validações no momento em que uma transação chegasse à nossa aplicação. Cada validação, no universo das serverless, constitui uma função que, por sua vez, se comunica com outras funções ou serviços externos (das Mastercard, por exemplo), e assim por diante.
Apesar disso, nem todas as facetas da computação tradicional podem ser substituídas. Por exemplo, algumas das características implícitas da computação serverless impossibilitam operações tradicionais, como o fato de que ela é, por default, assíncrona, isto é, baseada em eventos que são trigados (triggers) a partir do acontecimento de determinadas ações assíncronas na aplicação. Em vista disso, é importante que a sua programação leve em consideração o uso de funções não-blocking, que sejam passíveis de espera.
Vejamos mais alguns estados importantes do serverless nos tópicos a seguir.
Programação serverless é, por padrão, stateless, isto é, não pode guardar estado. O conceito já é bem conhecido em aplicações enterprise que fazem uso extensivo de objetos beans para execução de tarefas de negócio simples, independentes e, como o próprio nome sugere, sem estado. Ele vai além, se estendendo a restrições também para execuções paralelas e sequenciais, exigindo um certo jogo de cintura do programador para entender que seu estado, agora, deve ser salvo em um banco de dados, um servidor de arquivos, cache ou quaisquer estruturas que permitam isso de forma integrada, não mais interna à execução da aplicação.
O paradigma stateless facilitou em muito a construção e escalabilidade de aplicações nos últimos anos especialmente por seu deploy rápido e fácil acesso aos recursos. Todavia, nem tudo é perfeito: o maior benefício de ter um estado local é a baixa latência de acesso, e algumas aplicações não conseguem atingir boas performances sem isso. Como um exemplo, consideremos a construção de uma aplicação usada para trade de mercado financeiro, persistindo o estado em um banco de dados ou até mesmo num cache, o que pode se tornar extremamente custoso. Aplicações que requerem um estado local não se encaixarão bem no modelo serverless.
Note-se ainda que alguns provedores de computação serverless te previnem completamente de eventuais acessos à máquina hospedeira. Com o Azure Functions, você tem acesso de leitura/escrita ao disco virtual D: da máquina host, entretanto, é altamente recomendável que você não o use para persistir estado.
Para garantir a consistência, as funções de computação serverless devem ser idempotentes. Matematicamente, uma função é idempotente se, sempre que for aplicada duas vezes em qualquer valor, der o mesmo resultado que se fosse aplicada uma vez, ou seja, ƒ(ƒ(x)) ≡ ƒ(x) .
Para dar um exemplo simples de uma função não idempotente, imagine uma função com uma tarefa de cálculo de uma raiz quadrada dado um número de entrada. Se a função for executada uma segunda vez em um valor de entrada que já foi processado, resultará em uma saída incorreta, como temos em √(√(x)) ≠ √(x) . Assim, a única maneira de garantir que a função permaneça idempotente é garantir que a mesma entrada não seja processada duas vezes.
Em um ambiente assíncrono, altamente paralelizado, executado por containers de computação efêmeros, é preciso uma dose extra de trabalho para garantir que os erros de execução não impactem em todos os eventos subsequentes. O que acontece quando uma função falha no meio da codificação de um arquivo de mídia grande? O que acontece se uma função encarregada de processar 100 linhas em um banco de dados falhar antes de terminar? Será que o restante da entrada permanecerá não processado, ou sua parte já processada será processada de novo?
Para garantir a consistência, precisamos armazenar as informações de estado necessárias com nossos dados, permitindo que uma função termine graciosamente se não for necessário mais processamento. Além disso, precisamos implementar um padrão de circuit-breaker para garantir que uma função com falha não tente novamente infinitamente.
O Azure Functions, em particular, possui mecanismos de defesa internos que você pode aproveitar. Por exemplo, para uma função de fila de armazenamento, um processamento de mensagens da fila será reiniciado cinco vezes em caso de falha, após o qual será descartado para uma fila de mensagens DLQ, por exemplo.
Em comparação com uma aplicação tradicional, um ambiente FaaS tem duas restrições de execução muito importantes: o tempo que a função pode executar e o tempo necessário para iniciar a primeira execução da função após um período de inatividade.
Em um ambiente FaaS, o tempo de execução de cada função deve ser o mais curto possível. Alguns fornecedores impõem limites rígidos de até alguns minutos que devem ser rigidamente obedecidos. Esses limites determinam um certo estilo de programação, mas podem ser complicados de lidar.
Os Azure Functions são oferecidos em dois planos de hospedagem diferentes: um plano de consumo (Consumption plan) e um plano de serviço de aplicativos (App Service plan). O plano de consumo escala dinamicamente sob demanda, enquanto um plano de serviço de aplicativos sempre possui pelo menos uma instância da VM provisionada. Devido às diferentes abordagens para provisionamento de recursos, esses planos têm diferentes restrições de execução.
No plano de App Service, não há limite no tempo de execução da função. Já no plano Consumption há um limite padrão de cinco minutos, que pode ser aumentado até 10 minutos efetuando uma alteração na configuração da função.
Mesmo no plano do serviço de aplicativos, no entanto, é altamente recomendável manter o tempo de execução da função o mais curto possível. Uma função de longa execução pode ser dividida em funções mais curtas, onde cada uma executa uma tarefa específica.
Em um ambiente FaaS, as funções devem ser mantidas o mais leve possível. Carregar muitas dependências externas explícitas ou implícitas pode aumentar o tempo de carregamento da função e até causar tempos de espera. Assim, as funções devem manter suas dependências externas ao mínimo.
Além disso, na maioria dos ambientes FaaS, as funções enfrentam uma latência de inicialização significativamente aumentada. Após um período de inatividade, uma função não utilizada fica ociosa. A próxima vez que a função for carregada, o cálculo e a memória precisarão ser alocados, as dependências externas precisarão ser carregadas e, no caso de linguagens compiladas como C#, o código precisa ser recompilado. Todos esses fatores podem causar um atraso significativo no tempo de inicialização da função.
Nas funções baseadas no Azure C#, especificamente, o problema de inicialização foi atenuado com o lançamento das funções baseadas na .NET Class Library, uma vez que as funções são pré-compiladas e podem ser carregadas mais rapidamente. Além disso, quando executado no plano App Service, o problema de inicialização é eliminado.
As vantagens do FaaS podem ser agrupadas em algumas categorias. Algumas das vantagens existem na maioria dos ambientes PaaS (Platform as a Service), no entanto, elas podem ser melhor notadas em um ambiente FaaS.
Algumas das vantagens são semelhantes às vantagens da popular arquitetura de microsserviços, na qual a aplicação está estruturada como uma coleção de serviços de baixo acoplamento, cada uma das quais lidando com uma tarefa específica.
A computação serverless torna muito fácil escalar aplicações, fornecendo mais poder de computação, conforme necessário, e desalocando-o quando a demanda for baixa. Isso permite que os desenvolvedores evitem o risco de ter a aplicação falhando para seus usuários durante uma demanda de pico, e evitando ao mesmo tempo o custo de alocar infraestrutura de reserva maciça.
Isso torna a computação serverless particularmente útil para aplicativos com tráfego inconsistente. Vejamos os seguintes exemplos:
É importante notar que a vantagem de escalabilidade também existe nos serviços PaaS, no entanto, com a computação serverless, a escala geralmente é completamente dinâmica e tratada pelo fornecedor. Isso significa que, enquanto estiver em um serviço PaaS típico, você precisará definir métricas (como alta utilização de CPU ou memória) e, até certo ponto, definir o procedimento de dimensionamento (como uma série de nós adicionais para provisionar ou se a aplicação precisa diminuir a escala após a demanda diminuir) com a computação serverless, o fornecedor simplesmente alocará o cálculo adicional para sua função com base no número de requisições que chegam.
Na computação serverless, você só paga pelo que você usa. O modelo Pay-As-You-Go provavelmente resultará em economia de custos na maioria dos casos (lembre-se da infraestrutura subutilizada) e se torna particularmente benéfico nos cenários de tráfego inconsistentes descritos anteriormente. O modelo também significa que qualquer otimização de velocidade do seu serviço se traduz diretamente em economia de custos.
O Pay-As-You-Go também é uma vantagem nos serviços PaaS, no entanto, a maioria destes serviços não vão fundo no quesito granularidade de alocação de energia de computação.
Além disso, em um ambiente de serverless, você não precisa fornecer, gerenciar, corrigir ou proteger os servidores. Você está terceirizando o gerenciamento do hardware físico e dos servidores virtuais, sistemas operacionais, redes e segurança para o fornecedor de computação serverless . Isso fornece economia de custos das duas maneiras a seguir:
Essa vantagem também existe em qualquer serviço PaaS, e para um serviço FaaS, na verdade, não pode ser tão direto quanto parece. Embora existam benefícios de custos muito claros para não gerenciar servidores, é importante lembrar que as operações normalmente cobrem muito mais do que o gerenciamento de servidores, incluindo tarefas como implantação, monitoramento e segurança de aplicações.
Algumas dessas desvantagens resultam de uma complexidade adicional da arquitetura de aplicações. Outras resultam da falta de maturidade dos tools nos atuais ambientes serverless e dos problemas que acompanham as partes de terceirização do seu sistema.
Semelhante à arquitetura de microsserviços, o serverless apresenta uma maior complexidade de sistema e um requisito de comunicação de rede entre as camadas da aplicação. A complexidade adicionada se centra em torno dos dois aspectos principais, a saber:
Uma vez que as ofertas de computação serverless são novas, suas ferramentas de segurança e monitoramento também o são, e muitas vezes bem específicas para o ambiente serverless e para um determinado fornecedor. Isso introduz mais complexidade no processo de gerenciamento de operações para a aplicação em geral, adicionando um novo tipo de serviço a gerenciar.
Os testes podem tornar-se mais difíceis em um ambiente serverless devido aos seguintes aspectos:
Ao contrário do famoso vendor lock-in, o controle de fornecedores implica que, ao terceirizar uma grande parte do gerenciamento de suas operações, você também renuncia ao controle sobre como essas operações são tratadas. Isso inclui as limitações do serviço, o mecanismo de escalabilidade e a otimização potencial de hospedagem da sua aplicação.
Além disso, o fornecedor tem o controle final sobre o ambiente e as ferramentas, decidindo quando implementar recursos e corrigir problemas (embora no caso do Azure Functions você possa ajudar a resolver problemas contribuindo para o projeto de código aberto).
Apenas alguns anos atrás, o modelo multitenancy costumava estar no topo da lista de preocupações das organizações que consideravam usufruir da nuvem pública. No entanto, o multitenancy também é o que permite que as nuvens públicas se tornem mais rentáveis e mais inovadoras que os centros de dados privados. Em particular, os benefícios de custo da computação serverless dinamicamente alocada resultam da economia de escala, o que é possível utilizando a mesma infraestrutura para atender a diferentes aplicações de clientes em momentos diferentes.
Atualmente, a maioria das organizações aceitou que os fornecedores públicos de nuvem se comprometeram a assegurar que, como cliente, você obtenha o mesmo isolamento de segurança e alocação de recursos dedicados em uma nuvem pública como faria em um ambiente single-tenant (quando cada instância de uma aplicação é customizada para atender um cliente em específico).
A Azure é a plataforma pública de computação em nuvem da Microsoft. Neste artigo, nos concentraremos no serviço nativo chamado Azure Functions, que é a principal oferta da Microsoft para a computação serverless.
O Azure Functions é um FaaS. Conforme discutido anteriormente, em uma oferta típica de PaaS, você é responsável por gerenciar suas camadas de aplicativos e dados, enquanto o fornecedor administra o hardware, middleware, SO, servidores e redes. Em um ambiente FaaS, o fornecedor também gerencia o contexto do aplicativo e você pode se concentrar apenas na implementação de uma função específica, isto é, escrever o código que atinja um objetivo específico.
Uma conta na Azure (billing) é uma conta usada para fins de cobrança e gerenciamento de assinaturas. Uma vez criada a conta terá também acesso ao portal Azure Billing, onde você pode criar e gerenciar suas assinaturas. Existem dois tipos de contas Azure, pessoais e organizacionais:
Vejamos algumas maneiras diferentes para acessar uma conta Azure e subscrever para fins de desenvolvimento:
Para os propósitos deste artigo, faremos uso apenas dos recursos gratuitos do Microsof Azure, a menos que você não submeta milhares de requisições de teste. Logo, se estivermos dentro dos limites default da nossa subscrição, nenhum encargo será aplicado.
Primeiro, precisamos criar uma subscrição Azure através de alguns passos básicos. Acesse a home do portal Azure (vide seção Links) e crie uma conta (você pode usar uma conta Hotmail ou Outlook para logar, caso já tenha uma). O passo a passo é bem intuitivo, e dados do seu cartão de crédito serão requeridos ao longo do processo, porém é apenas para conferência de informações, nenhuma cobrança será efetuada a menos que você selecione um plano específico.
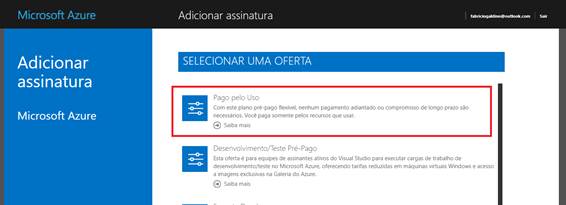
Quando finalizar, clique no botão “Introdução à assinatura Azure” e será redirecionado para o portal do Azure. Uma vez lá, na caixa de pesquisa superior do canto direito, digite “assinaturas”, selecione a opção que aparecer e, quando for redirecionado para a página de Assinaturas, clique em “Adicionar”. Selecione, então, a oferta “Pago pelo Uso”, tal como demonstrado na Figura 1. Caso seja solicitado atualizar o plano para manter os serviços existentes, selecione a primeira opção fornecida.
Você deve ter reparado que existe uma série de opções na barra lateral do portal Azure, dentre as quais temos os “Aplicativos de Funções”. Um aplicativo de função pode ser composto por uma ou mais funções individuais hospedadas em conjunto. Essas funções não precisam ser do mesmo tipo ou mesmo escritas na mesma linguagem.
Ao implantar funções a partir do controlador de códigos ou de um pipeline de delivery contínuo, o aplicativo de função representa a menor unidade de deploy (ou seja, as funções separadas no aplicativo de função não podem ser deployadas de forma independente).
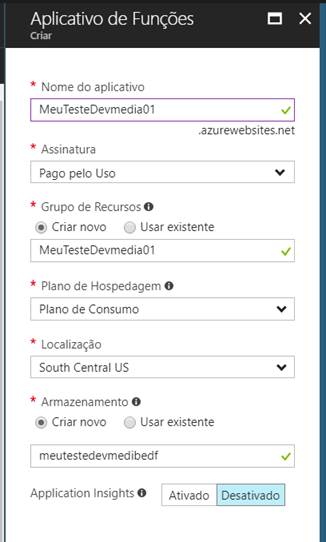
Uma função Azure, por sua vez, consiste em código de função e configuração. O código da função é o que será executado quando a função for acionada. A configuração da função define, entre outras coisas, as conexões de entrada e saída da função. As ligações de entrada determinam quando e como o código da função será acionado. Vamos criar, portanto, nossa primeira função Azure no portal de gerenciamento. Para isso, vá em “ Novo > Computação > Aplicativo de Funções ” e preencha as opções apresentadas tal como vemos na Figura 2. Perceba que basta preencher o nome do aplicativo com algo bem específico, que os demais campos serão automaticamente completados.
O parâmetro “Nome do aplicativo” é o prefixo DNS ao qual sua aplicação será atribuída. Uma vez implantado, seu aplicativo será roteável publicamente através de [SeuNomeDeApp].azurewebsites.net . O nome (prefixo DNS) precisa ser exclusivo no domínio azurewebsites.net.
Na computação serverless Azure, as funções ativadas por HTTP são automaticamente atribuídas a um endpoint público e não requerem um API Gateway. A URL https://[ SeuNomeDeApp].azurewebsites.net será a URL base para os endpoints das suas funções. Observe que você terá que escolher um nome diferente ou anexar um sufixo se o nome que você deseja usar já existe.
Uma vez que tudo estiver devidamente preenchido, basta clicar em “Criar” e em alguns minutos seu serviço estará deployado e disponível para uso. Na dashboard do seu painel você poderá acompanhar o status de deploy, assim como quando o mesmo estiver finalizado.
Para deployar uma função Azure num Aplicativo de Função, uma vez que o mesmo finalize sua implantação, o Portal de Gerenciamento irá redirecioná-lo para a página "Portal de Funções". Vamos explorar alguns dos passos para implantar uma função Azure online:
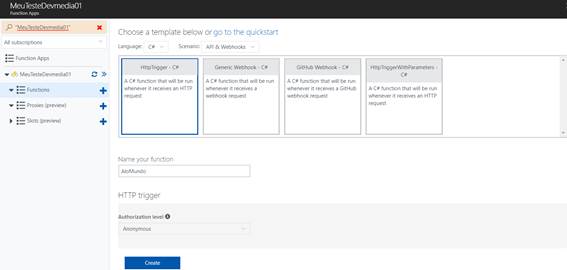
Vide a Figura 3 com base para validar as opções preenchidas até aqui. Após isso, basta clicar no botão Create e você será redirecionado para o portal de desenvolvimento das funções Azure UI, onde poderá, inclusive, editar o código C# da sua função, dentre outras opções de configuração.
No lado direito do portal, você verá a biblioteca de arquivos que contém o código e a configuração usados em sua função. Os arquivos necessários serão gerados automaticamente a partir do modelo quando você escolher o tipo de função. Você também pode adicionar ou fazer upload de novos arquivos e excluir os arquivos da parte inferior do painel View files.
Esses arquivos são hospedados em seu ambiente de serviço de aplicativo em D:\home\site\wwwroot\[NomeDaSuaFuncao] . Há também um arquivo host.json que está localizado no diretório wwwroot e contém a configuração de tempo de execução compartilhada por todas as funções individuais no seu Aplicativo de Funções.
O modelo de função disparado por HTTP que criamos vem com os seguintes dois arquivos gerados automaticamente: o arquivo run.csx que contém o código da função em si, e o arquivo function.json que contém as configurações da função. Vide na Listagem 1 o código autogerado da nossa função.
using System.Net; public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log) { log.Info("C# HTTP trigger function processed a request."); // parse query parameter string name = req.GetQueryNameValuePairs() .FirstOrDefault(q => string.Compare(q.Key, "name", true) == 0) .Value; // Get request body dynamic data = await req.Content.ReadAsAsync<object>(); // Set name to query string or body data name = name ?? data?.name; return name == null ? req.CreateResponse(HttpStatusCode.BadRequest, "Please pass a name on the query string or in the request body") : req.CreateResponse(HttpStatusCode.OK, "Hello " + name); }
Esta função é criada para responder a um trigger de endpoint HTTP. Ela espera um parâmetro chamado name na query da URL ou no corpo da query. Se recuperar um valor de string, como o “ Mundo ” para o parâmetro de name, a função retornará uma resposta HTTP com status OK (200) e uma mensagem " Hello world ". Caso contrário, retornará um status HTTP de Bad Request (400) e uma mensagem solicitando a passagem de um nome na query string ou na mensagem do corpo da requisição.
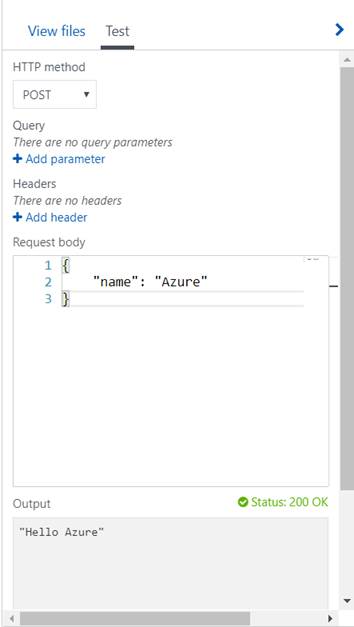
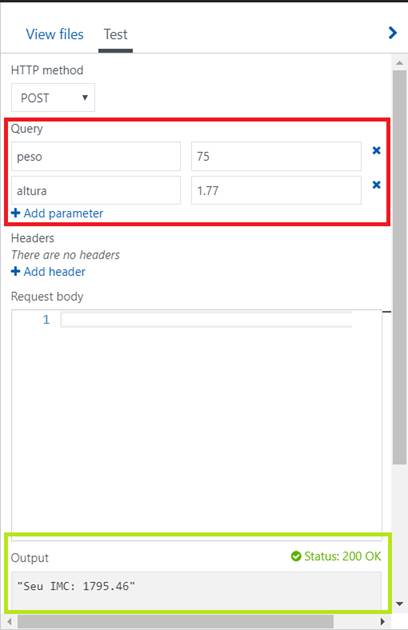
Caso o leitor queria testar o funcionamento de sua função, basta clicar na seção Test, ao lado da View files . Ela provê uma interface rápida para teste dos endpoints de funções que estamos desenvolvendo, bem como debugging dos resultados HTTP, etc. Vide Figura 4 para exemplo de teste com nossa função de Alô Mundo. A mesma será aberta assim que você clicar no botão “ Run ” acima do código da função.
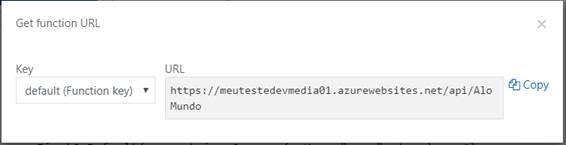
Além disso, ao lado do botão Run, temos um link chamado “</> Get function URL ” que, quando clicado, exibirá uma pop-up com uma representação da URL para que possa testar da maneira que desejar (Figura 5).
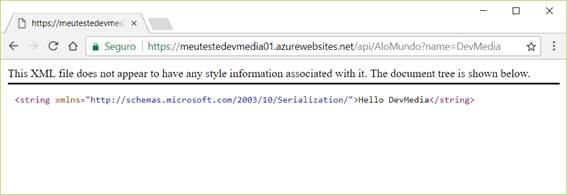
Para testar em um exemplo real, abra uma aba do seu navegador e digite a seguinte URL:
https://meutestedevmedia01.azurewebsites.net/api/AloMundo?name=DevMedia
Você verá o resultado da requisição, tal como temos na Figura 6.
A partir daí, alterar qualquer parte do código, ou criar novas funções se torna extremamente simples, até mesmo a adição de novos arquivos csx para contemplar novas funções pode ser feito usando somente a interface web, o que te disponibiliza um ambiente totalmente online, sem a necessidade de IDEs e toda a complexidade de downloads/gerenciamento que temos convencionalmente.
Por exemplo, vamos criar uma segunda função Azure para, agora, passar a receber dois parâmetros (peso e altura) que, por sua vez, serão usados para calcular o índice de massa corpórea (IMC) de uma pessoa. Vide o código da Listagem 2 que deverá substituir o default do arquivo run.csx. Crie a função usando as mesmas definições que usamos para a primeira, dando o nome de “ CalcularIMC ” à mesma.
using System.Net; using static System.Math; using static System.Convert; public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log) { log.Info("C# HTTP trigger function processed a request."); // parse query parameters string peso = req.GetQueryNameValuePairs() .FirstOrDefault(q => string.Compare(q.Key, "peso", true) == 0) .Value; string altura = req.GetQueryNameValuePairs() .FirstOrDefault(q => string.Compare(q.Key, "altura", true) == 0) .Value; // Get request body dynamic data = await req.Content.ReadAsAsync<object>(); // Set peso/altura to query string or body data peso = peso ?? data?.peso; altura = altura ?? data?.altura; if (peso == null) { log.Error($"Parameter peso missing in HTTP request. RequestUri={req.RequestUri}"); return req.CreateResponse(HttpStatusCode.BadRequest, "Favor informar o parâmetro 'peso' na query string!"); } if (altura == null) { log.Error($"Parameter altura missing in HTTP request. RequestUri={req.RequestUri}"); return req.CreateResponse(HttpStatusCode.BadRequest, "Favor informar o parâmetro 'altura' na query string!"); } return req.CreateResponse("Seu IMC: " + CalcularIMC(Convert.ToDouble(peso), Convert.ToDouble(altura))); } public static double CalcularIMC(double peso, double altura) { double bmi = Math.Pow(peso / altura, 2); return Math.Round(bmi, 2); }
Veja que mantivemos praticamente toda a estrutura original da função Run(), assíncrona, recebendo o mesmo objeto de request e devolvendo um response ao final. Vejamos as principais alterações:
Veja que a função CreateResponse() deve ser declarada como static, isso porque não estamos manipulando objetos no C#, logo ela deve estar sempre disponível após inicialização da classe em si, não carecendo assim de contexto.
Para testar nossa nova função, basta abrir a seção Test novamente, preencher os parâmetros da requisição e clicar no botão de Run, tal como vemos na Figura 7.
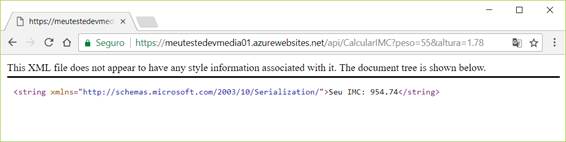
Ou, caso prefira, basta executar a seguinte URL no navegador e teremos o resultado demonstrado pela Figura 8:
https://meutestedevmedia01.azurewebsites.net/api/CalcularIMC?peso=55&altura=1.78
As ferramentas de Funções do Azure estão disponíveis a partir do Visual Studio 2017 Update 3 ou posterior. Para tal, vamos baixar e instalar o Visual Studio executando as seguintes etapas:
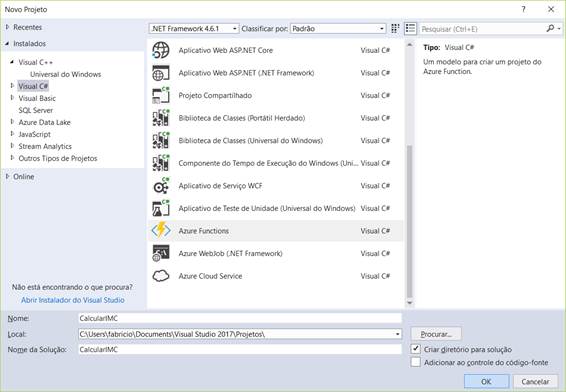
Seu Visual Studio IDE agora está pronto para usar para funções Azure. Após isso, o template Funções Azure aparecerá nos modelos de novos projetos do Visual Studio. Para criar um novo projeto de Funções, navegue até o menu “ Arquivo > Novo > Projeto ” e, em Modelos, selecione “ Visual C# > Cloud > Funções Azure ” conforme mostrado na Figura 9.
Depois de clicar em OK, um novo projeto de Aplicativo de Função será criado. Abra o painel do Solution Explorer clicando em “ View > Solution Explorer ”. Lá, você verá a nova estrutura de projeto da Aplicativo de Função. Você notará que o projeto recém-criado não contém automaticamente uma função. Os arquivos na árvore do projeto (local.settings.json e host.json) são os arquivos que definem as configurações do projeto inteiro e serão aplicadas a todas as funções adicionadas ao projeto.
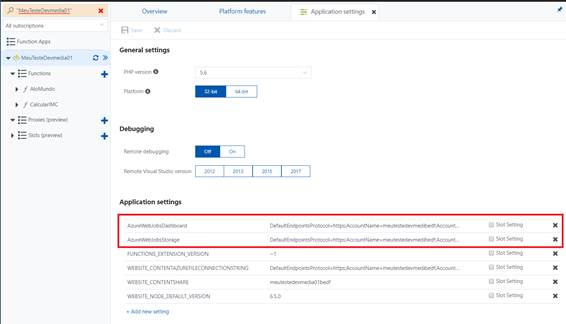
Para executar o seu Aplicativo de Função local contra o ambiente Azure que criamos anteriormente, precisamos propagar as configurações AzureWebJobsStorage e AzureWebJobsDashboard para o nosso ambiente Visual Studio local. Para fazer isso, vamos navegar até a função que criamos “MeuTesteDevmedia01”, ao lado dela você notará duas abas: “ Overview ” e “ Platform Features ”, clique nesta última e, em seguida, em “ Application Settings ”. Você verá as configurações com os nomes correspondentes às do arquivo (Figura 10) e poderá copiá-las e colá-las no local.settings.json do seu projeto (Listagem 3).
{ "IsEncrypted": false, "Values": { "AzureWebJobsStorage": "DefaultEndpointsProtocol= https;AccountName=meutestedevmedibedf; AccountKey=ZjVoxKR77uAOBI8/uctGnF/ fXWvr4PF35QnWADwpXyRLq32ahhPSkcEvSCs1CgvJHipwyheFsgXfpqLcbF3DXw==", "AzureWebJobsDashboard": "DefaultEndpointsProtocol=https; AccountName=meutestedevmedibedf; AccountKey=ZjVoxKR77uAOBI8/uctGnF /fXWvr4PF35QnWADwpXyRLq32ahhPSkcEvSCs1CgvJHipwyheFsgXfpqLcbF3DXw==" } }
Para criar uma nova função, basta clicar com o botão direito sobre o projeto, na Solution Explorer, ir em “ Adicionar > Novo Item... > Itens do Visual C# > Azure Functions ” e dar um nome ao arquivo (que será o mesmo nome da função). Digite “CalcularIMC” e, finalmente, clique em “ Adicionar ”.
Aqui seremos novamente questionados sobre o tipo de função a ser criada. Selecione mais uma vez “ Http trigger ” e “ Anonymous ” na combo de “ access rights ”. Clique em OK . O código será praticamente idêntico ao que criamos no portal online.
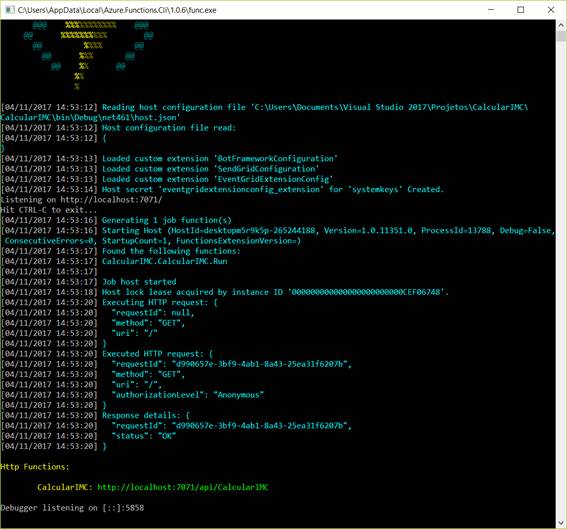
Para executar a função localmente, basta clicar no botão de Start no topo do Visual Studio, se certificando que o a opção “Debug” está selecionada na combo ao lado. O VS possivelmente exibirá um alerta informando que as ferramentas de debug do Azure Functions são necessárias, bastando selecionar OK para que ele prossiga. Uma janela auxiliar será aberta para subir o projeto localmente e, ao final, você verá algo como a Figura 11.
Por default, seus aplicativos subirão na porta 7071 da sua máquina (caso deseje alterar o valor, modifique a propriedade “ LocalHttpPort ” no arquivo local.setting.json do projeto). Para ver o exemplo funcionando, basta digitar a seguinte URL em seu navegador:
http://localhost:7071/api/CalcularIMC?name=DevMedia
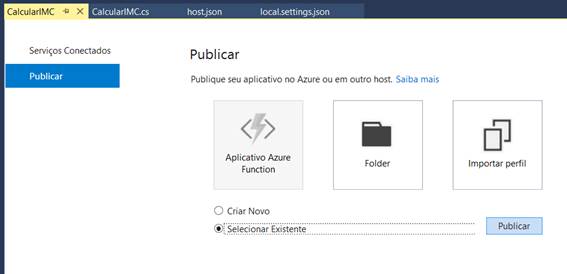
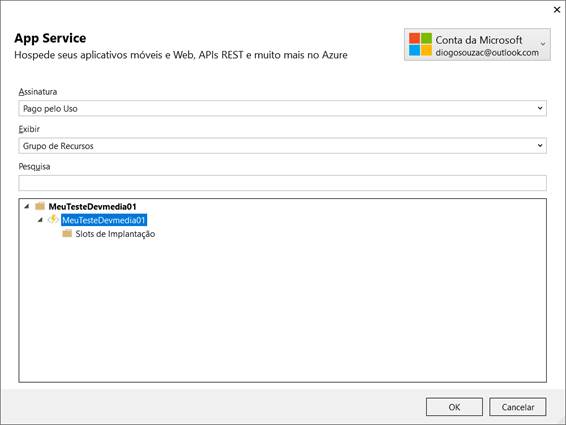
Uma vez que finalizar sua implementação, caso deseje publicar sua função para sua conta na nuvem Azure, basta clicar com o botão direito na solução e selecionar a opção “ Publicar... ”. Uma janela com as opções de publicação aparecerá perguntando se deseja criar um novo host na Azure ou usar um existente. Vamos selecionar a opção “ Selecionar Existente ”, tal como mostra a Figura 12.
Clique em Publicar . O Visual Studio se conectará automaticamente à Microsoft ou à conta organizacional com a qual você iniciou sua sessão e recuperará as assinaturas do Azure que você acessou. Escolha a assinatura apropriada sob a opção “ Assinatura ” e o valor “ Grupo de Recursos ” no menu suspenso “ Exibir ”. Em seguida, escolha a Aplicação de Função Azure que criamos (Figura 13).
Clique em OK . Revise as informações que o Visual Studio trouxer sobre o host publicado e, em seguida, clique em Publicar . Uma vez finalizado, você pode navegar até o portal online do Azure e visualizar a nova função.
As funções são recursos extremamente poderosos para disponibilizar tarefas rápidas, das quais recursos podem ser desalocados rapidamente no seu ambiente de nuvem. Muito mais pode ser adicionado aos nossos exemplos, como teste tente criar uma nova função no seu ambiente local (com Visual Studio) e efetuar o mesmo cálculo de IMC que fizemos, ou se desafie a novas implementações como calcular a idade de uma pessoa com base no ano e mês de nascimento dela. O segredo é explorar e, quando finalizar cada implementação, publique na nuvem e teste-as.


Utilizamos cookies para fornecer uma melhor experiência para nossos usuários, consulte nossa política de privacidade.