Há alguns anos – em abril de 2014 – a Spring IO disponibilizava a primeira versăo năo-beta do Spring Boot, a 1.0.0, depois de mais de dezoito meses de desenvolvimento e maturaçăo.
Desde entăo, o projeto tem evoluído em grande velocidade e, na data de escrita deste artigo, já se encontra na versăo 1.2.5, com a 1.3.x batendo a porta.
O Spring Boot é um projeto-chave para a Spring IO, mas, por ser recente, muitos desenvolvedores ainda năo tiveram um primeiro contato com ele e muitos dos já introduzidos ainda desconhecem algumas ou várias de suas possibilidades e recursos.
É uma ferramenta de alavancagem de produtividade e qualidade. Assim, se vocę é um desenvolvedor que lida com aplicaçőes baseadas em Spring, deve ao menos conhecę-la.
Conteúdo completo: Curso de Spring Boot
Ao ler este artigo vocę entenderá as motivaçőes por trás desse projeto, assim como sua importância, năo só para a Spring IO, como para a indústria de software atual.
Também irá aprender, se já năo sabe, como dar seus primeiros passos no uso do Spring Boot, assim como orientá-lo em casos excepcionais ŕs suas configuraçőes pré-fixadas.
Portanto, mesmo ŕqueles que năo estăo envolvidos com o Spring em seu dia a dia, ou o fazem muito esporadicamente, este artigo trará muita informaçăo útil, de uma forma ou de outra.
Com a finalidade de exercício dos conceitos, mecanismos e pontos apresentados, este artigo também traz um pequeno projeto web que expőe um serviço REST de consulta de aeroportos pelo mundo através dos critérios país, cidade ou código da International Air Transport Association, IATA. É uma aplicaçăo um tanto mais complexa que um "Hello World!", mas simples ao ponto de năo perdermos de vista nosso foco, a compreensăo e uso do Spring Boot.
Para construir e executá-la é preciso apenas do JDK, do Maven e estar conectado ŕ Internet, para que o mesmo descarregue as dependęncias do projeto. Apesar de ser inteiramente funcional com o Java 6 e 7, replicamos aqui a recomendaçăo do documento de referęncia do Spring Boot em utilizá-lo com o Java 8 – como veremos, entretanto, configurá-lo a uma ou outra versăo é tăo simples como escrever o número dela.
Quanto ao Maven, é necessário que seja a versăo 3.2+. É possível também utilizar o Gradle (1.12+), mas como o primeiro é mais conhecido e já faz parte do dia a dia da maior parte dos desenvolvedores, nosso projeto irá adotá-lo.
Apesar de código e recursos em arquivo năo somarem muito mais que uma dezena de itens, recomenda-se o uso de uma IDE, preferencialmente o Spring Tool Suite (STS) – mas só pelo fato de ele possuir uma integraçăo natural com componentes Spring, como o próprio Boot, o que facilita a execuçăo e depuraçăo com o mínimo esforço.
Para entendermos por que o Spring Boot foi criado, precisamos conhecer um pouco da história do Spring Framework. E para que possamos entender, de fato, o Spring Framework, precisamos conhecer um pouco da história do J2EE, Java 2 – Enterprise Edition. Comecemos, entăo, a discorrer sobre essas histórias e suas relaçőes, a começar pelo J2EE. É provável que alguns dos leitores já saibam delas, mas vale a pena ver de novo.
O J2EE, parte da plataforma Java, é similarmente uma plataforma, mas específica para o desenvolvimento de aplicaçőes Java em arquitetura de multicamadas, modular e distribuída, executadas em servidores de aplicaçőes.
Ela năo é exatamente um produto, mas um conjunto de especificaçőes, originalmente desenvolvido pela Sun Microsystems (casa original do Java, hoje na Oracle, como sabemos), e lançado evolutivamente em versőes.
A partir da versăo 1.3 a especificaçăo da plataforma passou ao domínio da JCP (Java Community Process), que a controla através de JSRs (Java Specification Requests), como a JSR-58, que especifica o J2EE 1.3 (2001), a JSR-151, que especifica o J2EE 1.4 (2002), e assim por diante.
O Java EE – passemos a utilizar a sigla atual a partir daqui – inclui diversas especificaçőes de API, como o JDBC, e-mail, JMS, web services, RMI, JTA, JPA, JSF, JMX, JNDI, manipulaçăo de XML, etc. e como usá-las de maneira coordenada. Há também especificaçőes únicas a seus componentes, como EJB, servlets, portlets e diversas tecnologias de serviços web. Todas essas especificaçőes estăo interligadas com o propósito de permitir a criaçăo de aplicaçőes corporativas – termo comum que usamos para designar uma aplicaçăo Java EE – portáveis entre os servidores de aplicaçăo, os quais disponibilizam todas as especificaçőes como infraestrutura de maneira uniforme, além de garantir escalabilidade, concorręncia e gerenciamento dos componentes e aplicaçőes entregues (deployed) neles.
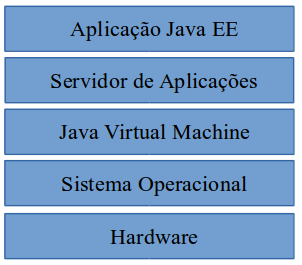
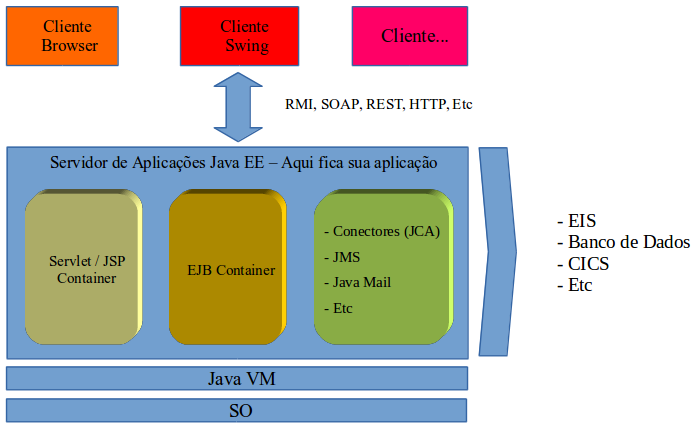
O objetivo é permitir ao desenvolvedor manter o máximo possível de seu foco na construçăo do negócio de sua aplicaçăo e alavancar produtividade e qualidade. Observe na Figura 1 a visăo geral do Java EE. A Figura 2 apresenta uma visăo mais detalhada e integrada.
Figura 1. Visăo geral da pilha Java EE.
Figura 2. Visăo integrada da pilha Java EE.
Năo há como negar que o Java EE tenha sido e seja um sucesso. Diferentemente do CORBA, Common Object Request Broker Architecture, da OMG, e do DCOM/COM+, da Microsoft, – só para citar duas das propostas próximas em intençăo e modelo de mais destaque na época do surgimento do Java EE – sua adoçăo pelo mercado e pelos desenvolvedores foi significativamente maior.
Além de contar com a força crescente da plataforma Java ŕ época, a estratégia de delegar a especificaçăo comunitária ŕ JCP pela Sun Microsystems e seu foco em dominar, ou ao menos estar entre os mais importantes nomes do mercado de soluçőes para o desenvolvimento e execuçăo de aplicaçőes corporativas, impulsionaram a consolidaçăo e evoluçăo autossustentável da plataforma Java EE.
Năo há também como negar que o Java EE tenha tido muitos problemas em seus primeiros anos. Todos ou boa parte deles vęm sendo tratados a cada nova versăo das diversas especificaçőes. De qualquer forma, no entanto, o desconforto causado deu espaço a novos modelos de desenvolvimento, manutençăo e execuçăo de aplicaçőes corporativas, como é o caso do Spring Framework.
O desconforto deveu-se principalmente a tręs fatores. O primeiro deles é que apesar de todo o cuidado e visăo das especificaçőes, o como elas eram implementadas e coordenadas em um servidor de aplicaçőes Java EE ficou bastante vago e até mesmo ausente em alguns aspectos nas primeiras versőes, afetando definiçőes de segurança, representaçăo de campos CMP (Container Managed Persistence) na classe de bean, ordem de deployment de módulos, para citar alguns. As diversas implementaçőes tentaram endereçar da melhor maneira possível algumas das lacunas de definiçăo citadas. Alguns exemplos comerciais e open source de servidores de aplicaçăo săo:
Essa quantidade de opçőes, apesar de vibrante, afetava um dos pilares conceituais do Java EE: a portabilidade. Cada produto tinha seu conjunto de ferramentas e especializaçőes de configuraçőes e o resultado final é que o único artefato portável era o código da aplicaçăo. Iniciou-se, entăo, um programa de certificaçăo para servidores de aplicaçăo, mas sua adoçăo foi lenta.
O JBoss AS, por exemplo, só se tornou certificado a partir de sua versăo 4. Apesar de ser ideal estar 100% fiel ŕ especificaçăo, é mais importante manter a base de usuários e clientes que simplesmente ter um selo de conformidade.
O código de uma aplicaçăo Java EE, vale a pena frisar, talvez seja sua parte mais descomplicada e que consuma menos tempo no fluxo de entrega, ao contrário de sua configuraçăo, empacotamento e deployment.
Lembremos que a intençăo de todas as especificaçőes é liberar a aplicaçăo de todo código de infraestrutura, como segurança, transaçăo, resoluçăo de nomes, camada de persistęncia, detalhes de mensageria, etc., os quais devem ser disponibilizados e coordenados pelo servidor de aplicaçőes.
Obviamente, a aplicaçăo necessita configurar o uso desses componentes junto ao servidor. Na prática, há muito que se configurar através, principalmente, de descritores em XML.
Desde o início soube-se da complexidade da configuraçăo no Java EE. Por isso mesmo foram formulados guias para o ambiente de desenvolvimento e entrega de aplicaçőes nos quais existiam diversos papéis além do desenvolvedor, como o do empacotador, entregador e administrador.
Năo é difícil imaginar que poucas empresas possuíam ou possuem tal estruturaçăo. Na vida real os papéis acabam se acumulando nos desenvolvedores, afetando outro pilar conceitual do Java EE: o foco no negócio.
O segundo fator de desconforto do Java EE, como já foi de certa forma delineado, é a configuraçăo complexa – e como foi ressaltado no parágrafo anterior, diferindo conforme o produto utilizado. Também foi ressaltado no parágrafo anterior que na prática o papel de configuraçăo acaba se acumulando no desenvolvedor.
Por contraditório que seja ou năo, quando elas afetam ambientes de produçăo ou qualquer outro ambiente sensitivo, a responsabilidade é das equipes de operaçăo, cujo modus operandi difere fundamentalmente dos das equipes de desenvolvimento.
Essa impedância histórica entre essas áreas acaba afetando outro pilar conceitual do Java EE: a produtividade/agilidade.
Curiosamente essa tensăo vem alavancado modelos de Desenvolvimento versus Operacionalizaçăo, que hoje chamamos de DevOps. Também é interessante observar que o termo Convention Over Configuration – convençăo sobre configuraçăo, apesar de năo estar exclusivamente ligado ao Java EE, recebeu um novo acento desde entăo.
O terceiro fator de desconforto é o sobrepeso. Uma aplicaçăo Java EE pode contar com todas as facilidades expostas pelo servidor de aplicaçőes, mas ela precisa? Na prática, observamos que muito poucas utilizam todas as facilidades.
A imensa maioria precisa apenas do Servlet Container e da camada de persistęncia através de JPA/JDBC. Eventualmente utiliza mensageria por JMS para implementar padrőes assíncronos. Utilizar o JAAS para segurança é muitas vezes muito complicado para os requisitos da aplicaçăo e o desenho acaba optando por mecanismos mais leves e de simples uso para tal.
Enfim, a aplicaçăo ainda é corporativa, mas utiliza apenas uma pequena parte das facilidades disponíveis. Apesar disso, sendo executada em um servidor Java EE, irá pagar por todos os ônus associados.
Esse é o motivo de encontrarmos boa parte dessas aplicaçőes sendo executadas em produtos que cumprem apenas parte das especificaçőes, como os Servlet Containers Tomcat e Jetty, e produtos exclusivos de mensageria com JMS e ESB (Enterprise Service Bus), como o Mule, e o WSO2. Assim, as aplicaçőes cumprem seus requisitos em ambientes costumeiramente mais simples de implantar e gerenciar, tanto para as equipes de desenvolvimento quanto operaçőes.
Apesar dos desconfortos citados, como foi dito inicialmente, o Java EE os tem tratado e vem evoluindo a cada nova versăo. E mesmo com todos eles, năo há como negar que desenvolver uma aplicaçăo corporativa com o Java EE seja muitíssimo mais simples e gerenciável que com CORBA, por exemplo.
Em novembro de 2002, Rod Johnson publicou pela editora Wrox, o livro: Expert One-on-One J2EE Design and Development. O objetivo de seu trabalho foi:
1) apontar o quanto complexo se tornava o desenvolvimento e manutençăo da maioria das aplicaçőes corporativas quando se seguia ortodoxamente o guia do J2EE; e
2) apresentar uma alternativa que fosse mais simples, menos custosa, com tempo de entrega de mercado mais realista, mais gerenciável e com melhor performance.
Acompanhavam o texto mais de 30.000 linhas de código em Java de um framework inicialmente batizado como Interface21 e futuramente renomeado como Spring Framework. Muitos dos conceitos e mecanismos fundamentais do Spring já estavam nessas linhas, a saber: um container de IoC – Inversion of Control, ou Inversăo de Controle – com um BeanFactory, um ApplicationContext e um DI, ou Dependency Injection – Injeçăo de Dependęncia – capaz e funcional, os primórdios do Spring MVC com Controller, HandlerMapping e associados, o JdbcTemplate e o conceito de acesso a dados agnóstico ŕ tecnologia.
Esses componentes săo o básico para a implementaçăo de uma aplicaçăo web CRUD utilizando-se o Spring. Citando Rod Johnson, o nome Spring foi inspirado pelo fato de se buscar uma Primavera, novos ares, ao desenvolvimento Java EE sob o Inverno de sua abordagem tradicional.
Diante de tudo isso, o Spring Framework năo levou muito tempo para conquistar o público. Năo foram só as dificuldades inerentes ao desenvolvimento e manutençăo do Java EE tradicional que o impulsionaram. O conceito e mecanismos de DI săo extremamente poderosos, pois atuam sobre um dos principais vilőes do desenvolvimento de software moderno, o acoplamento.
Desacoplar significa simplificar, ampliar extensibilidade e modularidade, melhorar o processo de testes, reduzir impactos negativos, aumentar produtividade e qualidade.
Coincidęncia ou năo, esses atributos săo muito alinhados ŕs metodologias de desenvolvimento ágil e evoluçăo contínua. Ou seja, houve uma conjunçăo de fatores que alavancaram exponencialmente a aceitaçăo e uso do Spring como framework de desenvolvimento Java EE năo tradicional.
Categoricamente, hoje, o Spring é uma plataforma Java que disponibiliza, de forma ordenada e compreensiva, uma infraestrutura para o desenvolvimento de aplicaçőes corporativas. O Spring cuida da infraestrutura e vocę, desenvolvedor, de sua aplicaçăo/negócio.
Muito parecido com o proposto pelo Java EE tradicional, năo? A diferença está em como o Spring faz. Em uma única expressăo, ele năo é intrusivo.
Ao contrário, podemos desenvolver toda a aplicaçăo utilizando apenas POJO – Plain Old Java Object, classes simples. Năo há necessidade de se implementar ou estender nenhum artefato alienígena aos nossos requisitos, como EJB.
O Spring simplesmente aplica serviços corporativos (JPA, JTA, JMX, JNDI, JMS, etc.) conforme solicitemos. Para realizar esse feito, ele se utiliza do container de IoC e também de mecanismos de AOP – Aspect Oriented Programming. Isso nos possibilita, citando seu próprio manual de referęncia:
Reforçando, a única coisa que codificamos săo POJOs. Todo o resto ligamos, como se brincássemos com Lego.
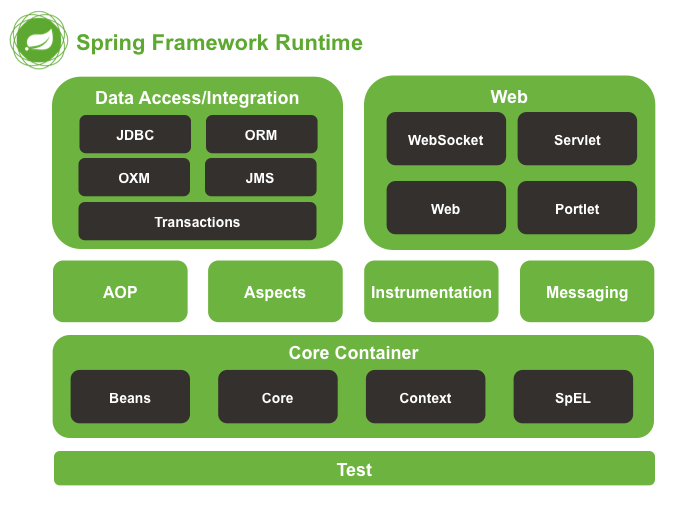
O Spring pretende ser uma soluçăo leve e one-stop-shop, ou seja, uma caixa de ferramentas completa para desenvolvimento Java EE, como ilustra a Figura 3. Entretanto, ele é extremamente modular em si, permitindo utilizar apenas o que necessitamos.
Portanto, pode-se empregar o container IoC com qualquer framework web, inclusive o Spring MVC, ou apenas suas abstraçőes para persistęncia, por exemplo.
Tipicamente, uma aplicaçăo com o Spring é desenvolvida para executar em simples Servlet Containers, como o Tomcat ou Jetty, mas nada nos impede de a termos em um servidor de aplicaçőes e até mesmo ligar componentes Spring a uma aplicaçăo Java EE tradicional.
Figura 3. Runtime do Spring Framework.
Inicialmente, o Spring Framework possuía seu container de IoC e seus mecanismos para executar a carga – o bootstrapping – do contexto dos Beans, inclusive nossos POJOs, conforme configurado em arquivos XML que definem os mesmos.
Também possuía uma série de facilidades e mecanismos para persistęncia de dados, leitura de recursos e MVC. Em suma, disponibilizava o modelo e ferramentas para o desenvolvimento de aplicaçőes Java EE web de uma forma descomplicada, eficiente (e até mesmo prazerosa para aqueles que conheciam o trabalho árduo de se desenvolver o equivalente com o Java EE tradicional).
Rod Johnson, Juergen Hoeller e Yann Caroff decidiram entăo fundar uma empresa, a SpringSource, centrada no projeto open source do Spring Framework.
A comunidade e adesăo crescentes o impulsionaram a uma evoluçăo rápida e marcante, sempre mantendo o espírito Java EE descomplicado de sua origem. Gradativamente foram sendo adicionadas novas funcionalidades e mecanismos para segurança, como o Spring Security, SOAP web services, com o Spring WS, padrőes de integraçăo corporativa, com o Spring Integration, infraestrutura de serviços em batch, com o Spring Batch, entre tantos outros.
Além disso, os componentes preexistentes, como o Spring MVC, foram se tornando mais e mais inteligentes e completos. Ao final de alguns anos o Spring Framework se tornou um tipo de ecossistema de desenvolvimento Java EE.
Seu poder de penetraçăo como novo modelo de desenvolvimento corporativo fez com que a empresa VMware comprasse a SpringSource em 2009 por cerca de 420 milhőes de dólares. Nos dias de hoje o Spring está sob o nome da Pivotal, junçăo criada pela VMware, EMC Corporation e GE para manter todos os produtos de software para aplicaçőes, como o Spring.
Apesar de sempre ter estado sob a direçăo de alguma empresa, o Spring é e sempre será um projeto open source, sob licença Apache 2.0 e intrinsecamente comunitário.
Esse ecossistema, hoje denominado Spring IO, é um conjunto de projetos contendo o Spring Boot, Spring Framework, Spring XD, Spring Cloud, Spring Data, Spring Integration, Spring Batch, Spring Security, Spring HATEOAS, Spring Social, Spring AMQP, Spring Mobile, Spring for Android, Spring Web Flow, Spring Web Services, Spring LDAP, Spring Session, Spring Roo e alguns ainda por vir, como o Spring Statemachine. Ufa, quanto projeto!
Essa quantidade de soluçőes se deve ao modus operandi do Spring, que abraça novos desafios no desenvolvimento EE conforme eles surjam, através da incubaçăo e maturaçăo de novos projetos e componentes.
Esse aspecto pragmático e eclético está no cerne da primeira das duas principais críticas ao Spring: a falta de uma concepçăo coesa em detrimento de uma coleçăo inconsistente de soluçőes de melhores práticas a aspectos diversos do desenvolvimento Java EE.
A segunda crítica é o excesso de dependęncia de configuraçăo em XML, que consome muito mais tempo do desenvolvedor que o próprio desenvolvimento de código. Essas duas críticas săo pertinentes.
A crítica com relaçăo ŕ coesăo talvez seja exagerada, mas năo há como negar que o espírito do Spring tenha muito mais compromissos com eficięncia e pragmatismo do que com concisăo conceitual. Isso năo vai, a princípio, mudar.
Com relaçăo ŕ dependęncia de muita configuraçăo em XML, trata-se do desdobramento natural da diversidade e abrangęncia do próprio ecossistema. É necessário configurar o MVC, o Security, o Integration, seus próprios Beans, etc. É necessário dizer ao Spring como ele irá carregar o contexto, enfim, e quais os mapeamentos e ligaçőes entre os componentes, entre outras coisas.
No entanto, assim como o Java EE tradicional, a cada versăo o Spring busca simplificar o trabalho com configuraçăo. Uma das medidas foi o uso do JavaConfig desde a versăo 3, mecanismo pelo qual as definiçőes em XML passam a ser substituídas por anotaçőes em classes de configuraçăo.
Mesmo com o JavaConfig (vide BOX 1), ainda há a necessidade de configurar tanto quanto sejam os recursos utilizados. Por isso o Spring também endereça de forma cada vez mais inteligente o aspecto Convention Over Configuration, assumindo muitas coisas através da presença de uma ou outra dependęncia no classpath da aplicaçăo ou várias opçőes de comportamento default para o MVC, mapeamentos e etc., sempre, obviamente, deixando a cargo do desenvolvedor seguir ou fugir dessas configuraçőes default.
O resultado prático é que é muito mais simples desenvolver a mesma aplicaçăo com o atual Spring 4 que com o Spring 1, 2 ou 3, basicamente porque o desenvolvedor perde muito menos tempo com configuraçăo.
BOX 1. JavaConfig
Spring Java Config, ou JavaConfig, é o mecanismo que nos possibilita configurar o Spring IoC diretamente de nossas classes Java por meio de metadados na forma de annotations – presentes no Java desde sua versăo 5 –, năo mais dependendo de arquivos de definiçăo de beans em XML. As principais vantagens em se utilizar o JavaConfig săo:
Ainda assim, o Spring perde em agilidade se desenvolvermos a mesma aplicaçăo com soluçőes paralelas mais recentes, como o Ruby On Rails, Django, Play (vide BOX 2) e Node.js, para citar algumas, que apesar de năo serem tăo abrangentes e generalistas (ainda), atuam no mesmo espaço de desenvolvimento EE.
Ciente de seus próprios problemas e tentando se equiparar em agilidade e ferramental a esses paralelos, ou mesmo incorporar boas ideias deles, o Spring desenvolveu ferramentas como o Spring Roo, porém sua aceitaçăo foi muito baixa.
BOX 2. Rod Johnson
Rod Johnson foi CEO da SpringSource até 2009, quando a VMware a adquiriu. A partir de 2012 ele se tornou um dos diretores da Typesafe Inc., empresa fundada por Martin Odersky e Jonas Bonér. Os produtos hoje mantidos pela Typesafe săo o Scala, Akka e Play!
O Spring Boot, de forma diferente do Roo (acima de tudo năo há geraçăo de código), busca solucionar a complexidade da inicializaçăo e gerenciamento de dependęncias de um projeto com Spring, além de tratar de maneira coesa e eficiente a questăo da configuraçăo, fazendo uso extensivo de Convention Over Configuration.
Essencialmente, o Spring Boot pode ser considerado um plugin para a ferramenta de building, seja ela o Maven ou o Gradle. Seus principais objetivos săo gerenciar dependęncias de maneira opinativa e automática, e simplificar a execuçăo do projeto em tempo de desenvolvimento e depuraçăo.
Com o comando mvn spring-boot:run, por exemplo, o Maven irá executar sua aplicaçăo na porta 8080. Isso é bastante similar ao plugin Maven do Jetty, que se tornou uma forma popular de se desenvolver e testar uma aplicaçăo web utilizando Spring ou outros frameworks.
O Spring Boot também possui a funcionalidade de empacotamento da sua aplicaçăo em um JAR executável contendo todas as dependęncias necessárias, inclusive o Servlet Container, seja ele o Tomcat, Jetty ou mesmo Undertow, apesar de ainda ser possível empacotar um WAR da forma tradicional.
O principal benefício do Boot, entretanto, é a configuraçăo de recursos baseada no que se encontra no classpath. Se o POM de seu Maven inclui a dependęncia do JPA e o driver do PostgreSQL, ele irá criar uma unidade de persistęncia baseada no PostgreSQL.
Se adicionarmos alguma dependęncia web, iremos perceber que o Spring MVC assumirá configuraçőes default e dependęncias com relaçăo a diversos aspectos, como a tecnologia de apresentaçăo (o default é o Thymeleaf), o mapeamento de recursos e marshalling de JSON (o default é o Jackson) e/ou XML (o default é o JAXB 2) para o tratamento de dados de requisiçăo e resposta, que necessitamos em uma aplicaçăo REST, por exemplo.
O Spring Boot é tudo acerca de opiniăo, ou seja, a menos que especifiquemos explicitamente, ele irá trazer dependęncias predefinidas, assim como instanciar e injetar beans predefinidos conforme o tipo de aplicaçăo que estamos construindo (iremos ver como funciona esse mecanismo em nossa aplicaçăo exemplo).
Podemos năo concordar com algumas opiniőes como, por exemplo, a versăo de dada dependęncia ou o Servlet Container default, mas ao menos ele as tem e, caso insistamos com a nossa, ele năo se opőe.
Por exemplo, se nosso POM declara o uso de persistęncia com o Spring Data, mas năo declaramos nada mais, será assumido que queremos utilizar JPA e Hibernate para a camada de persistęncia. Se estamos implementando uma aplicaçăo web e năo declaramos nada em específico, o Boot irá assumir que usaremos o Thymeleaf como view resolver.
Em suma, o que o Spring Boot faz principalmente, de maneira muito elegante, é nos livrar de qualquer preocupaçăo desnecessária com dependęncias e configuraçőes que săo as mesmas em 99% dos casos. E se o caso está no 1% restante, ele acata nossa opiniăo com a mesma elegância, como veremos em nosso projeto.
Năo há como negar a crescente tendęncia do desenvolvimento de aplicaçőes corporativas estarem migrando para outras linguagens e modelos além do Java EE. Independentemente disso, há muita lenha a queimar com o Java, seja com o tradicional Java EE ou com o Spring.
Esse último, entretanto, precisava impor alguma ordem e coesăo ŕ sua própria criatividade, e o Spring Boot é essa ordem e coesăo. Mais ainda: o modelo de empacotamento em standalone JAR casa-se muito bem com as unidades de execuçăo desejáveis em uma arquitetura de microserviços e conteinerizaçăo que vem tomando tanto corpo ultimamente.
Em outras palavras, o Boot năo só clareia o horizonte do Spring, mas também o energiza significativamente. Por isso é um projeto tăo importante para o Spring e consequentemente para o Java EE, sendo recomendado que desenvolvedores o entendam e façam uso dele sempre que possível.
Para demonstrar o Spring Boot na prática, iremos desenvolver uma pequena aplicaçăo para consulta de aeroportos que faz uso de uma base de dados gratuita mantida pela OpenFlights – uma ferramenta web (vide Links) que oferece funcionalidades de busca, estatísticas e rotas de voos comerciais pelo mundo. Basicamente, essa base contém o nome de dado aeroporto, seus códigos IATA e ICAO, coordenadas geográficas, fuso, cidade e país. Nossa aplicaçăo web de serviços REST irá fornecer no formato JSON:
Ao executá-la, poderemos acessar seus serviços através do cURL ou um navegador, como ilustra a Listagem 1.
Listagem 1. Exemplos de uso da aplicaçăo através do cURL, supondo que a mesma esteja ŕ porta 8080.
curl http://localhost:8080/openflights/iata/gru
curl http://localhost:8080/openflights/city/rio%20de%20janeiro
curl http://localhost:8080/openflights/country/brazilNota: Para os que năo conhecem, cURL é um programa de linha de comando que utilizamos, principalmente em ambientes Unix/Linux, mas também em ambientes Windows, para efetuar GET, POST, PUT, etc. em dada URL.
Além desta opçăo, também é possível acessar os serviços de nossa aplicaçăo pelo navegador, como o Chrome. Neste caso, no entanto, năo é necessário adicionar o código de espaço ŕ URL, como no trecho “sao%20paulo” no exemplo da Listagem 1, pois o próprio navegador se encarregará disso.
Para a execuçăo, depuraçăo e codificaçăo do projeto, certifique-se que seu ambiente atenda os seguintes requisitos:
O código fonte completo do projeto pode ser obtido na área de download desta ediçăo. Após realizar o download, desempacote-o e o execute conforme a Listagem 2 (foi utilizado um ambiente Linux aqui, mas năo difere muito para o Windows).
Listagem 2. Executando o projeto.
$ cd /tmp
$ tar xzvf airportapp.tar.gz
$ cd airportapp
$ mvn spring-boot:runApós a aplicaçăo subir, experimente acessar as URLs conforme a Listagem 1, com o cURL ou seu navegador. Vocę irá obter uma saída como a da Listagem 3.
Listagem 3. Listando os aeroportos cadastrados para o Rio de Janeiro.
$ curl http://localhost:8080/openflights/city/rio%20de%20janeiro
[{"id":2451,"name":"Campo Delio Jardim De Mattos","city":"Rio De Janeiro","country":"Brazil","iataCode":"","icaoCode":"SBAF","latitude":-22.875083,"longitude":-43.384708,"altitude":110.0,"offsetFromUTC":-3.0,"dstCode":"S","timezone":"America/Sao_Paulo"},{"id":2492,"name":"Galeao Antonio Carlos Jobim","city":"Rio De Janeiro","country":"Brazil","iataCode":"GIG","icaoCode":"SBGL","latitude":-22.808903,"longitude":-43.243647,"altitude":28.0,"offsetFromUTC":-3.0,"dstCode":"S","timezone":"America/Sao_Paulo"},{"id":2544,"name":"Santos Dumont","city":"Rio De Janeiro","country":"Brazil","iataCode":"SDU","icaoCode":"SBRJ","latitude":-22.910461,"longitude":-43.163133,"altitude":11.0,"offsetFromUTC":-3.0,"dstCode":"S","timezone":"America/Sao_Paulo"},{"id":2546,"name":"Santa Cruz","city":"Rio De Janeiro","country":"Brazil","iataCode":"STU","icaoCode":"SBSC","latitude":-22.93235,"longitude":-43.719092,"altitude":10.0,"offsetFromUTC":-3.0,"dstCode":"S","timezone":"America/Sao_Paulo"}]Nossa aplicaçăo possui tręs serviços REST, que executam a busca de aeroportos pelos critérios cidade, país ou código IATA. Após a busca, uma lista contendo um ou mais aeroportos é retornada em JSON, caso haja resultado; caso contrário, o conteúdo da resposta é vazio. Observe que cada um dos serviços REST é atendido por uma controladora.
Para a busca por cidade, temos a controladora CitySearch; por país, a CountrySearch; e por código IATA, a IataCodeSearch. Poderíamos ter uma única controladora para todos os serviços, mas optamos pela divisăo aqui, por maior clareza e separaçăo de responsabilidades.
As controladoras săo especificadas de modo mais detalhado a seguir:
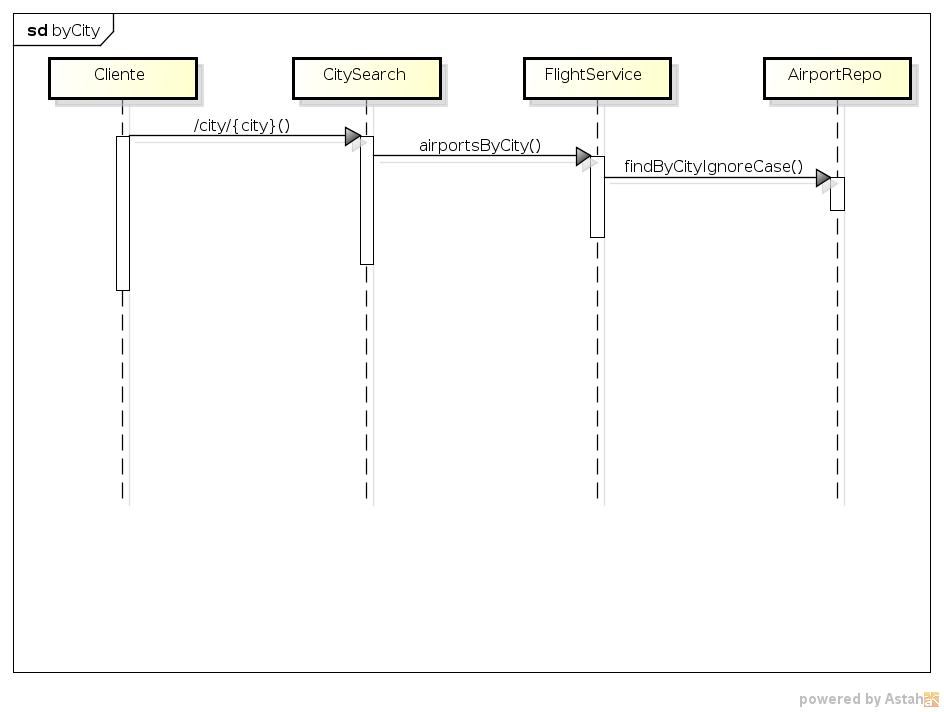
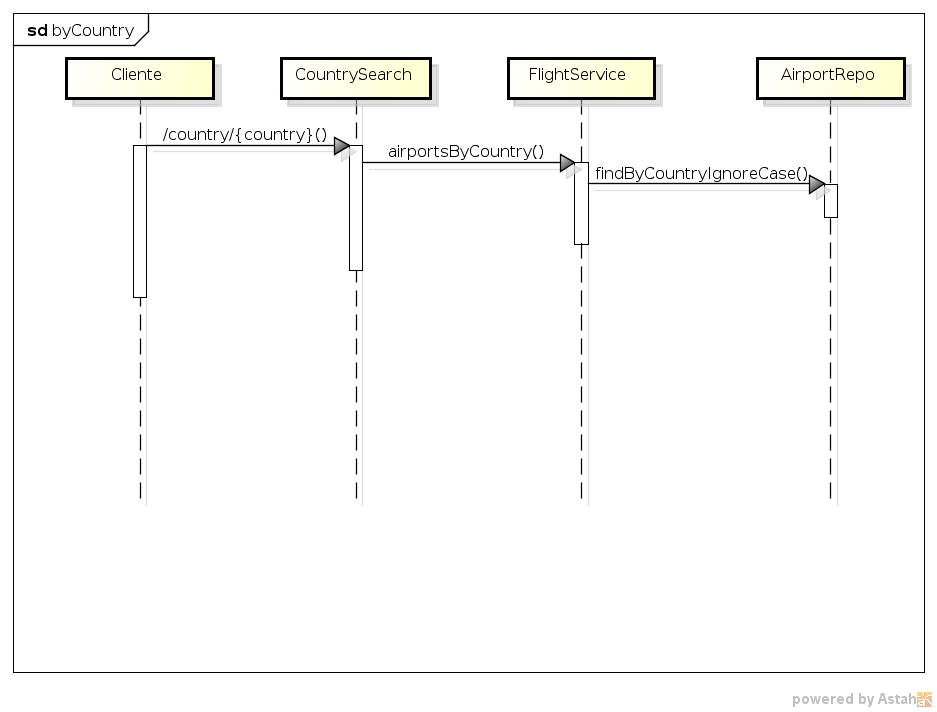
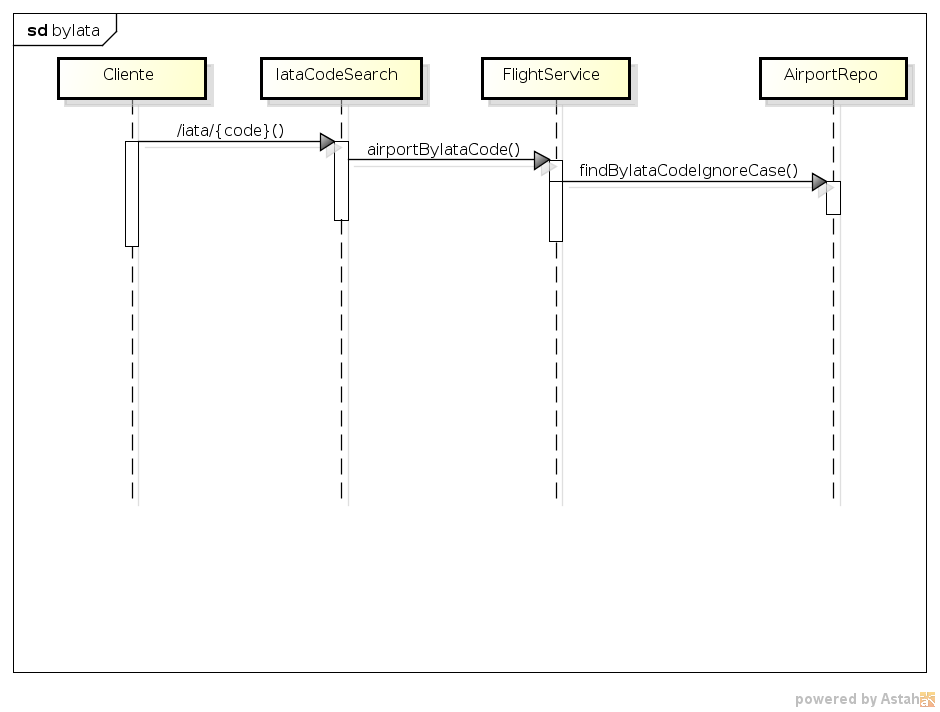
As controladoras utilizam a interface FlightService para realizar a pesquisa. Essa interface existe apenas para tornar abstrata a fonte de dados, pois năo importa ŕ camada de controle se os dados vęm de um banco de dados, um serviço externo ou um arquivo. OpenFlightService é a implementaçăo real de FlightService e se utiliza, como se pode notar no código, do repositório (abstraçăo de repositório de dados feita com o Spring Data) AirportRepo para efetivamente trabalhar com o banco de dados, buscando aeroportos por cidade, país ou código IATA. As Figuras 4, 5 e 6 apresentam os diagramas de sequęncia descrevendo o fluxo de dados da aplicaçăo.
Figura 4. Fluxo da controladora CitySearch.
Figura 5. Fluxo da controladora CountrySearch.
Figura 6. Fluxo da controladora IataCodeSearch.
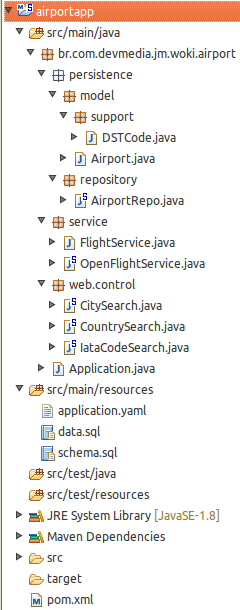
A Figura 7 mostra a estrutura do projeto e seus arquivos conforme apresentados no Eclipse ou STS. Se vocę os abrir, irá perceber que nosso (pouco) código está concentrado em apenas cinco classes: as tręs controladoras (CitySearch, CountrySearch e IataCodeSearch), uma classe de entidade JPA (Airport) e a implementaçăo de FlightService, OpenFlightService. Perceba como, graças ao Spring (MVC e Data) e Spring Boot, estamos focados quase que exclusivamente em nosso negócio.
Figura 7. Projeto airportapp e seus arquivos no Eclipse.
Como com qualquer projeto Maven, iniciamos por seu POM. O pom.xml do projeto que vocę descarregou é diferente do apresentado na Listagem 4. O original é a versăo final, na qual iremos chegar com todas as customizaçőes. O pom.xml da listagem năo possui as seguintes opçőes, ou “opiniőes”, que faremos prevalecer ŕs default do Spring Boot:
BOX 3. HikariCP
O HikariCP é a implementaçăo de um pool de conexőes JDBC criado em 2013 que tem ganhado destaque ultimamente por sua performance, confiabilidade e tamanho reduzido – cerca de 90Kb apenas.
Listagem 4. POM inicial do projeto airportapp.
01 <project xmlns="http://maven.apache.org/POM/4.0.0"
02 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
03 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
04 http://maven.apache.org/xsd/maven-4.0.0.xsd">
05 <modelVersion>4.0.0</modelVersion>
06 <groupId>br.com.devmedia.jm.woki</groupId>
07 <artifactId>airportapp</artifactId>
08 <version>0.0.1-SNAPSHOT</version>
09
10 <parent>
11 <groupId>org.springframework.boot</groupId>
12 <artifactId>spring-boot-starter-parent</artifactId>
13 <version>1.2.5.RELEASE</version>
14 </parent>
15 <properties>
16 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
17 <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
18 <java.version>1.8</java.version>
19 </properties>
20 <dependencies>
21 <!-- Core -->
22 <dependency>
23 <groupId>org.springframework.boot</groupId>
24 <artifactId>spring-boot-starter</artifactId>
25 </dependency>
26 <!-- Web application -->
27 <dependency>
28 <groupId>org.springframework.boot</groupId>
29 <artifactId>spring-boot-starter-web</artifactId>
30 </dependency>
31 <!-- Spring Data JPA -->
32 <dependency>
33 <groupId>org.springframework.boot</groupId>
34 <artifactId>spring-boot-starter-data-jpa</artifactId>
35 </dependency>
36 <!-- Embedded DB: H2 -->
37 <dependency>
38 <groupId>com.h2database</groupId>
39 <artifactId>h2</artifactId>
40 <scope>runtime</scope>
41 </dependency>
42 </dependencies>
43 </project>A análise desse POM irá nos mostrar muito do trabalho do Spring Boot. Comecemos observando a declaraçăo do projeto pai, das linhas 10 a 14. Ao declararmos o spring-boot-starter-parent como pai, teremos ŕ măo toda a gestăo de dependęncias do Spring Boot, o que nos libera de declará-las e mantę-las manualmente.
As dependęncias cujos nomes começam com spring-boot-starter săo especiais, pois năo se tratam de um artefato único, mas um conjunto de artefatos. Por exemplo, o spring-boot-starter traz consigo:
· spring-boot.jar;
o spring-context.jar.
· spring-boot-autoconfigure.jar;
· spring-boot-starter-logging.jar;
o jcl-over-slf4j.jar;
o jul-to-slf4j.jar;
o log4j-over-slf4j.jar;
o logback-classic.jar;
§ logback-core.jar.Uma forma de visualizar a árvore de dependęncias do projeto é utilizar o plugin dependency do próprio Maven. A partir disso, execute o comando mvn dependency:tree e vocę terá em uma árvore todas as dependęncias do projeto.
A dependęncia h2 mostra outro aspecto do gerenciamento de dependęncias do Boot. Apesar de năo estar sob nenhum spring-boot-starter, é uma de suas dependęncias gerenciadas e a prova disso é que năo necessitamos declarar sua versăo.
Todas as dependęncias e suas versőes – para cada versăo do Spring Boot – estăo, obviamente, documentadas em seu manual de referęncia. Sendo assim, antes de declarar qualquer uma, é bom consultar essa documentaçăo. Năo que năo se possa declará-la independentemente, mas porque é muito melhor deixá-lo gerenciá-las.
Caso desejemos depender de uma versăo diferente da declarada no Boot, basta adicionar a propriedade ${artifactId}.version ao conjunto de propriedades do projeto. Por exemplo, a versăo de H2 declarada no Spring Boot 1.2.5 é a 1.4.187. Supondo que haja a 1.4.188 e temos interesse em utilizá-la, basta adicionar a propriedade <h2.version>1.4.188</h2.version> e a mesma será acatada.
Por falar em propriedades, observe na linha 18 a definiçăo da versăo Java que queremos adotar. Se fosse necessário o Java 1.7, bastaria alterar o valor de java.version para 1.7.
Além do gerenciamento de dependęncias, o Spring Boot também é um plugin, e como tal, disponibiliza tręs goals:
Nota: Para utilizar o goal repackage do spring-boot é necessário acompanhá-lo do goal install do Maven, como no exemplo: mvn clean install spring-boot:repackage.
Para executar a aplicaçăo, basta invocar o Maven com mvn spring-boot:run. Observe que com esse comando estamos solicitando ao Maven que utilize o plugin spring-boot e invoque o goal run do mesmo.
Para demonstrar como customizar o projeto, vamos “brincar” um pouco com o Spring Boot rejeitando duas de suas opiniőes. Sendo assim, suponha que nosso projeto tenha como requisito năo funcional o uso do Jetty como Servlet Container e do HikariCP como gerenciador de pool de conexőes JDBC. Impor nossa opiniăo, neste caso, traduz-se em alterar o POM de nosso projeto.
Para utilizar o Jetty, por exemplo, devemos excluir o spring-boot-starter-tomcat do spring-boot-starter-web, pois essa é a opiniăo original, e adicionar a dependęncia spring-boot-starter-jetty, como demonstra a Listagem 5, que traz o trecho do POM alterado.
Listagem 5. Alterando opiniőes do Spring Boot – de Tomcat para Jetty.
26 <!-- Web application -->
27 <dependency>
28 <groupId>org.springframework.boot</groupId>
29 <artifactId>spring-boot-starter-web</artifactId>
30 <exclusions>
31 <exclusion>
32 <artifactId>spring-boot-starter-tomcat</artifactId>
33 <groupId>org.springframework.boot</groupId>
34 </exclusion>
35 </exclusions>
36 </dependency>
37 <dependency>
38 <groupId>org.springframework.boot</groupId>
39 <artifactId>spring-boot-starter-jetty</artifactId>
40 </dependency>Para fazer uso do HikariCP, o procedimento é parecido. Primeiro, excluímos o tomcat-jdbc como dependęncia de spring-boot-starter-data-jpa, e depois adicionamos a dependęncia do HikariCP, como mostra o trecho presente na Listagem 6.
Listagem 6. Alterando opiniőes do Spring Boot – de Tomcat-JDBC para HikariCP.
41 <!-- Spring Data JPA -->
42 <dependency>
43 <groupId>org.springframework.boot</groupId>
44 <artifactId>spring-boot-starter-data-jpa</artifactId>
45 <exclusions>
46 <exclusion>
47 <artifactId>tomcat-jdbc</artifactId>
48 <groupId>org.apache.tomcat</groupId>
49 </exclusion>
50 </exclusions>
51 </dependency>
...
58 <dependency>
59 <groupId>com.zaxxer</groupId>
60 <artifactId>HikariCP</artifactId>
61 <scope>runtime</scope>
62 </dependency>
63 </dependencies>Neste momento, ao executar mvn spring-boot:run vocę poderá observar pela saída da aplicaçăo que o Servlet Container mudou para Jetty e que o gerenciador do pool de conexőes JDBC passou a ser o HikariCP.
Até aqui, vimos como criar e customizar o POM de um projeto com o Spring Boot, e vimos também como executá-lo em tempo de desenvolvimento com o goal run. De agora em diante, vamos entender o código que traz a aplicaçăo airportapp ŕ vida. Comecemos pela classe de entrada, ou seja, aquela a partir da qual o Spring Boot irá inicializar todos os beans necessários. No caso do nosso exemplo, a classe br.com.devmedia.jm.woki.airport.Application, apresentada na Listagem 7.
Listagem 7. Nossa classe de entrada para aplicaçőes que fazem uso do Spring Boot.
01 @SpringBootApplication
02 public class Application {
03 public static void main(String... args) {
04 SpringApplication.run(Application.class, args);
05 }
06 }O Boot sabe que se trata da classe de entrada porque ela possui o método main() e pela invocaçăo de SpringApplication.run(). O nome da classe ou seu pacote năo importam.
Na linha 4 dessa listagem invocamos o método run() e informamos como argumentos nossa própria classe e os argumentos passados para a aplicaçăo. Esse método aceita uma classe que seja fonte de configuraçăo (contenha a anotaçăo @Configuration) e parâmetros repassados da linha de comando.
Essa é a variaçăo mais recomendada de SpringApplication.run() para se inicializar uma aplicaçăo com o Spring Boot. Há outras, mas essa opçăo induz ŕ utilizaçăo de uma única classe de entrada de configuraçăo (que pode, obviamente, carregar outras em cascata), tornando o código mais legível e facilitando a manutençăo. “Um momento! Isso significa que nossa classe é o ponto de entrada de configuraçăo?
Mas ela năo está anotada com @Configuration nem está configurando nada! ” – pode-se argumentar. Acontece que ela é e está configurando tudo em nossa aplicaçăo. A anotaçăo @SpringBootApplication é uma anotaçăo de convenięncia que contém as seguintes anotaçőes do Spring: @Configuration, @EnableAutoConfiguration e @ComponentScan. Essas duas últimas, basicamente, dizem ao inicializador do Spring: “Busque e instancie todo bean anotado deste pacote para frente”.
Com “bean anotado” estamos nos referindo a classes anotadas com @Configuration e métodos que retornam @Bean, e classes anotadas com @Service, @Component, @Controller e @RestController, por exemplo.
Esse processo de autoconfiguraçăo e busca de componentes, como se sabe, năo é especificamente do Boot, e sim do próprio Spring Framework.
Voltando ŕ nossa aplicaçăo, nossa classe Application năo configura nada, mas dispara a busca por beans a partir de seu pacote. Assim, serăo encontradas e devidamente inicializadas as classes e interfaces:
Deste modo serăo inicializados todos os componentes de nossa aplicaçăo. Como podemos notar, trata-se de um processo de bootstrapping normal do Spring, mas aqui orquestrado pelo Spring Boot.
Note também que năo há qualquer anotaçăo ou dependęncia do Boot em nenhum desses componentes. Săo artefatos usuais do Spring MVC e Spring Data/JPA, como mostram de maneira reduzida a Listagem 8, com uma das controladoras, a Listagem 9, com a entidade Airport, a Listagem 10, com o repositório AirportRepo, e a Listagem 11, com a implementaçăo de FlightService, OpenFlightService.
Listagem 8. Código do controller CitySearch.
01 @RestController
02 @RequestMapping(value="/city")
03 public class CitySearch {
04 private static final Logger logger = LoggerFactory.getLogger(CitySearch.class);
05
06 @Autowired
07 private FlightService flightService;
08
09 @RequestMapping(value="/{cityName}", method=RequestMethod.GET)
10 public List<Airport> search(@PathVariable String cityName) {
11 List<Airport> retval = flightService.airportsByCity(cityName);
12 if(retval != null) {
13 logger.info("Aeroportos para a cidade {}: {}", cityName, retval.size());
14 } else {
15 logger.info("Aeroportos para a cidade {}: 0", cityName);
16 }
17 return retval;
18 }
19 }Listagem 9. Código da entidade JPA Airport.
01 @Entity(name="airport")
02 @SuppressWarnings("serial")
03 public class Airport implements Serializable {
04 @Id @GeneratedValue
05 private long id;
06 private String name;
07 private String city;
08 private String country;
09 @Column(name="iatacode")
10 private String iataCode;
11 @Column(name="icaocode")
12 private String icaoCode;
13 private double latitude;
14 private double longitude;
15 private double altitude;
16 @Column(name="offsetutc")
17 private double offsetFromUTC;
18 @Column(name="dstcode")
19 @Enumerated(EnumType.STRING)
20 private DSTCode dstCode;
21 private String timezone;Listagem 10. Código do repositório Spring Data/JPA AirportRepo.
01 public interface AirportRepo extends JpaRepository<Airport, Long> {
02 List<Airport> findByCityIgnoreCase(String city);
03 List<Airport> findByCountryIgnoreCase(String country);
04 Airport findByIataCodeIgnoreCase(String iataCode);
05 }Listagem 11. Código da classe de serviço OpenFlightService.
01 @Service
02 public class OpenFlightService implements FlightService {
03 @Autowired
04 private AirportRepo airportRepository;
05
06 @Override
07 public List<Airport> airportsByCity(String city) {
08 return airportRepository.findByCityIgnoreCase(city);
09 }
10
11 @Override
12 public List<Airport> airportsByCountry(String country) {
13 return airportRepository.findByCountryIgnoreCase(country);
14 }
15
16 @Override
17 public Airport airportByIataCode(String iataCode) {
18 return airportRepository.findByIataCodeIgnoreCase(iataCode);
19 }
20 }As propriedades da aplicaçăo năo ficam em seu POM nem em código, mas em um arquivo próprio. É possível parametrizar muitos aspectos e comportamentos da aplicaçăo através desse arquivo. O nosso, entretanto, configura apenas os seguintes:
O nome desse arquivo é, por default, application.properties ou application.yaml – sim, o Spring Boot também entende configuraçőes no formato YAML (veja o BOX 4).
BOX 4. YAML
O YAML é uma linguagem para serializaçăo de dados derivado do JSON. Seus objetivos principais săo expressar informaçăo de forma humanamente legível, portabilidade entre linguagens de programaçăo e suporte a estruturas de dados nativas em linguagens modernas como o C/C++, Java, Ruby, Perl, Python, JavaScript, entre outras.
Na prática, o que estaria em um arquivo de propriedades como:
application.name=MyApplication
application.version=1.0.0
pode ser expresso dessa forma em YAML:
application:
name: MyApplication
version: 1.0.0
Caso nenhum application.properties/yaml seja encontrado, o Boot assumirá valores default sempre que possível. Nossa aplicaçăo, no entanto, possui o arquivo application.yaml, conforme a Listagem 12.
Listagem 12. Configuraçőes em application.yaml.
01 logging:
02 level:
03 org.springframework: INFO
04 br.com.devmedia.jm.woki.airport: INFO
05 server:
06 port: 8080
07 contextPath: /openflights
08 spring:
09 jpa:
10 hibernate:
11 ddl-auto: none
12 datasource:
13 platform: h2Note que entre as linhas 1 e 4 estamos configurando nossos níveis de logging. Já as linhas de 5 a 7 configuram a porta e o contexto raiz da aplicaçăo no Servlet Container. As linhas 8 a 13, por sua vez, configuram a geraçăo de DDL pelo Hibernate e a plataforma, ou tipo de banco de dados, de nosso Datasource.
Em nosso caso năo queremos que o Hibernate execute qualquer DDL a partir de nossas entidades e indicamos que usaremos o H2. Iremos explicar melhor essa última configuraçăo em breve. Antes é preciso notar que todas as configuraçőes da Listagem 12 possuem significado especial para o Boot e săo usadas para parametrizar componentes por ele gerenciados.
Além das listadas, há várias outras que podem ser verificadas no documento de referęncia do Spring Boot, assim como também podemos ter nossas próprias configuraçőes aqui, desde que năo conflitem em nomes com as reservadas. Por exemplo, supondo que o projeto airportapp precisasse de uma propriedade contendo, digamos, o caminho de dado arquivo, poderíamos utilizar algo como:
airportapp:
data-file: /tmp/data.dat
Esse mecanismo de externalizaçăo de configuraçăo năo é específico do Spring Boot, e já existe, inclusive, no próprio Spring Framework. O Boot adicionou, como diferencial, uma série de propriedades reservadas para simplificar a configuraçăo da aplicaçăo, conforme vimos.
Retornando ŕ configuraçăo de geraçăo de DDL e especificaçăo de banco de dados, entre as linhas 8 e 13, percebemos que a criaçăo do banco de dados – geraçăo de DDL – pelo Hibernate está desabilitada.
O motivo disso é que em nossa aplicaçăo, de maneira ilustrativa, usamos outra forma para a criaçăo de nosso banco e também sua carga de dados. Queremos criá-lo e populá-lo de maneira explícita através de arquivos SQL. Para isso, o projeto contém dois arquivos SQL:
A Listagem 13 mostra o conteúdo do arquivo schema-h2.sql e a Listagem 14, de forma reduzida, o de data-h2.sql.
Listagem 13. DDL de nosso banco de dados.
01 create table airport (
02 id integer not null generated always as identity (start with 1, increment by 1),
03 name varchar(256) not null,
04 city varchar(256),
05 country varchar(256) not null,
06 iatacode varchar(3),
07 icaocode varchar(4),
08 latitude double,
09 longitude double,
10 altitude double,
11 offsetutc integer,
12 dstcode char(1),
13 timezone varchar(128)
14 );
15
16 create index iata_unq on airport(iatacode);
17 create index city_idx on airport(city);
18 create index country_idx on airport(country);Listagem 14. Dados para popular nossa tabela airport.
01 insert into airport (name,city,country,iatacode,icaocode,latitude,longitude,altitude,offsetutc,dstcode,timezone) values ("Goroka","Goroka","Papua New Guinea","GKA","AYGA",-6.081689,145.391881,5282,10,"U","Pacific/Port_Moresby");
02 insert into airport (name,city,country,iatacode,icaocode,latitude,longitude,altitude,offsetutc,dstcode,timezone) values ("Madang","Madang","Papua New Guinea","MAG","AYMD",-5.207083,145.7887,20,10,"U","Pacific/Port_Moresby");E como o schema está sendo criado e os dados populados? Através do Spring JDBC, que possui uma facilidade de inicializaçăo de Datasource e o Spring Boot a habilita por default. Deste modo, sempre que houver os arquivos schema.sql e/ou data.sql na raiz do classpath, eles serăo executados pelo Boot através do Spring JDBC.
Adicionalmente, o Boot irá carregar os arquivos shema-${platform}.sql e data-${platform}.sql, se presentes, onde ${platform} corresponde ao conteúdo da propriedade:
spring.datasource.platform
ou, em YAML:
spring:
datasource:
platformNote que em nossa aplicaçăo năo fazemos uso de schema.sql nem data.sql. O intuito disso é mostrar como se utilizar da facilidade adicional do Spring Boot/Spring JDBC para carregar arquivos específicos por plataforma. Note que utilizamos em nossas propriedades o nome h2 para a plataforma.
Entretanto, poderia ser qualquer outro nome válido, como h2db, desde que os arquivos de DDL e DML estivessem nomeados como schema-h2db.sql e data-h2db.sql.
Vale ressaltar ainda que a localizaçăo desses arquivos pode mudar configurando-se as propriedades spring.datasource.schema e spring.datasource.data. Também podemos desabilitar essa facilidade com spring.datasource.initialize=false. Outra configuraçăo possível é spring.datasource.continueOnError=true, mas năo é aconselhável, pois o comportamento default é năo permitir que a aplicaçăo inicie sem a carga de dados.
É importante notar que essa facilidade na criaçăo do schema conflita com a similar do JPA/Hibernate, ddl-auto, que por default é create-drop. Por isso é preciso configurar a propriedade spring.jpa.hibernate.ddl-auto como false para evitar esse conflito.
Por outro lado, como a carga de dados é uma facilidade específica do Spring JDBC, podemos ter um cenário em que executamos o DDL pelo Hibernate e carregamos os dados pelo Spring JDBC – o que năo é o caso de nossa aplicaçăo.
No decorrer do artigo vimos que o Spring Boot é o componente da plataforma, ou ecossistema, Spring IO que objetiva simplificar, consolidar e reenergizar o Spring. A simplificaçăo deriva da visăo opinativa sobre dependęncias e autoconfiguraçăo.
Já a consolidaçăo refere-se ŕ agregaçăo coordenada de componentes, dependęncias e boas práticas sob os diversos artefatos *-starter-*.
O cumprimento desses dois objetivos pode ser averiguado quando comparamos o tamanho e simplicidade do POM de nosso projeto de exemplo com um que descreva as mesmas dependęncias sem o uso do Spring Boot.
A diferença é da grandeza de algumas dezenas de linhas para projetos simples e pequenos como esse! Mais do que essa diferença, no entanto, o que conta mesmo é a coesăo e clareza obtidas, adjetivos que tęm grande impacto no tempo de desenvolvimento e manutençăo do software.
Outro impacto, também indireto, está na qualidade do software. Năo se fala aqui exatamente de QA, testes, mas da capacidade de o desenvolvedor ater-se o máximo possível na codificaçăo do negócio, e năo da infraestrutura.
Quanto maior essa capacidade, maior a qualidade inerente do trabalho final. Por falar em testes, nosso projeto năo possui nenhum e isso de forma alguma é recomendável, mas o objetivo aqui foi de focar o uso básico e customizaçőes.
O Spring Boot também possui um *-starter-* específico para testes, o spring-boot-starter-test, que já traz os artefatos de teste do Spring Test, alguns específicos do Boot que ficam no próprio spring-boot, assim como dependęncias como o JUnit, Hamcrest e Mockito.
O último objetivo abordado, reenergizaçăo, é decorręncia natural do alcance dos dois primeiros. Há alguns anos era divertido desenvolver com o Spring Framework, e também havia muita sensaçăo de alívio para os que saíam do Java EE tradicional para um projeto com tal tecnologia.
Com o decorrer dos anos o número de componentes cresceu, os que já existiam evoluíram e, na prática, o setup de um projeto com o Spring se tornou oneroso e perdeu muito da sensaçăo de menos trabalho, menos configuraçőes. O Spring Boot, conforme vimos inclusive com o nosso projeto exemplo, responde justamente a esse desconforto, e de uma maneira elegante, simples e năo intrusiva.
O nosso projeto exemplo ilustrou como iniciar e customizar alguns aspectos do Spring Boot, mostrando que, apesar de sua visăo opinativa, ele năo apresenta obstáculos quando resolvemos sobrepor uma "opiniăo" ou outra.
Apesar de muitas facilidades interessantes, como monitoramento, uso de profiles, integraçăo com bancos de dados SQL ou NoSQL, integraçăo com outros projetos do Spring IO, como o MVC, Security, Integration, Batch e outras năo terem sido abordadas aqui pelo escopo do artigo, vale a pena dar uma olhada no documento de referęncia do Spring Boot e explorá-las!
Por último, é importante dizer que na vida real săo muito raras as oportunidades de migrar aplicaçőes legadas para o Spring, mas se vocę se deparar com uma, năo tenha dúvida: utilize o Spring Boot!
A mesma diretriz vale a novas aplicaçőes onde se decidiu utilizar o Spring. Portanto, năo perca tempo e adicione riscos a seu software gerenciando dezenas, centenas de dependęncias e arquivos de configuraçăo manualmente, quando vocę tem ŕ disposiçăo uma ferramenta como o Boot.
O Spring Boot tornou-se padrăo na construçăo de APIs RESTful e sistemas baseados em microserviços. Com o crescimento de arquiteturas baseadas em contęineres e orquestradores , destacou-se por sua facilidade de empacotamento e configuraçăo simplificada.
Com o avanço da computaçăo em nuvem, o Spring Boot adaptou-se com facilidade de integraçăo com serviços de nuvem, o suporte ao Spring Cloud e boas práticas em observabilidade.
Com a evoluçăo de versőes (2.x e 3.x), houve maior integraçăo com Spring WebFlux, Spring Data, Spring Security e Spring Native. Isso levou a um ecossistema mais modular, robusto e preparado para alto desempenho.
Spring Boot continua sendo uma excelente escolha para desenvolvimento backend em Java. Seu crescimento se manteve firme nos últimos anos graças ŕ sua adaptabilidade, produtividade e integraçăo com o ecossistema moderno de desenvolvimento (nuvem, DevOps, IA, containers). Para quem está começando, a curva de aprendizado inicial é compensada pela base sólida que o framework oferece.
Spring Boot năo é um framework de IA, mas é um excelente conector entre aplicaçőes de negócio e modelos de IA. Por meio dele podemos:
Spring Boot pode consumir qualquer modelo IA exposto como API, desta forma as principais IA disponíveis poderemos consumir seus recursos, o que permite rápida implementaçăo, reuso de modelos de última geraçăo.
Por meio desta integraçăo podemos detectar emoçőes (positivas, negativas, neutras) em textos como comentários de clientes ou redes sociais. Por exemplo:
Personalizaçăo de sugestőes com base no histórico, perfil e comportamento do usuário.
Identificar transaçőes ou eventos suspeitos em tempo real.
Extrair informaçőes de imagens e documentos năo estruturados (PDF, foto, scanner).
Criar textos automaticamente a partir de dados, contexto ou comandos (prompts).
| Benefício | Explicaçăo |
|---|---|
| Escalabilidade | Spring Boot é facilmente escalável em cloud (Kubernetes, Docker, AWS, etc.) |
| Reutilizaçăo de modelos | Integra com modelos prontos, reduzindo tempo de desenvolvimento |
| Isolamento de responsabilidades | Times de backend e IA podem trabalhar em paralelo |
| Agilidade com segurança | Spring Boot provę autenticaçăo, logs e controle de acesso com facilidade |
| Pronto para produçăo | APIs robustas e performáticas para servir modelos IA com latęncia mínima |
Referęncias:
Página
do projeto Spring IO.
http://spring.io
Documento
de referęncia do Spring Boot.
http://docs.spring.io/spring-boot/docs/current/
reference/htmlsingle
Documentaçăo
oficial do Java EE, Oracle.
http://docs.oracle.com/javaee
Página
do projeto Jetty.
http://www.eclipse.org/jetty
Página
do projeto HikariCP.
http://brettwooldridge.github.io/HikariCP
Endereço
do Sistema OpenFlights.
http://openflights.org


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.