Atualmente, boa parte dos aplicativos úteis em nossas vidas săo considerados complexos. O que muitas vezes deixamos de levar em consideraçăo a respeito deles é a complexidade da lógica de negócios com a qual estamos lidando, o que faz com que o desenvolvimento seja dificultado. Um meio que possuímos para facilitar esse desenvolvimento é através do uso do DDD – Domain-Driven Design (em traduçăo literal, Design Direcionado ao Domínio). Essa metodologia de design está presente em várias aplicaçőes desenvolvidas atualmente e, como o nome sugere, diz respeito ŕ prepararmos uma aplicaçăo direcionando-nos ao domínio de negócios da mesma.
Esse artigo visa entender o funcionamento do DDD utilizando o .NET Framework. Veremos que o DDD utiliza alguns padrőes de design para as aplicaçőes, e que eles săo muito úteis na prática. Entretanto, a grande sacada dessa metodologia é a capacidade que ele traz para a modelagem do problema, através do entendimento do mesmo. Ao longo do artigo, traremos uma introduçăo ao DDD e alguns padrőes comuns no desenvolvimento de aplicaçőes com essa metodologia, como os padrőes Domain Model e Repository.
O DDD ao qual nos referimos năo tem absolutamente nada a ver com o código de área que discamos quando precisamos fazer uma ligaçăo de longa distância. Dentro do desenvolvimento de software, o DDD é o Domain-Driven Design, e trata-se de uma sigla muito comum no meio. Trata-se de uma metodologia de design de software que tem um foco no que está acontecendo no domínio da aplicaçăo. Em outras palavras, e como o nome sugere, o design é centrado na lógica de negócios (domínio) do software.
A ideia básica do DDD está centrada no conhecimento do problema para o qual o software foi proposto. Na prática, trata-se de uma coleçăo de padrőes e princípios de design que buscam auxiliar o desenvolvedor na tarefa de construir aplicaçőes que reflitam um entendimento do negócio. É a construçăo do software a partir da modelagem do domínio real como classes de domínio que, por sua vez, possuirăo relacionamentos entre elas.
Essa modelagem de domínio encaixa-se perfeitamente no que conhecemos de bancos de dados relacionais e, mais recentemente, de ORM’s (Mapeadores Objeto-Relacionais). Ou seja: o domínio criado utilizando o DDD será uma modelagem bastante simples dos dados que serăo armazenados pela aplicaçăo em sua base de dados. Esse modelo, entretanto, necessita de mais alguns detalhes para funcionar corretamente, e é isso que veremos a seguir.
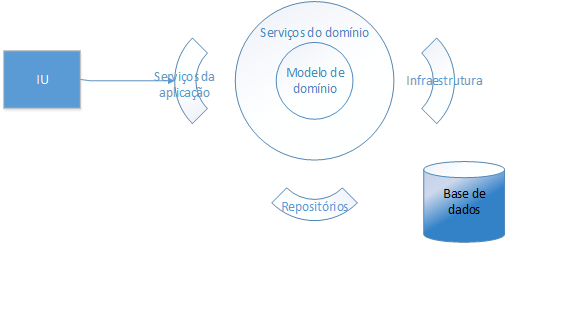
Uma abordagem muito comum no DDD é a separaçăo em camadas. Essa separaçăo é uma realidade no desenvolvimento de software há algum tempo, mas que só recentemente foi levada a sério, com o aumento da complexidade das aplicaçőes. Relacionando-a especificamente ao DDD, é um conceito que auxilia muito na separaçăo dos problemas, necessária no desenvolvimento DDD. A Figura 1 mostra a separaçăo em camadas comum no DDD.
Ela traz uma separaçăo dos problemas, algo muito comum no DDD. Esses conceitos encaixam-se em elementos diferentes da aplicaçăo, e por isso săo separados dessa forma. Entretanto, é importante ressaltarmos que o DDD năo é simplesmente a forma como definimos nosso software: é como preparamos o desenvolvimento como um todo, de uma forma mais ampla. Em outras palavras, o DDD é sobre como pensamos a respeito do software, e năo como ele está estruturado.
A Figura 1 trouxe algumas camadas comuns em aplicaçőes DDD. Como o espaço disponível aqui năo é suficiente para uma análise em detalhes a respeito do assunto, vamos trazer alguns desses elementos, apenas. Esses elementos estăo listados a seguir:
Os tręs elementos listados acima săo essenciais no desenvolvimento utilizando DDD. Os demais também o săo, mas o nível de importância desses tręs, no que diz respeito ao domínio da aplicaçăo, é maior, e por isso nosso foco estará neles, em especial o Modelo de Domínio e os Repositórios. Na sequęncia, veremos como esses elementos interagem na prática.
O padrăo Domain Model é, como o nome sugere, um modelo do domínio de nossa aplicaçăo. Como tal, ele é o responsável pela modelagem das classes de domínio de acordo com o que a realidade nos apresenta. Isso faz com que se trate de um dos elementos mais importantes dentro da aplicaçăo, uma vez que todas as operaçőes envolverăo, de uma forma ou outra, o domínio. Vamos começar analisando as classes desse domínio.
As classes do modelo de domínio săo chamadas de entidades. Essas entidades, por sua vez, possuem relacionamentos com outras entidades. É extremamente importante que as entidades e seus relacionamentos tenham um paralelo na realidade, pois assim será muito mais fácil para o desenvolvedor entender e replicar a lógica do negócio, contendo todos os processos de validaçăo e regras.
As entidades presentes no Domain Model năo possuem nenhum conhecimento de como fazer com que seus dados sejam persistentes. A persistęncia de dados é um conceito importante em uma aplicaçăo, uma vez que evita que haja perda destes, ou seja, faz com que os dados sejam armazenados em algum lugar. Logo, essas entidades săo consideradas dentro dos princípios POCO e PI, já mencionados. Outro ponto importante a respeito do modelo de domínio é que năo há, necessariamente, uma correspondęncia entre o modelo de dados (que representa a base de dados) e as entidades do modelo de negócios (Domain Model).
Com esses conceitos, surge uma questăo importante: como faremos a persistęncia dos dados do modelo de domínio? Normalmente é utilizado o padrăo Repository, que veremos em detalhes a seguir. Sucintamente, esse padrăo é responsável pelo mapeamento da entidade do modelo de domínio para a entidade associada no modelo de dados.
Antes de lidarmos com o padrăo Repository, precisamos criar um modelo de negócios. Estaremos utilizando o padrăo Domain Model, de modo que o leitor possa entender como é simples, uma vez que conhecemos o negócio, defini-lo.
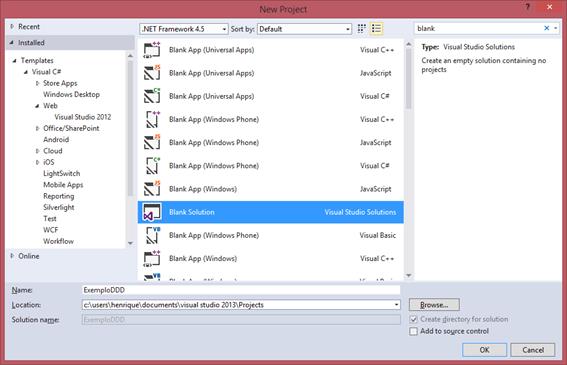
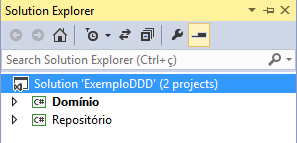
Vamos começar criando uma soluçăo vazia no Visual Studio, como mostra a Figura 2. Essa soluçăo vazia conterá dois projetos, apenas. Vale ressaltar que, em projetos reais, maiores, normalmente haverá mais projetos, cada um representando uma camada. Aqui, teremos apenas as camadas de Domínio (Domain Model) e Repositório (padrăo Repository) representadas. Vamos criar, portanto, esses dois projetos. Ambos săo do tipo “Class Library”. A estrutura da soluçăo após a criaçăo desses projetos está mostrada na Figura 3.
Nesse momento possuímos apenas dois projetos, sendo ambos do tipo “Class Library”, ou Biblioteca de Classes. Na Figura 3 podemos notar que o primeiro deles (Domínio) está definido como o projeto inicial, a ser executado no momento do build. Entretanto, se tentarmos realizar essa execuçăo, haverá um erro. Isso ocorre porque projetos do tipo “Class Library” năo podem ser executados, somente compilados. Portanto, se desejarmos utilizar essas bibliotecas, precisaríamos de um projeto diferente, web ou desktop, que permitisse a utilizaçăo dos mesmos. Năo criaremos esse projeto nesse exemplo, uma vez que estamos interessados em destrinchar o padrăo Domain Model, inicialmente, e năo em mostrar o funcionamento de uma aplicaçăo qualquer. Esse projeto seria o equivalente ŕ camada IU, mostrada na Figura 1. As demais camadas apresentadas nessa figura também serăo omitidas nesse exemplo.
Outro ponto digno de nota é referente aos relacionamentos entre as camadas. Como queremos manter a camada de domínio (projeto Domínio) livre de qualquer questăo de infraestrutura, ela năo receberá qualquer referęncia das outras camadas.
Agora que entendemos a estrutura do projeto, podemos começar a definir o mesmo. Nosso modelo de negócios possui duas classes: Categoria e Produto. Cada categoria pode possuir vários produtos, enquanto um produto somente possuirá uma categoria. Esse relacionamento é bastante simples e serve a nosso propósito. As classes de domínio estăo criadas, como mostram as Listagens 1 e 2.
namespace Domínio
{
public class Categoria
{
// Propriedades
public int Id_Categoria { get; set; }
public string Nome { get; set; }
public string Descricao { get; set; }
public IList<Produto> Produtos { get; set; }
}
}
namespace Domínio
{
public class Produto
{
// Propriedades
public int Id_Produto { get; set; }
public string Nome { get; set; }
public string Descricao { get; set; }
public decimal Preco { get; set; }
public int Quantidade { get; set; }
public int Categoria { get; set; }
// Métodos
public bool PodeVender()
{
return Quantidade > 0;
}
public void Vendeu()
{
if (PodeVender())
Quantidade--;
}
public void Comprou(int qtde)
{
Quantidade += qtde;
}
}
}A classe Categoria possui a referęncia a todos os produtos contidos na determinada categoria. Isso é condizente com o relacionamento que as classes de domínio possuem. No mais, apenas representaçőes simples das informaçőes necessárias ao armazenamento de cada categoria.
Já a classe Produto é mais complexa, pois o padrăo Domain Model insiste que adicionemos comportamento para nossas classes de domínio. Enquanto Categoria năo possuía nenhum comportamento (a exceçăo dos getters e setters), Produto os possui. Além dos detalhes normais de representaçăo dos dados, bem como a referęncia ŕ Categoria a qual o produto está vinculado, temos os métodos PodeVender(), Vendeu() e Comprou(), que referem-se ŕ quantidade de produtos disponível para venda. Nesse caso, estamos verificando se os produtos estăo disponíveis para venda, vendendo e comprando, respectivamente.
Quando lidamos com o mapeamento objeto-relacional em nossos projetos, é comum que tenhamos classes de domínio sem qualquer definiçăo de comportamento. Isso faz com que năo estejamos lidando mais com o padrăo Domain Model, e sim com uma variaçăo dele: o Anemic Domain Model, que significa, em uma traduçăo literal, Modelo de Domínio Anęmico. Nesse caso, é preciso que tenhamos classes de serviço responsáveis pela definiçăo dos comportamentos das classes de domínio. Ambos podem ser utilizados com o DDD, embora seja mais comum vermos a utilizaçăo do Domain Model.
Com isso, temos nosso modelo de domínio definido. Entretanto, năo há nenhuma persistęncia de dados, até o momento. Por isso, iremos utilizar o padrăo Repository para adicionar essa persistęncia e permitirmos o acesso a alguma base de dados em nossa aplicaçăo.
O fato de que o Domain Model năo fornece persistęncia aos dados de nossa aplicaçăo poderia ser um problema, năo fosse a existęncia do padrăo Repository. Os dois padrőes costumam ser utilizados em conjunto pelo simples fato de que eles se complementam. O primeiro cria o modelo de domínio sem a menor preocupaçăo a respeito de como os dados serăo armazenados e o último toma conta dessa ponte entre o modelo de domínio e a base de dados.
Como podemos ver, a ideia é extremamente simples. Entretanto, a forma como os repositórios de dados será implementada é muito dependente do banco de dados que estamos utilizando. Além disso, também há diferenças para casos em que utilizamos ferramentas de ORM (Object-Relational Mapping – Mapeamento Objeto-Relacional), como o Entity Framework, o LINQ to SQL ou o NHibernate. A ideia básica é que o repositório precisa estar adaptado ŕ essa estrutura.
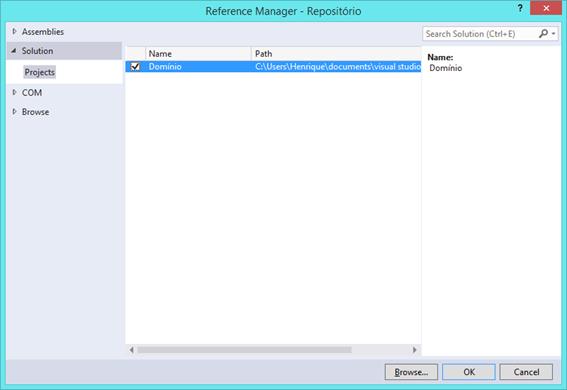
A ideia básica é que, para cada classe de domínio, tenhamos um repositório de dados. Para o exemplo que estamos criando, teríamos um repositório de Produto e outro de Categoria. Vamos criar esses dois elementos em nosso projeto a seguir. Primeiramente, porém, precisamos realizar a importaçăo das classes de domínio em nosso projeto Repositório (que representa a camada Repositórios da Figura 1). Para isso, basta clicar com o botăo direito nas referęncias do projeto Repositório e adicionar o projeto Domínio, como mostra a Figura 4.
Com isso, podemos começar a criaçăo de nosso repositório propriamente dito. O padrăo Repository funciona, comumente, através de interfaces. Essas interfaces visam criar uma abstraçăo do repositório em si, apenas para representar as operaçőes que serăo feitas nos dados, sem considerar o banco de dados utilizado. Logo, uma mesma interface IProdutoRepository, por exemplo, tem a mesma assinatura para um banco de dados SQL Server ou PostgreSQL.
Vamos criar as interfaces para os repositórios de dados, portanto. Elas estăo mostradas nas Listagens 3 e 4. Repare que a nomenclatura utilizada começa com a letra “I”, para indicar que se trata de uma interface, e termina com o sufixo “Repository”. Essa nomenclatura é uma convençăo quando utilizamos o padrăo Repository. Os métodos assinados nas interfaces săo similares para ambos os repositórios, com a diferença do tipo de dados: Categoria e Produto, respectivamente. A ideia é que tenhamos métodos para adicionar, salvar e buscar os dados na base, uma vez que o repositório concreto esteja criado.
namespace Repositório
{
public interface ICategoriaRepository
{
void Adicionar(Categoria categoria);
void Salvar(Categoria categoria);
IEnumerable<Categoria> ListarTodos();
Categoria BuscarPor(int idCategoria);
}
}namespace Repositório
{
public interface IProdutoRepository
{
void Adicionar(Produto produto);
void Salvar(Produto produto);
IEnumerable<Produto> ListarTodos();
Produto BuscarPor(int idProduto);
}
}Com isso temos a base para nosso repositório de dados. O repositório concreto irá variar de acordo com a tecnologia utilizada, por isso năo adicionaremos o mesmo ao nosso exemplo. A ideia é que tenhamos a possibilidade de escolher entre diversas tecnologias e entăo implementar essa interface que definimos agora para fazer com que ela tenha acesso aos dados reais. A Listagem 5 traz um exemplo de como ficaria um repositório concreto para a classe Produto, caso estivéssemos utilizando o Entity Framework. Aqui, vale ressaltar que o EF utiliza um DataContext para acesso aos dados, derivado da classe DbContext. Nesse caso, trata-se da classe DbDataContext. Outros ORM’s fazem uso de soluçőes similares, como o NHibernate com a interface ISession e o LINQ to SQL com a classe DataContext. É essa classe de contexto que contém os elementos da base de dados em si, normalmente da classe DbSet.
public class ProdutoRepository : IProdutoRepository
{
private DbDataContext _context = new DbDataContext();
public ProdutoRepository(DbDataContext context)
{
_context = context;
}
public IEnumerable<Produto> Produtos
{
get { return _context.Produtos; }
}
public void Salvar(Produto prod)
{
if (prod.Id_Produto == 0)
{
_context.Produtos.Add(prod);
}
else
{
Produto dado = _context.Produtos.Find(prod.Id_Produto);
if (dado != null)
{
dado.Nome = prod.Nome;
dado.Descricao = prod.Descricao;
dado.Preco = prod.Preco;
dado.Quantidade = prod.Quantidade;
dado.Categoria = prod.Categoria;
}
}
}
void Adicionar(Produto produto)
{...}
IEnumerable<Produto> ListarTodos()
{...}
Produto BuscarPor(int idProduto)
{...}
}Quando utilizamos o Entity Framework, normalmente haveria alguma alteraçăo nas classes de domínio. O EF utiliza o conceito de propriedades virtuais, representando aquelas que năo existem na base de dados. Assim, a classe Produto possuiria uma propriedade virtual do tipo Categoria (representando a categoria ŕ qual ele pertence) e a lista de Produtos da classe Categoria seria virtual.
Como foi possível vermos ao longo do artigo, Domain-Driven Design é uma coleçăo de padrőes e princípios que permitem que o desenvolvedor faça o design de uma aplicaçăo de lógica de negócios complexa com mais facilidade. Foi possível notarmos que a utilizaçăo do padrăo Domain Model, em conjunto com o padrăo Repository, é uma excelente opçăo para o desenvolvimento de aplicaçőes com essa metodologia, fazendo com que o domínio real da aplicaçăo seja mais facilmente entendido.
Podemos aproveitar esse momento para fazer uma breve comparaçăo entre o DDD e outras duas metodologias de design muito utilizadas: o TDD – Test-Driven Development – e o BDD – Behaviour-Driven Design. O primeiro diz respeito a permitir que os testes controlem o sistema; na prática, significa escrever os testes, inicialmente, e só entăo escrever o código que irá passar naqueles testes. Já o BDD é considerado uma uniăo entre o TDD e o DDD; ele foca no comportamento do sistema (behaviour), utilizando uma linguagem que beneficia tanto desenvolvedores como usuários. Logo, podemos notar que há diferenças entre as tręs metodologias, e a escolha de qual delas devemos utilizar depende muito do sistema sendo desenvolvido.

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.