Apesar do paradigma orientado a objetos estar sendo cada vez mais difundido no processo de desenvolvimento de software, năo existem hoje soluçőes comerciais robustas e amplamente aceitas neste paradigma para a persistęncia de dados. Mercado este dominado pelos bancos de dados relacionais. Neste contexto, o mapeamento do modelo orientado a objetos para o relacional é uma necessidade cada vez mais importante no processo de desenvolvimento.
Embora o uso de frameworks de persistęncia seja comum, é fundamental o entendimento das técnicas de mapeamento objeto relacional. Isso facilitará tanto o uso dos frameworks como também uma análise mais criteriosa dos mapeamentos realizados de forma automática caso seja necessário algum ajuste no código implementado.
A abordagem relacional está baseada no princípio de que as informaçőes em uma base de dados podem ser consideradas relaçőes matemáticas e que estăo representadas de maneira uniforme com o uso de tabelas bidimensionais.
Ao se fazer a análise para o desenvolvimento de uma aplicaçăo, é muito importante saber se os tipos de dados a serem armazenados săo tipos simples, tais como strings e números. Se este for o caso, é mais indicada a utilizaçăo de SGBDs relacionais.
Saiba mais: Entity Framework: Como fazer seu primeiro Mapeamento Objeto-Relacional
Os SGBDs relacionais possuem uma característica muito importante: săo extremamente confiáveis e mais eficientes, se comparados ŕ maioria dos SGBDs orientados a objetos disponíveis no mercado. Além disso, o modelo de dados relacional foi criado para permitir a representaçăo de uma grande variedade de problemas usando um pequeno conjunto de conceitos simples.
Através da linguagem de consulta SQL (Structured Query Language) é possível fazer a busca e recuperaçăo dos dados necessários de forma bastante eficiente.
Dentre as vantagens do modelo relacional, talvez a mais importante esteja relacionada com a persistęncia dos dados. As regras e rotinas para tratamento da persistęncia dos dados podem ser criadas no próprio banco de dados relacional.
Uma das grandes desvantagens do modelo relacional pode ser observada no momento da realizaçăo da análise de um sistema a ser implementado: a grande dificuldade em abstrair a realidade, ou seja, traduzir para um modelo de tabelas, com suas relaçőes entre si, suas chaves primárias e estrangeiras, um problema do mundo real.
O modelo de dados orientado a objetos é uma extensăo do paradigma orientado a objetos, possuindo basicamente os mesmos conceitos. O paradigma orientado a objetos se baseia na construçăo de aplicaçőes a partir de objetos abstraídos da realidade, com dados e comportamento associados. Esses objetos possuem atributos (propriedades que contém valores que descrevem o objeto) e métodos (especificaçőes de comportamentos dos objetos).
Além disso, o modelo Orientado a Objetos possui outras características importantes, dentre as quais se pode destacar as mostradas na Tabela 1. Já na Tabela 2 podem ser observadas as principais características de um objeto.
| Conceito | Descriçăo |
|---|---|
| Encapsulamento | Os valores dos atributos e os detalhes da implementaçăo dos métodos estăo escondidos de outros objetos. Em banco de dados se diz que um objeto está encapsulado quando o estado é oculto ao usuário e o objeto pode ser consultado e modificado exclusivamente por meio das operaçőes a ele associadas. |
| Mensagens | Meio de comunicaçăo entre objetos. Troca de mensagens significa chamar um método do objeto. |
| Herança | Relacionamento entre classes numa hierarquia. É a capacidade de criaçăo de uma nova classe a partir de outra existente. Quando uma classe herda características de mais de uma classe, diz-se que houve herança múltipla. As principais vantagens de herança săo prover uma maior expressividade na modelagem dos dados, facilitar a reusabilidade de objetos e definir classes por refinamento, podendo fatorar especificaçőes e implementaçőes como na adaptaçăo de métodos gerais para casos particulares. |
| Polimorfismo | Capacidade de existir diferentes implementaçőes para métodos com a mesma assinatura em diferentes classes da mesma hierarquia de herança. Em sistemas polimórficos, uma mesma operaçăo pode se comportar de diferentes formas em classes distintas. |
| Característica | Descriçăo |
| Estado | Indica como se encontram as informaçőes encapsuladas pelo objeto. |
| Comportamento | Define o modo que um objeto age e reage em termos das suas mudanças de estado. |
| Identidade | É a propriedade que distingue um objeto de outro. Cada objeto possui uma identidade única. |
No modelo Orientado a Objetos, a abstraçăo da realidade é mais simplificada, pois um objeto nada mais é do que uma abstraçăo direta da realidade. Por exemplo: um computador tem teclado, cpu e mouse. O teclado é um objeto, a cpu é outro objeto e o mouse também é um objeto.
Outra grande vantagem deste modelo é a questăo da reutilizaçăo. Um objeto pode ser facilmente reutilizado no mesmo programa ou até mesmo em programas diferentes.
Saiba mais: Curso Lógica de Programaçăo
O modelo orientado a objetos foi projetado para a criaçăo e representaçăo de estruturas complexas de uma maneira coerente e uniforme. Isto representa uma grande vantagem em relaçăo ao modelo de dados relacional, que foi criado sem se preocupar com o armazenamento de estruturas mais complexas. Outro ponto a favor do modelo orientado a objetos é a facilidade em expressar relaçőes complexas entre objetos.
O paradigma orientado a objetos apresenta um problema: os bancos de dados atuais năo oferecem uma boa aderęncia aos princípios da orientaçăo a objetos. Isto é, em termos de armazenamento, os bancos de dados orientados a objetos năo conseguiram ainda substituir a tecnologia comprovadamente eficiente dos bancos de dados relacionais.
Em funçăo disso, os administradores e desenvolvedores de bancos de dados acabam ficando em uma situaçăo difícil, pois mesmo querendo adotar a orientaçăo a objetos, eles tęm que parar na hora de manipular seus dados. Até mesmo linguagens de programaçăo orientadas a objetos, como Java, acessam os bancos de dados de maneira convencional e utilizando SQL. Com isso, um mesmo programa acaba tendo uma parte orientada a objetos e outra parte estruturada, fazendo com que as características da orientaçăo a objetos năo possam ser exploradas na sua plenitude.
Devido a isso, o que está ocorrendo nos dias de hoje é que o desenvolvimento é orientado a objetos, mas o banco de dados é relacional ou objeto-relacional. No modelo orientado a objetos, a implementaçăo acaba se tornando mais complicada do que no modelo relacional, pois as estruturas de dados usadas no banco e as usadas na programaçăo podem ser completamente diferentes. Isso reforça a necessidade da criaçăo de uma camada de persistęncia, fazendo com que se gaste um bom tempo do desenvolvimento para mapear as estruturas da programaçăo em estruturas do banco de dados.
Os bancos de dados orientados a objetos podem ser divididos em dois grupos:
As principais características dos Bancos de Dados Puramente Orientados a Objetos săo:
Saiba mais: Cursos de Engenharia de Software
Os BDPOO tendem a seguir um padrăo estabelecido pelo ODMG (Object Database Management Group). A última versăo disponibilizada pelo ODMG é a versăo 3.0, que pode ser obtida em no Operational Database Management Systems.
Com relaçăo aos Bancos de Dados Objeto-Relacionais, pode-se dizer que as principais características săo:
Dentre as principais vantagens dos BDOR, pode-se citar que todo o suporte para ao paradigma orientado a objetos está presente. Além disso, já existe um padrăo de implementaçăo estabelecido, determinando uma certa facilidade de convivęncia com os sistemas já existentes.
Na Tabela 3 podem ser observados alguns dos principais BDOR disponíveis no mercado.
| Fabricante | Descriçăo |
|---|---|
| IBM | Informix e DB2 |
| Oracle Corporation | Oracle 9i |
| PostgreSQL Global Development Group | PostgreSQL |
| Micro Database System, Inc. | TITANIUM |
| Intersystems | Caché |
Em termos conceituais, uma Camada de Persistęncia de Objetos é uma biblioteca que permite a realizaçăo do processo de persistęncia (isto é, o armazenamento e manutençăo do estado dos objetos em algum meio năo-volátil, como um banco de dados) de forma transparente.
Dentre as diversas vantagens obtidas com a utilizaçăo da Camada de Persistęncia, pode-se destacar o fato do analista/programador poder trabalhar como se estivesse em um sistema completamente orientado a objetos. Outra vantagem muito importante é que os acessos realizados diretamente ao banco de dados da aplicaçăo săo isolados, e os processos de construçăo de consultas e operaçőes de manipulaçăo de dados săo centralizados em uma camada de objetos inacessível ao programador. Esse encapsulamento torna as aplicaçőes mais confiáveis, permitindo até mesmo que o próprio SGBD ou a estrutura de suas tabelas possam ser alterados sem a necessidade de revisar e recompilar os programas.
Apesar disso, o modelo de classes de um projeto orientado a objetos năo pode simplesmente ser traduzido em um script SQL de criaçăo de banco de dados, é necessário realizar o mapeamento de objetos em um modelo de dados Entidade-Relacionamento.
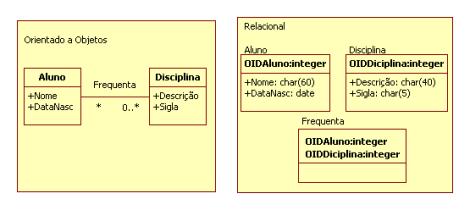
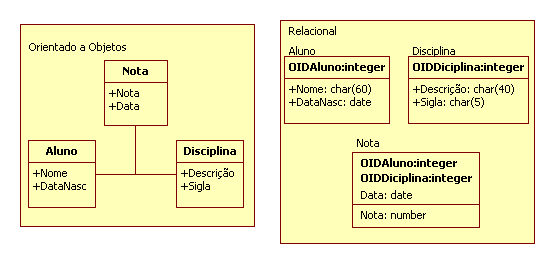
Para garantir que todas as características do modelo de objetos sejam reproduzidas fielmente pelo banco de dados relacional, alguns aspectos merecem ser destacados. Os objetos formam unidades que encapsulam atributos e operaçőes. Os bancos de dados relacionais representam de forma bastante eficiente os atributos, mas săo limitados na representaçăo das operaçőes. Pode-se tentar estabelecer uma analogia entre objetos e tabelas, e entre atributos e colunas.
Para mapear um objeto em uma tabela relacional, geralmente os atributos desse objeto săo representados através de colunas na tabela. Entretanto, essa năo é uma regra que pode ser seguida ao pé da letra, pois existem outras consideraçőes a serem feitas (tipos dos dados, tamanho dos campos, entre outras). Tais consideraçőes podem fazer com que um atributo seja mapeado em várias colunas, ou entăo que vários atributos sejam mapeados em apenas uma coluna.
Ao se realizar uma transposiçăo de um modelo orientado a objetos para um modelo relacional, algumas regras devem ser seguidas (vale destacar aqui que essas regras năo săo rígidas):
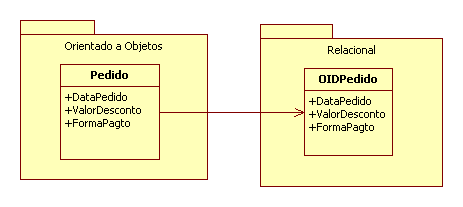
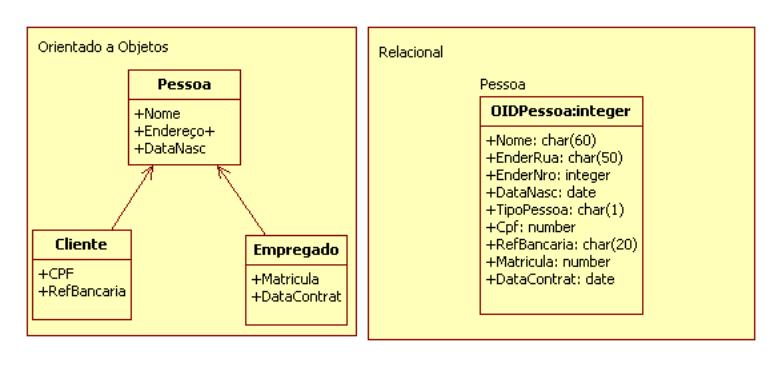
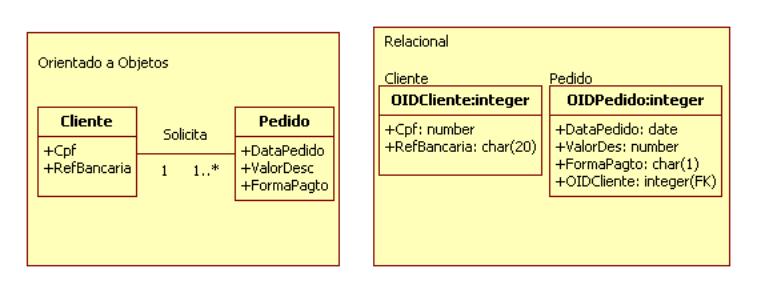
Para fazer essa implementaçăo no modelo relacional, deve ser criado um atributo OID para cada tabela. Na Figura 1 é mostrado um exemplo de como seria o mapeamento do objeto Pedido para a tabela Pedido.
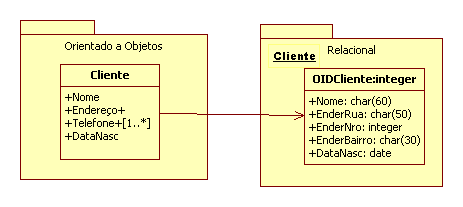
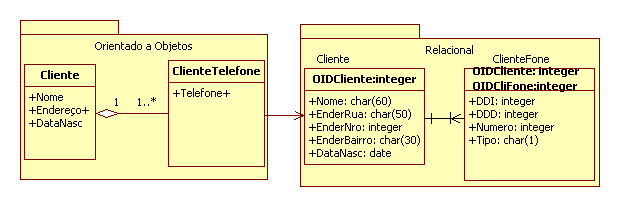
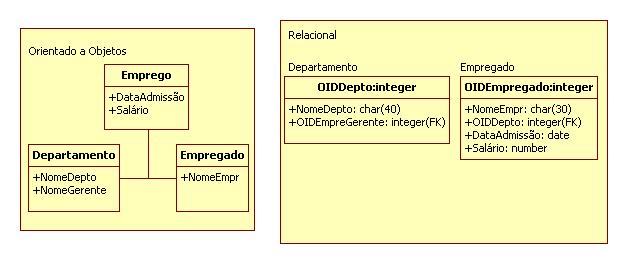
Na Figura 2 pode ser observado um exemplo de mapeamento de um atributo simples (Nome e DtNascimento) e de um atributo composto (Endereco). Já na Figura 3 pode ser observado um exemplo de mapeamento de um atributo multivalorado (Telefone).
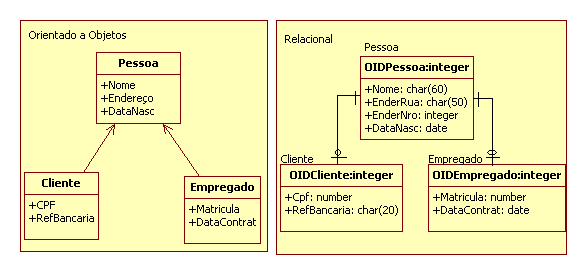
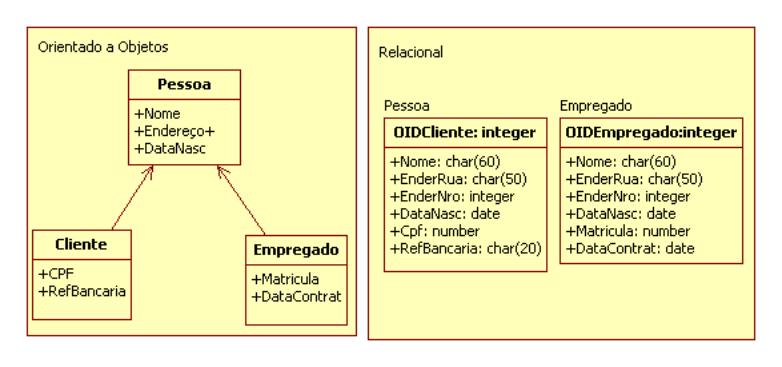
Na técnica de criaçăo de uma tabela para cada classe (Figura 4), os atributos da tabela săo os atributos específicos da classe e mais uma coluna de chave estrangeira que referencia a chave primária da tabela pai. As desvantagens do uso dessa técnica é que săo geradas muitas tabelas no banco de dados, fazendo com que haja uma demora maior para ler e gravar os dados. Por esse mesmo motivo, algumas consultas acabam sendo bastante dificultadas, obrigando a criaçăo de views para agilizar o processo.
Se for utilizada a segunda forma (Figura 5), a classe raiz é tomada por base, pois é nela que todos os atributos săo armazenados. Essa técnica facilita as consultas, pois os dados de um objeto estăo em uma única tabela O principal problema é que, potencialmente, há um desperdício de espaço no banco de dados. Além disso, a performance pode ser prejudicada.
Caso se opte por criar uma tabela para cada classe concreta (Figura 6), deve-se incluir em cada tabela tanto os atributos específicos, quanto os atributos herdados da classe que ela representa. Como os dados de uma classe ficam todos em uma única tabela, as consultas săo facilitadas.
Se for escolhida a primeira opçăo, os atributos da classe agregada devem ser colocados na mesma tabela da classe agregadora. Nessa técnica, a performance é melhor, pois é preciso acessar uma única tabela. Além disso, o objeto agregado é automaticamente excluído quando o objeto agregador é eliminado, năo havendo a necessidade da implementaçăo de triggers ou rotinas especiais na aplicaçăo para garantir a consistęncia do banco de dados. A grande desvantagem dessa técnica é que a incorporaçăo dos atributos aumenta a quantidade de páginas que săo recuperadas em cada acesso ŕ tabela.
No caso da opçăo ser pela geraçăo de duas tabelas, uma delas deve herdar como um atributo normal (chave estrangeira) a chave primária da outra tabela. Essa técnica facilita a manutençăo das tabelas e torna a estrutura do banco de dados mais flexível. Porém, as consultas necessitam de uma operaçăo de junçăo (join) ou pelo menos dois acessos ao banco de dados. Se o acesso aos dados de ambas as tabelas năo for muito freqüente, esta alternativa é aceitável, caso contrário, essa alternativa pode năo ser a mais adequada. Outra desvantagem de gerar uma tabela para cada classe é que para manter a consistęncia do banco de dados entre essas tabelas, por ocasiăo de operaçőes de exclusăo de objetos, é necessário implementar triggers ou rotinas especiais na aplicaçăo.
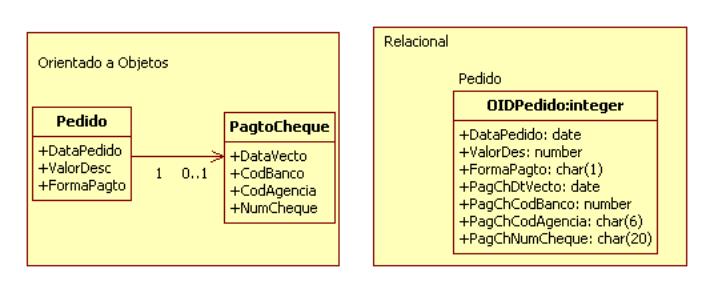
Na Figura 11 pode ser observado um exemplo da utilizaçăo da técnica de geraçăo de uma única tabela, com a utilizaçăo de um prefixo para distinguir os atributos (PagCh). Os objetos Pedido e Pagto em cheque săo transpostos na tabela Pedido. Já na Figura 12 é demonstrada a utilizaçăo da segunda técnica (geraçăo de duas tabelas), onde os objetos Pedido e Pagto em cheque săo transpostos nas tabelas Pagamento e PagamentoCheque.
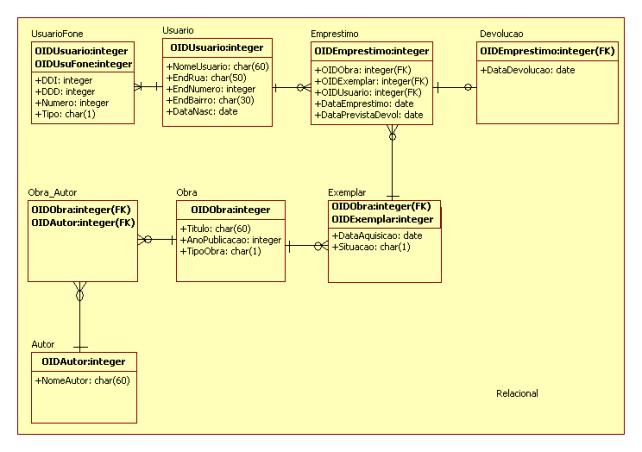
A Figura 13 mostra como seria o mapeamento de um sistema simplificado de controle de uma biblioteca. Através deste exemplo, pode-se observar a aplicaçăo de algumas das regras explicadas na seçăo anterior. É importante lembrar que as regras descritas admitem uma certa variaçăo, năo sendo totalmente rígidas.
Nos casos onde se faz necessário realizar o mapeamento de um modelo orientado a objetos para um modelo relacional, mais do que qualquer outro fator, o mais importante é realizar uma análise criteriosa, analisando cada caso individualmente. O fundamento dessa análise deve estar baseado nas regras de mapeamento existentes, porém, como todas as regras, sempre existem exceçőes que precisam ser analisadas com cuidado.
As regras de mapeamento já adquiriram certa maturidade, uma vez que vęm sendo propostas e aperfeiçoadas há vários anos. Alguns autores definem as regras de forma bastante genérica, enquanto outros especificam detalhadamente cada regra, preocupando-se com as possíveis exceçőes e até mesmo subdividindo algumas regras. Porém, todos săo unânimes em afirmar que uma boa análise individual sobre cada caso, verificando os objetos individualmente e como um todo, é muito importante. Até mesmo quando săo utilizadas ferramentas que fazem o mapeamento de forma automática, deve-se analisar o modelo obtido para verificar como ficaram as tabelas, pois pode haver exceçőes que precisam ser tratadas de forma manual.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.