Business Intelligence se refere ao conjunto de conceitos, métodos e recursos tecnológicos que habilitam a obtençăo e distribuiçăo de informaçőes geradas a partir de dados operacionais e históricos, visando proporcionar subsídios a tomada de decisőes gerenciais.
Uma característica fundamental de um processo de BI é que nele os dados săo copiados da base de dados transacional e de outras fontes, para a base de dados analítica, o que permite que as informaçőes sejam extraídas desta última sem que a performance do sistema transacional seja prejudicada e da forma mais eficiente, eficaz e visualmente agradável possível, sempre focada na tomada de decisăo.
Os dados podem, na sua origem, estar estruturados ou năo, ou seja, podem vir de um sistema de informaçăo com dados organizados e corretamente normalizados em tabelas e colunas, e podem ainda serem extraídos de sites da internet como texto puro, áudio, vídeo ou outros formatos. Apesar disso, em ambas as situaçőes eles devem ser tratados e gravados em um formato que facilite a extraçăo de informaçőes e apoie as decisőes dos gestores.
Neste artigo serăo apresentadas as técnicas básicas envolvidas na criaçăo de um data warehouse, na modelagem da base multidimensional, no processo de ETL, na modelagem e publicaçăo da parte lógica do cubo (metadados) e, por fim, na visualizaçăo dos dados em uma ferramenta OLAP.
Ao longo da década de 90 vivemos a descoberta da internet, ocasiăo em que a rede mundial de computadores revelou-se um ótimo mercado, surgindo a partir daí o e-commerce, os portais de notícias, de músicas e, o que vem revolucionado o mundo, as redes sociais.
Concomitante ŕ corrida pela visibilidade na internet, com o custo do hardware cada vez menor, as empresas investiram em seus sistemas de informaçăo, que se tornaram imprescindíveis. Desde panificadoras até a montagem robotizada de veículos automotivos, todos necessitam de um software especializado para gerir as etapas de seus processos.
Entretanto, seja pela dificuldade enfrentada pelas empresas em criar software sob medida para suas necessidades, seja pela complexidade envolvida em manter uma equipe interna de TIC (Tecnologia da Informaçăo e Comunicaçăo), seja pelos custos elevados da terceirizaçăo desse desenvolvimento, a maioria adquire vários produtos de terceiros para gerir diversas áreas da empresa como o RH, Financeiro, Gestăo de Projetos, Gestăo de Clientes, Ensino ŕ Distância, entre outros, o que acarreta em dados redundantes, descentralizados e em Sistemas Gerenciadores de Bancos de Dados Relacionais (SGBDRs) distintos, ao invés de serem armazenados em uma única base de dados, corporativa, normalizada e íntegra.
Diante da situaçăo criada pela descentralizaçăo e heterogeneidade dos dados, o grande desafio do momento é integrá-los, interpretá-los e transformá-los, de alguma forma, em informaçăo relevante ao seu negócio, possibilitando, com a devida análise, a criaçăo de conhecimento.
O conhecimento pode, muitas vezes, ser o diferencial de uma empresa, pois possibilita ressaltar os seus pontos fortes e mitigar os riscos envolvidos nos pontos fracos. Tendo um retrato fiel da realidade, uma empresa consegue, em muitos casos, com base nos dados históricos, fazer uma previsăo bastante assertiva do futuro e utilizá-la como embasamento para suas decisőes.
Com base nisso, nesta primeira parte da série serăo considerados os conceitos mais relevantes da Business Intelligence (BI), seguidos da apresentaçăo da suíte Pentaho, capaz de contemplar no case proposto, todos os requisitos e regras de negócio elencados por uma empresa fictícia, com diversas filiais. Analisando a base origem e levando em conta os requisitos e regras de negócio, será descrito o raciocínio necessário para a modelagem da base destino, em formato estrela. Por fim, dando início ao tutorial propriamente dito, tem-se o passo a passo para a instalaçăo e configuraçăo do Pentaho Data Integration.
O termo Business Intelligence provoca arrepios em muita gente. Atualmente, afirma-se que as grandes vendedoras de soluçőes proprietárias e seus especialistas pintam um “bicho de sete cabeças” para justificar as altas cifras envolvidas. Esta é uma atividade altamente especializada e exige, em suas diversas etapas, profissionais treinados com uma gama muito grande de conhecimentos. Entretanto, o processo de BI propriamente dito é bastante simples.
Em 1992, o Gartner Group definiu Business Intelligence como o “conjunto de conceitos, métodos e recursos tecnológicos que habilitam a obtençăo e distribuiçăo de informaçőes geradas a partir de dados operacionais e históricos, visando proporcionar subsídios a tomada de decisőes gerenciais”. O termo pode ser traduzido como inteligęncia empresarial ou inteligęncia de negócios.
O Gartner é uma empresa de consultoria fundada em 1979, por Gideon Gartner, com sede nos Estados Unidos, em Stamford, Connecticut. Atualmente conta com 5.300 associados, incluindo 1.280 consultores e analistas. Referęncia por ser formadora de opiniăo, trabalha em pesquisas de mercado e vende seus relatórios com incrível valor agregado para empresas privadas e para o governo de 85 países.
Uma característica fundamental de um processo de BI é que nele os dados săo copiados da base de dados transacional e de outras fontes, para a base de dados analítica, o que permite que as informaçőes sejam extraídas desta última sem que a performance do sistema transacional seja prejudicada e da forma mais eficiente, eficaz e visualmente agradável possível, sempre focada na tomada de decisăo.
Os dados podem, na sua origem, estar estruturados ou năo, ou seja, podem vir de um sistema de informaçăo com dados organizados e corretamente normalizados em tabelas e colunas, e podem ainda serem extraídos de sites da internet como texto puro, áudio, vídeo ou outros formatos. Apesar disso, em ambas as situaçőes eles devem ser tratados e gravados em um formato que facilite a extraçăo de informaçőes e apoie as decisőes dos gestores.
A maioria dos sistemas de informaçăo se enquadra na categoria dos Online Transaction Processing(OLTP), também chamada de processamento de transaçőes em tempo real. Um sistema deste tipo exige uma base de dados modelada para otimizar a inclusăo e alteraçăo de dados, obedecendo a padrőes rígidos de normalizaçăo, evitando redundâncias, permitindo a integridade referencial e outras consistęncias.
As soluçőes para análise de grandes volumes de dados, sob diversas perspectivas, exigem uma base de dados multidimensional, chamada de Online Analytical Processing (OLAP), modelada para otimizar a extraçăo de informaçőes e normalmente armazenada em servidores diferentes dos utilizados pela aplicaçăo OLTP.
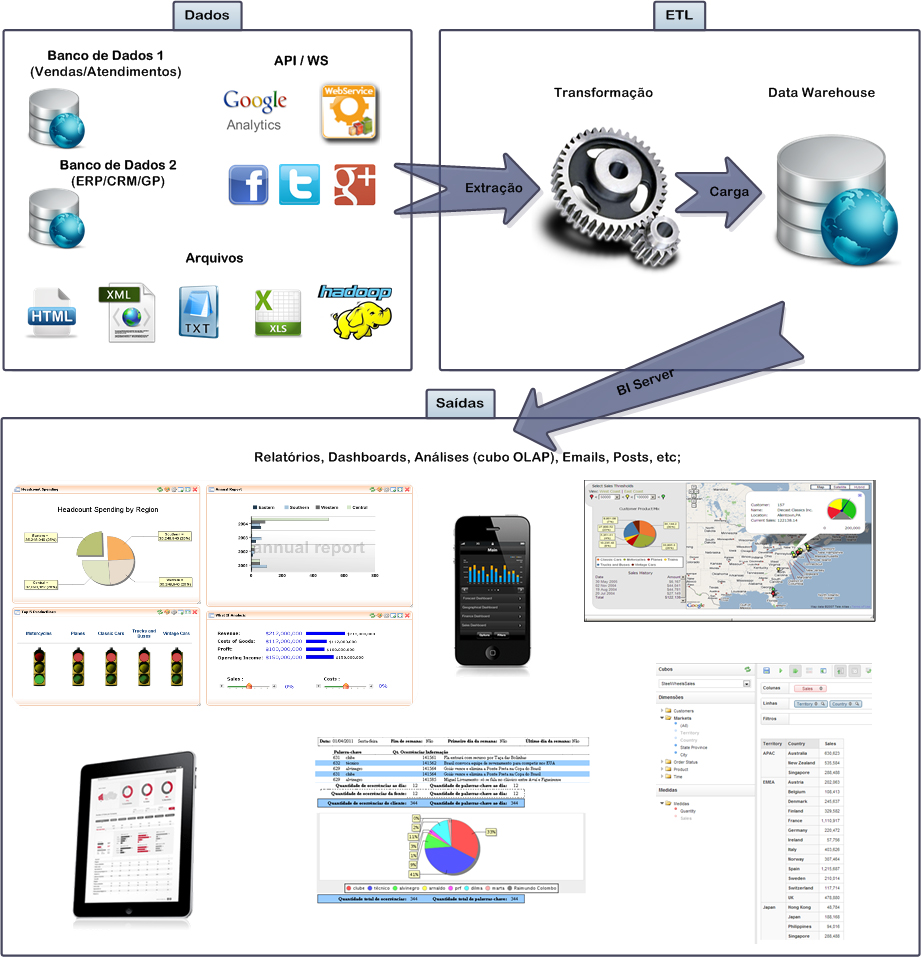
A Figura 1 ilustra as etapas de um ciclo de BI, que é repetido com certa periodicidade. Como pode ser observado, os dados seguem da sua origem até o seu destino e fornecerăo insumos para as saídas aos usuários finais. A primeira etapa deste ciclo consiste na captaçăo dos dados, oriundos de diversas fontes e em distintos formatos. Na maioria dos casos, no entanto, os dados săo lidos da base transacional, OLTP.
A segunda etapa é a Extract, Transform and Load, que consiste em ler os dados, fazer as adequaçőes para torná-los de fácil interpretaçăo e pré-calcular os totalizadores desejados, gravando-os no Data Warehouse.
O processo de ETL é dividido em tręs etapas:
A ETL é uma das etapas do processo de Business Intelligenceque visa a criaçăo de um grande armazém para os dados (Data Warehouse). Para que o processo de Business Intelligence se tornasse viável, foi necessário o desenvolvimento de ferramentas especialistas, capazes de executar todas as tarefas exigidas pela atividade. Devido ŕ grande facilidade proporcionada, a adoçăo destas ferramentas para outros processos, como a migraçăo e a sincronizaçăo de dados entre sistemas, passou a ser apenas uma questăo de tempo. Hoje em dia essas ferramentas săo utilizadas para atividades como garimpagem de dados, leitura e análise de conteúdo das redes sociais e bolsas de valores, envio de e-mail marketing, etc.
A terceira e última etapa do ciclo de BI é a da saída dos dados, que pode acontecer em diversos formatos. Os relatórios, o formato mais usual, tęm layout pré-definido, aceitam uma gama de filtros e geram documentos em pdf, xls, etc. Outra forma de saída de dados săo os dashboards, que tęm a finalidade principal de permitir o acompanhamento de indicadores em tela, de forma gráfica e interativa. Já as análises săo feitas por meio de uma ferramenta de navegaçăo OLAP, pelo próprio usuário final, que pode manipular os cubos criados, além de salvar e compartilhar suas consultas analíticas. Outras formas usuais de saída săo os E-mails e Posts, que podem ser disparados para sinalizar a ocorręncia de um evento ou para alertar que determinado indicador atingiu um nível crítico.
Normalmente o processo de ETL se repete uma vez ao dia, de madrugada, refletindo todas as alteraçőes do dia anterior, mas a periodicidade deve ser ajustada de acordo com a necessidade, em cada situaçăo.
Com essa enorme demanda, muitas soluçőes de BI foram criadas. Inicialmente o foco das empresas desenvolvedoras era apenas em grandes mercados e, por isso, cobravam valores estratosféricos pelos softwares, consultorias e claro, pelo hardware, que ainda hoje, năo raro, vem embutido na maioria das propostas.
O advento do software livre possibilitou que ótimas alternativas ŕs soluçőes proprietárias fossem criadas. Em 2004, na Flórida, Estados Unidos, formou-se uma equipe de executivos de grande experięncia em BI que analisou diversas soluçőes Open Source do mercado, selecionando as mais interessantes em cada especialidade. A equipe, que foi acrescida dos principais líderes dos projetos escolhidos, fez algumas pequenas adaptaçőes para que as suas ferramentas fossem todas compatíveis entre si, criando assim a suíte de aplicativos Pentaho Business Analytics. Esta suíte segue as políticas de desenvolvimento, distribuiçăo e suporte dos softwares open source, que săo flexíveis, independem de sistema operacional e de fornecedores, o que garante alta confiabilidade, segurança e escalabilidade. Também por isso, o código fonte, baseado em padrőes do mercado (J2EE e AJAX), é aberto e liberado para distribuiçăo e modificaçăo sem qualquer custo de licenciamento.
A versăo 4.8 do Pentaho, lançada em novembro de 2012, conta com uma das principais novidades dos últimos anos, o Pentaho Marketplace, que é um repositório que permite a instalaçăo, atualizaçăo e remoçăo de plugins, pela interface web.
Outro ponto positivo do Pentaho é que muitas pessoas estăo envolvidas nas melhorias acrescentadas ŕs ferramentas da suíte. Uma delas merece especial destaque, o portuguęs Pedro Alves. Ele é o responsável pela criaçăo das ferramentas C, batizadas de C*Tools, todas disponíveis no Pentaho Marketplace, que englobam diversas ferramentas extremamente úteis, como o Community Dashboard Framework (CDF), Community Dashboard Editor (CDE), Community Data Access (CDA), Community Cluster Cache (CCC), entre outras.
Cabe destacar também o plugin Saiku Analytics, que será demonstrado nesta série e que traz um front end em jQuery que permite a criaçăo de análises OLAP com grande facilidade, por meio de recursos de drag and drop.
É importante ressaltar que o Pentaho, apesar de ser um software livre, conta também com uma versăo comercial, com o nome de Pentaho Enterprise Edition. Basicamente o software é o mesmo, mas acrescenta alguns recursos que permitem maior facilidade na sua configuraçăo, gestăo e análise de dados, além do suporte técnico oferecido. Esta versăo tem um modelo semelhante aos outros distribuidores de BI, que levam em conta o número de servidores, processadores e núcleos, mas com valores irrelevantes quando comparados. A versăo livre, chamada de Pentaho Community Edition é suficiente para se iniciar um projeto e, caso haja a necessidade, a versăo paga pode ser contratada a qualquer momento, sem a necessidade de ajustes nas soluçőes já criadas.
A parte servidora da suíte é formada por dois serviços web. O primeiro é o BI-Server, executado no servidor Tomcat. Além de se encarregar de executar todas as ETLs, possui uma interface web para disponibilizar ao usuário final as soluçőes criadas, chamada de Pentaho User Console (PUC). O segundo serviço é o da interface de administraçăo, executado no servidor light de aplicaçőes Jetty, e chamado de Pentaho Administration Console (PAC). É neste serviço que os usuários, seus grupos, conexőes JNDI e agendamentos de ETLs săo mantidos e os caches dos diversos componentes podem ser limpos.
Com os conceitos apresentados, tęm-se subsídios para iniciar o desenvolvimento de uma aplicaçăo analítica, utilizando software livre. A primeira etapa de qualquer projeto de TIC é o levantamento de requisitos e de regras de negócio, que é fundamental para delimitar o que se espera como resultado deste trabalho e como ele será validado. Com projetos de Business Intelligence năo é diferente. Para exemplificar as etapas do processo de desenvolvimento de BI, a seguir apresentam-se os requisitos e regras de negócio do case proposto para esta série de artigos.
Para apresentar os conceitos relevantes para esta série de artigos, bem como para exemplificar o uso de algumas das ferramentas da suíte Pentaho Business Analytics, suponha que o diretor da Magazine Setorial, uma grande empresa fictícia de e-commerce, contrata os serviços de Business Intelligence de uma empresa especializada e explica, nos itens a seguir, as características e necessidades do projeto:
Normalmente os requisitos de um case real săo repassados ao analista de BI de forma sucinta, tal como foram, propositadamente, descritos neste case. A análise dos requisitos é fundamental para que as perguntas corretas sejam formuladas e respondidas, ainda que mentalmente, para que entăo a soluçăo seja modelada.
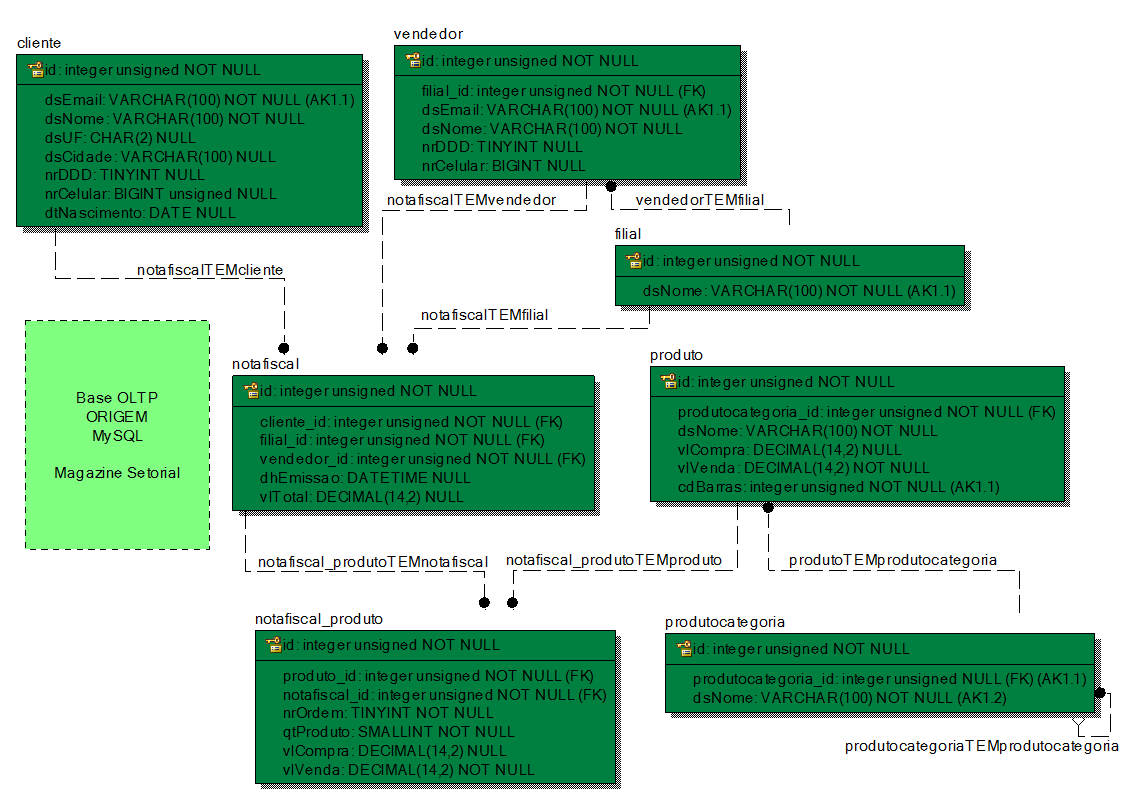
Na Figura 2 é apresentado o Modelo de Entidade-Relacionamento (MER ou ER) da base que armazena os dados do sistema transacional, em MySQL. Esta estrutura armazena dados referentes ŕs filiais e seus vendedores, além dos dados dos clientes e suas notas fiscais, com os produtos de cada compra. Percebe-se, além disso, que os produtos săo sempre de uma categoria (gęnero ou tipo) de produto, pois a tabela de produtos tem uma chave estrangeira apontando para a de categoria de produtos, sem aceitar nulos.
Após a análise da base origem do processo de ETL e o confronto com os requisitos elencados, percebe-se que a criaçăo de um cubo para totalizar os dados com toda a flexibilidade solicitada será a melhor alternativa, uma vez que esta soluçăo contempla todos os requisitos e o usuário terá todos os resultados em uma única tela, com uma ferramenta OLAP.
Para armazenar os dados do cubo, uma base multidimensional é necessária. Muito embora existam mitos sobre a dificuldade na modelagem de dados multidimensional, o conceito é simples. Independente das diferenças doutrinárias de Ralph Kimball e William Inmon, dois dos precursores do BI, entende-se que a maioria das necessidades apresentadas pelos usuários săo contempladas por meio do esquema estrela (star schema), defendido por Kimball e que consiste em uma “tabela fato” e suas várias “dimensőes”. A outra vertente, útil em muitos casos e defendida por Inmon, prega o modelo floco de neve (snow flake), onde modelagens mais complexas (com maior normalizaçăo) săo utilizadas para armazenar os dados.
Este case adota o esquema estrela que, tal como salientado, é utilizado na grande maioria dos casos e atende a todos os requisitos elencados aqui. Para tanto, abordar-se-á a seguir alguns conceitos importantes.
Um data warehouse pode ter um ou mais data marts, que seriam um conjunto de tabelas que armazenam os cubos multidimensionais de um mesmo assunto, como por exemplo, “vendas”. Cada dimensăo permite analisar os fatos por uma determinada visăo, seja por “filial”, “categoria de produto”, “data da venda”, etc.
As dimensőes podem ser basicamente de dois tipos, Simples e SCD. No primeiro tipo, o processo de ETL năo versiona os dados na base analítica. Isso significa que, por exemplo, caso o telefone de um cliente fosse alterado na base transacional, o telefone antigo seria sobrescrito na dimensăo de clientes no processo de ETL. Este comportamento para o caso do telefone é perfeito, mas para analisar informaçőes temporais, năo.
Imagine que para o seu negócio, a UF em que o cliente mora é de suma importância e um determinado cliente se mudou para outro estado. Todo o histórico dele, quando ele morava no primeiro endereço, é extremamente relevante e por isso năo deve ser perdido, ou seja, quando analisados os dados das vendas efetuadas na época em que ele morava no primeiro endereço, estes devem ser computados nas estatísticas da primeira UF, e os dados das vendas efetuadas depois da mudança devem entrar nas estatísticas da nova UF.
Para resolver esse problema existem as dimensőes do tipo Slowly Changing Dimension (SCD), que guardam o histórico dos dados caso tenham seu valor alterado. O histórico pode ser criado de algumas formas, mas a principal é versionando o registro. Isto quer dizer que cada registro tem datas de início e fim da sua vigęncia, e uma coluna para indicar o número da versăo. Deste modo, apenas um registro será vigente em um determinado momento. No exemplo do telefone alterado, o registro teria sua data de fim de vigęncia alterada do valor default, que é “01/01/2199”, para a data e hora atuais e seria incluído um novo registro vigente com o número da versăo acrescido em um. Muitos autores dizem que esta característica é um divisor de águas entre as “verdadeiras” ferramentas de BI e as “falsas”. Isto porque, muitas soluçőes proprietárias de relativo sucesso no mercado năo oferecem esta funcionalidade, limitando-se apenas a oferecer os dados atuais, desprezando toda a riqueza que o histórico tem a oferecer.
Dando continuidade aos importantes conceitos, a chave primária que as dimensőes recebem é chamada de Surrogate Key ou “chave substituta”, daí o prefixo “SK_” em seus nomes. Outra nomenclatura utilizada é Technical Key, com o prefixo “TK_”.
Como boa prática, o primeiro registro de toda dimensăo deve ter em seus atributos valores nulos. Isso porque, este registro será utilizado nos casos em que a ETL da tabela fato năo encontra, nas dimensőes, o registro procurado. Dessa forma, a tabela fato sempre apontará para um registro da dimensăo, mesmo que com valores nulos, garantindo a integridade relacional e deixando evidenciado que aquela informaçăo năo foi encontrada. Isto permite que o processo de ETL, em um caso de năo conformidade dos dados, siga sua execuçăo normalmente, sem disparar erro algum.
Outra boa prática é utilizar colunas de auditoria nas dimensőes, como a data de inserçăo e a data de alteraçăo do registo. Mas evite criar estas colunas com valores default no banco de dados, pois assim, todo o controle fica com o Pentaho e o comportamento das tabelas é sempre o mesmo, independente do SGBDR envolvido.
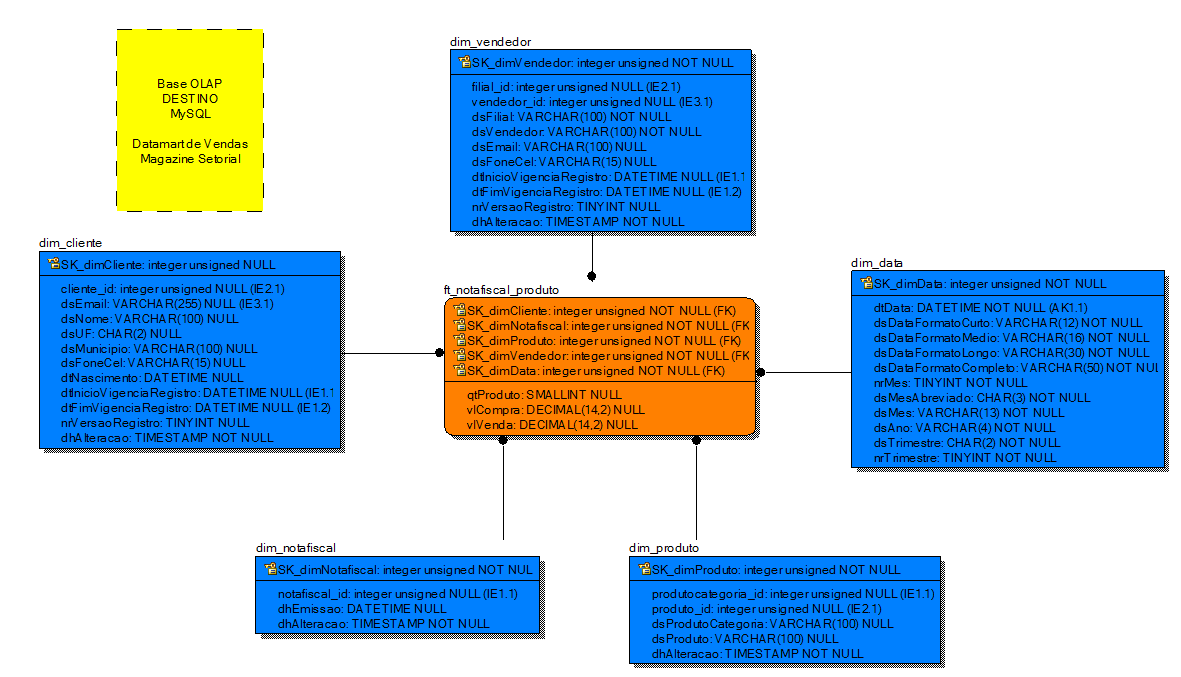
A partir destes conceitos, tęm-se subsídios para iniciar efetivamente a modelagem da base de dados analítica. Como primeira tarefa, devem-se verificar os dados da base origem e definir qual é o fato que será analisado a partir do cubo criado. Neste case săo as vendas de produtos. Isto já define a origem dos dados da tabela fato e, pela padronizaçăo sugerida neste artigo, o seu nome. Como os dados virăo da tabela “notafiscal_produto”, que contém uma linha por produto vendido, a tabela Destino será chamada de “ft_notafiscal_produto”, que teve seu nome formado pelo prefixo “ft_” e pelo nome da tabela origem.
Analisando os requisitos, percebe-se que o de número 7 orienta a definiçăo de algumas dimensőes, sendo, a princípio, uma para cada conceito tratado (filial, vendedor, cliente, nota fiscal, produto e categoria do produto), enquanto o requisito de número 8 diz que filial e vendedor podem ser armazenadas em uma mesma dimensăo, explicando que um vendedor sempre estará ligado a uma filial, e terá o nome “dim_vendedor”, obtido concatenando o prefixo “dim_” com o nome da tabela origem. Como um vendedor pode mudar de filial, esta dimensăo deve guardar o histórico dos seus dados.
Com o objetivo de facilitar a venda, bem como a gestăo dos produtos, estes săo agrupados conforme o gęnero, de modo que um produto como o “Ipad” está atrelado ŕ categoria “Eletrônicos”, simulando a experięncia de estar em uma loja com diversos corredores. Neste contexto, um produto raramente muda de categoria e, em ocorrendo tal hipótese, pode-se simplesmente sobrescrever, na dimensăo do produto, o valor antigo da categoria, mantendo o novo valor. Assim, a dimensăo “dim_produto” deve ter também as informaçőes da categoria do produto, além das informaçőes referentes ao produto, e năo precisa das colunas para o versionamento (número de versăo e datas de vigęncia do registro).
Na prática, o que diferencia o tipo da dimensăo é a presença ou ausęncia dessas colunas, pois nenhuma alteraçăo na nomenclatura das tabelas é recomendada para indicar se a dimensăo é uma SCD ou Simples. Isto porque, a qualquer momento pode-se optar por versionar ou deixar de versionar os registros de uma tabela, e a nomenclatura pode se tornar um obstáculo considerável, pois com o nome da tabela alterado, os metadados do cubo deveriam também refletir esta alteraçăo e ser republicados.
Ainda analisando os produtos, uma característica que merece especial atençăo é a de que os valores de compra e venda também văo para a tabela fato. Isto porque um servidor OLAP tem a incumbęncia de traduzir as consultas feitas por meio de queries multidimensionais (MDX) em simples queries SQL para obter os valores das suas diversas Medidas. Estes cálculos săo sempre feitos levando em conta os dados da tabela fato de cada cubo, por meio da utilizaçăo de agregadores como soma, média, quantidade total, valor máximo e valor mínimo, etc. Entretanto, nada impede que os valores também sejam armazenados e versionados na “dim_produto”. Apesar disso, estes valores seriam apenas ilustrativos e năo seriam utilizados nos cálculos.
Para que sejam possíveis análises levando em conta o cliente, a dimensăo “dim_cliente” é fundamental e terá os atributos para versionamento, pois neste caso as informaçőes săo todas relevantes ao negócio. Outra dimensăo necessária e presente em praticamente todas as aplicaçőes de BI é a dimensăo tempo, aqui chamada de “dim_data”.
Neste case serăo computados dados com as granularidades de Ano, Trimestre, Męs e Dia, de acordo com os requisitos, mas poderíamos ter uma dimensăo para as horas e minutos, por exemplo, o que permitiria análises sobre o horário em que cada compra foi efetuada. A dimensăo “dim_data” terá um registro para cada dia e terá atributos para representar também o ano, trimestre e męs referentes ao dia em questăo, sem a necessidade dos atributos de versionamento. Por exemplo, o registro do dia “01/01/2008” tem o atributo dsAno com o valor “2008”, o atributo dsMes com valor “Janeiro” e nrTrimestre com valor igual a “1”.
O processo com a finalidade de popular esta dimensăo com seus dados deve gerar registros suficientes que abranjam as datas em que os fatos analisados no case ocorreram ou ocorrerăo. Por exemplo, desde 01/01/2000 até 01/01/2020. Armazenamos dias suficientes para que a aplicaçăo năo exija a geraçăo destes registros em um curto espaço de tempo. Datas mais avançadas também serăo úteis para análises preditivas e por este motivo deve-se gerar linhas suficientes para se contemplar esta análise.
O modelo de dados multidimensional apresentado na Figura 3 segue o modelo estrela, defendido por Kimball, e será a base Destino do processo de ETL, criando assim o Data mart de Vendas. Na hipótese deste case ser proposto a diversos profissionais da área de Business Intelligence, as bases de dados por eles modeladas năo seriam muito diferentes desta figura.
Com relaçăo ŕ performance do banco de dados, para este case foi selecionado o SGBDR MySQL com a engine MyIsam, que é otimizada para a leitura de dados. As Foreign Keys representadas na Figura 3 năo serăo criadas efetivamente, pois a engine MyIsam năo conta com este recurso. Em outros SGBDRs, no entanto, a utilizaçăo das chaves estrangerias de integridade referencial é recomendada.
No que tange ŕ performance na leitura de dados, alguns autores defendem que a engine InnoDB já atingiu maturidade suficiente para competir com a engine MyIsam, enquanto outros autores, visando melhor performance nesta leitura, defendem a utilizaçăo do MySQL com a engine MariaDb, ou entăo a utilizaçăo de bancos de dados colunares como Cassandra ou MongoDB. Entretanto, este assunto exige um novo estudo e foge do escopo deste artigo.
Saiba mais: Curso de MongoDB
Cumpre registrar que estăo disponíveis para download, no site da SQL Magazine, as bases de dados Origem e Destino, os arquivos do PDI capazes de executar toda a ETL e o arquivo com os metadados do cubo de vendas.
Assim, para dar início ao processo de ETL descrito a seguir, baixe os arquivos fornecidos e execute os dois arquivos SQL em uma ferramenta cliente do MySQL. O arquivo DumpMagazineSetorial.sql cria a base origem, já com seus dados, e o arquivo CriaBaseDestino_OLAP.sql cria a base destino, pronta para receber os dados migrados pelo processo de ETL.
O Pentaho Data Integration (PDI), uma das ferramentas da suíte open source Pentaho Business Analytics, é comumente chamado pelo nome do projeto que lhe deu origem, o Kettle. Ele é composto por quatro componentes, sendo o mais importante o Spoon, uma interface gráfica que será utilizada neste case para a criaçăo do processo de ETL, enquanto os componentes Pan, Kitchen e Carte se destinam ŕ execuçăo, via linha de comando ou requisiçőes HTTP, dos processos criados no Spoon. Como possibilitam chamadas remotas aos processos, estes componentes permitem a criaçăo de clusters para a execuçăo das ETLs e também a fácil utilizaçăo de processos Pentaho por softwares de terceiros.
Com a adoçăo do PDI, passa a ser indiferente para a aplicaçăo qual é o SGBDR Origem e o Destino. Eles săo apenas datasources, que fornecerăo os dados que passarăo por processos de validaçăo, higienizaçăo, formataçăo, normalizaçăo, sincronizaçăo, etc.
O PDI tem conectividade com praticamente todos os bancos de dados do mercado e pode ainda acessar web services ou fazer chamadas HTTP, além de ler e gerar arquivos xml, json, csv, excel, hadoop fs, etc.
Para a concretizaçăo do case proposto neste artigo, foram utilizados os softwares Pentaho Data Integration, Pentaho Schema Workbench e Pentaho Business Intelligence Server. Todos săo executados em máquinas virtuais Java, daí a necessidade da prévia instalaçăo do Java Runtime Environment (JRE) e da posterior instalaçăo dos drivers JDBC em cada uma das ferramentas Pentaho. Os caminhos para download dos softwares referidos estăo destacados na seçăo Links.
Para iniciar as atividades, faça o download da versăo mais recente do PDI e descompacte o arquivo, disponibilizado em formato .zip. Feito isto, instale e execute o aplicativo realizando as etapas apresentadas a seguir:
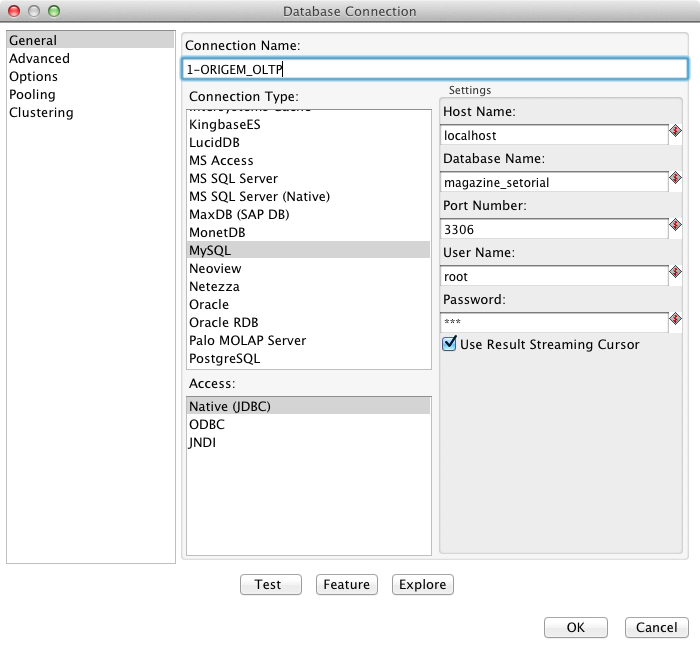
Com o PDI instalado e em execuçăo, a primeira tarefa é conferir se ele, em sua configuraçăo inicial, já possui conectividade com os SGBDRs envolvidos. No PDI, a conexăo aos bancos de dados é feita via JDBC, e cada banco de dados deve ter um driver JDBC correspondente para ele. Dessa forma, basta que o .jar do driver JDBC seja salvo em data-integration\libext\JDBC e o PDI seja reiniciado.
Para este case, em que é utilizado o MySQL, foi utilizado o driver mysql-connector-java-5.1.17.jar. O caminho para download deste driver se encontra na seçăo Links, ao final do artigo.
Saiba mais: Curso Completo de MySQL
O PDI permite armazenar todas as ETLs em banco de dados, entretanto para isso seria necessária a criaçăo do repositório do Pentaho. Neste case, utilizaremos a opçăo de salvar as ETLs em arquivos, e para a organizaçăo destas, foi criada uma pasta chamada SQLMagazine-DW, onde estes arquivos serăo salvos.
Ao longo desta série, será criado um arquivo .ktr para cada transformaçăo. Cada qual será composta por uma série de componentes chamados de steps, ligados entre si por meio de hops, que săo as flechas indicativas da direçăo do fluxo dos dados.
Uma transformaçăo pode ser executada individualmente ou fazer parte de um Job, que permite a execuçăo de várias transformaçőes ou até mesmo de outros Jobs em sequęncia, armazenados em arquivos .kjb.
Tanto os arquivos .ktr quanto os .kjb săo gravados no formato XML, sem criptografia.
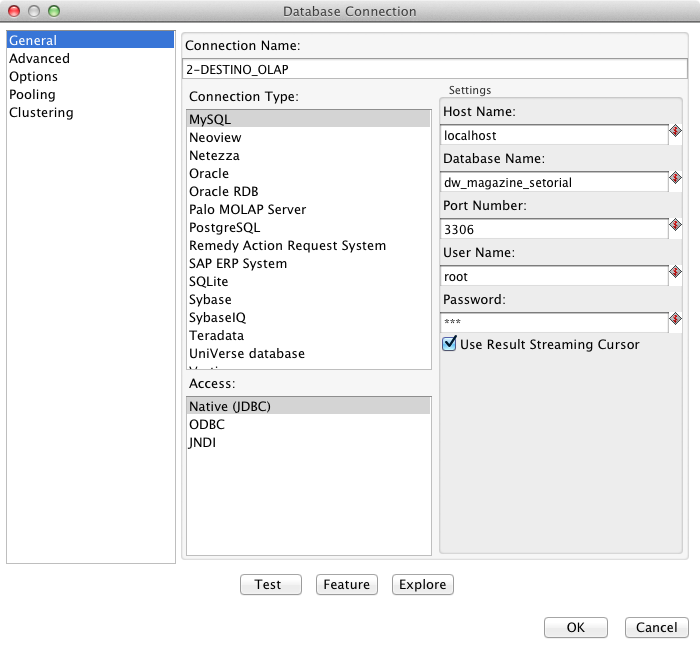
Para obter acesso aos dados da base origem, há a necessidade de criar uma conexăo com o banco de dados. Esta configuraçăo é feita uma única vez e a conexăo será compartilhada entre todas as transformaçőes. Isto gera uma flexibilidade muito grande, permitindo que as ETLs sejam criadas acessando uma base de desenvolvimento e, depois de efetuados os testes, com uma única modificaçăo nesta configuraçăo, todas as transformaçőes passem a apontar para a base de dados de produçăo, por exemplo. Com o objetivo de demonstrar esta flexibilidade, será criada uma transformaçăo e uma conexăo para a base Origem, em MySQL, conforme os passos a seguir:
O PDI possui duas abas no frame esquerdo. Na primeira, chamada View, estăo todos os objetos utilizados, enquanto na segunda, chamada Design, estăo todos os componentes disponíveis para utilizaçăo. Ambas contam com, na parte superior, a convenięncia de um campo de busca pelo nome do componente.
Com a conexăo para a base Origem configurada, criar-se-á a conexăo para a base destino conforme as especificaçőes a seguir:
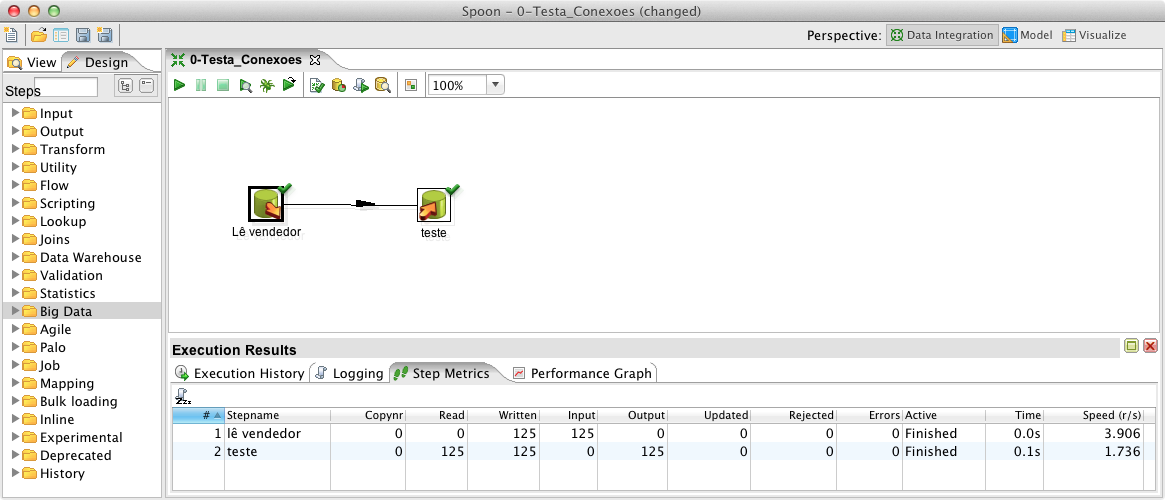
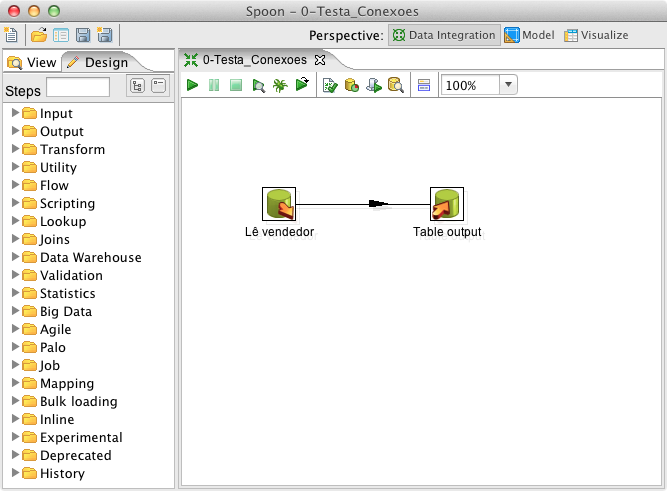
Com isso, a primeira ETL foi efetivada. Ela busca dados da tabela “vendedor” do banco Origem e os grava na tabela “teste” do banco Destino. Para verificar a execuçăo desta transformaçăo, observe os resultados obtidos diretamente no banco de dados. A correta execuçăo desta transformaçăo comprova a eficácia do driver JDBC de conexăo com o MySQL, dos encodes, das permissőes do banco de dados e da rede;
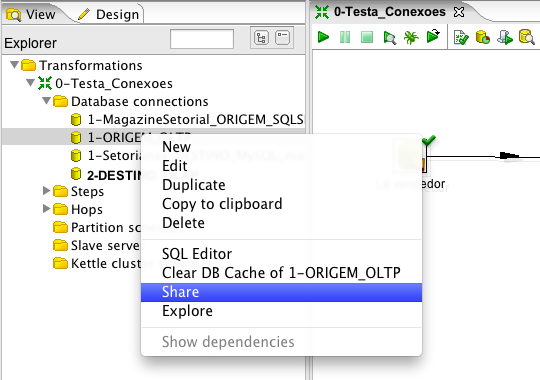
Para que as conexőes criadas possam ser utilizadas por todas as transformaçőes, no PDI, clique na aba View e depois em Database Connections. Em cada uma das duas conexőes criadas, clique com o botăo direito e depois em Share, como expőe a Figura 10.
Com as conexőes criadas, torna-se transparente ao usuário do PDI quais săo os bancos de dados manipulados, pois para esta ferramenta, os dados podem ter origens e formatos diversos. Além da facilidade de acesso aos dados, a ferramenta conta com uma longa lista de steps, cada qual com uma atribuiçăo bem específica. Alguns destes steps executam as mesmas tarefas que os comandos SQL, mas nem por isso o conhecimento desta linguagem deixa de ser relevante, pois seu uso repercute, muitas vezes, em ganho de produtividade.
Neste artigo foram abordados os principais conceitos de Business Intelligence, e para exemplificá-los, foi proposto o case de uma loja de departamentos fictícia, formada por diversas filiais e com a necessidade de analisar os dados de suas vendas. Em seguida, foi apresentada a suíte Pentaho, capaz de contemplar os requisitos e regras de negócio elencados. De volta ao exemplo, a base de dados Origem foi analisada, de forma que o raciocínio necessário para a modelagem da base Destino, em formato estrela, pudesse ser descrito. Por fim, as etapas para a configuraçăo do Pentaho Data Integration foram realizadas.
Os resultados desse trabalho darăo subsídios para que, na segunda e última parte deste artigo, o processo de ETL seja criado, juntamente com os metadados do cubo, sua publicaçăo no servidor web e a análise dos dados em uma ferramenta OLAP.
Continue lendo: Business Intelligence com Pentaho

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.
 <
<