Por Paulo Alvim e Hamilton Oliveira
A introduçăo da orientaçăo a objetos no contexto de desenvolvimento provocou mudanças significativas na forma como os softwares săo produzidos e mantidos. As mudanças foram motivadas pela nova perspectiva adotada pelo paradigma OO, em oposiçăo ao paradigma estruturado, que utiliza uma abordagem focada nos dados e no fluxo de informaçăo dos sistemas.
Uma comparaçăo entre as abordagens e em que contexto determinada perspectiva é mais adequada que outra está fora do escopo desse artigo. É inegável, no entanto, que o mercado já percebeu que a adoçăo da orientaçăo a objetos melhora a qualidade do produto final pois utiliza conceitos, já consagrados em outros segmentos, que facilitam a manutençăo e a evoluçăo dos sistemas.
Em consequęncia, muitas áreas do desenvolvimento de software estăo sendo revisitadas, pois práticas, teorias e técnicas que eram adequadas para o modelo convencional năo podem ser aplicadas de forma irrestrita quando se cria software OO. Uma dessas áreas é a que trata da persistęncia dos dados.
Os Sistemas Gerenciadores de Banco de Dados Relacionais (SGBDRs) conquistaram um lugar de destaque em comparaçăo a outras tecnologias de armazenamento de dados. Embora estes produtos realizem seu papel de modo satisfatório no mundo relacional, quando utilizados no contexto OO adicionam complexidade extra, pois a aplicaçăo passa a necessitar de um processo intermediário de conversăo.
Dessa forma, para persistęncia dos objetos de negócio, temos tręs alternativas: i) utilizar um banco de dados orientado a objetos; ii) utilizar um banco de dados relacional estendido; ou iii) criar uma camada de mapeamento OOxSGBDR. A terceira opçăo é o tema desse artigo.
A adoçăo de banco de dados orientado a objetos é a opçăo ideal quando se desenvolve software OO, pois a camada de persistęncia encontra-se no mesmo nível de abstraçăo da aplicaçăo e nenhuma conversăo precisará ser feita.
Os bancos de dados relacionais estendidos, assim como os bancos de dados OO, fornecem transparęncia, pois o processo de conversăo OO-Relacional é realizado automaticamente.
Um obstáculo para adoçăo dessas duas soluçőes é a grande quantidade de dados armazenados em bancos relacionais (sistemas legados), além do elevado grau de aceitaçăo que os SGBDRs conquistaram no mercado.
Uma soluçăo para usar software OO e manter a base relacional instalada é a criaçăo de classes de mapeamento objeto-relacional. No entanto, a criaçăo dessas classes aumenta o trabalho de codificaçăo. Por outro lado, temos a opçăo de utilizar ferramentas que automatizam essa tarefa, reduzindo o esforço de integraçăo entre os dois mundos.
Existem diversos utilitários que se propőem a realizar o mapeamento objeto/relacional. Nesse artigo utilizaremos o Hibernate, um projeto Open Source e Free, desenvolvido em linguagem Java.
O Hibernate constitui-se de uma biblioteca de classes Java (hibernate.jar), que deve ser adicionada ao classpath, e é uma camada adicional entre a aplicaçăo e o banco de dados. Seu objetivo é eliminar a existęncia de instruçőes SQL nas classes de negócio, atuando como uma fronteira entre as duas tecnologias. Observe na figura 1 a arquitetura do Hibernate.
A figura 1 apresenta uma visăo geral da arquitetura do hibernate.
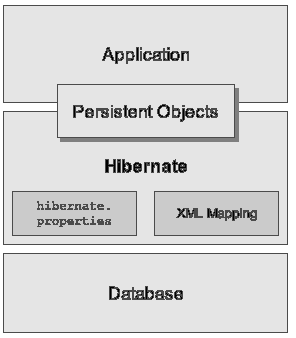
Figura 1 – Visăo Geral da Arquitetura do Hibernate
Dois componentes sobressaem: hibernate.properties e XML Mapping. O hibernate.properties é o arquivo que contém as informaçőes sobre a conexăo com o banco de dados. Nele definimos o tipo do banco, dialect, driver, url, username e password. O hibernate suporta os bancos de dados Oracle, DB2, MySQL, PostgreSQL, Sybase, SAP DB, HypersonicSQL, Microsoft SQL Server, Progress, Mckoi SQL, Pointbase e Interbase. Para facilitar o processo de configuraçăo do arquivo hibernate.properties săo fornecidos modelos que devem ser customizados pelo desenvolvedor, conforme veremos mais adiante.
No XML Mapping săo registradas as informaçőes a respeito do mapeamento das classes e suas respectivas tabelas relacionais. Cada classe é mapeada para uma tabela. Além disso, săo registradas informaçőes sobre os relacionamentos, cardinalidades e identificadores, entre outras.
Vale notar que as classes do hibernate realizam a leitura desses arquivos em tempo de execuçăo, permitindo alteraçőes sem a necessidade de recompilaçăo.
Instalaçăo do ambiente
Para compilar e executar o exemplo descrito neste artigo será necessário instalar os seguintes componentes:
- Ambiente J2SDK 1.4 ou superior - http://java.sun.com/j2se/
- Hibernate - http://hibernate.bluemars.net/
- Servidor MySQL -www.mysql.com
- Driver nativo JDBC para o MySQL (Conector/J) - http://www.mysql.com/products/connector-j/index.html
- Cliente para administraçăo do MySQL. O Front-End utilizado nesta matéria é o MySQL Control Center (MySQL CC) - http://www.mysql.com/products/mysqlcc/index.html
Para o processo de instalaçăo, basta seguir as instruçőes específicas que acompanham cada componente.
Para instalar a aplicaçăo faça o download dos fontes no site da revista, crie um diretório na raiz do disco chamado appHibernate e copie os arquivos para esta pasta.
O exemplo descrito neste artigo é uma variaçăo da aplicaçăo de demonstraçăo disponível na instalaçăo do Hibernate.
Descriçăo das classes de negócio
O modelo parcial de classes do exemplo está representado na figura 2.
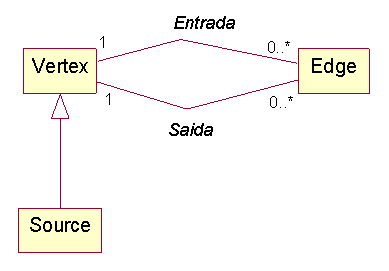
Figura 2 – Modelo parcial de classes de negócio da aplicaçăo
A aplicaçăo possui tręs classes de negócio: Vertex, Edge e Source, que representam uma estrutura em grafo. Analisando as classes Vertex (Vértice) e Edge (Extremidade), observamos que existem dois relacionamentos possíveis entre ambas, que săo entrada e saída. A leitura pode ser feita da seguinte maneira: uma instância de vértice possui um número indefinido de instâncias de extremidades de entrada (0..*) e uma instância da extremidade de entrada possui apenas um vértice.
Outra leitura: uma instância de vértice possui um número indefinido de instâncias de extremidades de saída (0..*), enquanto que uma instância de extremidade de saída possui apenas um vértice. A classe Vertex possui ainda uma subclasse, denominada Source. Pode-se dizer também que toda extremidade possui exatamente dois vértices¸ um de entrada e um de saída.
Criaçăo das tabelas
A partir do modelo de classes devemos criar as tabelas relacionais. Cada classe terá uma tabela equivalente, exceto para generalizaçăo/especializaçăo (herança), como Vertex/Source, onde ambas serăo mapeadas para a mesma tabela. Considerando que a classe Source (subclasse) possui todos os atribuídos da classe Vertex (superclasse), a tabela resultante terá a soma dos atributos das duas classes. Quando for armazenada uma instância de Vertex, os campos referentes a Source receberăo null. Estes atributos pertencem somente ŕ subclasse e năo podem possuir valores para as instâncias da superclasse. Todo esse processo é gerenciado pelo Hibernate, desde que o arquivo de mapeamento esteja corretamente configurado, conforme será visto adiante.
O Hibernate năo realiza a criaçăo das tabelas sozinho. Existem, no entanto, alguns utilitários para geraçăo automática de comandos DDL a partir do modelo de classes. Alternativas no caminho inverso também estăo disponíveis, como o TableGen (http://freespace.virgin.net/joe.carter/TableGen/) que gera classes a partir de um banco de dados.
O script para criaçăo das tabelas referentes ŕs classes Edge e Vertex está disponível para download, juntamente com os demais arquivos da aplicaçăo. A estrutura das tabelas pode ser visualizada nas figuras 3 e 4.
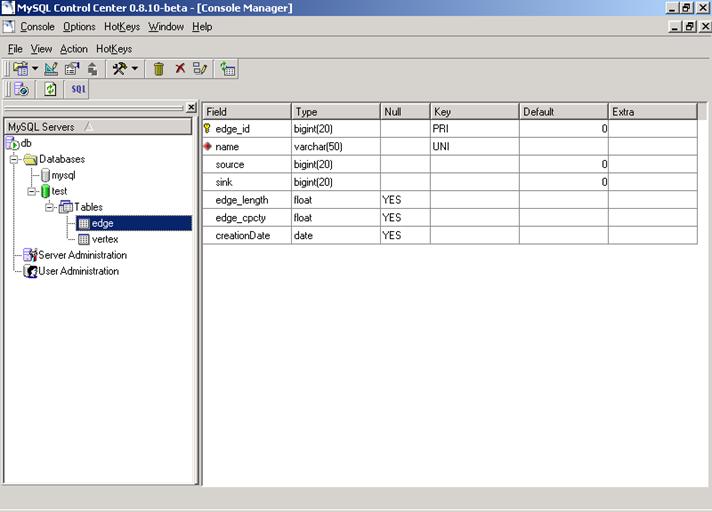
Figura 3 – Representaçăo da tabela relacional Edge, no MySQL CC
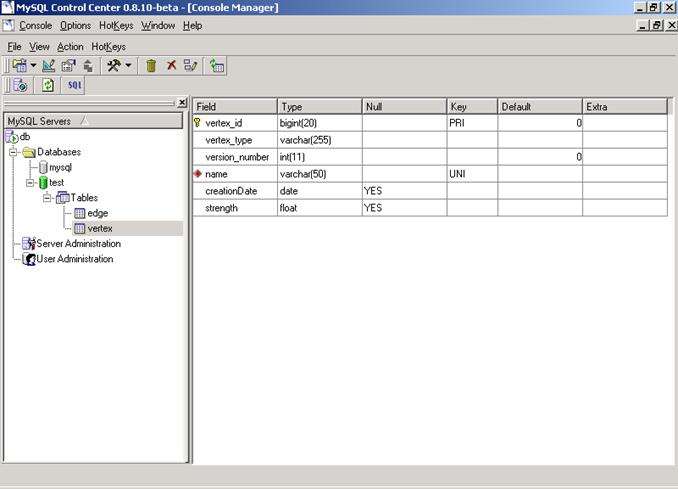
Figura 4 – Representaçăo da tabela relacional Vertex, no MySQL CC
Criaçăo dos arquivos de mapeamento (XML Mapping)
O próximo passo é a criaçăo dos arquivos XML de mapeamento. O arquivo é identificado pelo nome da classe mais a extensăo .hbm.xml.
Sendo assim, para a classe Vertex.java teremos o arquivo Vertex.hbm.xml (listagem 1) e para a classe Edge.java teremos o arquivo Edge.hbm.xml (listagem 2). A criaçăo/ediçăo desses arquivos deve ser feita manualmente. Embora esta operaçăo seja trabalhosa no início, podemos derivar novos arquivos apenas realizando as modificaçőes necessárias sobre a primeira versăo. Por exemplo, se iniciarmos um novo projeto com classes herdadas do nosso modelo, reutilizaremos boa parte da estrutura dos arquivos Vertex.hbm.xml e Edge.hbm.xml para o novo mapeamento. O código completo para os arquivos XML pode ser conferido nas listagens 1 e 2.
-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-1.1.dtd">
<hibernate>-mapping></hibernate>
<class name="appHibernate.Edge" table="edge"></class>
<!--<st1:PersonName w:st="on"-->--<jcs>-cache usage="read-write"/>--></jcs>
<id name="key" column="edge_id"></id>
<generator class="native"></generator>
<property name="name" w:st="on" unique="true" not=""><st1:personname>-null="true" length="50"/></property>
<many>-to-one name="source" not-null="true"/></many>
<many>-to-one name="sink" not-null="true"/></many>
<property name="length" column="edge_length"></property>
<property name="capacity" column="edge_cpcty"></property>
<property name="creationDate" type="date"></property>
Listagem 1 – Arquivo de mapeamento objeto/relacional da classe Edge.java
-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-1.1.dtd">
<hibernate>-mapping></hibernate>
<class name="appHibernate.Vertex" table="vertex"></class>
<!--<st1:PersonName w:st="on"-->--<jcs>-cache usage="read-write"/>--></jcs>
<id name="key" column="vertex_id"></id>
<generator class="native"></generator>
<discriminator column="vertex_type"></discriminator>
<version name="version" column="version_number"></version>
<property name="name" w:st="on" unique="true" not=""><st1:personname>-null="true" length="50"/></property>
<set role="incoming" cascade="all"></set>
<key column="sink"></key>
<one>-to-many class="appHibernate.Edge"/></one>
<set role="outgoing" cascade="all"></set>
<key column="source"></key>
<one>-to-many class="appHibernate.Edge"/></one>
<property name="creationDate" type="date"></property>
<subclass name="appHibernate.Source"></subclass>
<property name="sourceStrength" column="strength"></property>
-mapping>
Listagem 2 –Arquivo de mapeamento objeto/relacional da classe Vertex.java
Vejamos o papel das principais tags deste XML:
- class: Indica a tabela que representará a classe. As propriedades name e table recebem o nome da classe e o nome da tabela, respectivamente.
- id: Indica o campo que será o identificador, ou chave primária. O Hibernate possui diversos algoritmos built-in para geraçăo automática de chaves, que independem do banco de dados. No entanto, referęncias a implementaçőes específicas dos SGBDs também săo permitidas. Neste exemplo, estamos usando o valor native, indicando que năo utilizaremos a geraçăo de chave do Hibernate, já que os valores serăo passados pela aplicaçăo.
- discriminator: Especifica o campo que será utilizado para discriminar a classe do objeto armazenado na tabela. Deve ser utilizado em tabelas que referenciam classes e subclasses, como Vertex. No exemplo, a coluna vertex_type será o discriminator, assumindo os valores Source ou Vertex.
- version: O Hibernate faz o tratamento de concorręncia otimista, permitindo que usuários recuperem registros em paralelo para alteraçăo, sem lock. Para isso, é necessário um campo para atualizar um número de versăo do objeto. Esta propriedade é opcional. No exemplo, criamos a coluna version_number, da tabela Vertex, para esta tarefa.
- property: Neste elemento mapeamos as colunas das tabelas relacionais para atributos do modelo de classes. As propriedades column e name recebem o nome do campo e o nome da propriedade de classe, respectivamente.Veja o exemplo:
Se o nome da propriedade for igual ao nome do campo, podemos omitir a palavra column:
Podemos ainda reforçar a validaçăo de regras, como tamanho máximo e permissăo de valores NULL:
-null="true" length="50"/>set: Utilizado para mapear o relacionamento entre classes. O sub-elemento key recebe o nome do campo que será utilizado como chave entre as tabelas. O sub-elemento one-to-many refere-se a cardinalidade, significando que cada linha da tabela Vertex possui um relacionamento de muitas linhas com a tabela Edge. A análise inversa pode ser feita no arquivo edge.hbm.xml, onde o elemento utilizado é many-to-one. O parâmetro role indica o nome da Interface SET (Collection) que receberá as instâncias da classe relacionada. Na classe Vertex.java, as Collections foram definidas como “incoming” e “outgoing”, indicando uma coleçăo para extremidades de entrada e uma coleçăo para extremidades de saída.
-to-many class="appHibernate.Edge"/>
-to-many class="appHibernate.Edge"/>
subclass: Mapeia uma propriedade que pertence somente a sub-classe. No atributo name indicamos o nome da subclasse referente. No exemplo, a propriedade strength está disponível somente na classe Source.
A documentaçăo do Hibernate disponibiliza uma descriçăo detalhada de todas as tags e propriedades de configuraçăo disponíveis.
Descriçăo das classes Application e Persistente
Além das classes de negócio descritas na figura 2, criamos duas outras classes: Application e Persistence. O código-fonte para a classe Application está descrito na listagem 3.
1 package appHibernate;
2
3 /** A classe principal da aplicaçăo **/
4 public class Application {
5 private static Vertex foo,bar; private static Source src,snk;
6 private static Edge e1,e2; private static Persistence persistence;
7
8 public static void main( String[] no_args ) throws Exception {
9 //Criando a conexăo com banco de dados através do Hibernate
10 persistence = new Persistence();
11 persistence.parserClass(Vertex.class,Edge.class);
12 persistence.buildSessionFactory();
13 persistence.openSession();
14 //Criando uma instância do objeto Source
15 src=new Source();
16 src.setName("src");
17 src.setSourceStrength(1);
18 //criando uma segunda instância do objeto Source
19 snk=new Source();
20 snk.setName("snk");
21 snk.setSourceStrength(-1);
22 //Criando uma instância do objeto Edge que faz referęncia as instâncias snk e src
23 e1=new Edge();
24 e1.setName("e1");
25 e1.setSource(src);
26 e1.setSink(snk);
27
28 //Fazendo com que os objetos tornem-se persistentes
29 persistence.save(src,new Long(1000));
30 persistence.save(snk,new Long(2000));
31 persistence.save(e1,new Long(3000));
32 persistence.flush();
33 //Alterando o nome de uma instância persistente
34 e1.setName("e10");
35 persistence.flush();
36 }
37 }
Listagem 3 – Descriçăo do código-fonte da classe principal Application
Na Listagem 4 podemos visualizar a classe Persistence. Nessa classe vemos o uso dos componentes principais do Hibernate. A Interface Datastore representa o conjunto de todos os mapeamentos das classes Java para o modelo relacional. Esta interface é responsável por verificar, em tempo de execuçăo, as informaçőes contidas nos arquivos XML. Após a verificaçăo da consistęncia do arquivo, a Interface Datastore configura o ambiente de modo que a persistęncia possa ser efetuada.
Em seguida, Datastore cria uma instância de SessionFactory, que vem a ser a fábrica de sessőes para a aplicaçăo. A partir da obtençăo de SessionFactory năo será mais necessário a utilizaçăo de Datastore, pois seu objetivo é apenas a preparaçăo do ambiente.
A classe Persistence foi criada com o objetivo de intermediar a aplicaçăo e os serviços do Hibernate. Esses serviços poderiam ser implementados diretamente em Application; no entato, a classe Persistence foi criada por motivos de clareza.
1 /** classe Persistence **/
2 package appHibernate;
3 import cirrus.hibernate.*;
4 import java.sql.SQLException;
5
6 public class Persistence {
7 private SessionFactory sessions; private Datastore ds; private Session sess;
8
9 public void parserClass(Class persistClass1, Class persistClass2) throws Exception
10 {
11 // configura o Datastore
12 ds = Hibernate.createDatastore().storeClass(persistClass1).storeClass(persistClass2);
13 }
14
15 public void buildSessionFactory() throws Exception
16 {
17 sessions = ds.buildSessionFactory(); // cria uma instância SessionFactory
18 }
19
20 public void openSession() throws Exception
21 {
22 sess=sessions.openSession();
23 }
24
25 public void flush() throws SQLException , HibernateException
26 {
27 sess.flush();
28 }
29
30 public void save(Object persistClass, Long id) throws SQLException, HibernateException
31 {
32 sess.save(persistClass, id);
33 }
34 }
Listagem 4– Código-fonte da classe Persistence
Observamos na listagem 4, linha 3, que é necessário realizar a importaçăo das classes do Hibernate. Na linha 7 declaramos SessionFactory, Datastore e Session. O modelo de classes evoluído, com a adiçăo de Application e Persistence, pode ser visto na figura 5.
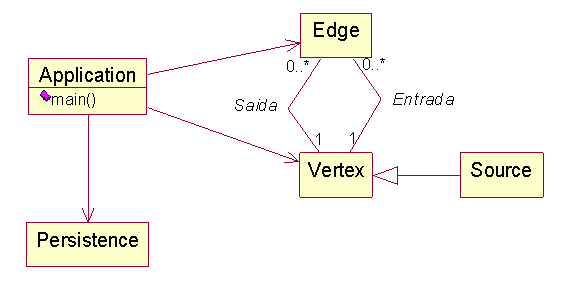
Figura 5 – Modelo de classes da aplicaçăo
Analisando a figura 5 notamos setas partindo da classe Application para as demais classes do modelo, indicando navegabilidade. Isso significa que as classes Persistence, Vertex, Source e Edge se tornarăo atributos da classe Application, conforme pode ser visto nas linhas 5 e 6 da listagem 3.
Descrevendo o código da classe Application
Observando o código-fonte da listagem 3 vemos que os procedimentos para configuraçăo do Hibernate, através da classe Persistence, săo realizados nas linhas 10 ŕ 13.
A verificaçăo dos arquivos XML é feita na linha 11. Repare que informamos as classes Vertex e Edge como parâmetro, indicando ao Hibernate que os arquivos de mapeamento serăo Vertex.hbm.xml e Edge.hbm.xml, respectivamente.
Se nenhuma exceçăo for gerada no parser do arquivo XML, uma instância de SessionFactory será criada na linha 12. Na linha 13 obtemos uma instância de Session para a aplicaçăo. A partir desse momento, estamos prontos para realizar o mapeamento objeto/relacional.
Da linha 15 ŕ linha 26 criamos instâncias de nossas classes de negócio (Vertex, Edge e Source), fazendo o relacionamento através dos métodos setSource (linha 25) e setSink (linha 26), da classe Edge.
Somente nas linhas 28 a 31 tornamos nossos objetos persistentes. O método save (linhas 28, 29 e 30) insere um novo objeto na base de dados e o método flush (linha 31) garante a sincronia entre o estado da conexăo JDBC e o estado dos campos em memória.
Nas linhas 33 e 34 o nome do objeto e1 é alterado e10. Após a mudança, disparamos o método flush() sem precisar chamar o método save. Isso porque, após a execuçăo do primeiro save, o objeto passa a ser monitorado pelo Hibernate e todas as chamadas ao método flush() subseqüentes garantem a sincronia entre os valores em memória e as informaçőes no banco.
Se executássemos, neste exemplo, uma chamada ao método flush() antes do método save(), nada aconteceria no banco de dados.
Executando a aplicaçăo
Antes de executarmos a aplicaçăo, devemos configurar o arquivo hibernate.properties, que armazena as informaçőes de conexăo com o banco de dados.
33#hibernate.query.substitutions yes 'Y', no 'N'
34
35
36 ## DB2
37
38 #hibernate.dialect cirrus.hibernate.sql.DB2Dialect
39 #hibernate.connection.driver_class COM.ibm.db2.jdbc.app.DB2Driver
40 #hibernate.connection.url jdbc:db2:test
41 #hibernate.connection.username db2
42 #hibernate.connection.password db2
43
44
45 ## MySQL
46
47 hibernate.dialect cirrus.hibernate.sql.MySQLDialect
48 hibernate.connection.driver_class org.gjt.mm.mysql.Driver
49 hibernate.connection.driver_class com.mysql.jdbc.Driver
50 hibernate.connection.url jdbc:mysql:///test
51 hibernate.connection.username
52 hibernate.connection.password
53
54
55 ## Oracle
56
57#hibernate.dialect cirrus.hibernate.sql.OracleDialect
58#hibernate.connection.driver_class oracle.jdbc.driver.OracleDriver
59#hibernate.connection.username ora
60#hibernate.connection.password ora
61#hibernate.connection.url jdbc:oracle:thin:@localhost:1521:test
Listagem 5– Visăo parcial do arquivo hibernate.properties
Analisando as linhas 47 a 52 da listagem 5 vemos que as configuraçőes com o MySQL encontram-se ativas, pois o símbolo # indica comentário.
Este arquivo deve estar no diretório raiz da variável classpath, para que o Hibernate funcione de maneira adequada.
Finalmente, estamos prontos. Dentro do diretório appHibernate, digite executa.bat, arquivo de lote com os comandos necessários para compilar e rodar a aplicaçăo Java.
Após a execuçăo do programa, as tabelas Edge e Vertex devem estar conforme as figuras 6 e 7.
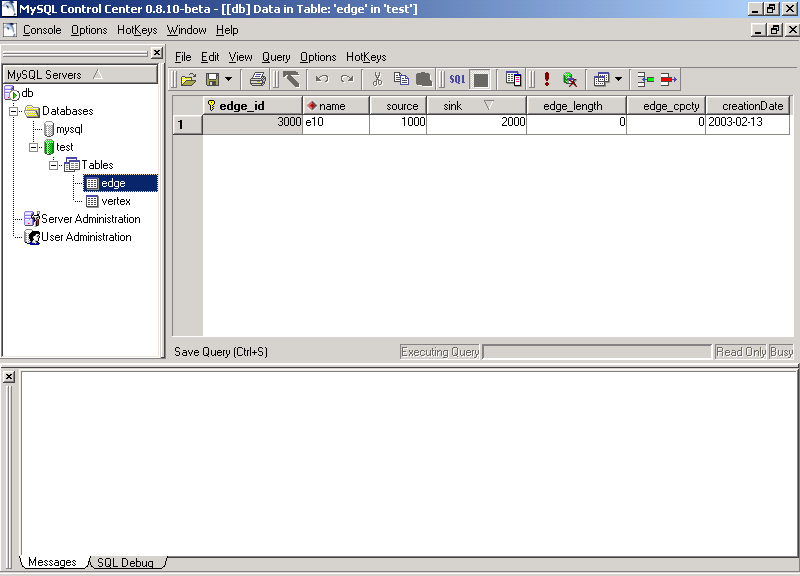
Figura 6 – Visualizaçăo da tabela Edge após a execuçăo do programa
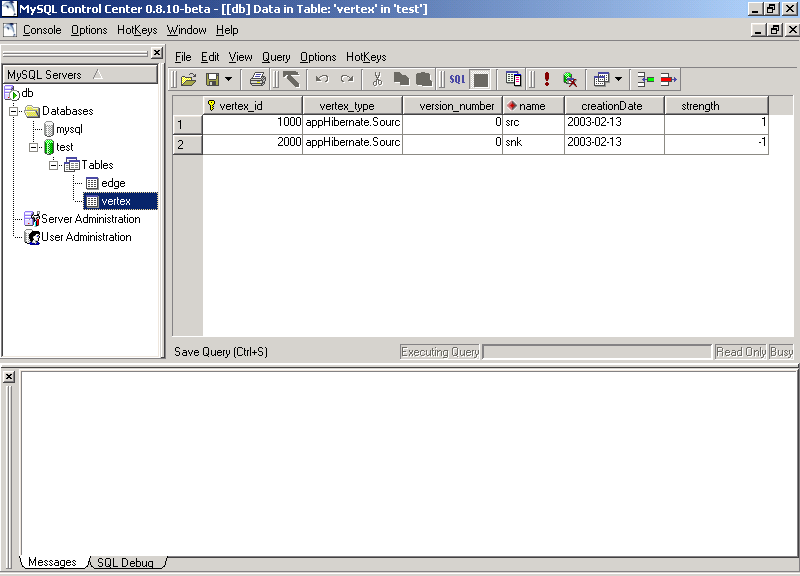
Figura 7 – Visualizaçăo da tabela Vertex após a execuçăo do programa
Recuperando Informaçőes
A aplicaçăo de exemplo apenas insere e altera os atributos das classes. Para recuperar as informaçőes persistidas, podemos utilizar o código a seguir:
1 Edge edge= new Edge();
2 edge = (Edge) sess.load(Edge.class, new Long(3000));
3 Source src = new Source();
4 src=edge.getSource(); // o objeto ‘src’ foi recuperado através da execuçăo da linha 2
5 Source snk = new Source()
6 snk=edge.getSink(); //o objeto ‘snk’foi recuperado através da execuçăo da linha 2
Listagem 6 – Código para recuperaçăo de objetos armazenados no banco de dados
Neste bloco, o método load recupera um objeto da tabela Edge com identificador igual a 3000. O Hibernate retorna todos os objetos que săo referenciados por este objeto, ou seja, src e snk, que encontram-se gravados na tabela Vertex, o que permite a execuçăo com sucesso das linhas 4 e 6.
O Hibernate também possibilita a execuçăo de instruçőes de seleçăo, através da HQL (Hibernate Query Language). Consulte a referęncia do Hibernate para detalhes sobre a sintaxe desta linguagem de consulta.
Conclusăo
Ao longo do artigo demonstramos, através de um exemplo, como realizar o mapeamento OOxSGBDR através do Hibernate, um projeto Open Source e Free. Utilizamos uma aplicaçăo de demonstraçăo que foi modificada para estar mais próxima de um processo real de desenvolvimento. Criamos um aplicativo Java, utilizando J2SDK 1.4, que realiza chamadas ŕs classes e Interfaces fornecidas pelo Hibernate. Sabemos que dificilmente um desenvolvedor iria se aventurar a criar uma aplicaçăo que acessa um banco de dados cliente/servidor utilizando comandos através do prompt do Shell. No entanto, essa abordagem foi utilizada para reduçăo da complexidade, de modo que, para entender, executar ou mesmo modificar a aplicaçăo, é necessário apenas o conhecimento básico de Java e da especificaçăo J2SDK. Considerando ainda que estamos utilizando classes Java, as chamadas ao hibernate podem ser realizadas através de Java Server Pages (JSP), Servlets ou Enterprise JavaBens(EJB).
Por motivo de simplificaçăo, năo foi demonstrado todo o potencial do Hibernate, como o gerenciamento de transaçőes ou a possibilidade de um EJB obter uma fábrica de sessőes (SessionFactory), utilizando JNDI Lookup. Informaçőes mais detalhadas sobre recursos do hibernate podem ser obtidas na documentaçăo que acompanha o projeto.

