Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.

Clique aqui para ler todos os artigos desta ediçăo
Explorando visualmente informaçőes em grandes bases de dados utilizando a ferramenta FMDB
Um dos objetivos das organizaçőes que utilizam sistemas computacionais é armazenar os dados coletados para que eles sejam utilizados em seus procedimentos. O problema é que muitas empresas acreditam que apenas armazenar esses dados lhes garante toda a informaçăo necessária. Entretanto, muitos dos dados guardados săo sub-utilizados, e na maioria das vezes nunca mais serăo acessados.
Como modeladores e gerentes de bases de dados, é importante que nós analisemos esse panorama: esforço humano e gasto em armazenamento para coletar e guardar um volume crescente de dados que na maioria năo serăo utilizados novamente. O problema năo está em guardar esses dados, que de fato ocultam muita informaçăo útil mas sim, em năo termos mecanismos apropriados para analisá-los. Daí a necessidade de utilizaçăo de técnicas automatizadas, ou ao menos semi-automatizadas que possibilitem recuperar informaçőes relevantes.
Algumas análises podem ser obtidas nos sistemas de gerenciamento de bancos de dados (SGBDs) através de consultas SQL. Um exemplo típico é: “Quais săo os produtos vendidos em uma concessionária de veículos que realizaram uma margem de lucro acima de 30%?”.
Por outro lado, se o interesse do gerente da concessionária é saber qual o relacionamento entre as vendas de diferentes produtos, outros tipos de consultas deveriam ser feitas. Exemplificando, constataçőes do tipo: “Quando o cliente troca o filtro de gasolina, existe uma probabilidade de 80% dele também trocar o filtro de ar”, poderiam ser levantadas se as tabelas de dados fossem exploradas por procedimentos estatísticos de análise. Complicando um pouco mais, uma informaçăo realmente estratégica para a empresa seria descobrir quais săo todos os pares de produtos que freqüentemente (mas nem sempre) săo comprados juntos, ou melhor, com poucos dias de separaçăo entre uma compra e outra. Veja que é possível existir muitos pares que ocorrem com freqüęncia sem que seja intuitivo descobri-los. Embora essa informaçăo esteja na base de dados, ela está ocultada pelo grande volume de dados armazenados, e desenvolver um procedimento de análise para identificá-la năo é uma tarefa trivial.
Neste contexto, esse artigo apresenta uma ferramenta para exploraçăo visual de dados denominada FMDB (FastMap in Databases).
A Ferramenta FMDB
O FMDB é uma ferramenta para exploraçăo visual de dados que utiliza a técnica FastMap para efetuar o mapeamento entre itens de dados quaisquer (espaciais, categóricos ou mesmo métricos) para um espaço euclidiano (ver nota 1). Para isto, é necessário que haja uma funçăo de distância (ver nota 2) definida sobre esses dados. No entanto, nem todo espaço é euclidiano, o que implica na necessidade de mapeamento. Por exemplo, se vocę estiver numa cidade em que todas as ruas săo quarteirőes, a distância mais próxima para ir a algum lugar a partir de onde vocę está năo é um caminho reto, mas a soma de cada trecho caminhado. Outro exemplo é quando uma coordenada năo tem valores contínuos, mas discretos, como o cargo de funcionários de uma empresa (săo atributos categóricos).
Nota 1
Um espaço euclidiano é aquele que estamos acostumados, com tręs dimensőes – altura, largura e profundidade – e onde a distância mais curta entre dois pontos é um caminho reto.
Nota 2
A funçăo de distância é responsável por calcular quăo semelhantes săo dois objetos através da análise de seus atributos e, a partir deste cálculo, gerar uma distância no espaço euclidiano entre eles. Os atributos utilizados pela funçăo de distância podem ser quaisquer dados: numéricos (contínuos ou discretos), datas (considerando a contagem de dias a partir de uma data-referęncia), dados similares (por exemplo, que cargo é mais parecido: um gerente e um diretor, ou um gerente e um manobrista?) ou textuais (considerando a funçăo Ledit, a qual indica o número mínimo de caracteres inseridos, removidos ou substituídos para transformar uma palavra em outra. A diferença entre ‘gato’ e ‘rato’ é um, pois a troca de uma letra muda uma em outra, e a diferença entre gato e garfo é dois, pois troca-se uma letra e insere-se outra). Por exemplo, uma funçăo de distância que envolva os atributos {preço, código} usa a diferença entre o valor numérico de preço e a diferença Ledit de código para definir quăo diferentes săo dois dados armazenados. Estes dados ainda podem ser ponderados, normalizados, e/ou utilizados em escala linear ou logarítmica. A funçăo de distância criada é entăo utilizada para indicar o relacionamento entre os itens de dados, guiando a geraçăo de um gráfico em tręs dimensőes.
Suponha que vocę queira verificar se existe uma tendęncia entre o tempo de permanęncia de um empregado na empresa e seu salário. Como o tempo de permanęncia e o salário săo números contínuos, vocę pode traçar a curva de tempo de permanęncia versus salário, e provavelmente vai perceber que com o aumento do tempo, o salário tende a aumentar. E se vocę quiser ver o relacionamento entre salário e cargo? Como cargo năo é um valor contínuo (mas categórico), o máximo que se pode fazer é traçar gráficos de barras, tortas etc. Mas, e se vocę quiser cruzar isso com o tempo de permanęncia? E com outros fatores? O objetivo do FMDB é justamente imaginar que cada atributo pode ser tratado como uma coordenada em algum espaço e mapear esse espaço para um espaço euclidiano tri-dimensional. Com isso podemos usar nossa habilidade de interpretaçăo visual para analisar os dados que as empresas armazenam e descobrir, minerar visualmente, a informaçăo oculta. Assim, o FMDB permite ao analista perceber como os itens de dados estăo relacionados, quais săo os padrőes envolvidos e detectar agrupamentos e elementos de exceçăo.
Nota
O FMDB está sendo desenvolvido em uma parceria entre o Laboratório de Bases de Dados e Imagens (GBdI) coordenado pelo Prof. Caetano Traina Jr. do Departamento de Cięncias de Computaçăo e Estatística da USP no Campus de Săo Carlos, SP; e o Database Group coordenado pelo Prof. Christos Faloutsos da Carnegie Mellon University, em Pittsburgh, Pennsylvania, nos EUA.
Visualizaçăo de Dados
A ferramenta FMDB utiliza a técnica FastMap, proposta originalmente pelo Prof. Faloutsos (Faloutsos & Lin 1995), que efetua o mapeamento entre itens de dados quaisquer (espaciais, categóricos ou mesmo métricos) para um espaço euclidiano (visual), desde que haja uma funçăo de distância definida sobre esses dados.
Nota
A técnica FastMap foi apresentada ŕ comunidade cientifica em Faloutsos, C. and K.-I. D. Lin (1995). FastMap: A Fast Algorithm for Indexing, Data Mining and Visualization of Traditional and Multimedia Datasets. ACM International Conference on Data Management (SIGMOD), San Jose, CA, ACM Press. Vale destacar que a SIGMOD (Special Interest Group in Management Of Data) é a principal conferęncia em banco de dados da ACM (Association for Computing Machinery).
Na ferramenta FMDB, o algoritmo FastMap é utilizado de maneira que um dado conjunto de informaçőes n-dimensional, onde n é o número de atributos da tabela, tenha seu número de dimensőes reduzido para 3, garantindo que cada dimensăo resultante seja contínua. De maneira geral, a utilizaçăo básica da ferramenta FMDB corresponde ŕ execuçăo dos seguintes passos:
1- Escolher uma base de dados relacional;
2- Definir as tabelas da base que serăo utilizadas no processo de análise;
3- Selecionar os atributos que irăo compor a visualizaçăo;
4- Definir os parâmetros da visualizaçăo (cores etc.);
5- Observar e interagir com a visualizaçăo resultante.
Para exemplificarmos o uso da ferramenta, utilizamos dados de domínio público que estăo disponíveis em:
· Machine Learning Repository da Universidade da Califórnia em Irvine (ftp://ftp.ics.uci.edu/pub/machine-learning-databases/breast-cancer-wisconsin) Neste local estăo disponíveis diversos conjuntos de dados. Aqui utilizamos o conjunto BreastCancer, que guarda 11 atributos de exames de pacientes com suspeita de câncer de mama obtidos no Hospital Universitário da Universidade of Wisconsin, Madison.
· Câmara dos Deputados: dados colhidos como resultado de 15 votaçőes realizadas entre 20/03/2002 e 18/06/2002 pelos deputados federais no Congresso Nacional (http://www.camara.gov.br/internet/plenario - variando de lv1760 a lv1781). Deve-se escolher “ Resultado da votaçăo eletrônica e lista de presença” e depois escolher as votaçőes de cada data desejada.
Para facilitar a criaçăo dos exemplos os dois bancos de dados, no formato Paradox, estăo disponíveis para download no site da revista.
A seguir percorreremos cada um dos 5 passos colocados acima, lembrando que se pode retornar aos passos anteriores a qualquer momento da execuçăo do FMDB.
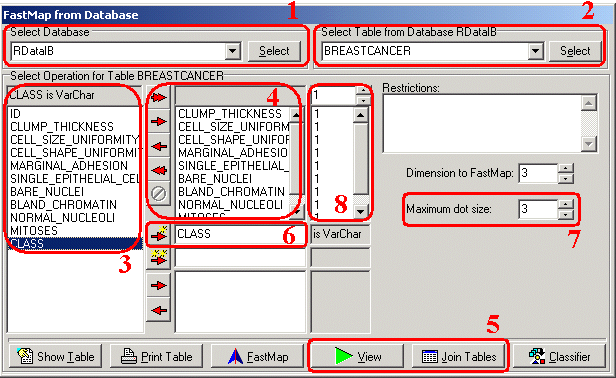
Figura 1. Interagindo com a janela principal do FMDB.
Passo 1 - Escolha de uma base de dados
A Figura 1 mostra a tela principal do FMDB. Ela guia o usuário na execuçăo dos primeiros passos na utilizaçăo da ferramenta. Inicialmente, uma lista das conexőes com bases de dados registradas no BDE ou ODBC é apresentada ao usuário (destaque 1 na Figura 1).
Passo 2 - Definiçăo das tabelas da base que serăo utilizadas
Depois que a base de dados é escolhida, uma lista de todas as suas tabelas é apresentada e uma tabela base é entăo escolhida pelo usuário (destaque 2 na Figura 1), neste caso, a BreastCancer. A tabela base é aquela que centralizará os processos de visualizaçăo que serăo efetuados. A partir dela, outras tabelas podem ser acessadas desde que tenham uma ligaçăo de chave estrangeira com ela (ou com outras já ligadas), gerando uma tabela de trabalho denominada tabela operacional.
Passo 3 - Seleçăo dos atributos para compor a visualizaçăo
Neste passo, os atributos da tabela (disponíveis no destaque 3 da Figura 1) săo selecionados para fazerem parte do conjunto de atributos que devem ser usados para criar a visualizaçăo (destaque 4 da Figura 1). Além de selecionar atributos da tabela base, também é possível selecionar atributos resultantes de comandos “GROUP BY” usando sum, min, max, avg e count.
A ferramenta FMDB permite que o usuário prossiga incluindo tabelas adicionais para compor a tabela operacional que poderá entăo ser mapeada/visualizada. A opçăo de junçăo está disponível por meio do botăo “Join tables” (destaque 5 da Figura 1).
Passo 4 - Definiçăo dos parâmetros da visualizaçăo
Nesta ferramenta, cada linha da tabela base é representada através de um ponto. Neste passo o analista escolhe como (por exemplo, cor e formato) ele quer que os pontos representem os dados que sejam de seu interesse. Uma opçăo interessante é escolher um dos atributos disponíveis como “classificador” (destaque 6 da Figura 1), fazendo com que linhas pertencentes a diferentes classes sejam representadas em diferentes cores e formatos na visualizaçăo.
Da mesma maneira, um atributo pode ser selecionado como referęncia para o tamanho dos pontos visualizados. Ou seja, tendo definido um atributo como base, o tamanho dos pontos na tela irăo variar de acordo com diferença existente entre o atributo de um determinado ponto e o valor do atributo base. A escala de variaçăo de tamanho é baseada no valor definido pelo usuário no campo “Maximum dot size” (destaque 7 da Figura 1).
Como o mapeamento dos objetos da base para o espaço cartesiano é realizado através da distribuiçăo de distâncias entre os mesmos, é importante definir a funçăo de distância para os objetos e atribuir a cada atributo pesos variados. Isso é feito através dos controles marcados no destaque 8 da Figura 1. A tela principal mostra apenas o peso atribuído a cada atributo selecionado. Clicando-se no peso de um dado atributo com o botăo direito, abre-se uma janela específica para tratar das opçőes desse atributo (Figura 2). Através dessa janela, o usuário pode indicar que um atributo é mais importante do que outros, aumentando seu peso (destaque 1 da Figura 2), ou vice-versa. Também é possível realizar outras operaçőes sobre os valores de um determinado atributo, como por exemplo, compensar variaçőes muito grandes das faixas de valores, trabalhando seu logaritmo (destaque 2 da Figura 2). A definiçăo da funçăo de distância para os objetos é realizada conforme o destaque 3 da Figura 2. As opçőes săo as funçőes padrăo Euclidiana, Manhattan (que corresponde a distância em quarteirőes), distâncias de projeçőes (Chebychev), ou mesmo funçőes definidas pelo usuário.
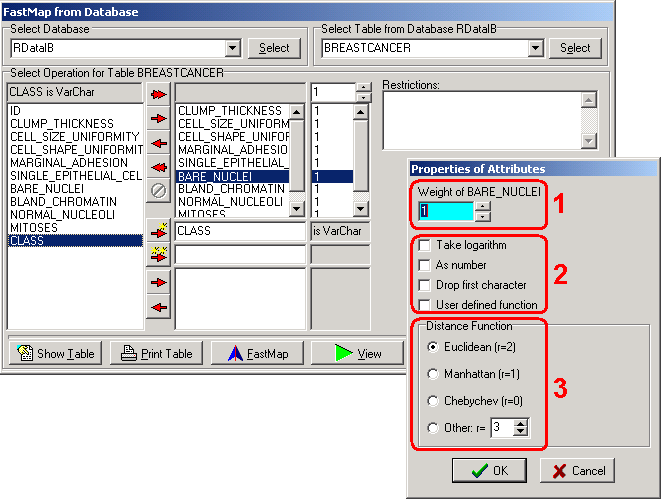
Figura 2. Janela de propriedades do atributo BARE_NUCLEI.
Passo 5 - Visualizaçăo interativa do resultado
Terminado o passo 4, é possível visualizar os dados por meio do botăo “View” (destaque 5 da Figura 1). No exemplo da Figura 3 foram escolhidos 9 atributos dos 11 existentes. É importante ressaltar que, graças ao algoritmo FastMap, todos os atributos contribuem para a composiçăo das 3 dimensőes finais, e neste exemplo onde o peso foi mantido igual a 1 para todos os atributos, os nove atributos contribuem da mesma maneira. Sem realizar reduçăo de dimensionalidade, só poderíamos visualizar 3 atributos por vez e năo seria possível ter uma idéia global do conjunto de atributos sem utilizar cálculos complexos e custosos.
A janela do módulo visualizador da ferramenta é mostrada na Figura 3. A visualizaçăo gerada pode ser explorada e manipulada interativamente através de translaçăo, rotaçăo e escala.
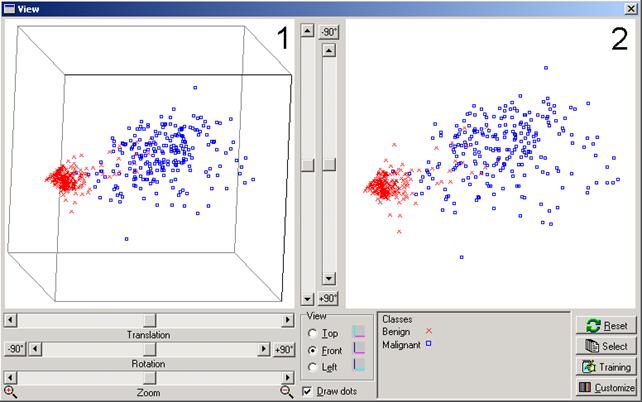
Figura 3. Explorando a visualizaçăo dos dados da tabela breastcancer.
O módulo visualizador é composto basicamente de duas apresentaçőes: visualizaçăo estática dos dados mapeados (janela 1 da Figura 3) e visualizaçăo dos dados transformados pelo processo interativo (janela 2 da Figura 3). A primeira janela apresenta um cubo tridimensional que delimita os pontos mapeados mostrados na segunda visualizaçăo. Através de movimentos de rotaçăo, translaçăo e escala realizadas com o mouse sobre esse cubo, o usuário pode observar a nova disposiçăo dos dados e assim analisá-los sob diferentes ângulos, posicionamentos e aproximaçőes.
A Figura 3 apresenta a visualizaçăo dos dados de exames de pacientes com suspeita de câncer de mama do conjunto BreastCancer, considerando o atributo CLASS como classificador. A ferramenta atribui automaticamente uma cor e um formato de ponto para cada classe, e indica qual cor e formato representa cada classe na legenda “Classes” disponível logo abaixo na janela de visualizaçăo. Se quiser, o usuário pode clicar no botăo “Customize” ao lado dessa janela e escolher outra cor ou formato para os pontos. A visualizaçăo resultante permite a identificaçăo de pelo menos um agrupamento bem definido, que é aquele dos exames que foram classificados como benignos (em vermelho na Figura 3), e podem ser usados para ajudar a classificar um novo resultado. Por exemplo, se mapearmos os resultados de um novo exame, já poderíamos ter uma boa idéia para classificá-lo como benigno ou maligno apenas olhando onde ele seria representado.
Em alguns casos é interessante identificar um determinado ponto ou subconjunto de pontos da visualizaçăo, tal como obter a identificaçăo do paciente correspondente a um determinado ponto no espaço visualizado. Esta funcionalidade está disponível por meio do botăo Select (destaque 1 da Figura 4).
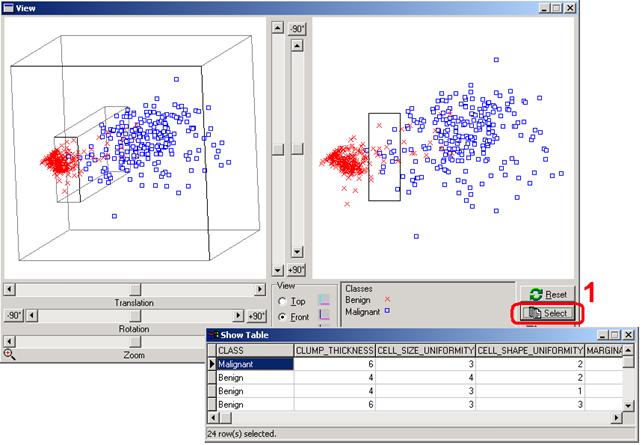
Figura 4. Efetuando o mapeamento inverso a partir da visualizaçăo.
Agora analisaremos o conjunto de dados referentes ŕs votaçőes da Câmara dos Deputados realizadas entre 20/03/2002 e 18/06/2002, considerando apenas os deputados presentes. Aqui usamos o partido de cada deputado como o atributo classificador. Assim, cada deputado aparece como um ponto na cor e forma associada ao seu partido. Pelos resultados apresentados pelo FMDB, pode-se analisar questőes como coesăo partidária e até mesmo reconhecer quais deputados năo estăo votando conforme a orientaçăo de seus partidos.
Para gerar a visualizaçăo mostrada na Figura 5, foi solicitado que se visualizasse somente os resultados de votaçőes dos partidos PFL (elementos verdes), PSDB (elementos azuis) e PT (elementos vermelhos). Pode-se observar que grande parte dos congressistas petistas está agrupada e separada dos congressistas pefelistas e psdbistas. Porém, alguns petistas estăo mais afastados de seu grupo e há mesmo até alguns poucos que se comportam como os congressistas do PFL e PSDB. Note que essa figura é calculada geometricamente, utilizando uma expressăo matemática que se baseia exclusivamente no voto que cada deputado deu para cada uma das 15 matérias votadas no período em questăo. Năo existe aqui nenhuma interferęncia proveniente de fatores subjetivos.
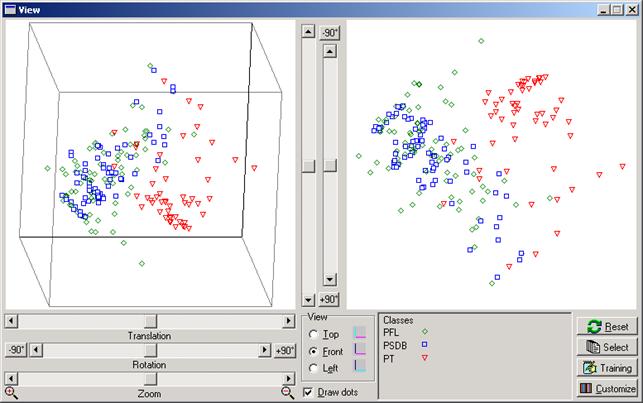
Figura 5. Explorando a visualizaçăo dos dados da tabela PolíticosBR para os partidos ‘PT’, ‘PSDB’ e ‘PFL’.
Como esta ferramenta é voltada fundamentalmente para a análise interativa dos dados, existem muitas opçőes que o analista pode usar para explorá-los. Por exemplo, outros partidos políticos poderiam ser escolhidos e comparados. Poder-se-ia dar pesos diferentes para cada um dos diversos assuntos votados, ou escolher outros conjuntos de leis, ou mesmo estabelecer regras para trabalhar com estatísticas que envolvessem cada deputado e seu suplente, além de outras possibilidades. Pode-se também trabalhar com sub-conjuntos de pontos (deputados), e analisar cada grupo separadamente. Obviamente, cada um dos “pontos” pode ser identificado pelo nome do respectivo deputado.
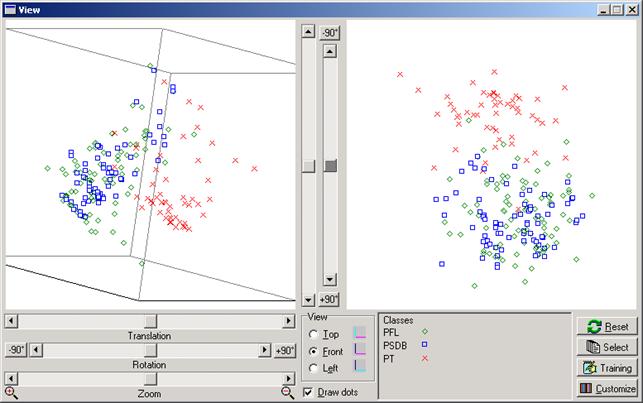
Figura 6. Alterando dinamicamente a visualizaçăo dos dados da tabela PolíticosBR para os Partidos ‘PT’, ‘PSDB’ e ‘PFL’.
Entre outras opçőes disponíveis na ferramenta, é possível também acompanhar todas as sentenças SQL e os parâmetros passados por ela (menu “Tools”, item “Show SQL”). Assim, profissionais de informática podem verificar as consultas que a ferramenta faz na base de dados.
Conclusăo
Os testes efetuados até aqui no FMDB tęm sido motivantes a partir do momento que ele tornou possível a descoberta de algumas informaçőes nos dados que anteriormente năo haviam sido sequer cogitadas.
A ferramenta é free e ainda está em desenvolvimento. Atualmente está sendo construído um novo módulo que permitirá a análise de dados que mudam com o tempo. Isso facilitará acompanhar a evoluçăo dos dados que estejam sendo coletados.
A versăo atual e seu manual estăo disponíveis na seçăo de downloads no site do Grupo de Bases de Dados e Imagens do ICMC/USP em http://gbdi.icmc.usp.br, onde também serăo mantidas as novas versőes.
Prof. Dr. Caetano Traina Júnior (caetano@icmc.usp.br) é Professor Associado (livre-docente) do Departamento de Cięncias de Computaçăo do ICMC-USP e pesquisador na área de banco de dados. Seus interesses incluem o suporte a dados năo convencionais em bancos de dados, tais como imagens, áudio e séries temporais, bem como técnicas de mineraçăo de dados e suporte informacional a aplicaçőes da área médica. Realizou estágio de pós-doutoramento na Carnegie Mellon University, é autor de mais de 140 publicaçőes nacionais e internacionais na área de banco de dados, e já orientou mais de 30 trabalhos de mestrado e doutorado.
Profa. Dra. Agma Juci Machado Traina (agma@icmc.usp.br) é Professora Associada (livre-docente) do Departamento de Cięncias de Computaçăo do ICMC-USP e pesquisadora na área de Processamento de Imagens e Indexaçăo de Dados Multimídia. Seus interesses incluem o tratamento de imagens de exames médicos e sistemas de visualizaçăo de dados científicos, bem como mineraçăo de dados multimídia e aplicaçőes na área médica. Realizou estágio de pós-doutoramento na Carnegie Mellon University, é autora de mais de 120 publicaçőes nacionais e internacionais na área de Imagens e Banco de Dados, e já orientou mais de 15 trabalhos de mestrado e doutorado.
Humberto Razente (hlr@icmc.usp.br) é responsável pela manutençăo dos sistemas computacionais do Laboratório de Banco de Dados e Imagens do Departamento de Cięncias de Computaçăo do ICMC-USP e pelo suporte ŕ construçăo de aplicativos envolvendo bancos de dados, imagens e mineraçăo de dados. Atualmente está engajado em programa de mestrado no ICMC-USP.
Ms. Maria Camila Nardini Barioni (mcamila@icmc.usp.br) é aluna de doutorado do Programa de Pós-Graduaçăo em Cięncias de Computaçăo e Matemática Computacional do ICMC-USP. Seus interesses incluem o acesso a dados năo convencionais em bancos de dados e mineraçăo de dados, incluindo técnicas de realimentaçăo de interesse para navegaçăo e visualizaçăo de grandes volumes de dados multimídia.

