Os artigos dessa ediçăo estăo disponíveis somente através do formato HTML.

Clique aqui para ler todos os artigos desta ediçăo
TreeMiner: Uma Ferramenta para Exploraçăo Visual de Dados
O avanço da tecnologia tem proporcionado a empresas e organizaçőes acumularem uma quantidade significativa de dados armazenados eletronicamente. Mas a posse destes dados năo se traduz imediatamente em posse de informaçőes úteis. Para isso săo necessárias técnicas e ferramentas que os explorem de forma eficiente. Foi justamente com esta finalidade que surgiu a área de estudo denominada Descoberta de Conhecimento em Bases de Dados (KDD – Knowledge Discovery in Databases). KDD pode ser definido como o processo de extraçăo de informaçăo útil, năo trivial e previamente desconhecida de bases de dados. A fase mais importante do KDD é a mineraçăo de dados e é nesta fase que informaçăo útil é efetivamente extraída dos dados.
Dentre as técnicas de mineraçăo de dados, a exploraçăo visual de dados é a mais intuitiva por usar a habilidade humana de rapidamente interpretar imagens. Assim, técnicas de exploraçăo visual mapeiam dados em imagens a fim de permitir a interpretaçăo dos dados. No universo de tipos de dados, as estruturas hierárquicas de informaçăo săo bastante comuns. Estruturas de diretórios, estruturas organizacionais e árvores genealógicas săo alguns exemplos.
Neste contexto, este artigo apresenta uma ferramenta de exploraçăo visual de dados hierárquicos baseada em mapas em árvore chamada TreeMiner. O sistema é importante pois trabalha em uma área da computaçăo muito recente e ainda pouco explorada. Os algoritmos e o conceito da ferramenta săo estudados por centros de excelęncia em computaçăo no mundo, como a Universidade de Maryland (http://www.cs.umd.edu/hcil/treemap/). Posso colocar também a Microsoft no grupo de instituiçőes que pesquisam sobre o assunto (http://netscan.research.microsoft.com/treemap). Além disso o TreeMiner se aplica a casos reais como bolsas de valores, análise de tráfego em redes, centros educacionais dentre outros.
Nota
O TreeMiner foi desenvolvido por este autor sob orientaçăo do Prof. Manoel Mendonça como parte da dissertaçăo de mestrado na Universidade Salvador (www.unifacs.br), com o apoio do fundo de amparo a pesquisa da Eletrobrás.
Visualizaçăo de Informaçőes
Como vimos, a visualizaçăo de informaçőes é um dos mecanismos que podem ser utilizados para descoberta de informaçăo útil em um conjunto de dados. Para exemplificar este conceito, a Figura 1 apresenta um padrăo em formato tabular. Para maioria das pessoas este padrăo é de difícil detecçăo. A Figura 2 mostra o mesmo padrăo em um formato gráfico. Neste caso, o padrăo pode ser facilmente interpretado.

Figura 1. Dados apresentados na forma tabular.
É importante notar, todavia, que padrőes simples como o mostrado na Figura 2 năo săo comuns. Padrőes de interesse săo geralmente complexos e variam em diversas dimensőes.
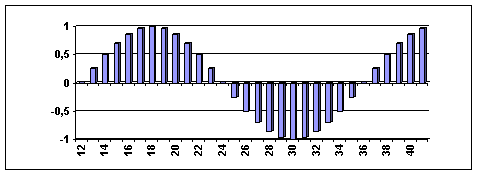
Figura 2. Dados apresentados de forma gráfica.
Exploraçăo visual de dados hierárquicos
Dados hierárquicos săo bastante comuns e a aplicaçăo de técnicas de mineraçăo visual de dados ajudam a extrair informaçőes úteis deles. A forma mais comum de representaçăo visual de estruturas hierárquicas é através de árvores usando linhas (ver Figura 3). Entretanto, esta possui duas grandes desvantagens: (1) uma grande porçăo do espaço visual disponível é gasto na organizaçăo dos nós; e (2) estruturas hierárquicas grandes geram árvores de difícil visualizaçăo. Poderíamos considerar o exemplo mostrado na Figura 3 como uma estrutura de pastas. As folhas representariam os arquivos com seus respectivos tamanhos e os nós pai, as pastas com soma de todos os tamanhos dos arquivos e de sub-pastas.
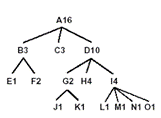
Figura 3. Desenho de uma árvore usando linhas.
O Mapa em Árvore é um método de visualizaçăo de preenchimento de espaço utilizado em estruturas hierárquicas. Ele utiliza todo o espaço disponível para visualizaçăo das informaçőes, mapeando a hierarquia em regiőes retangulares, como mostrado na Figura 4.
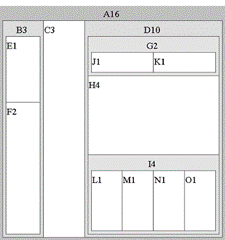
Figura 4. Um Mapa em Árvore para a Figura 3.
Como mostrado na Figura 4, ele pode ser usado para fazer com que os nós que contenham informaçőes de maior importância sejam colocados em regiőes maiores que aqueles de menor importância. Isto permite aos usuários comparar os tamanhos dos nós e das sub-árvores, ajudando a mostrar padrőes hierárquicos incomuns. O algoritmo usado para desenhar os retângulos nesta figura é o cortar e fatiar, criado por Ben Shneiderman da universidade de Maryland, nos EUA. Ele alterna cortes verticais e horizontais na tela para cada nível da hierarquia. Assim, as orientaçőes das linhas săo trocadas ŕ medida que descemos na estrutura hierárquica. Entretanto, este método tem uma deficięncia, ele pode criar um desenho com altas razőes de aspecto, ou com retângulos muito longos e finos que podem ser difíceis de ver, selecionar, comparar em tamanho e rotular (ver Figura 5a).
Neste contexto, existem outros algoritmos que desenham os retângulos com melhor visualizaçăo. Săo eles: aglomerado (Figura 5b), quadriculado (Figura 5c), pivô pelo meio (Figura 5d) e pivô por tamanho (Figura 5e). Esses algoritmos criam visualizaçőes mais claras da hierarquia melhorando a visualizaçăo de itens menores. Os Mapas em Árvore aglomerados e quadriculados, criados por Huizing Bruls e J. van Wijk, e os algoritmos pivô por tamanho e pivô por média, criados por Ben Shneiderman e Martin Wattenberg, reduzem bastante a relaçăo de aspecto. Cada um deles com uma particularidade.
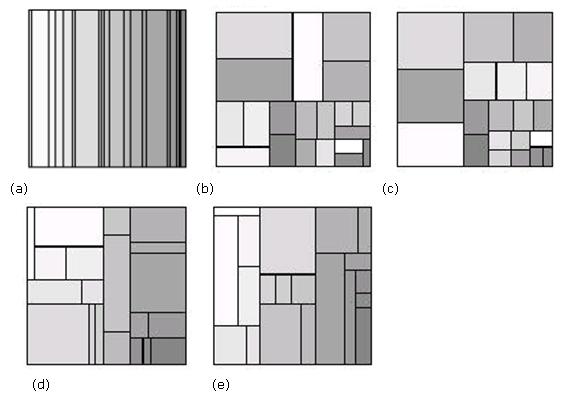
Figura 5. Representaçăo de um mesmo nível hierárquico utilizando o cortar e fatiar (a), aglomerado(b), quadriculado (c), pivô pelo meio(d) e pivô por tamanho(e).
O TREEMINER
O TreeMiner é uma ferramenta para exploraçăo visual de dados baseada em mapas em árvores. Ela foi desenvolvida com objetivo inicial de representaçăo e manipulaçăo de dados do sistema energético brasileiro. Para isto, ela combina o uso de imagens baseadas em mapas em árvore com recursos para consulta interativa e detalhamento sobre demanda dos dados sendo explorados. Sua arquitetura é composta de quatro módulos (ver Figura 6): entrada de dados, apresentaçăo visual, controle de consulta e controle de atributos visuais.
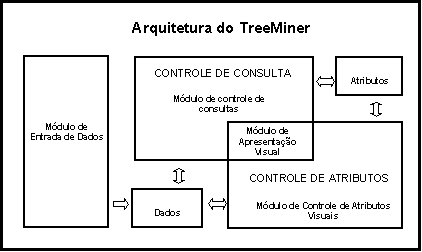
Figura 6. Arquitetura do aplicativo.
Este módulo permite a integraçăo da ferramenta com os mais variados tipos de fontes de dados. Desta forma é possível acessar arquivos CSV, bancos de dados relacionais, servidores de documentos e estruturas de diretórios.
Este módulo é responsável por apresentar o modelo dos itens da hierarquia em mapas em árvore e fornecer meios de exploraçăo desse modelo. No TreeMiner, foram implementados dois algoritmos de desenho de mapas em árvore: o cortar e fatiar e o quadriculado. O destaque 1 da Figura 7 mostra uma visualizaçăo utilizando o algoritmo quadriculado.
No exemplo da Figura 7 temos cada usina representada por um retângulo azul sendo sua área proporcional ŕ sua potęncia em MW (Megawatt). A unidade federativa (UF) está representando o primeiro e único nível na hierarquia, que é percebido através dos agrupamentos de retângulos pelas bordas em cinza, mostrando dessa forma quais usinas estăo em uma mesma unidade federativa.
Com o objetivo de facilitar e detalhar a exploraçăo do modelo visual săo oferecidas outras funcionalidades como zoom, dicas textuais, rótulos, detalhamento completo dos atributos de um registro de dados, controle de exibiçăo de níveis e escolha da hierarquia.
Módulo de controle de consultas
Os controles de consultas săo componentes visuais que permitem a execuçăo de operaçőes de seleçăo sobre o conjunto de dados sendo manipulado (ver destaque 2 da Figura 7). Para isto, para cada atributo é criado um controle que possui os valores que estes podem assumir.
Módulo de controle de atributos visuais
Este módulo define as características das estruturas visuais do modelo, tais como: o ajuste do tamanho dos retângulos, das cores que representarăo os atributos e a formaçăo dos agrupamentos com a escolha da hierarquia dos dados. Além disso, é responsável por vários outros detalhes visuais como a largura das bordas entre os conjuntos e a cor que representa um filtro nos dados.
Veremos a partir de agora como estes módulos em conjunto permitem a extraçăo de informaçăo útil a partir de uma base de dados.
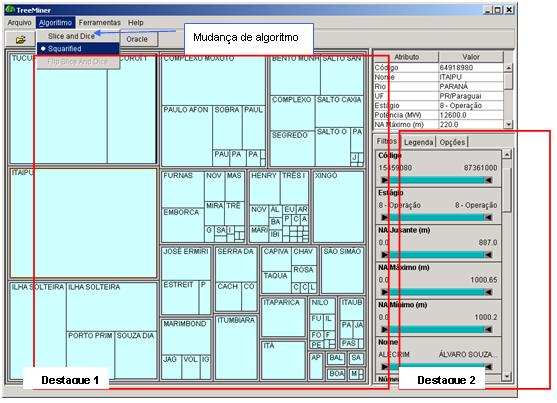
Figura 7. Imagem geral do TreeMiner com o uso do algoritmo quadriculado exibindo informaçőes sobre usinas hidrelétricas brasileiras.
Conhecendo o TreeMiner
Os dados utilizados neste exemplo săo projeçőes que indicam as possíveis necessidades de geraçăo térmica convencional para os próximos 5 anos das usinas que operam em regime complementar para o Sistema Nacional Interligado (SIN). Foram coletados e montados em uma tabela a média anual de utilizaçăo da usina, o ano da análise, o subsistema do qual a usina faz parte (Sudeste/Centro Oeste, Sul, Nordeste), tipo de combustível, custo por MW, potęncia, produçăo máxima, produçăo mínima, nome, dentre outros.
Essa tabela foi entăo colocada no formato CSV. Este é um arquivo de texto puro em que cada linha representa um registro de dados e cada campo desse registro é separado por uma vírgula ou ponto-e-vírgula (ver Figura 8).

Figura 8. Formataçăo dos dados em arquivo CSV.
Tendo estes dados, devemos abri-los no TreeMiner. Como este tipo de entrada năo possui uma hierarquia pré-definida e o software é baseado na utilizaçăo de árvores para a visualizaçăo dos dados, é obrigatória a definiçăo dos atributos que especificam a hierarquia. Por exemplo, poderíamos escolher o ano para representar o primeiro nível da hierarquia, e sistema, o segundo. Neste caso, estaríamos dividindo os registros em conjuntos que possuam o mesmo ano e em cada um dos subconjuntos de ano classificando a usina por subsistema ao qual ela faz parte. A Figura 9 apresenta a interface onde é configura a hierarquia dos dados. Neste exemplo, definimos a hierarquia ano-subsistema-combustível.
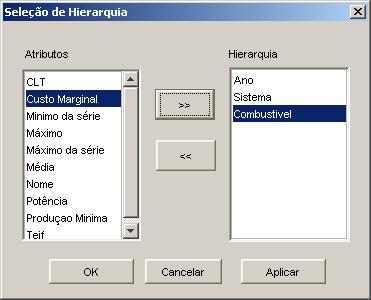
Figura 9. Escolha da hierarquia
Os dados poderăo entăo ser visualizados (ver Figura 10). Como variável de dimensionamento foram usados os atributos “produçăo mínima” e “produçăo máxima”. Esta variável servirá para calcular o tamanho dos retângulos projetados na tela. E como variável de coloraçăo foi utilizado o atributo “custo marginal”, partindo da cor branca representando o menor custo até a cor vermelha representando o maior custo. Em conjunto, as variáveis de dimensionamento e coloraçăo săo uma poderosa ferramenta para a descoberta de informaçőes úteis em bases de dados. A escolha dessas variáveis săo feitas através da aba Legendas como mostrado na Figura 11.
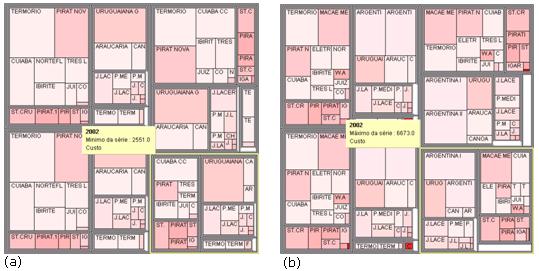
Figura 10. Visualizaçăo dos dados do setor energético: produçăo mínima (a) e produçăo máxima (b) ao longo de 4 anos de previsăo.
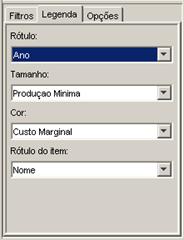
Figura 11. Definiçăo do comportamento dos atributos.
A partir desta visualizaçăo pode-se perceber a distribuiçăo das produçőes mínimas e máximas nos subsistemas (pelo tamanho dos retângulos) e quais usinas serăo responsáveis pelas maiores geraçőes no decorrer dos anos. Assim, torna-se mais fácil perceber também quais usinas possuem probabilidade de serem acionadas ou desativadas primeiro de acordo com seu custo e capacidade de produçăo. Um exemplo: as usinas com tamanhos menores e cores mais vermelhas devem ser desativadas primeiro pois săo caras e produzem pouca energia. Já as maiores e mais claras devem ser acionadas primeiro pois produzem muita energia a um custo mais baixo.
Além disso, é possível perceber facilmente a distribuiçăo da geraçăo de energia por tipo de combustível utilizado e por custo marginal de operaçăo. Neste contexto, um outro exemplo seria a análise com base na emissăo de CO2. Esta análise demonstraria quais usinas deveriam ser desativadas ou terem diminuídas sua geraçăo, na hipótese de entrada de usinas que reduzam ou năo emitam gases de efeito estufa.
Representando a quantidade de emissăo de CO2 pelo tamanho, como mostrado na Figura 12, pode-se identificar quais subsistemas apresentam maior potencial de emissăo.

Figura 12. Visualizaçăo dos dados do setor energético. Mostra a quantidade de CO2 emitido por cada usina (verde – gás, azul – óleo, vermelho – carvăo).
Conclusăo
O TreeMiner, apesar de ter sido criado com o objetivo de analisar dados do setor energético, possui capacidades que o torna bastante abrangente. As muitas funcionalidades de manipulaçăo e detalhamento do modelo visual permitem que ele seja utilizado de forma bastante eficiente em diferentes domínios de aplicaçăo.
Para confirmar sua utilidade, foram feitos alguns estudos de caso no TreeMiner. Ele se mostrou útil na análise de dados do setor energético, em especial a produçăo de energia e emissăo de gases por usinas termelétricas. Ajudou também a explorar visualmente um repositório de documentos, além da análise de tráfego dos serviços e detecçăo de comportamentos incomuns em redes de computadores.
Embora o TreeMiner năo esteja disponível para download, os leitores poderăo ter um noçăo prática de como a técnica funciona acessando o site www.smartmoney.com/marketmap, e através do site http://www.cs.umd.edu/hcil/treemap/ (site oficial da técnica), onde atualmente é disponibilizada uma ferramenta com recursos e usabilidade bastante semelhantes ao TreeMiner (ver Figura 13).
Por fim, aos leitores mais curiosos, existe uma documentaçăo ampla sobre a técnica disponível no site oficial citado no parágrafo anterior. Boa sorte!
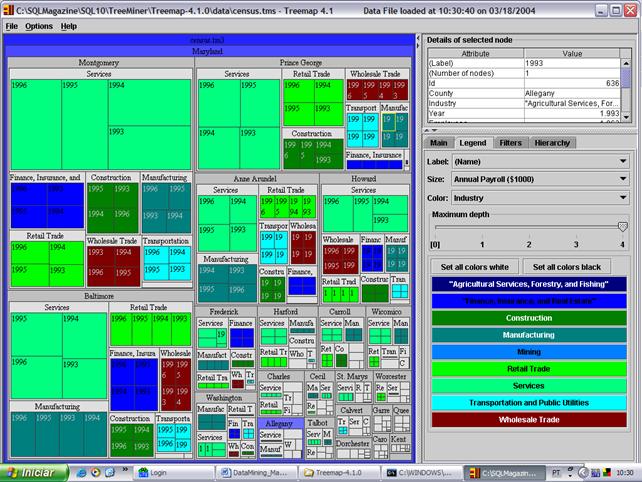
Figura 13.

