Quase toda aplicaçăo J2EE acessa dados de um banco de dados relacional. Por este motivo, o JDBC é provavelmente uma das APIs mais populares disponíveis para a plataforma Java. O JDBC é conceitualmente simples e fácil de usar, mas para aplicaçőes em produçăo, vários detalhes podem tornar o desenvolvimento do create/read/update/delete (CRUD) mais trivial em uma tarefa difícil. Embora muitos frameworks, ferramentas e APIs possam simplificar o desenvolvimento, estas săo freqüentemente muito complexas. Como uma alternativa, este artigo apresenta um pequeno conjunto de classes fáceis de usar, manter e estender.
Vocę pode estar pensando: mais uma ferramenta/assistente/API/framework para complicar nossa vida? Posso entender sua hesitaçăo: o problema de mapeamento objeto-relacional está sendo abordado faz anos. Todo mundo tem uma soluçăo que é mais fácil, melhor, mais rápida e mais barata. Para que precisaríamos de mais código que provavelmente faz o que alguém já fez? Por duas razőes: a maioria das soluçőes săo geralmente mais complicadas do que o necessário e também demandam um compromisso significativo: uma vez que entramos, é difícil cair fora.
Gosto de coisas simples. Um colega citou recentemente uma frase interessante: "A simplicidade conduz ŕ onipresença, a complexidade conduz a obscuridade". E todos tęm ouvido a citaçăo de Einstein: "Uma teoria científica deveria ser tăo simples quanto possível, mas năo a mais simples".
E esta é uma citaçăo do James Gosling: "A complexidade é de muitas formas perniciosa. A complexidade torna as coisas mais difíceis de entender, mais difíceis de construir, mais difíceis de depurar, mais difíceis de evoluir, mais difícil de fazer tudo”.
Poderia continuar. Há muitos exemplos de complexidade, muitos. No caso de acesso a banco de dados, podemos utilizar entity beans, uma ferramenta de mapeamento objeto-relacional ou o mais recente framework open source. Năo tenho reclamaçőes formais contra quaisquer uma dessas ferramentas; tenho certeza de que os autores tiveram uma grande visăo ao desenvolvę-las. Para mim, hoje, quero algo bem simples.
Voltemos um pouco no tempo. A maioria das vezes, uma aplicaçăo precisa obter informaçăo de um usuário e as criar/editar/deletar/visualizar como linhas em um banco de dados. Um detalhe importante é que a informaçăo que vai e provém do usuário deve estar na forma de strings. Isto significa que a validaçăo deve ser feita na entrada e a formataçăo na saída. Isto năo é difícil, mas é repetitivo e envolve numerosas verificaçőes desnecessárias. Outra característica importante que os usuários esperam ter é a habilidade para obter um conjunto grande de resultados ou pular para o fim de um conjunto de registros, nada fácil de obter com um ResultSet.
Uma soluçăo popular é a de manualmente ou automaticamente mapear o SQL e esquemas resultantes de tabelas para objetos e classes. No início, isto parece razoável, se năo natural. Em geral, modeladores de banco de dados e modeladores de objeto tentam realizar a mesma coisa: gerenciar a informaçăo empresarial de uma maneira lógica e extensível.
Infelizmente, a lua de mel termina por aqui. Modeladores de objetos preferem se isolar dos vários detalhes quanto a como os dados săo inseridos e recuperados. Para alguns, o banco de dados é como um grande hashmap com mais de uma chave. Esta poderia ser uma avaliaçăo precisa, mas há a necessidade de uso de SQL conhecido como table join. Peritos de banco de dados argumentam que junçőes dăo poder aos bancos de dados relacionais. Modeladores de objeto poderiam encará-los como algo que só causa mais dificuldades do que benefícios. Apesar das suas opiniőes, objetos e bancos de dados provavelmente năo irăo mudar significativamente no futuro próximo. Aplicaçőes e lógica de negócio continuarăo usando objetos, e persistęncia de dados continuará tendo a forma de um banco de dados relacional.
Barreiras culturais aparte, existem diferenças significativas entre classes/objetos e linhas/tabelas. Objetos podem incluir comportamento, o que os distingue de estruturas e outros tipos de agregados. Classes oferecem herança e polimorfismo, o que as torna reutilizáveis e extensíveis. Mas bancos de dados tęm a ver com armazenamento eficiente e procura rápida. Isso năo pode ser subestimado quando săo consideradas dezenas de milhares, se năo milhőes, de linhas de informaçăo potenciais. Esta informaçăo e o seu acesso de modo eficiente provam o quăo importante é o código que irá fazer sua manipulaçăo.
Outro detalhe importante é que classes săo fáceis de mudar e o código é freqüentemente refatorado quando for conveniente e útil. Mudar a estrutura de um banco de dados representa um problema muito maior. Mudar nomes de colunas ou mesmo criar novas tabelas e recarregar dados năo é em si mesmo um desafio, mas ajustar todo o código que suporta esta estrutura pode ser bem problemático. Por isso, tipicamente, tabelas de banco de dados mudam pouco depois que foram povoadas.
Todas estas diferenças conduziram ŕ chamada impedância de casamento, um termo relativo ao princípio de máxima potęncia de transferęncia emprestado da engenharia elétrica. Embora possamos extrair e inserir dados fácil e eficazmente em um banco de dados, os objetos que usam os dados poderiam năo se ajustar bem. O resultado típico é a ocorręncia de muitos códigos que se assemelham ŕ serializaçăo manual de objetos. Isto é tedioso e propenso a erros.
Para evitar o tédio, muitas ferramentas evoluíram no decorrer dos anos. A especificaçăo J2EE oferece um modelo na forma de container-managed entity beans e a EJB-QL (Enterprise JavaBean Query Language). Na comunidade open source, o Hibernate tem se tornado uma soluçăo popular. Estas soluçőes dependem de uma linguagem de consulta como a SQL, mas năo precisamente. O resultado é que poderíamos ter que ajustar as consultas para se ajustarem ŕ ferramenta, em lugar de utilizar o que o banco de dados é capaz de fazer por si só.
Estas podem ser soluçőes efetivas para uma ampla gama de questőes, mas ainda năo satisfazem um padrăo arbitrário de simplicidade. Dou ęnfase ŕ expressăo arbitrário, porque muitos acharăo que estas soluçőes satisfazem as exigęncias: é apenas uma diferença de opiniăo e nada mais.
Simplificando a vida do desenvolvedor
Muitos desenvolvedores com os quais trabalhei năo săo modeladores de objetos ou modeladores de banco de dados; representam uma terceira categoria de programadores. Eles se sentem igualmente confortáveis com objetos e com o SQL; săo os desenvolvedores em PowerBuilder. O PowerBuilder tem suas qualidades boas e ruins, como qualquer produto, mas em minha opiniăo, tem uma jóia: a janela de dados. Em vez de mapear toda a tabela ou resultset potencial em uma classe diferente, o PowerBuilder tem uma única classe: a janela de dados. Simplesmente falando, a janela de dados equivale a um ResultSet atualizável. Para usá-la, simplesmente emita uma consulta, qualquer consulta, năo importa o quăo complexa seja. Qualquer resultado retornado poderá ser formatado facilmente, poderá ser ordenado e poderá ser navegado em qualquer ordem. Ainda mais, quaisquer dos dados devolvidos poderăo ser modificados e ser submetidos ao banco de dados mediante uma chamada de método. A janela de dados também controla o gerenciamento de todas as chaves primárias e transaçőes.
Simplificando a vida do desenvolvedor, versăo 1
Estando já convencido de que a janela de dados pode ser uma soluçăo efetiva, comecei a escrever algo semelhante em JDBC com Java. Obtive uma soluçăo bastante completa, mas havia problemas. Um das vantagens da janela de dados é que ela administra automaticamente chaves primárias e tipos de dados de colunas. Isto reduz significativamente o trabalho do desenvolvedor. O problema com minha implementaçăo era a disponibilidade de drivers de banco de dados de alta qualidade. A implementaçăo depende pesadamente de resultsets de metadados. Estes metadados, como quaisquer outros, tais como Java Reflection e XML Schema, serăo poderosos quando for preciso. O problema é que muitos drivers, até mesmo aqueles de alta qualidade, năo retornam todos os metadados necessários. Nada na especificaçăo do JDBC exige isto dos drivers. Os métodos existem, mas năo trabalham necessariamente para todas as combinaçőes de drivers de bancos de dados.
Pelo que eu sei, o PowerBuilder também tem problemas de metadados ao utilizar o ODBC e os drivers nativos. A soluçăo é implementar drivers de banco de dados personalizados para cada banco de dados suportado para garantir funcionalidade robusta. Tolamente, desperdicei muito tempo investigando por que alguns drivers năo proviam todos os metadados. A resposta é simples: há muitos bancos de dados, muitos drivers e algumas pessoas que os desenvolvem. Provavelmente, metadados perfeitos năo estăo no topo da lista de prioridades; năo é provável que seja atingido cem por cento de suporte no futuro próximo.
Simplificando a vida do desenvolvedor, versăo 2
Tentei descobrir as necessidades de metadados na esperança de suportar os drivers de banco de dados e bancos de dados mais populares. Isto provou ser melhor, mas menos conveniente que a implementaçăo original, e alguma coisa poderia ainda ser omitida.
Concluí que talvez estivesse sendo muito preciosista. Como outros, tentei resolver o problema de forma ampla. Reduzi meu escopo para algo mais manipulável, algo simples. Decidi dar prioridade ŕs facilidades de navegaçăo, formataçăo, análise gramatical e validaçăo. Abandonei a idéia de gerenciar chaves primárias e deixei isto para o desenvolvedor. Concluí que no fim as chaves primárias năo săo a parte mais difícil do gerenciamento.
O resultado final é uma soluçăo escalável que tolera limitaçőes de drivers de banco de dados disponíveis, mas ainda é relativamente fácil de usar.
Agora na prática
Chega de introduçăo, chegou a hora de ver a implementaçăo e alguns exemplos. Veremos como o pacote pode ser usado para executar operaçőes básicas select/insert/update/delete e também para formatar e validar dados. A Figura 1 apresenta o diagrama de classes da UML para as classes responsáveis por facilitar o uso do JDBC.
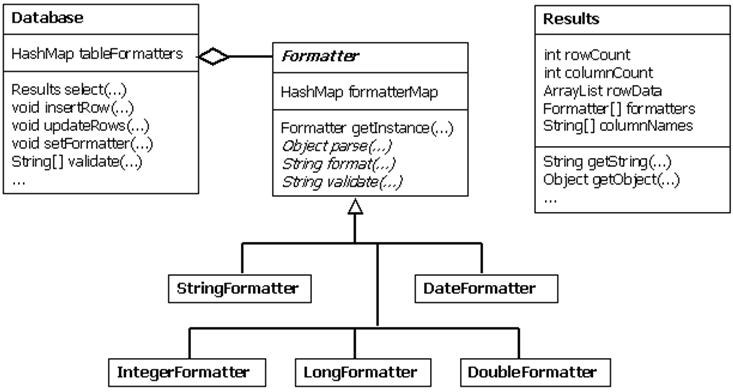
Figura 1. Diagrama UML das classes básicas.
A classe Database faz duas coisas: mantém um mapa de Formatter e implementa métodos para selecionar, inserir, atualizar e apagar linhas. Também há um método validate(), sobre o qual falarei brevemente. Formatter é uma classe abstrata que define tręs métodos: parse(), format() e validate(). Como mencionado antes, a visăo de dados dos usuários está na forma de strings, assim os formatters săo responsáveis por converter tipos de banco de dados de/para strings. Sempre é possível a inserçăo de dados inválidos, por exemplo, caracteres năo numéricos em um campo numérico, data formatada incorretamente ou strings que năo casam com um padrăo. Para cada um dos dados de coluna esperados, existe uma subclasse Formatter.
Vejamos um exemplo simples de seleçăo de dados na Listagem 1.
Connection con = getConnection();
myDB = new Database(false);
myDB.loadDefaultFormatters(con, "roles");
String[] params = {"roles.id", "99"};
Results rs = myDB.select(con, "select id,name,role from roles where id = ?", params, 10);
System.out.println("Name is " + rs.getString(0, 1));
System.out.println("Password is " + rs.getString(0, "roles.role"));Listagem 1. Exemplo de seleçăo de dados.
A primeira linha obtém uma conexăo com o banco de dados. Assumi que existem meios para obter a conexăo, a maioria das aplicaçőes o faz. Normalmente, provém de uma fonte de dados predefinida ou de uma chamada simples a DriverManager. O construtor do banco de dados possui um argumento booleano que diz ŕ instância para fechar automaticamente a conexăo depois de uma operaçăo. Como provavelmente vocę deve saber, fechar conexőes é um processo crítico e propenso a erros, portanto isto pode ser automatizado caso assim o prefira. O método loadDefaultFormatters() é um modo prático de carregar o formatter apropriado para uma determinada tabela. Este depende do método getColumnClass() em ResultSetMetaData. Possivelmente, isto poderia năo funcionar, mas em minha experięncia, este método parece funcionar com todos os bancos de dados que testei, inclusive com o Access, SQL Server, MySQL, Oracle e DB2. Alternativamente, podemos configurar o formatter para colunas específicas por nome. Provavelmente vocę desejará fazer isto em produçăo, já que o formatter padrăo năo possui muitas restriçőes de validaçăo.
Este exemplo é de um simples select. Perceba que o SQL năo é nada além do que vocę iria prover ao PreparedStatement. Na realidade, no fundo é exatamente isto, permitindo a utilizaçăo de qualquer SQL executado pelo seu banco de dados. O argumento params é um array de Strings que contem pares de nome de coluna e valor. A ordem dos parâmetros equivale a um HashMap ordenado, porém mais fácil de criar e inicializar. O nome das colunas é necessário, pois desta maneira a análise gramatical dos valores dos parâmetros poderá ser realizada corretamente.
O método select() retorna um objeto Results que equivale a um ResultSet, mas formata os resultados baseado em nomes de colunas. Se o nome de coluna năo estiver disponível, tentará utilizar o tipo da coluna. Valores para uma determinada linha ou coluna podem ser recuperados em qualquer ordem. Perceba que o nome de coluna ou o numero da coluna pode ser especificado. O método select() levantará uma SQLException se algo der errado.
Agora analisaremos um exemplo de inserçăo na Listagem 2.
String[] values = {
"roles.id", "99",
"roles.name", "ahab",
"roles.role", "captain"
};
String[] errors = myDB.validate(values);
if (errors != null) {
for (int i=0; i System.out.println(values[2*i] + ": " + errors[i]);
}
} else {
myDB.insertRow(con, values);
}Listagem 2. Exemplo de inserçăo.
Este exemplo mostra como a validaçăo pode ser usada. A classe Database possui um método validate() que aceita um array de valores a ser validado e retorna mensagens de erro caso necessário. Cada valor é verificado contra seu formatter correspondente. Se qualquer valor năo for válido, o array conterá as mensagens de erro correspondentes. Valores válidos contęm um string vazio (năo-nulo). Um valor de retorno nulo indica que năo houve erros de validaçăo.
O método insertRow() aceita uma conexăo e os valores a inserir. Os valores săo formatados como um array de Strings que contęm pares de nome de coluna e valor. Um SQLException será levantado se algo der errado.
Agora analisaremos um exemplo de atualizaçăo na Listagem 3.
String[] values = {
"roles.id", "99",
"roles.name", "ahab",
"roles.role", "fool"
};
String[] params = {"roles.id", "99"};
int n = myDB.updateRows(con, values, "id=?", params);Listagem 3. Exemplo de atualizaçăo.
O terceiro parâmetro na última linha da Listagem 3 representa os critérios para uma cláusula opcional WHERE. Este parâmetro pode ser nulo, e neste caso, todas as linhas serăo atualizadas.
E finalmente, analisemos um exemplo de delete na Listagem 4. Perceba que a validaçăo pode (e deve) ser feita também com parâmetros.
String[] params = {"roles.id", "99"};
String[] errors = myDB.validate(params);
if (errors != null) {
for (int i=0; i System.out.println(values[2*i] + ": " + errors[i]);
}
} else {
int n = myDB.deleteRows(con, "roles", "id=?", params);
}Listagem 4. Exemplo de remoçăo.
Minha meta năo foi substituir qualquer framework de banco de dados. Foi simplesmente um esforço para resolver um conjunto de problemas com pouco código. É possível utilizar estas classes como base para um framework mais completo, que faz cache de dados e se integra diretamente com JSP/servlets. Năo seria difícil de construir taglibs personalizadas ou componentes para outros frameworks web.
Claro que esta soluçăo năo é perfeita. Configurar formatters para cada coluna de cada tabela que vocę planeja acessar pode ser muito trabalhoso. Felizmente, só precisamos fazer isto apenas uma vez. Idealmente, todas as informaçőes deveriam ser definidas quando a tabela fosse definida, mas isso normalmente năo acontece. As informaçőes poderiam ser carregadas de um arquivo XML ou poderiam ser armazenadas no próprio banco de dados; isso é o que PowerBuilder faz.
É bastante simples? Vocę decide. É possível que seja simples demais; alguns poderiam argumentar que năo é coisa para o horário nobre. Isso está certo. Em minha opiniăo, é mais fácil acrescentar funcionalidade a uma soluçăo simples em lugar de simplificar uma soluçăo complexa.
