


Tuning - Plano de Execuçăo - Parte 2
Olá!
Aprenderemos agora a efetuar a leitura do Plano de Execuçăo Gráfico de uma query, assunto que iniciei na coluna anterior.
A leitura de um plano de execuçăo deve ser efetuada da direita para a esquerda e de cima para baixo. Cada objeto sinaliza uma operaçăo distinta, e existem setas indicando o caminho a seguir. Vamos analisar o plano de um select na tabela Orders , localizado no database NorthWind :
PS: Para geraçăo do plano, selecione Query...Display Estimated Execution Plan na barra de ferramentas do Query Analyzer ou aperte em conjunto +L
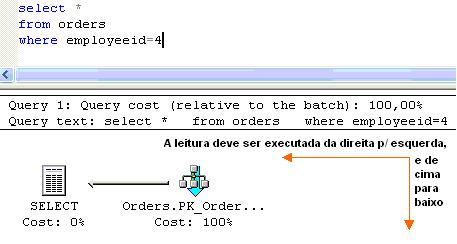
O simbolo ![]() indica que está sendo efetuada uma varredura sequencial na tabela Orders (=Clustered Index Scan) , tendo por base o índice cluster PK_Orders.
indica que está sendo efetuada uma varredura sequencial na tabela Orders (=Clustered Index Scan) , tendo por base o índice cluster PK_Orders.
O símbolo ![]() indica que após o processo de varredura sequencial na tabela Orders , o resultado da seleçăo será apresentado ao cliente.
indica que após o processo de varredura sequencial na tabela Orders , o resultado da seleçăo será apresentado ao cliente.
Vamos buscar informaçőes de outro empregado na tabela Orders e observar o plano de execuçăo:
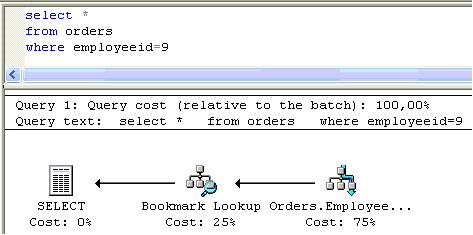
Nesse plano existe dois simbolos novos: ![]() representa um processo de Index Seek , e indica que a busca do empregado para employeeId=9 foi uma busca pontual, realizada com o auxílio de um índice năo-cluster.
representa um processo de Index Seek , e indica que a busca do empregado para employeeId=9 foi uma busca pontual, realizada com o auxílio de um índice năo-cluster.
Verificando a composiçăo do índice utilizado na pesquisa com o comando sp_HelpIndex Orders , nota-se que esse índice é composto apenas pela coluna employeeId . Como a query executada necessita de todas as colunas da tabela Orders , será necessário acessar a página de dados através de um ponteiro localizado na estrutura do índice. Esse processo de busca da página de dados ŕ partir de ponteiros localizados na estrutura do índice é conhecido por bookmark lookup, representado no plano de execuçăo pelo símbolo![]() .
.
Agora vamos a uma pergunta básica :
Como tirar proveito desse tipo de leitura?
Podemos enumerar vários detalhes importantes:
1) Acrescentar e/ou alterar filtros na cláusula where tem o poder de “modificar” um plano de execuçăo.
Nas queries executadas foram desenvolvidos planos de execuçăo diferentes para empregados diferentes. Porque o plano foi diferente ? Ora, na tabela Orders existem 43 linhas para employeeId=9 e 156 linhas para employeeId=4 . O esforço requerido para pesquisar 156 linhas na estrutura do índice e, para cada uma dessas linhas acessar a correspondente página de dados é maior do que acessar diretamente as páginas de dados sem auxílio de índice. Normalmente o otimizador utiliza um índice năo-cluster somente se conseguir descartar 95% dos dados existentes na tabela. Aplicando o percentual de 95% sobre 830, chegamos numa média de 42 linhas, o que explica a utilizaçăo do índice somente no segundo select.
2) Processos de Scan săo lentos :
Para executar o primeiro select , foi necessária uma leitura seqüencial das de todas as linhas presentes na tabela Orders . Como a tabela é pequena (possui somente 830 linhas!) esse problema passa despercebido. Agora imagine se, ao invés de 830, a tabela Orders possuísse 1.500.000 linhas ... Processos de scan devem ser sempre evitados, principalmente em tabelas com grande número de linhas.
3) Processos de Seek săo rápidos:
Buscas com operadores do tipo seek săo buscas pontuais e específicas. Para executar o segundo select foram necessárias 43 leituras num universo de 830 linhas existentes. Como sei disso? Basta passar com o mouse sobre o plano de execuçăo, para que informaçőes detalhadas sejam apresentadas sob a forma de um “post-it”. Procure pela linha “Estimated Row Count” ao passar com o cursor sobre o símbolo “Index Seek” (veja figura abaixo).
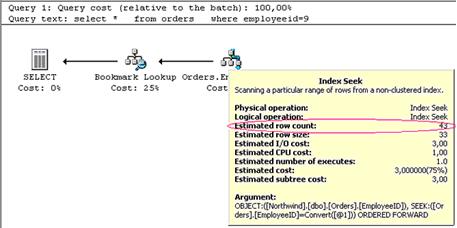
4) Processos de Seek em indices năo-cluster săo eficientes :
Um processo de seek é rápido porque utiliza a estrutura otimizada do índice para ler SOMENTE a informaçăo desejada. Assim, o segundo select leu SOMENTE as linhas da tabela que continham employeeId=9.
5) Processos de Seek em indices cluster săo muiiiiito mais eficientes:
Um processo de seek num índice cluster pode(*) desencadear um processo BookMark Lookup para localizaçăo da página de dados da tabela em questăo. Índices cluster ordenam a própria página de dados da tabela, portanto năo requerem estruturas em separado para prover a funcionalidade do índice. Assim, pesquisas em índices cluster săo mais eficientes porque NĂO REQUEREM processos de bookmark lookup, pois a página de dados é a própria página do indice.
(*) Nem toda pesquisa em índice năo-cluster irá gerar um processo de bookmark lookup . O bookmark lookup irá existir somente quando o índice năo comportar em sua estrutura todas as colunas explicitadas no comando select.
Bem pessoal por hoje é só, mas continuaremos a explorar esse assunto na próxima coluna.
Um forte abraço a todos!

Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.