


Um sistema de banco de dados distribuído é capaz de
oferecer diversas vantagens onde um grande volume de dados e processamento é
utilizado, aumentando o desempenho das aplicaçőes e oferecendo um ambiente
descentralizado e de alta disponibilidade. Em um cenário global onde o volume
de dados vem sendo cada vez maior em tamanho e importância, torna-se essencial
que o banco de dados consiga oferecer agilidade e segurança para o acesso dos
dados.Por que eu devo ler este artigo:O objetivo deste artigo é apresentar a ferramenta PgPool-II,
utilizada para a criaçăo de sistemas de banco de dados distribuído no SGBD
PostgreSQL através da instalaçăo e configuraçăo de um ambiente de redundância e
de alta disponibilidade.
Um sistema de banco de dados distribuído pode ser entendido como um banco de dados virtual, composto por diversos bancos de dados “reais” interligados fisicamente, através de vários meios como redes de alta velocidade, redes sem fio ou linhas telefônicas.
Normalmente, o usuário deste sistema năo sabe onde os dados estăo localizados fisicamente, caracterizando um sistema altamente transparente.
Entretanto, os computadores em um sistema de banco dados distribuídos năo compartilham componentes físicos, como memória principal ou discos de armazenamento, podendo variar em tamanho e funçăo, diferentemente de um sistema paralelo. A Figura 1 representa um sistema distribuído interligado por uma rede de comunicaçăo.
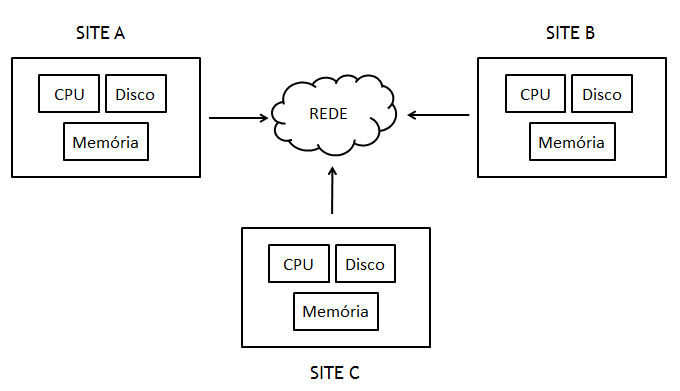
Figura 1. Representaçăo de um sistema distribuído
Neste sistema, o banco de dados é armazenado em diversos computadores, que săo denominados como “clusters” (nós). Cada cluster possui seu próprio hardware e năo compartilham nenhum componente físico.
Diferente de um sistema paralelo, os clusters podem variar em tamanho e funçăo. Uma das vantagens em utilizar um sistema distribuído em clusters é sua alta disponibilidade, uma vez que no desativamento de um cluster, seja por problemas técnicos ou qualquer outro motivo, um outro cluster pode tomar para si as requisiçőes vindas pelas aplicaçőes.
Um sistema de banco de dados distribuído pode ainda ser classificado de duas formas: sistemas Homogęneos, onde todos os clusters do sistema rodam o mesmo SGBD, conhecendo um ao outro e facilitando o processamento das transaçőes; e, Sistemas Heterogęneos, onde cada cluster roda um SGBD diferente, muitas vezes limitando e dificultando o processo de manipulaçăo dos dados, além de aumentar sua complexidade.
Formas de armazenamento de dados
Existem diversas formas com que um banco de dados distribuído pode armazenar os dados, sendo as principais:
· Replicaçăo: onde o sistema mantém réplicas idęnticas dos dados entre seus diversos clusters, assegurando que todos os servidores tenham o mesmo conteúdo durante todo o tempo.
Esta replicaçăo pode ocorrer de forma síncrona ou assíncrona. No caso da primeira, o conteúdo é replicado imediatamente após uma transaçăo, enquanto que na segunda, o servidor que está recebendo a transaçăo pode esperar por todo seu processamento para depois enviar a modificaçăo aos demais servidores.
De modo geral, a replicaçăo dos dados também fornece maior desempenho nas operaçőes de leitura, porém, as operaçőes de atualizaçăo consomem maior recurso, pois há a necessidade de atual ...


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.