Olá a todos os leitores. Este é meu primeiro artigo e
gostaria de compartilhar com vocęs o fruto de um estudo que fiz há alguns anos
atrás da aplicaçăo de algumas técnicas de Reflection, disponíveis no .NET
Quando estudo algo relacionado ŕ programaçăo, costumo
criar algumas ferramentas para por em prática tudo o que estou estudando.
Procuro fazer com que essas ferramentas sejam bastante úteis na medida do
possível. Nesse caso a ferramenta ORM que desenvolvi, foi fruto do estudo das
técnicas de Reflection e acabei adotando essa ferramenta para alguns projetos
que desenvolvi em algumas empresas onde
trabalhei.
Gostaria de deixar claro que o principal objetivo
aqui é estudar as possibilidades que as Namespaces citadas nos oferecem. A
ferramenta ORM criada como exemplo está bastante incompleta, pois se fossemos
construir uma ferramenta completa gastaríamos muito tempo e o artigo ficaria
enorme, fugindo de seu escopo inicial, além de gastar um tempo enorme para
fazer algo que já existe de forma muito mais completa em frameworks como Entity
Framework, NHibernate etc. Para este artigo, a ferramenta é apenas uma amostra
do que podemos fazer utilizando os recursos que estamos estudando. Temos
cięncia de sua limitaçăo em face das poderosas ferramentas disponíveis no
mercado. Eventualmente, ela poderá ser útil em algum cenário de ambiente de
trabalho, porém obviamente essa ferramenta deverá ser incrementada para uma
melhor utilizaçăo.
Como vocęs poderăo perceber posteriormente,
utilizamos diversas namespaces para a construçăo de nosso projeto, porém vamos
nos ater ao foco deste artigo que é estudar as Namespaces System.Reflection e
System.Attributes.
Para iniciarmos, vamos dar um breve overview sobre as
duas namespaces, os conceitos de ORM e a
arquitetura 3 -tier:
É a técnica para
observar, modificar e criar estruturas de códigos executáveis em tempo de
execuçăo.
A técnica de manipulaçăo
e criaçăo de código em tempo de execuçăo existe há muito tempo. Antigamente
isso era feito através de manipulaçăo direta de endereços na memória, o que era
bastante trabalhoso, muitas vezes gerando bugs indecifráveis e sérias falhas de
segurança.
Com a evoluçăo das
linguagens de programaçăo, mecanismos para representar o código executável
foram sendo criados e aperfeiçoados. Esse aperfeiçoamento permitiu que um
programa pudesse analisar sua própria representaçăo através de estruturas de
alto nível, o que facilitava a construçăo do código fonte e reduzia o número de
possíveis bugs. Esses mecanismos definem o que se conhece por Reflection (ou
Reflexăo).
Existem dois tipos de
Reflexăo:
- reflexăo computacional: quando essa representaçăo abrange o código
executável;
- reflexăo estrutural: quando abrange as
estruturas definidas no programa (como classes e métodos).
O .Net dá suporte ŕ reflexăo
estrutural através da Namspace System.Reflection e o suporte ŕ reflexăo
computacional é feito através da Namespace System.Reflection.Emit. Todo esse
suporte foi construído para que seja possível analisar a estrutura de um
programa, independente da linguagem em que foi escrito, ou seja, programas escritos em C# podem ser lidos por
um programa feito em VB.Net de forma totalmente transparente.
Reflection está presente em muitos pontos da BCL
(Base Class Librarys) e em muitas bibliotecas e frameworks do mercado. ORMs
como NHibernate e Entity Framework usam reflection para alterar o estado de
objetos em tempo de execuçăo. Bibliotecas como Castle.DynamicProxy e a
System.Xml.Serialization usam IL Emitting para gerar código em tempo de
execuçăo, seja com o objetivo de aumentar a performance, ou até mesmo para
estender a funcionalidade de certos objetos.
No .NET, o Commom
Language Runtime (CLR), gerencia Application Domains. Esse gerenciamento inclui
o carregamento de cada Assembly em seu respectivo Application Domain e o
controle do layout de memória da hierarquia de tipos dentro de cada assembly.
Sendo que Assemblies contém módulos, que por sua vez contém Types e Types
contém Members. Reflection fornece objetos que encapsulam o acesso a toda essa
hierarquia.
Via Reflection, podemos
criar instâncias de um Type qualquer em tempo de execuçăo. Podemos até criar
Types em tempo de execuçăo para posteriormente criarmos instâncias deste Type.
Um atributo é
um objeto que representa os dados que vocę deseja associar a um elemento no seu
programa. O elemento que vocę anexa um atributo é conhecido como alvo [target].
Esses alvos podem ser classes, structs, propriedades, métodos etc.
Se vocę pesquisar no CLR,
encontrará inúmeros atributos, Alguns deles săo aplicados em assemblies, outros
nas classes ou interfaces e alguns, como o [WebMethod], săo aplicados nos membros
das classes.
Alguns attributos que
iremos encontrar estăo declarados no AttributeTargets e estăo detalhados na tabela abaixo:
|
NOME MEMBRO |
USO |
|
|
All |
Aplicado a qualquer um
dos seguintes elementos: assembly,classe,contructor,delegate,enum,event, |
|
|
Assembly |
Aplicado ao próprio
assembly |
|
|
Class |
Aplicado a uma classe |
|
|
Constructor |
Aplicado a um dado
construtor |
|
|
Delegate |
Aplicado a um delegado |
|
|
Enum |
Aplicado a uma série |
|
|
Event |
Aplicado a um evento |
|
|
Field |
Aplicado a um campo |
|
|
Interface |
Aplicado a uma interface |
|
|
Method |
Aplicado a um método |
|
|
Module |
Aplicado a um único
módulo |
|
|
Parameter |
Aplicado a um parâmetro
de um método |
|
|
Property |
Aplicado a uma
propriedade (seja get ou set) |
|
|
ReturnValue |
Aplicado
a um valor de retorno |
|
|
Struct |
Aplicado a uma struct |
|
|
|
|
|
Tabela 1 – Attribute Targets
O atributo mais conhecido
em C# é o [Serializable]. Com ele, vocę garante que sua classe pode ser
serializada para o disco ou para a web.
Podemos criar nossos
próprios atributos e usá-los em qualquer momento. Exemplo:

Ilustraçăo
1
- Exemplo de criaçăo de um Atributo

Ilustraçăo
2-
Exemplo de utilizaçăo do Atributo criado na Ilustraçăo 1
Como citado anteriormente, Reflection é uma técnica
que possibilita observar e modificar o executável em tempo de execuçăo. Portanto
utilizando Reflection, podemos ter acesso a todos os Atributos de uma classe em
tempo de execuçăo. E de uma maneira extremamente simples:
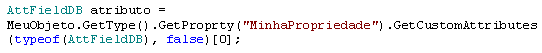
Ilustraçăo
3
- Exemplo de como ter acesso ŕ atributos customizados em tempo de execuçăo
No
.Net, todos os objetos possuem o método GetType(). Este método nos possibilita
trabalhar com algumas fincionalidades de Reflection. Entre elas estăo a
possibilidade de refletir uma propriedade qualquer de um objeto e listar todos
os atributos customizados da mesma, ou entăo trazer apeans um atributo
específico, como o exemplo.
Arqutetura em tręs camadas 3 - tier
Muitos projetos de
software hoje em dia utilizam o conceito de tręs camadas (3-tier).
Para nos
aprofundarmos um pouco sobre esse conceito, vamos definir a diferença entre
Tier e Layer:
A) Tier
Indica a separaçăo física dos componentes de uma
aplicaçăo, o que pode significar conjuntos diferentes como DLL, EXE, etc. no mesmo servidor ou vários servidores, como é descrito na figura abaixo:
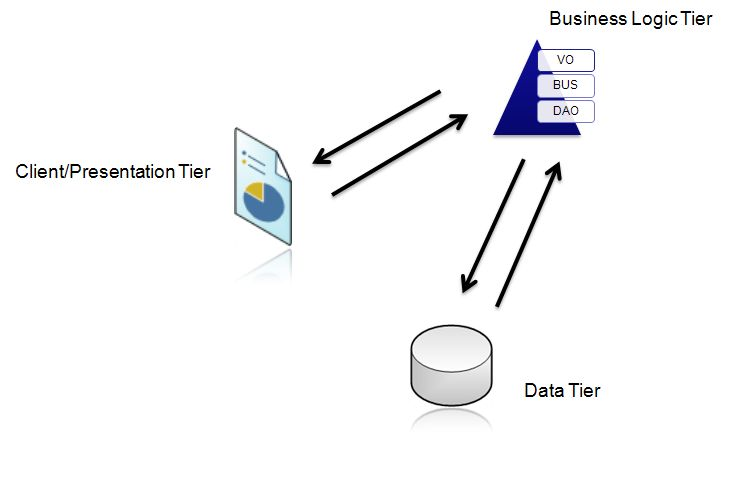
Ilustraçăo 4
- Arquitetura de tręs camadas
Segundo a figura acima, a
camada
de dados năo tęm acesso ŕ camada de apresentaçăo e
vice-versa, mas há uma camada intermediária – Business Logic Tier, que é a principal responsável pela comunicaçăo entre a camada
de dados e a camada de apresentaçăo.
Entăo, se nós separarmos cada camada pela sua funcionalidade, entăo chegamos ŕ seguinte conclusăo:
Presentation Tier (Camada de apresentaçăo) – É a camada onde o usuário final interagirá com a
aplicaçăo
Business Logic Tier (Camada de negócios) – É a camada que fará a comunicaçăo entre a Data Tier
(Camada de Dados) e a Presentation Tier (Camada de apresentaçăo), aplicando as
regras de negócios do projeto.
Data Tier – Basicamente
representa o servidor de banco de dados que gerencia e armazena os dados da
aplicaçăo.
B) Layer
Indica a Separaçăo
lógica dos componentes.
Podemos definir que
“Tier” é a separaçăo física de todos os componentes de uma aplicaçăo e “Layer”
é a separaçăo lógica de cada componente. Poderíamos separar em vários Layers as
Tiers Presentation, Business Logic e
Data Tier da seguinte forma:
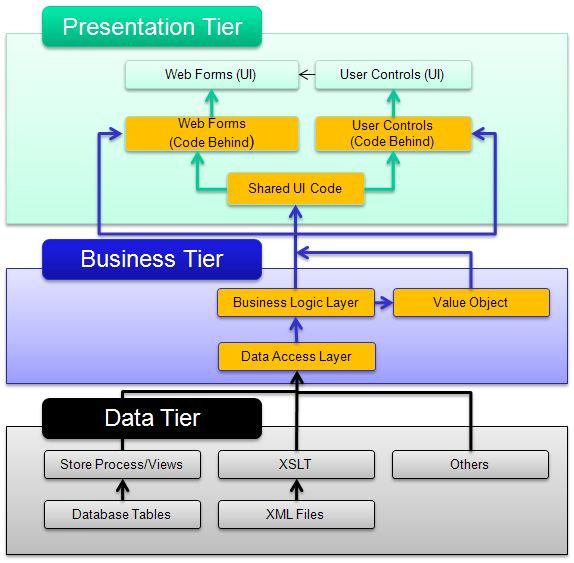
Ilustraçăo 5 – Representaçăo das Layers
Para a construçăo do
nosso artigo, vamos nos ater ŕs “Layers” da “Business Tier”.
Value Objects ou Model Layer: Esta camada contém classes, geralmente anęmicas
(contém somente propriedades e construtores, sem qualquer tipo de inteligęncia
de negócio ou métodos), que refletem tabelas de bancos de dados. Alguns
projetos utilizam structs ao invés de classes Um exemplo seria:
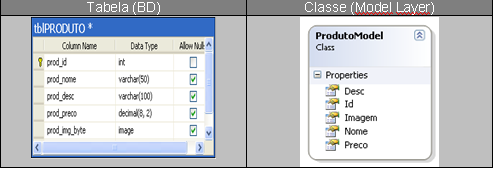
Tabela 2 – Exemplo de uma classe model
Data Access Layer (DAL): Consiste em um projeto que contem classes que farăo
acesso a dados, ou seja, realizarăo as operaçőes de Manipulaçăo, Criaçăo e
Recuperaçăo de dados contidos nas tabelas do BD do projeto, por meio de
chamadas a Stored Procedures ou execuçăo de código SQL. Essas classes năo devem possuir nenhuma
inteligęncia de negócio e via de regra para cada classe da camada de modelo, é
criada uma classe para a camada de acesso a dados. Na maioria das vezes os
métodos recebem como parâmetros, objetos da camada Model e alguns deles
retornam esses mesmos tipos de objetos. Exemplo:
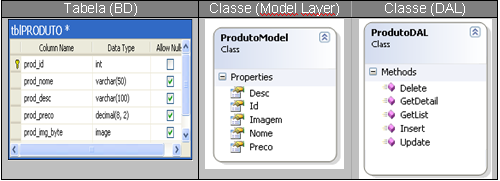
Tabela 3 – Exemplo de uma classe DAL
Business Layer: É a camada que utiliza as duas camadas explicadas anteriormente para
aplicar as regras de negócio do projeto e fazer a comunicaçăo ente elas. Ela
năo possui objetos de acesso a dados, e também năo possui propriedades para
refletir uma tabela no banco de dados. Ao invés disso, ela utiliza a camada
Model e DAL, fazendo uso das propriedades encapsuladas na Model e os métodos de
acesso ŕ dados da DAL para controlar as regras de negócio.
Imaginemos uma regra
hipotética: Para cada produto inserido, um email é disparado para o gerente da
área de estoque. Sendo esta uma regra de negócio, ela tem que estar encapsulada
dentro da camada de negócio, como demonstra a classe ProdutoBL que contém um
método para envio de email, e outro método que faz a inserçăo do produto,
utilizando a classe DAL.
Para cada classe da
camada model também é criada uma classe na camada Business:
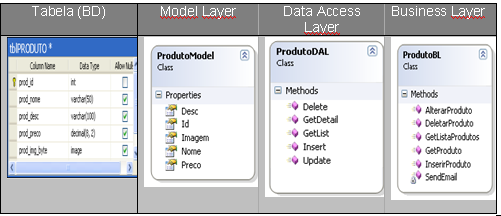
Tabela 4 – Exemplo de uma classe
Business
Essa é uma
arquitetura básica, haja vista a miríade de novas tecnologias e Design Patterns
que estăo surgindo a cada momento e que nos dăo uma série de novas
possibilidades e vantagens. Porém ela é ainda muito utilizada em empresas, pois
em alguns ambientes de trabalho, fazer migraçőes tecnológicas é algo muito
burocrático e muitas vezes quase impossível. Mas o fato é que esta arquitetura
oferece uma série de vantagens como – maior facilidade em dar manutençăo no
código e a possibilidade de reaproveitamento de código entre outras.
Mas também possui
seus inconvenientes. Muito código é escrito, e na maioria das vezes, código
repetitivo Um exemplo de código repetitivo săo as classes da camada DAL. Em um
projeto com este tipo de arquitetura, geralmente as classes DAL possuem métodos
quase que idęnticos (Inserir, Deletar, Alterar, Recuperar), o que muda săo Tabelas/Stored
Procedures acessadas, os tipo de parâmetros esperados pelos métodos e os
objetos de retorno destes mesmos métodos.
Outro inconveniente é
que na maioria das vezes em que se utiliza esta arquitetura, os responsáveis
pelo projeto năo deixam o sistema pronto para eventuais mudanças de Bancos de
Dados. Eles utilizam objetos ado.net específicos para cada banco, o que
dificulta esse tipo de alteraçăo.
Mapeamento
Objeto Relacional – ORM
Mapeamento objeto-relacional (ou ORM, do inglęs: Object-relational mapping) é uma técnica de desenvolvimento
utilizada para reduzir a impedância entre a programaçăo orientada a objetos e o conceito de bancos de dados relacionais. As tabelas do banco
de dados săo representadas
através de classes e os registros de cada tabela săo
representados como instâncias das classes correspondentes. Em suma ORM faz a
conexăo entre o “mundo orientado a objeto” e o “mundo relacional”, como
demonstra a figura a seguir:
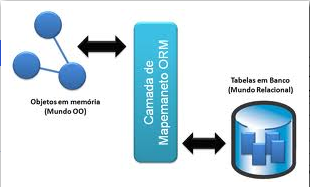
Ilustraçăo 6 – Representaçăo gráfica do conseito ORM
Com esta técnica, o programador năo precisa se preocupar com os
comandos em linguagem SQL; ele
irá usar uma interface de
programaçăo simples que faz todo
o trabalho de persistęncia.
Năo é necessária uma correspondęncia direta entre as tabelas de
dados e as classes do programa. A relaçăo entre as tabelas onde originam os
dados e o objeto que os disponibiliza é configurada pelo programador, isolando
o código do programa das alteraçőes ŕ organizaçăo dos dados nas tabelas do banco de dados.
A forma como este mapeamento é configurado depende da ferramenta que estamos a usar. Como exemplo, o programador que use NHibernate pode usar arquivos XML ou o sistema de anotaçőes que a linguagem providencia. No nosso caso, faremos esse mapeamento utilizando “Attributes”.
