Neste artigo trabalharemos um ponto importante com relaþÒo ao SGBD PostgreSQL que Ú o particionamento, onde abordaremos sua conceituaþÒo, qual a necessidade de realizar esta tarefa e apresentaremos exemplos de sua criaþÒo, de forma a sanar d·vidas referentes a criaþÒo e utilizaþÒo de particionamento de tabelas.
A primeira questÒo a ser levantada Ú: O que seria um particionamento? Particionamento, Ú na verdade o processo de dividir as tabelas em partes gerencißveis menores, onde estas partes menores sÒo chamadas de partiþ§es. O que ocorre no processo de particionamento Ú a divisÒo da l¾gica de uma grande tabela em m·ltiplas unidades fÝsicas menores.
Dentre os motivos que nos levam a realizar o particionamento das tabelas, temos o que podemos considerar o mais importante que Ú para o aumento do desempenho da base de dados, o que Ú conseguido com o auxÝlio dos Joins de partiþÒo, onde se precisarmos realizar uma sÚrie de consultas numa tabela completa, a utilizaþÒo de partiþ§es nos ajudaria limitando o Ômbito dessa pesquisa. A segunda razÒo mais importante Ú que com o particionamento das tabelas, torna-se muito mais fßcil o seu gerenciamento.
Outras vantagens que podemos ver sÒo quando consultas ou atualizaþ§es acessam uma grande porcentagem de uma ·nica partiþÒo, onde o desempenho pode ser melhorado, tendo como vantagem uma varredura sequencial da partiþÒo, ao invÚs de utilizar Ýndices e acessos aleat¾rios espalhados por toda a tabela. Operaþ§es de exclusÒo podem ser realizadas pela adiþÒo ou mesmo remoþÒo de partiþ§es, onde as operaþ§es de ALTER TABLE NO INHERIT e DROP TABLE sÒo ambas muito mais rßpido do que uma operaþÒo em massa. AlÚm de que, com estes comandos temos a possibilidade de evitar a sobrecarga causada pelo VACUUM causado por uma exclusÒo em massa de registros, dentre outras raz§es.
Hoje, na versÒo 9.4 do PostgreSQL, temos suporte ao particionamento atravÚs de heranþa entre tabelas, onde cada partiþÒo deverß ser criada como uma tabela filha de uma ·nica tabela pai, a qual Ú vazia, existindo apenas para representar o conjunto de dados gerados. Para a implementaþÒo dos particionamentos no PostgreSQL, temos realiza-los de duas possÝveis formas, que sÒo a Range partitioning e a List partitioning, as quais veremos a seguir uma breve descriþÒo.
Neste processo, temos que a tabela ômestraö Ú dividida em "intervalos", definidos por uma coluna chave ou por um conjunto de colunas, sem que haja uma sobreposiþÒo entre os intervalos dos valores atribuÝdos a diferentes partiþ§es. Quando estamos trabalhando com intervalos de partiþÒo, podemos utilizar intervalos de datas ou registros numÚricos, por exemplo.
Nesta forma, temos que a tabela Ú dividida em listas que de forma explicita, apresenta os valores chave de cada partiþÒo. Com relaþÒo a lista de particionamentos, podemos criar, por exemplo, listas de departamentos, como RH e financeiro.
Antes de darmos seguimento com as partiþ§es, precisamos entender primeiro o processo de implementaþÒo de heranþa que ocorre entre as tabelas do PostgreSQL, o que pode ser de grande utilidade ao criarmos nossas bases de dados. A heranþa Ú um conceito de bancos de dados orientados a objeto, que abre possibilidades interessantes para os projetos de bancos de dados, onde no PostgreSQL temos que uma tabela pode herdar de nenhuma ou de vßrias tabelas.
Para exemplificarmos a sua utilizaþÒo, vejamos a criaþÒo de um modelo de dados para cidades e estados, onde cada estado possui vßrias cidades, mas apenas uma capital para cada cidade. Para recuperarmos mais rßpido a capital, podemos criar duas tabelas para acelerar o processo, onde uma Ú para a capital e a outra para as cidades que nÒo sÒo capitais. Vejamos de acordo com as Listagens 1 e 2 como ficariam nossas tabelas.
CREATE TABLE empresa(
nome_empresa text,
endereco text
);
CREATE TABLE departamento(
nome_dep text,
qtde_funcionarios int
) INHERITS (empresa);
Agora que temos as nossas tabelas criadas, adicionaremos alguns dados de teste para vermos o funcionamento, como mostra a Listagem 3.
INSERT INTO empresa(nome_empresa, endereco)
VALUES('Empresa testes', 'Rua dos testes');
INSERT INTO departamento(nome_empresa, endereco , nome_dep, qtde_funcionarios)
VALUES('Empresarial dos testes', 'Rua testador', 'Financeiro', 60);
Neste exemplo, temos que a tabela departamento herda todas as colunas da tabela pai, empresa, a qual possui duas colunas que sÒo quantidade de funcionßrios e o nome do departamento.
Agora que entendemos um pouco sobre a heranþa, daremos continuidade a criaþÒo das partiþ§es, onde precisamos estar cientes de que existem ao todo, cinco passos necessßrios para a criaþÒo das partiþ§es no PostgreSQL, que sÒo a criaþÒo da tabela principal (ou pai), criaþÒo das tabelas filhas, criaþÒo dos Ýndices das tabelas, criaþÒo de triggers para a inserþÒo dos dados nas tabelas filhas e por ·ltimo, habilitar a restriþÒo de exclusÒo.
Quando utilizamos intervalos de partiþÒo, temos que este Ú o tipo de partiþÒo onde particionamos a tabela em intervalos menores, definidos por uma coluna ·nica ou vßrias colunas. Ao definirmos os intervalos, precisamos tomar cuidado para que as tabelas estejam conectadas, nÒo sobrepondo umas Ós outras. AlÚm disso, os intervalos devem ser definidos usando o operador (<). Para entendermos melhor com relaþÒo a partiþÒo de intervalos, criaremos agora um exemplo de sua utilizaþÒo, onde teremos os registros das vendas referentes ao ano de 2014.
Para comeþarmos o exemplo, criaremos inicialmente a nossa tabela principal, a qual chamaremos de registros_financeiros, teremos os campos apresentados de acordo com a Listagem 4. Nesta tabela, teremos todos os dados sobre as vendas armazenadas em uma base dißria.
CREATE TABLE registros_financeiros
(
cod_registro NUMERIC PRIMARY KEY,
qtde_vendas NUMERIC,
data_venda DATE NOT NULL DEFAULT CURRENT_DATE
);
Como apresentado pela Listagem 1, temos a nossa tabela principal, ou pai criada, onde todos os registros que forem inseridos serÒo movidos para as tabelas filhas com base nos critÚrios de data das vendas, o que serß criado agora.
Criada a tabela principal, implementaremos uma partiþÒo para a criaþÒo das tabelas filhas que herdarÒo a tabela pai. Adicionaremos uma restriþÒo do tipo CHECK para as datas, o que irß possibilitar que tenhamos os dados corretos para cada partiþÒo. Cada partiþÒo possuirß dados referentes a um trimestre, onde teremos as tabelas criadas de acordo com as Listagens 5, 6 e 7.
CREATE TABLE registros_financeiros_jan_mar
(
PRIMARY KEY (cod_registro, data_venda),
CHECK (data_venda >= DATE '2015-01-01' AND data_venda < DATE '2015-04-01')
)
INHERITS (registros_financeiros);
CREATE TABLE registros_financeiros_abril_junho
(
PRIMARY KEY (cod_registro, data_venda),
CHECK (data_venda >= DATE '2015-04-01' AND data_venda < DATE '2015-07-01')
)
INHERITS (registros_financeiros);
CREATE TABLE registros_financeiros_jul_set
(
PRIMARY KEY (cod_registro, data_venda),
CHECK (data_venda >= DATE '2015-07-01'
AND data_venda < DATE '2015-10-01')
)
INHERITS (registros_financeiros);
Agora que temos nossas tabelas criadas, iremos adicionar Ýndices para cada uma das tabelas filhas para que dessa forma possamos agilizar ainda mais as consultas. Os Ýndices serÒo criados no campo data_venda e servirß para qualquer operaþÒo DML (INSERT, SELECT ou UPDATE) referente ao campo de data. Os Ýndices serÒo criados de acordo com as instruþ§es a seguir:
CREATE INDEX data_venda_jan_mar_idx ON registros_financeiros_jan_mar (data_venda);
CREATE INDEX data_venda_abril_junho_idx ON registros_financeiros_abril_junho (data_venda);
CREATE INDEX data_venda_jul_set_idx ON registros_financeiros_jul_set (data_venda);
Ap¾s a realizaþÒo das tabelas e dos Ýndices, o pr¾ximo passo Ú a criaþÒo da trigger que serß disparada pela tabela principal, onde as condiþ§es devem ser as mesmas aplicadas nas tabelas filhas. Vejamos entÒo de acordo com a Listagem 8 como ficarß a nossa trigger.
CREATE OR REPLACE FUNCTION insercao_registros()
RETURNS TRIGGER AS $
BEGIN
IF (NEW.data_venda >= DATE '2015-01-01' AND
NEW.data_venda < DATE '2015-04-01') THEN
INSERT INTO registros_financeiros_jan_mar VALUES (NEW.*);
ELSIF (NEW.data_venda >= DATE '2015-04-01' AND
NEW.data_venda < DATE '2015-06-01') THEN
INSERT INTO registros_financeiros_abril_junho VALUES (NEW.*);
ELSIF (NEW.data_venda >= DATE '2015-06-01' AND
NEW.data_venda < DATE '2015-09-01') THEN
INSERT INTO registros_financeiros_jul_set VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'A data nÒo se encontra nos limites estabelecidos para a inserþÒo...';
END IF;
RETURN NULL;
END;
$ LANGUAGE plpgsql;
O ·nico prop¾sito desta funþÒo que acabamos de criar Ú para que os dados sejam preenchidos nas respectivas tabelas com base na data dos registros financeiros da empresa. Para que a trigger criada na Listagem 8 seja disparada, precisaremos de uma funþÒo que irß executar a trigger no momento em que as instruþ§es de INSERT, UPDATE e DELETE forem disparadas. Esta trigger function, que chamaremos de registro_mes_trigger, serß definida de acordo com a apresentada pela Listagem 9.
CREATE TRIGGER registro_mes_trigger
BEFORE INSERT ON registros_financeiros
FOR EACH ROW
EXECUTE PROCEDURE insercao_registros();
Como ·ltima etapa a ser realizada, temos a implementaþÒo das restriþ§es de exclusÒo, ou constraints exclusion, onde esta Ú uma tÚcnica voltada para a otimizaþÒo das consultas que buscam melhoria de desempenho para as tabelas particionadas que foram definidas no decorrer do artigo. Para que possamos definir a restriþÒo como ativa, o processo Ú realizado da seguinte forma:
SET constraint_exclusion = on;
SELECT count(*) FROM registros_financeiros WHERE data_venda >= DATE '2015-03-01';
Caso a constraint_exclusion nÒo tenha sido definida, a consulta serß realizada em cada uma das partiþ§es da tabela de registros_financeiros. No entanto, quando a restriþÒo Ú habilitada, as constraints de cada partiþÒo serÒo examinadas, onde serß verificada a necessidade de pesquisa apenas nas tabelas que estejam de acordo com a clßusula WHERE da consulta.
No momento em que executamos uma instruþÒo de INSERT na tabela principal, temos que a trigger insercao_registros(), criada anteriormente serß acionada e em sequÛncia, chamarß a trigger function registro_mes_trigger, onde com base no campo data_venda teremos os dados salvos na tabela filha especÝfica. Para vermos o funcionamento da nossa estrutura, iremos inserir alguns registros na tabela registros_financeiros, para que em seguida, utilizemos o comando SELECT para ver o resultado final da operaþÒo. Vejamos entÒo de acordo com a Listagem 10.
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (1, 300, TO_DATE('05/03/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (2, 700, TO_DATE('07/15/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (3, 450, TO_DATE('02/08/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (5, 1300, TO_DATE('05/15/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (6, 900, TO_DATE('02/27/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (7, 3000, TO_DATE('08/07/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (8, 1500, TO_DATE('08/17/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (9, 1000, TO_DATE('01/27/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (10, 4000, TO_DATE('07/06/2015','MM/DD/YYYY'));
INSERT INTO registros_financeiros (cod_registro, qtde_vendas, data_venda) VALUES (11, 3000, TO_DATE('04/20/2015','MM/DD/YYYY'));
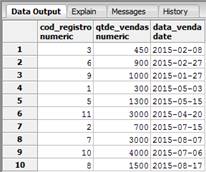
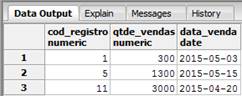
Com nossos registros inseridos, realizaremos inicialmente uma consulta na tabela principal para que possamos ver o resultado que nos serß apresentado, e em seguida, realizaremos uma consulta em uma das tabelas filhas para verificarmos os registros que foram inseridos. Realizaremos nossas consultas de acordo com as instruþ§es a seguir, seguidas dos resultados apresentados pelas Figuras 1 e 2.
SELECT * FROM registros_financeiros;SELECT * FROM registros_financeiros_abril_junho;Como podemos observar na tabela filha, referente as vendas dos meses de abril a junho, temos apresentados trÛs registros inseridos, sendo que dois foram no mÛs de maio e um de abril. Com relaþÒo as instruþ§es de UPDATE ou DELETE, nÒo precisaremos criar nenhuma nova trigger, pois a trigger de inserþÒo criada anteriormente resolve o nosso problema. Para demonstrarmos isso, realizaremos inicialmente a atualizaþÒo em um dos registros e verificaremos o impacto realizado sobre a tabela filha, como podemos ver de acordo com a instruþÒo a seguir:
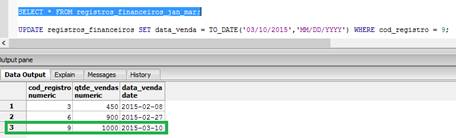
UPDATE registros_financeiros SET data_venda = TO_DATE('03/10/2015','MM/DD/YYYY') WHERE cod_registro = 9;O resultado apresentado ao realizarmos uma consulta sobre a tabela filha de janeiro a marþo serß entÒo apresentado com um novo registro, como mostra a Figura 3, com base na instruþÒo de pesquisa a seguir:
SELECT * FROM registros_financeiros_jan_mar;Por fim, realizaremos agora a exclusÒo de um dos registros, o qual se aplica da seguinte forma:
DELETE FROM registros_financeiros WHERE data_venda = TO_DATE('03/10/2015','MM/DD/YYYY');Ao tratarmos de lista de partiþ§es, temos que esta Ú uma maneira similar ao Range partitioning, com a diferenþa de que a tabela Ú dividida listando-se explicitamente os valores-chave que aparecem em cada partiþÒo. Neste caso, cada partiþÒo Ú definida e designada com base em um valor de coluna presente em um conjunto de listas de valores, ao contrßrio de ser com base em um conjunto de faixas de valores adjacentes, o qual serß realizado atravÚs da definiþÒo de cada partiþÒo por meio dos valores representados pelo value_list, onde value_list Ú uma lista de valores separados por vÝrgulas.
Para nosso prop¾sito, criaremos novas tabelas principal e filhas, as quais conterÒo os registros financeiros da empresa de vendas em conjunto com as informaþ§es das cidades que possuem uma unidade da empresa em questÒo. Neste caso, teremos a coluna cidade como sendo a base para a criaþÒo da nossa lista de partiþ§es. Dito isso, criaremos inicialmente a nossa tabela principal, a qual chamaremos de registros_financeiros_listaParticao, como mostra a Listagem 11.
CREATE TABLE registros_financeiros_listaParticao
(
cod_reg NUMERIC primary key,
data_venda date,
qtd_vendas NUMERIC,
cidade_empresa text
);
Agora, serÒo criadas as tabelas filhas, como podemos ver de acordo com as instruþ§es apresentadas pelas Listagens 12 e 13.
CREATE TABLE registros_financeiros_1
(
PRIMARY KEY (cod_reg, didade_empresa),
CHECK (didade_empresa IN ('Recife', 'Caruaru'))
)
INHERITS (registros_financeiros_listaParticao);
CREATE TABLE registros_financeiros_2
(
PRIMARY KEY (cod_reg, didade_empresa),
CHECK (didade_empresa IN ('Vit¾ria', 'Fortaleza'))
)
INHERITS (registros_financeiros_listaParticao); Realizada a criaþÒo das tabelas, serÒo criados os Ýndices para as tabelas geradas, os quais geraremos de acordo com as seguintes instruþ§es:
CREATE INDEX listaParticao1_idx ON registros_financeiros_1(didade_empresa);
CREATE INDEX listaParticao2_idx ON registros_financeiros_2(didade_empresa);Em seguida, criaremos as triggers principal e a trigger function para realizarmos a atualizaþÒo das tabelas, como mostra asListagens 14 e 15.
CREATE OR REPLACE FUNCTION insere_registros_listaParticao()
RETURNS TRIGGER AS $
BEGIN
IF (NEW.didade_empresa IN ('Recife', 'Caruaru')) THEN
INSERT INTO registros_financeiros_1 VALUES (NEW.*);
ELSIF (NEW.didade_empresa IN ('Vit¾ria', 'Fortaleza')) THEN
INSERT INTO registros_financeiros_2 VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'A cidade nÒo foi encontrada na listagem especificada...';
END IF;
RETURN NULL;
END;
$ LANGUAGE plpgsql;
CREATE TRIGGER registros_financ_trigger
BEFORE INSERT ON registros_financeiros_listaParticao
FOR EACH ROW
EXECUTE PROCEDURE insere_registros_listaParticao();
Para finalizarmos, realizaremos a inserþÒo de alguns registros para vermos o funcionamento das instruþ§es, como mostra a Listagem 16.
INSERT INTO registros_financeiros_listaparticao(cod_reg, data_venda, qtd_vendas, didade_empresa) VALUES (1, '16-07-2015', 1500, 'Vit¾ria');
INSERT INTO registros_financeiros_listaparticao(cod_reg, data_venda, qtd_vendas, didade_empresa) VALUES (2, '26-03-2015', 3500, 'Fortaleza');
INSERT INTO registros_financeiros_listaparticao(cod_reg, data_venda, qtd_vendas, didade_empresa) VALUES (3, '10-09-2015', 500, 'Caruaru');
INSERT INTO registros_financeiros_listaparticao(cod_reg, data_venda, qtd_vendas, didade_empresa) VALUES (4, '16-12-2015', 1500, 'Recife');
INSERT INTO registros_financeiros_listaparticao(cod_reg, data_venda, qtd_vendas, didade_empresa) VALUES (5, '18-10-2015', 5000, 'Fortaleza');
Com os registros inseridos, vejamos atravÚs da instruþÒo SELECT como serÒo apresentadas as informaþ§es em uma das tabelas filhas, como mostrado a seguir:
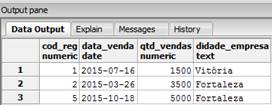
select * from
registros_financeiros_2;Com base na instruþÒo de seleþÒo, tivemos os dados apresentados como mostra a Figura 4, onde temos que trÛs registros foram inseridos, sendo que dois foram para Fortaleza.
Com isso finalizamos este artigo, no qual foram apresentadas as tÚcnicas de particionamento de tabelas para a base de dados PostgreSQL, onde para isso, precisamos entender conceitos de heranþa entre as tabelas para que pudÚssemos capitar melhor o motivo de tal necessidade. Esperamos que tenham gostado. AtÚ a pr¾xima! =)
Links
DLL Inherit
http://www.postgresql.org/docs/9.4/static/ddl-inherit.html
DLL Partitioning
http://www.postgresql.org/docs/9.4/static/ddl-partitioning.html


Utilizamos cookies para fornecer uma melhor experiÛncia para nossos usußrios, consulte nossa polÝtica de privacidade.