Este artigo descreve o que acontece quando uma query é submetida dentro do SQL Server, criando uma base conceitual a respeito do funcionamento do plano de execuçăo e dos fatores que o influenciam.
A aplicaçăo dos conceitos e o entendimento do plano de execuçăo săo recomendados para profissionais em empresas de todos os segmentos. A construçăo de queries visando performance e tendo a compreensăo da melhor maneira de construí-las influencia na qualidade de qualquer projeto que envolva extraçăo de informaçăo do SQL Server.
Hoje, com a grande necessidade de extrair informaçőes do banco de dados, podendo ser tanto para carga e manipulaçăo desses dados como para disponibilizaçăo de informaçőes analíticas, entre outras finalidades, surgem alguns problemas para disponibilizar os dados com rapidez a qual năo foi prevista durante a construçăo da query.
Entăo surge a questăo, se os dados năo estăo sendo recuperados com a velocidade desejada, o plano de execuçăo da query foi analisado? Uma vez que este plano foi ao menos gerado, săo compreensíveis quais foram os fatores de influęncia dentro da construçăo da query para o resultado gerado pelo plano de execuçăo no SQL? O que acontece dentro do SQL quando uma query é submetida?
No desenvolvimento de um projeto de banco de dados, as informaçőes precisam ser disponibilizadas de forma eficiente e eficaz, ou seja, com rapidez e qualidade. No entanto, nem sempre é possível alcançar isso.
Em um mundo em que os projetos săo sempre para ontem, as necessidades estăo cada vez mais urgentes e muitas vezes o preço de um processo dentro do banco de dados mais lento do que o suportável é o preço a ser pago.
Mas o tempo escasso e a urgęncia năo săo os únicos inimigos a serem vencidos, ou administrados. A falta de conhecimento a respeito de como é gerado o plano de execuçăo de um comando T-SQL e quais fatores influenciam na construçăo de queries coerentes para obter performance săo itens a serem considerados.
Na maioria das vezes, as queries săo construídas no processo de tentativa e erro e a sorte passa a ser um fator dominante, ao invés do conhecimento.
Alcançar performance na construçăo de queries no SQL está além de entender os operadores envolvidos em um plano de execuçăo. Também envolve compreender o porquę esses operadores foram gerados, como foram gerados e quais foram os fatores que influenciaram o SQL a tomar as decisőes que tomou para gerar o plano.
Por exemplo, quais as informaçőes que foram levadas em consideraçăo para que o índice criado năo fosse usado, ou por que uma determinada query está levando mais tempo que o esperado para recuperar as informaçőes, ou ainda por que determinado processo de carga de dados está levando mais tempo que a janela disponibilizada, entre outros problemas.
Considerando isso, o objetivo deste artigo é compreender o funcionamento do processamento de uma query dentro do SQL, e baseado nisso, ajustar o comando T-SQL para que alcance as necessidades do processo o qual faz parte. Afinal, como obter o melhor de algo que năo se entende como funciona?
Logo, é preciso no começo cavar um pouco mais fundo para que o alicerce do conhecimento esteja bem fundamentado.
Segundo a o livro The Art of High Performance SQL Code: SQL Server Execution Plans, plano de execuçăo é definido como uma maneira simples do query optimizer calcular o caminho mais eficiente para implementar uma requisiçăo representada pelo T-SQL, quando esta for submetida dentro SQL Server.
Portanto, uma vez que a query for submetida, o SQL vai calcular vários caminhos e escolher uma opçăo dentre esses.
Plano de Execuçăo – Modo gráfico
Para entender visualmente a ideia do que é um plano de execuçăo o primeiro exemplo a ser apresentado será no modo gráfico. O script disponibilizado na Listagem 1 é um passo a passo que será utilizado neste artigo para o estudo de como funciona o plano de execuçăo. Através do SQL Management Query Editor, considerando que o SQL Server já esteja instalado, este acessível pelo SQL Management Studio, conecte no servidor a ser usado para este estudo, clique em New Query e execute o script abaixo através da tecla F5.
--Criaçăo da tabela
CREATE TABLE [dbo].[LOG_EXECUCAO](
[ID] [int] IDENTITY(1,1) NOT NULL,
[DATA_ATUALIZACAO] [DATETIME] NOT NULL,
[ID_PROCESSO] [INT] NOT NULL,
[NOME_SISTEMA] [VARCHAR](100) NOT NULL
CONSTRAINT [PK_LOG_EXECUCAO_ID] PRIMARY KEY NONCLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
--Inserçăo de dados
INSERT INTO dbo.LOG_EXECUCAO
(DATA_ATUALIZACAO
,ID_PROCESSO
,NOME_SISTEMA)
VALUES (GETDATE()
,1
,'SISTEMA DE VENDAS')
GO
INSERT INTO dbo.LOG_EXECUCAO
(DATA_ATUALIZACAO
,ID_PROCESSO
,NOME_SISTEMA)
VALUES (GETDATE()
,2
,'SISTEMA DE CONTROLE')
GO
INSERT INTO dbo.LOG_EXECUCAO
(DATA_ATUALIZACAO
,ID_PROCESSO
,NOME_SISTEMA)
VALUES (GETDATE()
,3
,'SISTEMA DE ESTOQUE')
GO
INSERT INTO dbo.LOG_EXECUCAO
(DATA_ATUALIZACAO
,ID_PROCESSO
,NOME_SISTEMA)
VALUES (GETDATE()
,4
,'SISTEMA DE MONITORAÇĂO')
GO
INSERT INTO dbo.LOG_EXECUCAO
(DATA_ATUALIZACAO
,ID_PROCESSO
,NOME_SISTEMA)
VALUES (GETDATE()
,5
,'SISTEMA DE LOGÍSTICA')
--Select dos dados
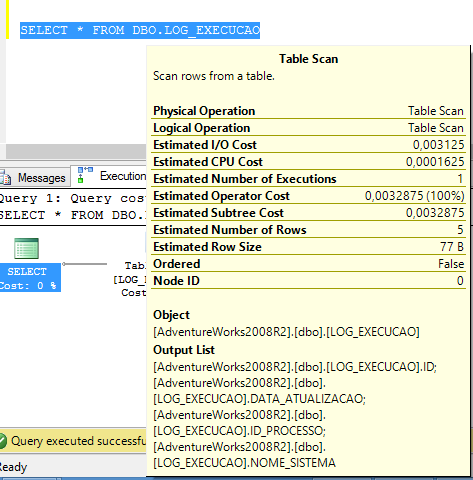
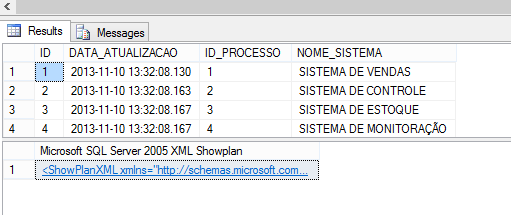
SELECT * FROM DBO.LOG_EXECUCAO
Uma vez que a query que será analisada esteja montada, ou seja, como mostrado na Listagem 1, a query a ser analisada é o select da tabela LOG_EXECUCAO. É possível obter o plano de execuçăo de diversas maneiras, entre elas o modo gráfico.
Neste caso para gerar o plano no modo gráfico, clique na barra de ferramentas do Management Studio Query Editor, pode-se escolher entre duas opçőes Display estimated execution plan e Include actual execution plan. Se a opçăo escolhida for Include Actual Execution Plan, é preciso executar o script antes que o plano de execuçăo seja gerado, pois dessa forma o plano trará também o resultado atual além da estimativa, esta opçăo pode ser identificada na Figura 1, circulada em vermelho.
Se a opçăo desejada for Display Estimated Execution o script primeiro passa pelo processo de "parse", e depois a estimativa do plano de execuçăo é gerada. A opçăo Display Estimated Execution pode ser identificada circulada em preto na Figura 1.
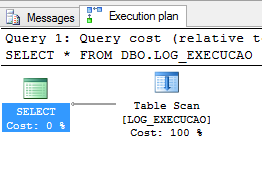
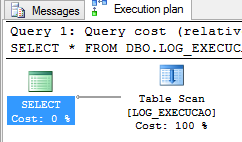
Após a seleçăo de uma dessas opçőes (Display Estimated Execution ou Include Actual Execution Plan) o plano gerado será simular ao mostrado na Figura 2. Esta é a visualizaçăo do plano no modo gráfico.
Para entender o caminho que foi percorrido na engine do SQL Server para gerar o plano de execuçăo, usando como, por exemplo, na Figura 2 o operador Table Scan e ainda o que é um Table Scan, é preciso entender o que ocorre dentro do banco de dados quando a execuçăo de uma query é submetida no SQL Server.
Quando uma determinada query é executada dentro SQL Server como, por exemplo, um select em uma tabela para obter o retorno de um conjunto de dados, ocorrem vários processos no servidor. O propósito deles é administrar a maneira como os dados serăo retornados. Embora existam vários processos diferentes ocorrendo ao mesmo tempo, a query submetida vai passar basicamente por dois estágios:
1. Processos que ocorrem na Relational Engine;
2. Processos que ocorrem na Storage Engine.
De forma resumida na Relational Engine é onde a query passa pelo processo de "parse" e é processada pelo query optimizer, o que irá gerar o plano de execuçăo. O plano é mandado (em formato binário) para a Storage Engine para execuçăo da query e retorno dos dados solicitados.
O “parse” da query ocorre, como informado anteriormente, no Relational Engine. Isso significa que quando a query chega, esta deverá passar pelo processo de análise da escrita do T-SQL para que seja verificado se está correta.
A query também será submetida ao algebrizer, o qual vai identificar entre as colunas todos os tipos de dados (varchar, char, nvarchar, etc.) de todos os objetos que estăo sendo acessados.Se existirem agregaçőes serăo localizadas (como group by) em um processo chamado de aggregation binding. A saída deste processo é a query gerada em forma de árvore no qual săo identificados os passos lógicos para a execuçăo da mesma (isso se o plano da query năo existir em cache).
Depois disso a query passa ao Query Optimizer, aonde vai ser modelada, usando o resultado do query parsing e as estatísticas dos dados.
O query optimizer é aonde os planos baseado em custo săo gerados, o que significa que entre várias possibilidades uma é escolhida baseada no menor custo. Os cálculos văo levar em consideraçăo algumas informaçőes como, por exemplo, recursos de CPU, I\O e estatística. As estatísticas por default săo coletadas automaticamente, baseadas nas colunas dos índices dentro do banco de dados elas descrevem a distribuiçăo dos dados, a unicidade, ou seletividade destes.
O caminho ótimo para execuçăo da query será definido pelo optimizer tendo como resultado o plano de execuçăo. Neste processo serăo definidos quais os tipos de joins serăo usados, quais índices serăo acessados e ainda outras informaçőes que săo baseadas em custo.
Se o plano năo existir em cache vários planos serăo gerados, o plano com o menor custo que leve menos tempo para ser gerado será escolhido (veja BOX 1), no entanto algumas vezes o plano menos eficiente vai ser escolhido.
Isso se o optimizer achar que vai ser mais rápido escolher o plano menos eficiente, do que gerar mais planos. Por exemplo, no caso de uma query que faça uma consulta no SQL e năo faz o uso de índices, cálculos ou agregaçőes. Ao invés de tentar o plano de execuçăo ótimo, o optimizer escolhe o plano de execuçăo trivial.
O custo da query năo é traduzido em segundos, é um número utilizado para representar o valor de custo para cada recurso no plano. Para obter o custo dos operadores multiplica-se o valor base do operador pelo tamanho da linha e a estimativa de número de linhas. A soma disso é o total de custo dos operadores.
Uma vez que o plano de execuçăo foi gerado, também chamado de plano atual pelo optimizer, ele é e armazenado numa área da memória chamada "plan cache", se um plano idęntico já existir no cache o plano vai ser reutilizado.
Gerar os planos de execuçăo no SQL pode consumir tempo e recurso intensivamente do banco de dados, logo faz sentido reusar um plano de execuçăo sempre que é possível. Ao reutilizar o plano de execuçăo que foi gerado, por exemplo, torna-se desnecessário gerar um plano de execuçăo para uma query muito complexa que já tem seu plano armazenado em cache ou ainda uma query pequena que é chamada muitas vezes. Os planos de execuçăo săo armazenados numa área da memória chamada plan cache.
Os planos de execuçăo armazenados em cache săo acessíveis através da DMV sys.dm_exec_cached_plans. Pode-se saber, por exemplo, quantas vezes o plano foi reutilizado. Na Listagem 2, o filtro para planos que foram reutilizados mais de uma vez foi aplicado através da coluna “usecounts > 1”:
SELECT usecounts, cacheobjtype, objtype, text
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE usecounts > 1
ORDER BY usecounts DESC;Algumas informaçőes interessantes podem ser obtidas com uso das DMVS que o SQL disponibiliza. DMVs săo Dynamic Management Views, ou seja, views de sistema que podem ser utilizadas para várias finalidades como análise de performance. Considerando os planos armazenados em cache obtidos através da DMV sys.dm_exec_cached_plans e a DMV sys.dm_exec_query_plan, a qual retorna os planos de execuçăo em formato XML, é possível gerar o plano de execuçăo das queries que estăo em cache, como mostrados na Listagem 3.
SELECT *
FROM sys.dm_exec_cached_plans c
CROSS APPLY sys.dm_exec_query_plan(c.plan_handle) p
Entre as informaçőes que săo resultadas da execuçăo da Listagem 3 visualizadas na Figura 3, observa-se o retorno da coluna query_plan. Nela existe um link XML que acessa as informaçőes gráficas do plano de execuçăo armazenado no cache. Na maioria das vezes existirá no cache um plano armazenado por query, a năo ser que o SQL descubra que uma execuçăo paralela pode resultar numa performance melhor. Neste caso, o paralelismo passa a ser uma opçăo, e um segundo plano é criado para aquela query.
Os planos de execuçăo năo săo mantidos na memória para sempre. Eles envelhecem também, e a fórmula que o SQL utiliza para determinar a idade de um plano de execuçăo, consiste em multiplicar o custo do plano pela quantidade de vezes que ele foi executado. Este valor será decrescido pelo lazy writer (veja BOX 2).
Lazy writer é o processo responsável por limpar o cache, inclusive a área chamada de plan cache. Periodicamente ele verifica os objetos que estăo no cache e diminui o valor que foi calculado para eles.
Portanto, quando a idade do plano chegar a zero ele vai deixar de constar no cache. Existem outras situaçőes em que isso pode ocorrer como, por exemplo, quando mais memória for requerida pelo sistema e toda memória corrente estiver em uso.
Existem alguns casos em que o plano de execuçăo será recompilado, esta operaçăo pode ser bem cara para o SQL. Suponha que um plano de uma query esteja compilado e armazenado no plan cache, quando esta query for executada e o plano reutilizado, a validade e a otimizaçăo deste plano serăo validados. Se por alguma razăo esta operaçăo de validaçăo do SQL no plano falhar, ele será compilado novamente e um novo plano será gerado. Seguem alguns exemplos que podem levar a recompilaçăo do plano de execuçăo:
Talvez em algum momento de análise de performance da query possa ser interessante forçar a saída do armazenamento desta query no cache. O cache do SQL pode ser limpo completamente ou individualmente.
Para limpá-lo individualmente, por exemplo, pode ser feito através do plan_handle com o uso da DBCC FreeProcCache, a Listagem 4 mostra como obter o plan_handle, em seguida limpar individualmente o plano do cache.
SELECT plan_handle, st.text
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS st
WHERE text LIKE N'SELECT * FROM dbo.LOG_EXECUCAO%';
GO
DBCC FREEPROCCACHE (0x0600060022DC2D1E40818F85000000000000000000000000);Como informado anteriormente, é possível limpar todos os planos armazenados em cache, neste caso năo é preciso passar o plan handle. A Listagem 5 mostra como realizar isso através do uso do comando DBCC FreeProcCache.
DBCC FREEPROCCACHE WITH NO_INFOMSGS;A próxima fase pela qual a query que foi submetida irá passar é o query execution, como nome já diz é o momento em que ocorre a execuçăo da query.
Depois que o plano é gerado na Storage Engine a query vai ser executada de acordo com o plano e os dados requeridos serăo acessados. As páginas com os dados requeridos ou săo obtidas por existirem no cache ou săo acessadas no disco e depois disso colocadas no cache de dados.
O tempo que se leva para ler os dados do disco e colocá-los na memória é o tempo representado pelo waittype PageIOLatch.
Algumas vezes podem ocorrer diferenças entre as estatísticas coletadas e os dados que existem nas tabelas. Isso geralmente ocorre quando:
Isso gera um plano de execuçăo menos eficiente e má performance na execuçăo da query.
O plano de execuçăo no SQL pode ser obtido de várias maneiras e em vários formatos diferentes. A forma que irá ser escolhida para análise vai variar de pessoa para a pessoa.
Tende-se a preferir o modo gráfico, pois este é mais fácil de compreender. O modo texto é uma feature deprecated, ou seja, em algum momento a Microsoft vai desabilitar este modo de visualizaçăo.
O modo XML é o que deverá substituir o modo de visualizaçăo texto e é mais fácil de compreender.
Uma vez que a geraçăo de plano no modo texto é uma feature deprecated. Qual o sentido de saber como gerar o plano neste modo? A resposta é simples, nem sempre ao se desenvolver um projeto em SQL, os servidores estăo na última versăo do produto.
Em alguns casos, nem mesmo estăo usando o SQL 2005, neste caso por uma questăo de compatibilidade é importante saber gerar plano de execuçăo em diferentes versőes e situaçőes. A seguir estăo descritas as opçőes que permitem gerar o plano de execuçăo no modo texto:
Os planos de execuçăo no formato XML passaram a existir a partir do SQL 2005, deverăo substituir os planos de execuçăo no modo texto. Eles podem ser visualizados em formato gráfico ou formato XML e trazem até mais informaçőes que no modo gráfico.
Para gerar o plano de execuçăo em qualquer modo, seja XML, texto ou gráfico é necessário ter permissăo no banco de dados para isso. Se a pessoa que for gerar o plano de execuçăo năo for sysadmin, dbcreator ou dbowner, a permissăo a necessária é de SHOWPLAN:
GRANT SHOWPLAN TO [USER]
Com as devidas permissőes dadas, o próximo passo é obter o plano de execuçăo. Continuando pelo modo gráfico, escolha Display Estimated Execution Plan. Além do caminho apresentado no tópico “Exemplificando: Plano de Execuçăo - Modo gráfico” no início deste artigo, também existem outros caminhos possíveis para obter este modo de visualizaçăo do plano de execuçăo, sendo eles:
Uma vez que é gerado o plano apresentado, este pode ser visualizado na aba execution plan (ver Figura 5).
Com o uso dos mesmos meios demonstrados já descritos, o plano de execuçăo com as informaçőes atuais, pode ser obtido selecionando-se Include Actual Execution Plan. No entanto a tecla de atalho para acessá-lo é CTRL+M. Lembrando que o plano será gerado com a execuçăo da query, por isso ele inclui as informaçőes atuais além das estimativas, diferente do Display estimated execution plan.
Importante lembrar que no caso de se tentar ler o plano de execuçăo de uma procedure que esteja encriptada, esta por uma questăo de segurança năo mostra o plano de execuçăo.
No modo gráfico, a leitura do plano deve ser feita da direita para a esquerda de cima para baixo. Săo aproximadamente 78 operaçőes que representam várias açőes e decisőes que podem ser tomadas pelo plano de execuçăo, a operaçăo mostrada na Figura 6, é uma das possíveis.
A seta que liga os ícones representa os dados que estăo sendo passados entre eles. Quanto mais grossa a seta, maior o número de informaçőes que está sendo passada. Esta inclusive é uma pista que pode ser analisada em caso de problemas de performance.
Abaixo de cada item tem uma porcentagem que representa o custo relativo da query, para cada operador representado pelos ícones. Este custo vai de 0% até 100%, uma query pode ter múltiplos passos, cada passo vai ter um valor de custo relativo dentro do contexto da query.
Ao passar com o mouse pelos ícones percebe-se uma janela aparecer como pode ser visualizada na Figura 7, esta janela é a “tooltip”. Cada operador tem uma “tooltip” associada a ele, com detalhes referente ŕ execuçăo da package. A natureza de execuçăo de cada operador define um grupo de dados que estará disponível nesta “tooltip”.
As seguintes informaçőes podem aparecer nas tooltips:
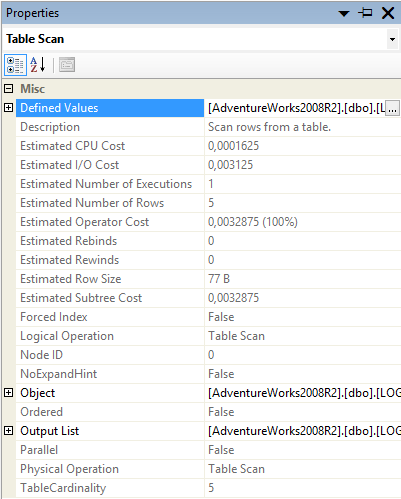
Ao clicar com o botăo direito no plano de execuçăo no modo gráfico e selecionar propriedades, pode-se obter mais detalhes sobre as operaçőes, conforme pode ser observado na Figura 8. A maioria do que está disponível nas propriedades já é conhecido, exceto por algumas informaçőes, como por exemplo:
O modo de visualizaçăo de planos de execuçăo no modo texto tem a vantagem de passar a informaçăo de uma vez só, sem a necessidade de utilizar recursos como tooltip ou as propriedades obtidas através do modo gráfico.
Para ativar este modo de exibiçăo, é preciso fazę-lo através de comando no SQL Server Management Studio, antes de executar a query, como por exemplo:
SET SHOWPLAN_ALL ON;
Logo, todos os comandos T-SQL que forem executados após a ativaçăo, como feita no exemplo acima, estarăo sujeitos ŕ exibiçăo do plano de execuçăo. Lembrando que nos casos de SHOWPLAN_ALL, SHOWPLAN_TEXT, SHOWPLAN_XML, o plano de execuçăo é estimado sem a execuçăo da query. Para desabilitar esta opçăo digite o comando:
SET SHOWPLAN_ALL OFF;
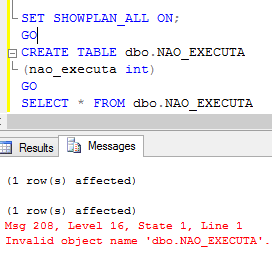
Considerando que este comando năo executa a query, apenas gera o plano. Se a query estiver na dependęncia da criaçăo de uma tabela, e esta opçăo for habilitada antes da criaçăo da tabela, o comando irá retornar erro. O comando năo irá executar a query, apenas estimá-la.
E uma vez que o comando năo irá executar a criaçăo da tabela esta năo vai existir para a geraçăo do plano de execuçăo. Esta situaçăo pode ser observada na Figura 9.
O modo de ativaçăo do plano de execuçăo no modo gráfico é diferente da ativaçăo no modo texto ou XML, neste caso utiliza-se a sintaxe: SET [modo do plano de execuçăo] ON e para desativaçăo SET [modo do plano de execuçăo] OFF.
Seguem alguns exemplos na Listagem 6 de ativaçăo e desativaçăo do plano de execuçăo.
SET SHOWPLAN_TEXT ON;
SET SHOWPLAN_TEXT OFF;
SET STATISTICS PROFILE ON;
SET STATISTICS PROFILE OFF;
SET SHOWPLAN_XML ON;
SET SHOWPLAN_XML OFF;
SET STATISTICS XML ON;
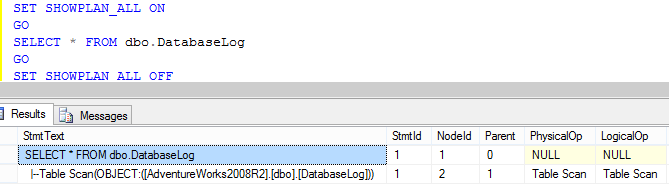
SET STATISTICS XML OFF;O plano de execuçăo no modo texto é mais complexo de ser lido do que no modo gráfico, tanto que no geral o plano de execuçăo no modo gráfico é mais usado. Para tornar isso mais claro, segue na Figura 10 o mesmo plano de execuçăo que foi gerado no modo gráfico, exemplificado dessa vez no modo texto com uso do comando SHOWPLAN ALL.
No retorno obtido ao executar o comando SHOWPLAN_ALL, a primeira coluna é StmtText, e a primeira linha desta coluna é o SELECT que foi submetido ao plano de execuçăo, as linhas após isso săo as operaçőes. No modo gráfico as operaçőes eram mostradas através de ícones.
Quanto mais complexo o plano de execuçăo, mais complexa é a leitura no modo textual. A leitura neste caso, năo pode ser da direita para a esquerda como no modo gráfico, no modo texto fará mais sentido ler a partir do meio e depois disso para fora seguindo o uso da endentaçăo e do pipe (|).
As mesmas informaçőes disponíveis no modo gráfico estăo disponíveis no modo texto ou XML, e ainda um pouco mais de informaçăo.
Lembrando que o modo mais recomendado para obter os planos de execuçăo no modo texto săo os planos gerados como XMLs.
No modo XML, disponível a partir do SQL 2005, é possível visualizar mais informaçőes que no modo gráfico como, por exemplo, fraçőes de memória (como a memória que foi disponibilizada é distribuída entre os operadores no plano) e é notavelmente mais simples que o modo texto, no qual tem – se que se localizar através de endentaçőes e pipes (|).
O plano de execuçăo no modo XML traz os resultados do plano através de um link XML, conforme pode ser verificado na Figura 11, e pode ser visualizado tanto no modo gráfico como em XML.
Ao clicar no link disponibilizado pelo plano de execuçăo, percebe-se que um conjunto mais completo de informaçőes, mesmo para uma query simples, é disponibilizado.
Algo interessante de se observar é o tipo de plano que foi gerado, esta informaçăo é obtida através do valor em StatementOptmLevel = “TRIVIAL”. Logo, para a execuçăo desta query foi escolhido um plano de execuçăo trivial, ou seja, ao invés de escolher o plano de execuçăo ótimo, pela simplicidade da query foi escolhido o modo trivial.
O modo XML provę mais informaçăo para análise e é melhor para ler que o modo texto, parte do plano pode ser observado pela Listagem 7 o qual o resultado foi gerado através do script da Listagem 8. A maioria das informaçőes disponibilizadas já săo conhecidas como, por exemplo, EstimateRows ou EstimateIO e podem ser visualizadas tanto no modo XML , texto ou gráfico.
<ShowPlanXML xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan" Version="1.1" Build="10.50.1600.1">
<BatchSequence>
<Batch>
<Statements>
<StmtSimple StatementText="SELECT *
FROM dbo.DatabaseLog
" StatementId="1"
StatementCompId="1" StatementType="SELECT"
StatementSubTreeCost="0.576891" StatementEstRows="1597"
StatementOptmLevel="TRIVIAL" QueryHash="0xCEA1767217FB35FD"
QueryPlanHash="0x2959B5DE1A3E7C7D">
<StatementSetOptions QUOTED_IDENTIFIER="true"
ARITHABORT="true" CONCAT_NULL_YIELDS_NULL="true"
ANSI_NULLS="true" ANSI_PADDING="true"
ANSI_WARNINGS="true" NUMERIC_ROUNDABORT="false" />
<QueryPlan CachedPlanSize="16" CompileTime="121"
CompileCPU="109" CompileMemory="88">
<RelOp NodeId="0" PhysicalOp="Table Scan"
LogicalOp="Table Scan" EstimateRows="1597"
EstimateIO="0.574977" EstimateCPU="0.0019137"
AvgRowSize="8593" EstimatedTotalSubtreeCost="0.576891"
TableCardinality="1597" Parallel="0"
EstimateRebinds="0" EstimateRewinds="0">
<OutputList>
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="DatabaseLogID" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="PostTime" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="DatabaseUser" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="Event" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="Schema" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="Object" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="TSQL" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="XmlEvent" />
</OutputList>
<TableScan Ordered="0" ForcedIndex="0" NoExpandHint="0">
SET SHOWPLAN_XML ON
GO
SELECT * FROM dbo.DatabaseLog
GO
SET SHOWPLAN_XML OFFÉ possível salvar o plano de execuçăo, e para isso nem é preciso abri-lo. Basta clicar com o botăo direito no link disponibilizado e escolher Save as. Da mesma forma o modo gráfico pode ser salvo, apenas clicando com o botăo direito do mouse e escolhendo a opçăo Save as.
Entre as opçőes possíveis para gerar o plano de execuçăo, existe a opçăo Statistics XML, a qual vai executar a query antes de trazer o plano de execuçăo, com isso as informaçőes atuais como número de linhas atuais serăo disponibilizadas Diferente do comando SHOWPLAN_XML que apenas estima e năo executa a query, portanto os dados atuais năo aparecem apenas os dados estimados. A Figura 12 traz a execuçăo do Statistics XML feita através dos comandos na Listagem 9.
SET STATISTICS XML ON
GO
SELECT * FROM dbo.DatabaseLog
GO
SET STATISTICS XML OFFParte das informaçőes contidas no link XML gerado pode ser vista na Listagem 10. Nela estăo as informaçőes atuais do plano de execuçăo.
<ShowPlanXML xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan" Version="1.1" Build="10.50.1600.1">
<BatchSequence>
<Batch>
<Statements>
<StmtSimple StatementText="SELECT *
FROM dbo.DatabaseLog
" StatementId="1"
StatementCompId="1" StatementType="SELECT"
StatementSubTreeCost="0.576891" StatementEstRows="1597"
StatementOptmLevel="TRIVIAL" QueryHash="0xCEA1767217FB35FD"
QueryPlanHash="0x2959B5DE1A3E7C7D">
<StatementSetOptions QUOTED_IDENTIFIER="true"
ARITHABORT="true" CONCAT_NULL_YIELDS_NULL="true"
ANSI_NULLS="true" ANSI_PADDING="true" ANSI_WARNINGS="true"
NUMERIC_ROUNDABORT="false" />
<QueryPlan DegreeOfParallelism="1" CachedPlanSize="16"
CompileTime="121" CompileCPU="109" CompileMemory="88">
<RelOp NodeId="0" PhysicalOp="Table Scan"
LogicalOp="Table Scan" EstimateRows="1597"
EstimateIO="0.574977" EstimateCPU="0.0019137"
AvgRowSize="8593" EstimatedTotalSubtreeCost="0.576891"
TableCardinality="1597" Parallel="0"
EstimateRebinds="0" EstimateRewinds="0">
<OutputList>
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="DatabaseLogID" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="PostTime" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="DatabaseUser" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="Event" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="Schema" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="Object" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]" Column="TSQL" />
<ColumnReference Database="[AdventureWorks2008R2]"
Schema="[dbo]" Table="[DatabaseLog]"
Column="XmlEvent" />
</OutputList>
<RunTimeInformation>
<RunTimeCountersPerThread Thread="0" ActualRows="1597"
ActualEndOfScans="1" ActualExecutions="1" />
</RunTimeInformation>
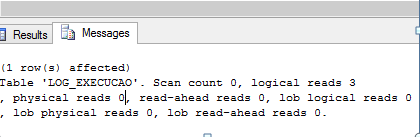
<TableScan Ordered="0" ForcedIndex="0" NoExpandHint="0">Entre as opçőes de Statistics usadas para gerar e avaliar o plano de execuçăo existe a Statistics IO. As estatísticas de I/O medem a quantidade de atividade em disco gerada pela query. O resultado do Statistics IO pode ser visto na Figura 13 habilitada através do script da Listagem 11.
SET STATISTICS IO ON
GO
SELECT * FROM dbo.DatabaseLog
GO
SET STATISTICS IO OFFAs informaçőes produzidas por esta opçăo estăo descritas a seguir:
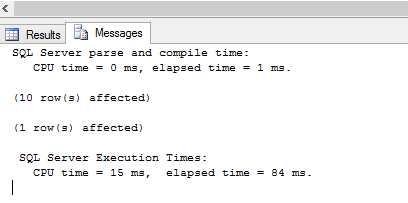
Existe tambéma opçăo Statistics Time, a qual informa o tempo em milissegundos para cada operaçăo a ser completada no plano de execuçăo. Habilitada através do exemplo na Listagem 12, os resultados podem ser vistos na Figura 14.
SET STATISTICS TIME ON
GO
SELECT * FROM dbo.DatabaseLog
GO
SET STATISTICS TIME OFFO momento em que a opçăo Statistics Time for habilitada e a query for rodada pode trazer variaçăo no tempo informado, dependendo do tamanho do dataset retornado ou concorręncia no banco e etc.
Existem outros tipos de Sets Statistics, estes săo apenas alguns dos que podem ser utilizados para a análise de performance da query.
Os exemplos de planos de execuçăo que foram gerados no decorrer deste artigo apresentavam o operador table scan conforme pode ser visto na Figura 15. O que exatamente Table Scan significa?
Table Scan, conforme definido anteriormente, informa que o Optimizer escolheu fazer scan da tabela toda, linha a linha até encontrar o resultado que foi requerido. Esta decisăo pode ter sido entre outros motivos por năo ter índice na tabela, ou por que a quantidade de dados a ser trazida é tăo grande que năo vale a pena utilizar o índice. Portanto os índices, caso existam, năo estăo sendo utilizados.
Se a tabela for pequena, o table scan năo chega a ser um problema. Entretanto se for uma tabela grande é interessante avaliar outras estratégias como: reescrever a query, verificar a possibilidade de criaçăo de um índice de acordo com a consulta, ou filtrá-la e limitar os dados para que esta possa a utilizar índices que já existam na tabela.
Além do Table Scan, existe outro tipo de operador que utiliza Scan e é muito encontrado nos planos de execuçăo. Este é o Index Scan, o que isso significa dentro do plano de execuçăo?
Index Scan é o scan do índice que pode ser cluster ou năo cluster, ou seja, o índice todo ou uma grande parte dele esta sendo escaneado linha por linha até alcançar o resultado desejado.
Os índices săo armazenados em B-tree (vários nós que apontam para um parente). Um índice cluster năo armazena apenas a estrutura chave como um índice normal, mas também filtra e classifica o armazenamento do dado.
Por isso só existe um índice cluster por tabela. Se um índice scan está sendo retornado no plano de execuçăo, isso significa que o Optimizer entendeu que muitas linhas precisam ser retornadas e é mais fácil escanear o índice inteiro do que simplesmente utilizar as chaves providenciadas por ele.
Neste caso o que pode ser feito é analisar o uso do índice criado, estreitar, se possível, o filtro da cláusula WHERE, podem ser um bom caminho a seguir.
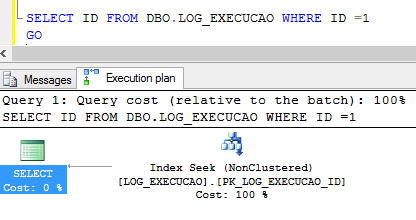
Outro operador comum de ser visualizado no plano de execuçăo é o index seek, conforme pode ser visto na Figura 16. Este năo é um operador de scan como os dois anteriores, é um operador de seek que funciona sobre o índice. O que isso significa para o plano de execuçăo?
Index Seek, ao contrário do index scan, ocorre quando o Optimizer conseguiu localizar a informaçăo requerida através do uso do índice que pode ser cluster ou năo cluster. Logo através dos valores chaves do índice, rapidamente o valor da linha que precisa ser retornado foi encontrado. Percebe-se que quando há o uso de cluster index seek a propriedade Ordered do plano de execuçăo esta setada para true, ou seja, os dados estăo ordenados. Se o índice for năo cluster, este pode ou năo estar apontando para um índice cluster a fim de realizar o index seek.
Compreender o que ocorre dentro do SQL e como os planos de execuçăo săo gerados permite diferenciar o que de fato é importante para o ganho de performance na construçăo de uma query do que năo é.
Por exemplo, considerando que os planos de execuçăo săo baseados em custo e que cada operador tem sua base de custo para o cálculo do plano de execuçăo, pode-se concluir que o custo dos operadores năo é baseado na velocidade do hardware. Năo se está considerando que o hardware năo é importante para performance, ao contrário, é importante, todavia o custo dos operadores independe do hardware.
Logo, o custo do operador calculado será o mesmo em qualquer versăo e instalaçăo do SQL. Um fator de influęncia no cálculo do plano neste caso, entre outros fatores, seria a atualizaçăo das estatísticas, pois o cálculo de estimativa do custo leva em consideraçăo esta informaçăo.
Estas informaçőes podem ser concluídas, porque há entendimento de como o SQL funciona e o que acontece quando uma consulta é submetida. Com isso é possível determinar quais as melhores decisőes a serem tomadas, as que realmente irăo influenciar na performance do código de acordo com o objetivo a ser atingido.
A partir dos próximos artigos, a complexidade das queries vai aumentar e também o número de operadores usados pelo plano de execuçăo. Com isso serăo abordados quais desses operadores devem sero foco de atuaçăo para obter ganho de performance
GRANT, Fritchey. The Art of High Performance SQL Code: SQL Server Execution Plans. Simple-Talk. 2008. p 17-46.
BOLTON Christian; LANGFORD Justin; BERRY Glen; PAYNE Gavin; BANERJEE Amit; FARLEY Rob. SQL Server 2012 Internals and Troubleshooting. John Wiley & Sons, Inc., Indianópolis, Indiana. 2013. p 48-55.


Utilizamos cookies para fornecer uma melhor experięncia para nossos usuários, consulte nossa política de privacidade.